Usar o Azure Toolkit for IntelliJ para criar aplicativos Apache Spark para um cluster do HDInsight
Este artigo demonstra como desenvolver aplicativos Apache Spark no Azure HDInsight usando o plug-in Azure Toolkit para o IntelliJ IDE. Azure HDInsight é um serviço gerenciado de análise de software livre na nuvem. O serviço permite que você use estruturas de software livre como Hadoop, Apache Spark, Apache Hive e Apache Kafka.
Você pode usar o plug-in Azure Toolkit destas maneiras:
- Desenvolver e enviar um aplicativo Scala Spark em um cluster HDInsight Spark.
- Acessar os recursos de cluster Spark do Azure HDInsight.
- Desenvolver e executar um aplicativo Scala Spark localmente.
Neste artigo, você aprenderá como:
- Usar o plug-in Azure Toolkit for IntelliJ
- Desenvolver aplicativos do Apache Spark
- Enviar um aplicativo para o cluster do Azure HDInsight
Pré-requisitos
Um cluster do Apache Spark no HDInsight. Para obter instruções, consulte o artigo sobre como Criar clusters do Apache Spark no Azure HDInsight. Somente os clusters do HDinsight na nuvem pública têm suporte, enquanto outros tipos seguros de nuvem (por exemplo, nuvens governamentais) não têm.
Kit de desenvolvimento Oracle Java. Este artigo usa a versão do Java 8.0.202.
IntelliJ IDEA. Este artigo usa o IntelliJ IDEA Community 2018.3.4.
Azure Toolkit for IntelliJ. Confira Installing the Azure Toolkit for IntelliJ (Instalação do Azure Toolkit for IntelliJ).
Instalar o plug-in Scala para IntelliJ IDEA
Etapas para instalar o plug-in do Scala:
Abra o IntelliJ IDEA.
Na tela de boas-vindas, navegue até Configurar>Plug-ins para abrir a janela Plug-ins.

Selecione Instalar para o plug-in Scala caracterizado na nova janela.

Depois que o plug-in foi instalado com êxito, você deve reiniciar o IDE.
Criar um aplicativo Scala Spark para um cluster HDInsight Spark
Inicie o IntelliJ IDEA e selecione Criar novo projeto para abrir a janela Novo projeto.
Selecione Azure Spark/HDInsight no painel esquerdo.
Selecione Projeto Spark (Scala) na janela principal.
Na lista suspensa Ferramenta de build, selecione uma destas opções:
Maven para obter suporte ao assistente de criação de projetos Scala.
SBT para gerenciar as dependências e para criar no projeto Scala.
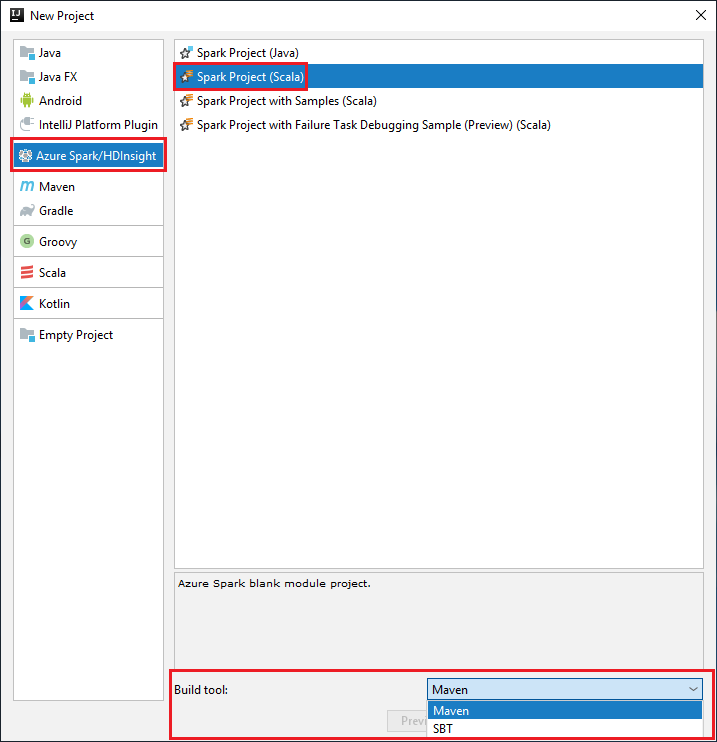
Selecione Avançar.
