Planejamento de capacidade para clusters HDInsight
Antes de implantar um cluster HDInsight, planeje a capacidade do cluster, determinando o desempenho e a escala necessários. Este planejamento ajuda a otimizar os custos e a usabilidade. Algumas decisões sobre a capacidade do cluster não podem ser alteradas após a implantação. Se os parâmetros de desempenho se alterarem, um cluster poderá ser desmontado e criado novamente sem perder os dados armazenados.
As principais perguntas para o planejamento de capacidade são:
- Em qual região geográfica você deve implantar o cluster?
- Qual a quantidade de armazenamento que você precisa?
- Qual tipo de cluster você deve implantar?
- Qual o tamanho e o tipo de VM (máquina virtual) os nós de cluster devem usar?
- Quantos nós de trabalho seu cluster deve ter?
Escolher uma região do Azure
A região do Azure determina o local em que o cluster é provisionado fisicamente. Para minimizar a latência de leituras e gravações, o cluster deve ficar próximo aos seus dados.
O HDInsight está disponível em muitas regiões do Azure. Para localizar a região mais próxima, consulte Produtos disponíveis por região.
Escolher o tamanho e o local de armazenamento
Local do armazenamento padrão
O armazenamento padrão, seja uma conta de Armazenamento do Azure ou um Azure Data Lake Storage, deve estar no mesmo local que o cluster. O Armazenamento do Azure está disponível em todos os locais. O Data Lake Storage está disponível em algumas regiões. Veja a Disponibilidade do Data Lake Storage atual.
Local dos dados existentes
Se quiser usar uma conta de armazenamento existente ou Data Lake Storage como o armazenamento padrão do cluster, deverá implantar o cluster no mesmo local.
Tamanho de armazenamento
Em um cluster implantado, você pode anexar outras contas de Armazenamento do Microsoft Azure ou acessar outros Data Lake Storage. Todas as suas contas de armazenamento precisam estar no mesmo local que o cluster. Um Data Lake Storage pode estar em um local diferente, embora grandes distâncias possam apresentar alguma latência.
O Armazenamento do Microsoft Azure tem alguns limites de capacidade, enquanto o Data Lake Storage é virtualmente ilimitado. Um cluster pode acessar uma combinação de contas de armazenamento diferentes. Exemplos comuns incluem:
- Quando é provável que a quantidade de dados exceda a capacidade de armazenamento de um único contêiner de armazenamento de blobs.
- Quando a taxa de acesso ao contêiner de blob pode exceder o máximo em que a limitação ocorre.
- Quando você quiser disponibilizar os dados que você já carregou em um contêiner de blob para o cluster.
- Quando você quiser isolar diferentes partes do armazenamento por questões de segurança ou para simplificar a administração.
Para obter melhor desempenho, use apenas um contêiner por conta de armazenamento.
Escolher um tipo de cluster
O tipo de cluster determina a carga de trabalho que o cluster HDInsight está configurado para executar. Os tipos incluem Apache Hadoop, Apache Kafka ou Apache Spark. Para obter uma descrição detalhada dos tipos de cluster disponíveis, consulte Introdução ao Azure HDInsight. Cada tipo de cluster tem uma topologia de implantação específica que inclui os requisitos de tamanho e número de nós.
Escolher tipo e tamanho da VM
Cada tipo de cluster tem um conjunto de tipos de nós e cada tipo de nó tem opções específicas quanto ao tamanho e o tipo de VM.
Para determinar o tamanho de cluster ideal para sua aplicação, você pode submeter a capacidade do cluster a submeter a benchmark e aumentar o tamanho conforme indicado. Por exemplo, você pode usar uma carga de trabalho simulada ou uma consulta canary. Execute suas cargas de trabalho simuladas em clusters de tamanho diferente. Aumente gradualmente o tamanho até que o desempenho pretendido seja atingido. Uma consulta canary pode ser inserida periodicamente entre as outras consultas de produção a fim de mostrar se o cluster tem recursos suficientes.
Para mais informações sobre como escolher a família de VMs correta para sua carga de trabalho, consulte Selecionar o tamanho correto da VM para seu cluster.
Escolher a escala do cluster
A escala do cluster é determinada pela quantidade de seus nós de VM. Para todos os tipos de cluster, há tipos de nós que têm uma escala específica e tipos de nós que dão suporte à expansão. Por exemplo, um cluster pode exigir exatamente três nós do Apache ZooKeeper ou dois nós principais. Nós de trabalho que realizam o processamento de dados de maneira distribuída se beneficiam de outros nós de trabalho.
Dependendo do tipo de cluster, aumentar o número de nós de trabalho inclui mais capacidade computacional (como mais núcleos). Mais nós aumentarão a memória total necessária para que o cluster inteiro dê suporte ao armazenamento na memória dos dados em processamento. Assim como a seleção do tamanho e do tipo de VM, selecionar a escala certa do cluster é normalmente um processo empírico. Use cargas de trabalho simuladas ou consultas canary.
Você pode escalar horizontalmente o cluster para atender às demandas de pico de carga. Em seguida, reduza-o verticalmente quando esses nós extras não são mais necessários. O recurso de dimensionamento automático permite dimensionar automaticamente o cluster com base em métricas e tempos predeterminados. Para mais informações sobre o dimensionamento manual de clusters, consulte Dimensionar clusters do HDInsight.
Ciclo de vida do cluster
A cobrança é feita pelo tempo de vida do cluster. Se seu cluster for necessário apenas em momentos específicos, você poderá criar clusters sob demanda usando o Azure Data Factory. Você também pode criar scripts do PowerShell que provisionam e excluem o cluster e, em seguida, agendar esses scripts usando a Automação do Azure.
Observação
Quando um cluster é excluído, seu metastore do Hive padrão também é excluído. Para manter o metastore para a próxima recriação de cluster, use um repositório de metadados externo, como o Banco de Dados do Azure ou Apache Oozie.
Isolar os erros de trabalho do cluster
Às vezes, erros podem ocorrer devido à execução paralela de vários mapas e componentes de redução em um cluster de vários nós. Para ajudar a isolar o problema, experimente o teste distribuído. Execute vários trabalhos simultâneos em um único cluster de nó de trabalho. Em seguida, expanda essa abordagem para executar vários trabalhos simultaneamente em clusters que contenham mais de um nó. Para criar um cluster do HDInsight de nó único no Azure, use a opção Custom(size, settings, apps) e um valor de 1 para Número de nós de trabalho na seção Tamanho do cluster ao provisionar um novo cluster no portal.
Exibir o gerenciamento de cotas do HDInsight
Ver um nível granular e a categorização da cota em um nível de família de VMs. Exiba a cota atual e a quantidade de cota restante para uma região em um nível de família de VMs.
Observação
No momento, este recurso está disponível no HDInsight 4.x e 5.x para a região Leste dos EUA EUAP. Outras regiões para seguir posteriormente.
Exibição da cota atual:
Veja a cota atual e a quantidade de cota restante para uma região em um nível de família de VMs.
No portal do Azure, na barra de pesquisa superior, pesquise e selecione Cotas.
Na página Cota, selecione Azure HDInsight