Na janela Novo Projeto, forneça as seguintes informações:
Propriedade Descrição Nome do projeto Insira um nome. Este artigo usa myApp.Localização do projeto Insira o local no qual salvar o projeto. SDK do projeto Esse campo ficará em branco na primeira utilização do IDEA. Selecione Novo... e navegue até o JDK. Versão do Spark O assistente de criação integra a versão apropriada para o SDK do Spark e o SDK do Scala. Se a versão do cluster do Spark for anterior à 2.0, selecione Spark 1.x. Caso contrário, selecione Spark2.x. Esse exemplo usa o Spark 2.3.0 (Scala 2.11.8) . 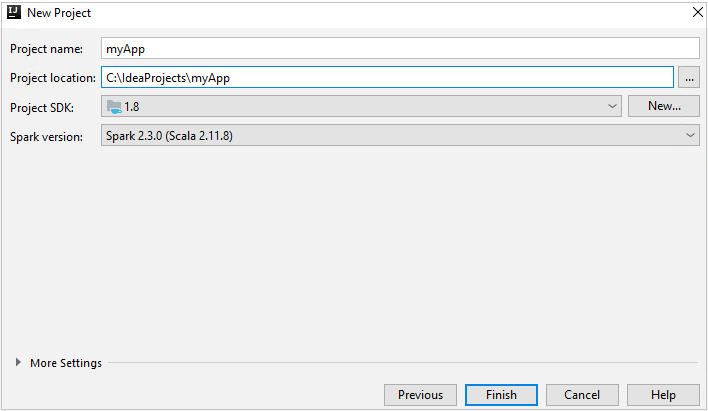
Selecione Concluir. Pode levar alguns minutos antes que o projeto fique disponível.
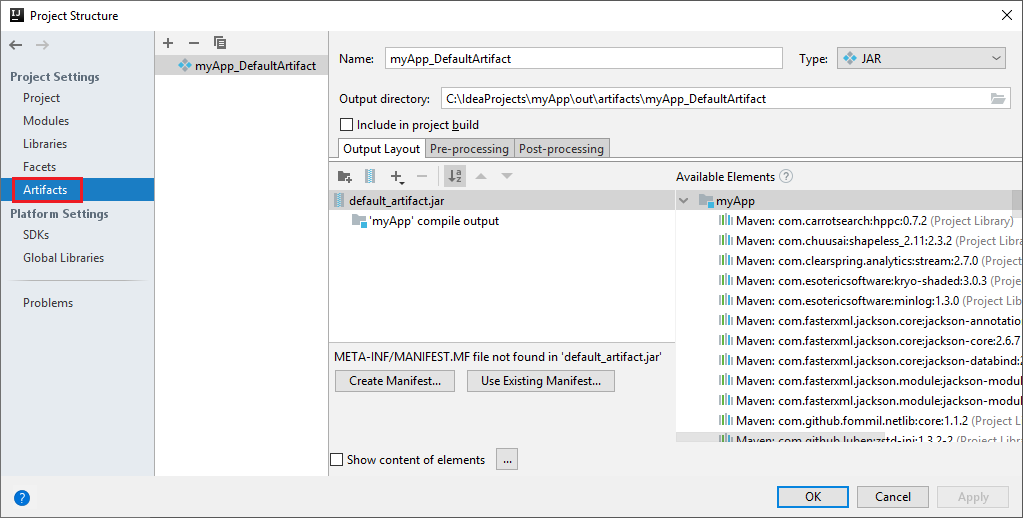
O projeto do Spark cria automaticamente um artefato para você. Para exibir o artefato, execute as seguintes etapas:
a. Na barra de menus, navegue até Arquivo>Estrutura do projeto... .
b. Na janela Estrutura do Projeto, selecione Artefatos.
c. Selecione Cancelar depois de exibir o artefato.
Adicione o código-fonte do aplicativo seguindo estas etapas:
a. Em Projeto, navegue até myApp>src>principal>scala.
b. Clique com o botão direito do mouse em scala e, em seguida, navegue até Novo>classe Scala.
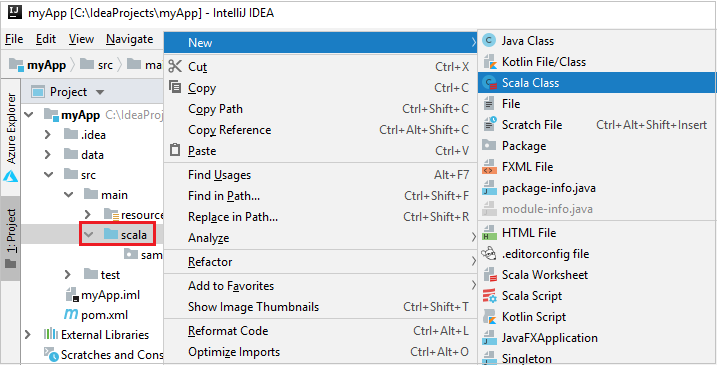
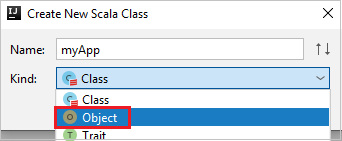
c. Na caixa de diálogo Criar Nova Classe do Scala, forneça um nome, selecione Objeto na lista suspensa Tipo e selecione OK.
d. O arquivo myApp.scala então se abre na exibição principal. Substitua o código padrão pelo código localizado abaixo:
import org.apache.spark.SparkConf import org.apache.spark.SparkContext object myApp{ def main (arg: Array[String]): Unit = { val conf = new SparkConf().setAppName("myApp") val sc = new SparkContext(conf) val rdd = sc.textFile("wasbs:///HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv") //find the rows that have only one digit in the seventh column in the CSV file val rdd1 = rdd.filter(s => s.split(",")(6).length() == 1) rdd1.saveAsTextFile("wasbs:///HVACOut") } }O código lê os dados no HVAC.csv (disponível em todos os clusters Spark do HDInsight), recupera as linhas com apenas um dígito na sétima coluna no arquivo CSV e grava a saída em
/HVACOutno contêiner padrão de armazenamento do cluster.
Conectar-se ao cluster HDInsight
O usuário pode entrar na assinatura do Azure ou vincular um cluster do HDInsight. Use o nome de usuário/senha do Ambari ou a credencial de ingresso no domínio para se conectar ao cluster do HDInsight.
Entre em sua assinatura do Azure
Na barra de menus, navegue até Exibição>Janelas de Ferramentas>Azure Explorer.
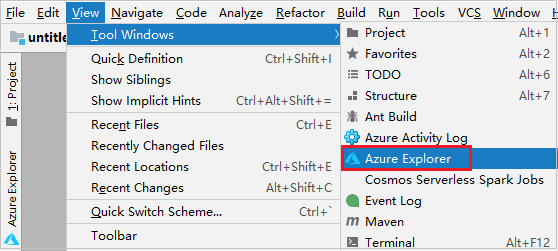
No Azure Explorer, clique com o botão direito do mouse no nó Azure e, em seguida, selecione Entrar.
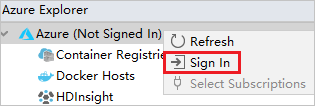
Na caixa de diálogo Entrar no Azure, escolha Logon do Dispositivo e selecione Entrar.

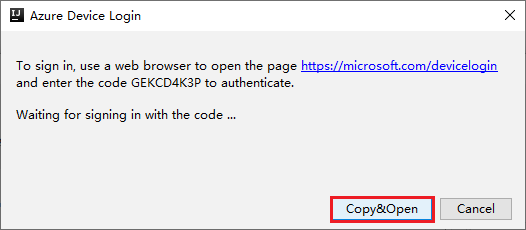
Na caixa de diálogo Logon no Dispositivo do Azure, clique em Copiar e Abrir.
Na interface do navegador, cole o código e clique em Avançar.
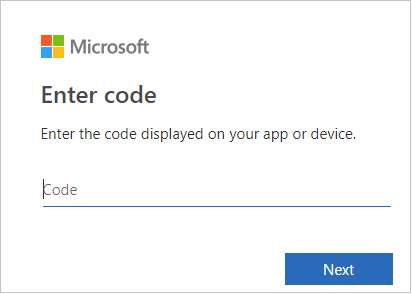
Insira suas credenciais do Azure e feche o navegador.

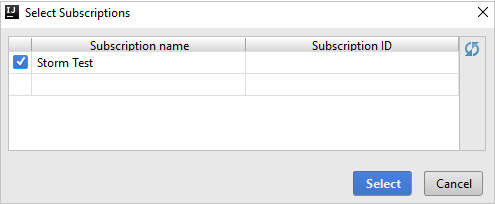
Depois que você estiver conectado, a caixa de diálogo Selecionar Assinaturas listará todas as assinaturas do Azure associadas às credenciais. Selecione sua assinatura e, em seguida, selecione o botão Selecionar.