Na caixa suspensa, selecione sua Assinatura e a Região
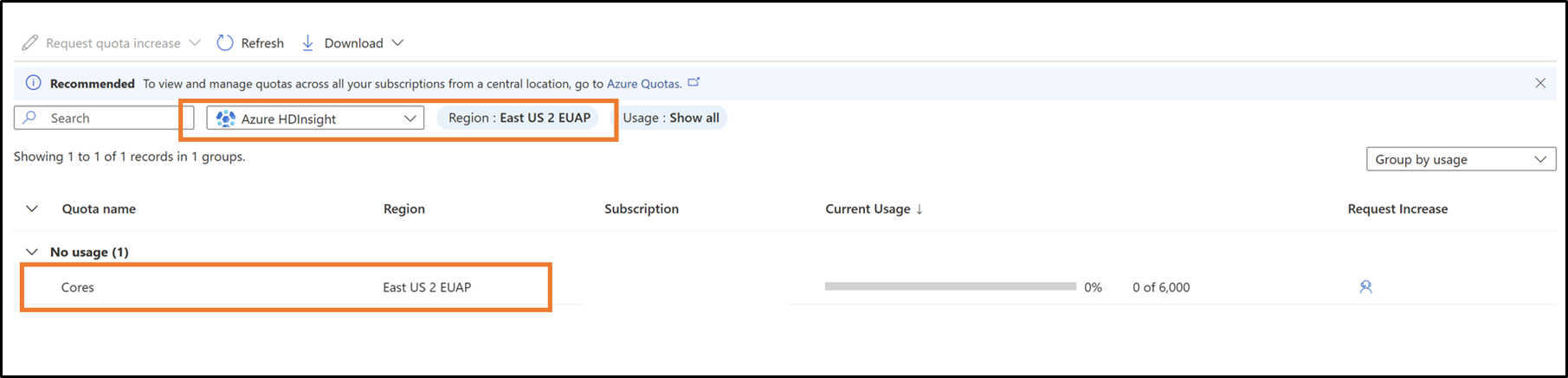

Solicitar novas cotas por família de VM e região
- clique na linha para a qual deseja exibir os detalhes da cota.





Cotas
Para mais informações sobre o gerenciamento de cotas de assinatura, consulte Solicitar aumentos de cota.
Próximas etapas
- Configurar clusters no HDInsight com Apache Hadoop, Spark, Kafka e mais: Saiba como instalar e configurar clusters no HDInsight.
- Monitorar o desempenho do cluster: saiba mais sobre os principais cenários a serem monitorados em seu cluster HDInsight e que podem afetar a capacidade do seu cluster.