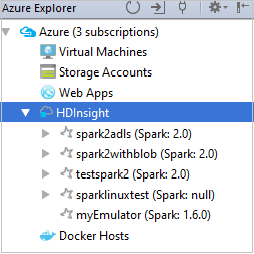
No Azure Explorer, expanda HDInsight para exibir os clusters Spark do HDInsight em suas assinaturas.
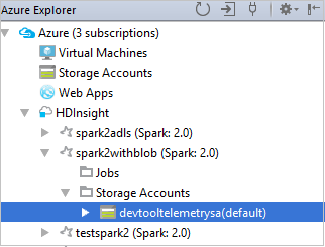
Para exibir os recursos (por exemplo, contas de armazenamento) associados ao cluster, você poderá expandir ainda mais um nó de nome de cluster.
Vincular um cluster
Você pode vincular um cluster HDInsight usando o nome de usuário gerenciado do Apache Ambari. Da mesma forma, para um cluster HDInsight ingressado no domínio, crie o vínculo usando o domínio e o nome de usuário, como user1@contoso.com. Also you can link Livy Service cluster.
Na barra de menus, navegue até Exibição>Janelas de Ferramentas>Azure Explorer.
No Azure Explorer, clique com o botão direito do mouse em HDInsight nó e selecione Vincular um Cluster.
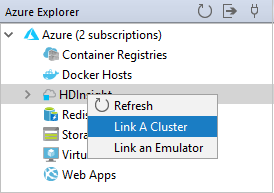
As opções disponíveis na janela Vincular um Cluster vão variar conforme o valor selecionado na lista suspensa Tipo de Recurso de Link. Insira seus valores e, em seguida, selecione OK.
Cluster do HDInsight
Propriedade Valor Tipo de Recurso de Link Selecione Cluster do HDInsight na lista suspensa. Nome/URL do cluster Insira o nome do cluster. Tipo de autenticação Deixe como Autenticação Básica Nome do Usuário Insira o nome de usuário do cluster, o padrão é admin. Senha Insira a senha do nome de usuário. 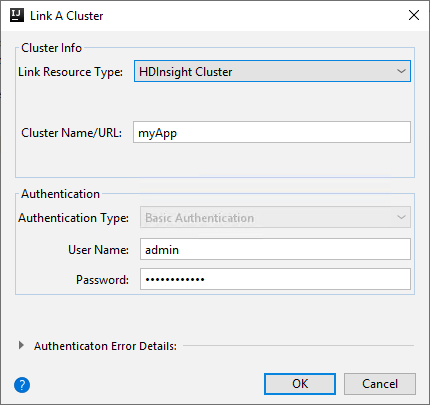
Serviço Livy
Propriedade Valor Tipo de Recurso de Link Selecione Serviço Livy na lista suspensa. Ponto de Extremidade do Livy Inserir o Ponto de Extremidade Livy Nome do cluster Insira o nome do cluster. Ponto de Extremidade do Yarn Opcional. Tipo de autenticação Deixe como Autenticação Básica Nome do Usuário Insira o nome de usuário do cluster, o padrão é admin. Senha Insira a senha do nome de usuário. 
Você pode ver seu cluster vinculado do nó do HDInsight.

Também é possível desvincular um cluster a partir do Azure Explorer.
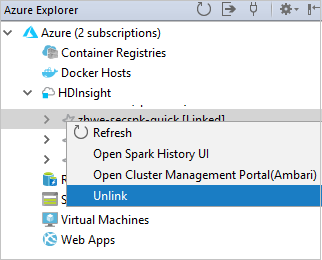
Executar um aplicativo Scala Spark em um cluster HDInsight Spark
Depois de criar um aplicativo Scala, você poderá enviá-lo ao cluster.
De Projeto, navegue até myApp>src>main>scala>myApp. Clique com o botão direito do mouse em myApp e selecione Enviar Aplicativo Spark (provavelmente estará localizado na parte inferior da lista).
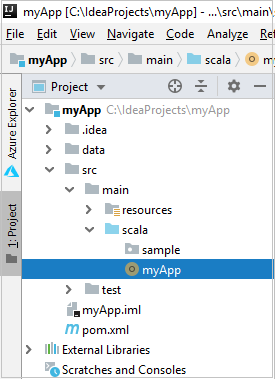
Na janela de diálogo Enviar Aplicativo do Spark, selecione 1. Spark no HDInsight.
Na janela Editar configuração, forneça os seguintes valores e, em seguida, selecione OK:
Propriedade Valor Clusters do Spark (somente Linux) Selecione o cluster HDInsight Spark no qual você deseja executar o aplicativo. Selecione um Artefato para enviar Deixe a configuração padrão. Nome da classe principal O valor padrão é a classe principal do arquivo selecionado. Você pode alterar a classe selecionando as reticência ( ... ) e escolhendo outra classe. Configurações de trabalho Você pode alterar as chaves e/ou valores padrão. Para obter mais informações, confira API REST do Apache Livy. Argumentos de linha de comando Você pode inserir argumentos separados por espaço para a classe principal se necessário. Arquivos Referenciados e Jars Referenciados você pode inserir os caminhos para os Jars e os arquivos referenciados, se houver. Você também pode procurar arquivos no sistema de arquivos virtual do Azure, que atualmente suporta apenas o cluster ADLS Gen 2. Para obter mais informações: Configuração do Spark do Apache. Confira também Como carregar recursos para o cluster. Armazenamento de Upload de Trabalho Expanda para revelar opções adicionais. Tipo de armazenamento Selecione Usar Blob do Azure para carregar na lista suspensa. Conta de Armazenamento Insira sua conta de armazenamento. Chave de Armazenamento Insira sua chave de armazenamento. Contêiner de armazenamento Selecione seu contêiner de armazenamento na lista suspensa depois que Conta de Armazenamento e Chave de Armazenamento tiverem sido inseridas. 
Selecione SparkJobRun para enviar seu projeto para o cluster selecionado. A guia Trabalho do Spark Remoto no Cluster exibe o andamento da execução do trabalho na parte inferior. Você pode parar o aplicativo clicando no botão vermelho.
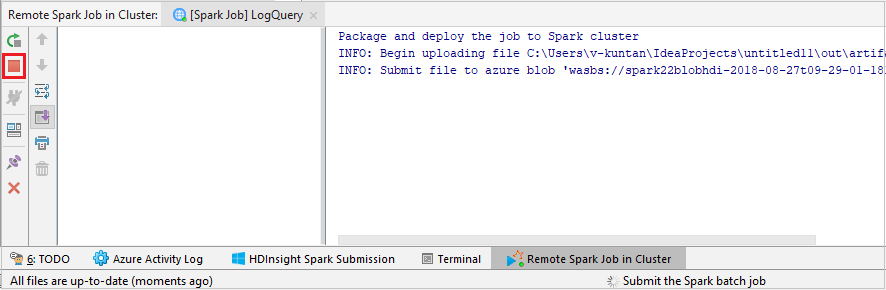
Depurar aplicativos do Apache Spark local ou remotamente em um cluster do HDInsight
Também recomendamos outra forma de enviar o aplicativo Spark ao cluster. Você pode fazer isso definido os parâmetros no IDE Executar/Depurar configurações. Confira Depurar aplicativos Apache Spark local ou remotamente em um cluster HDInsight com Azure Toolkit for IntelliJ por meio do SSH.
Acessar e gerenciar clusters Spark do HDInsight usando o Kit de Ferramentas do Azure para IntelliJ
Você pode executar várias operações usando o Azure Toolkit for IntelliJ. A maioria das operações é iniciada no Azure Explorer. Na barra de menus, navegue até Exibição>Janelas de Ferramentas>Azure Explorer.
Acessar a exibição do trabalho
No Azure Explorer, navegue até HDInsight><Seu Cluster>>Trabalhos.
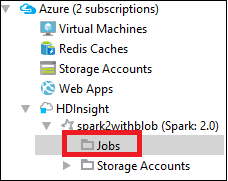
No painel direito, a guia Exibição de Trabalho do Spark exibe todos os aplicativos que foram executados no cluster. Selecione o nome do aplicativo do qual você deseja ver mais detalhes.
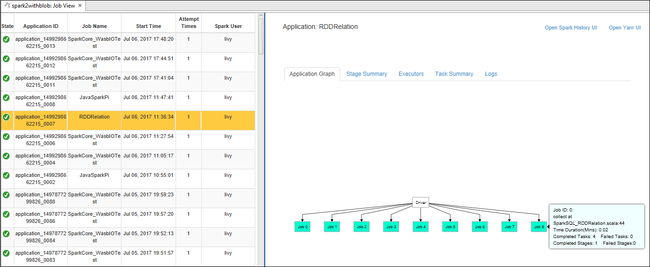
Para exibir informações básicas do trabalho em execução, passe o mouse sobre o grafo de trabalhos. Para exibir o grafo de estágios e as informações geradas pelos trabalhos, escolha um nó no grafo de trabalhos.
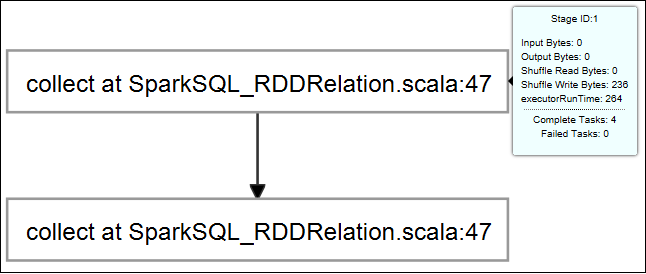
Para exibir logs usados frequentemente, como Stderr do Driver, Stdout do Driver e Informações do diretório, escolha a guia Log.
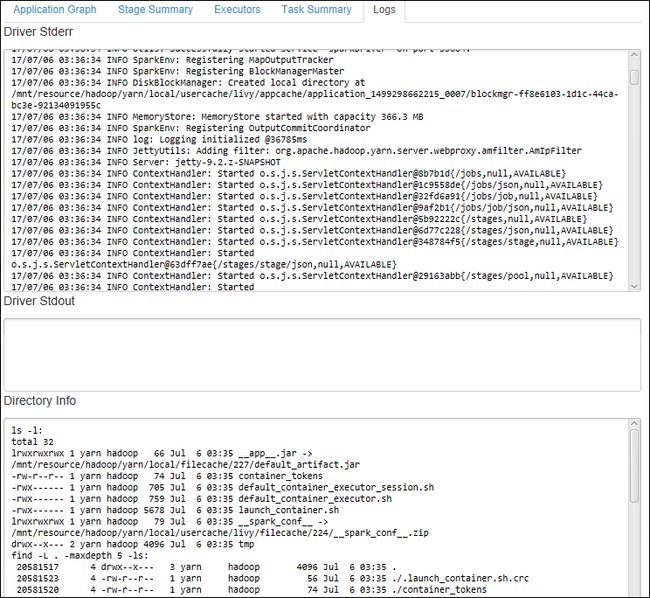
Você pode ver a IU de histórico do Spark e IU do YARN (no nível do aplicativo). Selecione um link na parte superior da janela.
Acessar o servidor de histórico do Spark
No Azure Explorer, expanda o HDInsight, clique com o botão direito do mouse no nome do cluster Spark e selecione Abrir interface do usuário do Histórico Spark.
Quando for solicitado, insira as credenciais do administrador do cluster, que você especificou ao configurar o cluster.
No painel do servidor de histórico do Spark, é possível usar o nome do aplicativo para procurar o que você acabou de executar. No código anterior, você definiu o nome do aplicativo usando
val conf = new SparkConf().setAppName("myApp"). O nome do aplicativo Spark é myApp.
Iniciar o portal do Ambari
No Azure Explorer, expanda HDInsight, clique com o botão direito do mouse no nome do cluster Spark e selecione Abrir Portal de Gerenciamento do Cluster (Ambari).
Quando solicitado, insira as credenciais de administrador para o cluster. Você especificou essas credenciais durante o processo de configuração do cluster.
Gerenciar assinaturas do Azure
Por padrão, o Kit de Ferramentas do Azure para IntelliJ listam os clusters Spark de todas as suas assinaturas do Azure. Se for necessário, você poderá especificar as assinaturas que deseja acessar.
No Azure Explorer, clique com o botão direito do mouse no nó-raiz Azure e selecione Selecionar Assinaturas.
Na janela Selecionar Assinaturas, desmarque as caixas de seleção ao lado das assinaturas que você não deseja acessar e, em seguida, selecione Fechar.
Console do Spark
Você pode executar o Console Local do Spark (Scala) ou o Console de Sessão Interativa do Spark Livy (Scala).
Console Local do Spark (Scala)
Verifique se você satisfez o pré-requisito do WINUTILS.EXE.
Na barra de menus, navegue até Executar>Editar Configurações... .
Na janela Executar/depurar configurações, no painel esquerdo, navegue até Apache Spark no HDInsight>[Spark no HDInsight] myApp.
Na janela principal, selecione a guia
Locally Run.Forneça os seguintes valores e, em seguida, selecione OK:
Propriedade Valor Classe principal do trabalho O valor padrão é a classe principal do arquivo selecionado. Você pode alterar a classe selecionando as reticência ( ... ) e escolhendo outra classe. Variáveis de ambiente Verifique se o valor de HADOOP_HOME está correto. Localização de WINUTILS.exe Verifique se o caminho está correto. 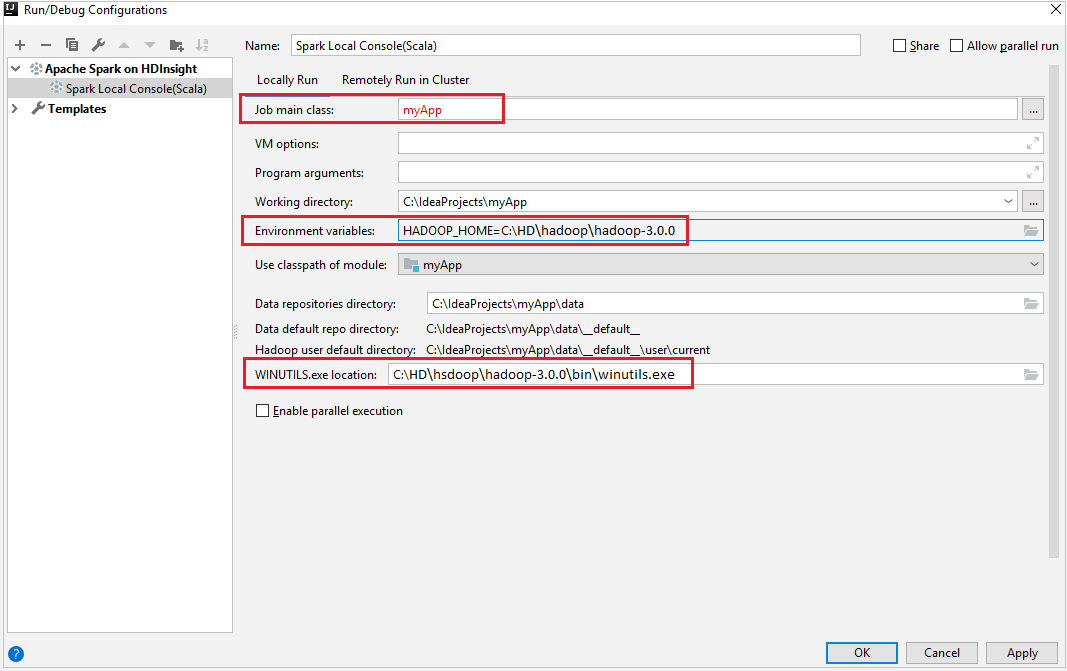
De Projeto, navegue até myApp>src>main>scala>myApp.
Na barra de menus, navegue até Ferramentas>Console do Spark>Executar Console Local do Spark (Scala) .
Em seguida, duas caixas de diálogo poderão ser exibidas para perguntar se você deseja corrigir automaticamente as dependências. Em caso afirmativo, selecione Autocorreção.
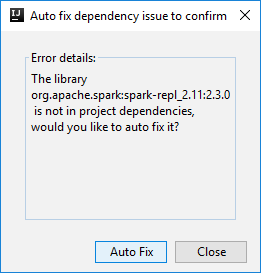

O console deve ser semelhante à imagem abaixo. Na janela do console, digite
sc.appNamee pressione ENTER. O resultado será exibido. Você pode interromper o console local clicando no botão vermelho.
Console de Sessão Interativa do Spark Livy (Scala)
Na barra de menus, navegue até Executar>Editar Configurações... .
Na janela Executar/depurar configurações, no painel esquerdo, navegue até Apache Spark no HDInsight>[Spark no HDInsight] myApp.
Na janela principal, selecione a guia
Remotely Run in Cluster.Forneça os seguintes valores e, em seguida, selecione OK:
Propriedade Valor Clusters do Spark (somente Linux) Selecione o cluster HDInsight Spark no qual você deseja executar o aplicativo. Nome da classe principal O valor padrão é a classe principal do arquivo selecionado. Você pode alterar a classe selecionando as reticência ( ... ) e escolhendo outra classe. 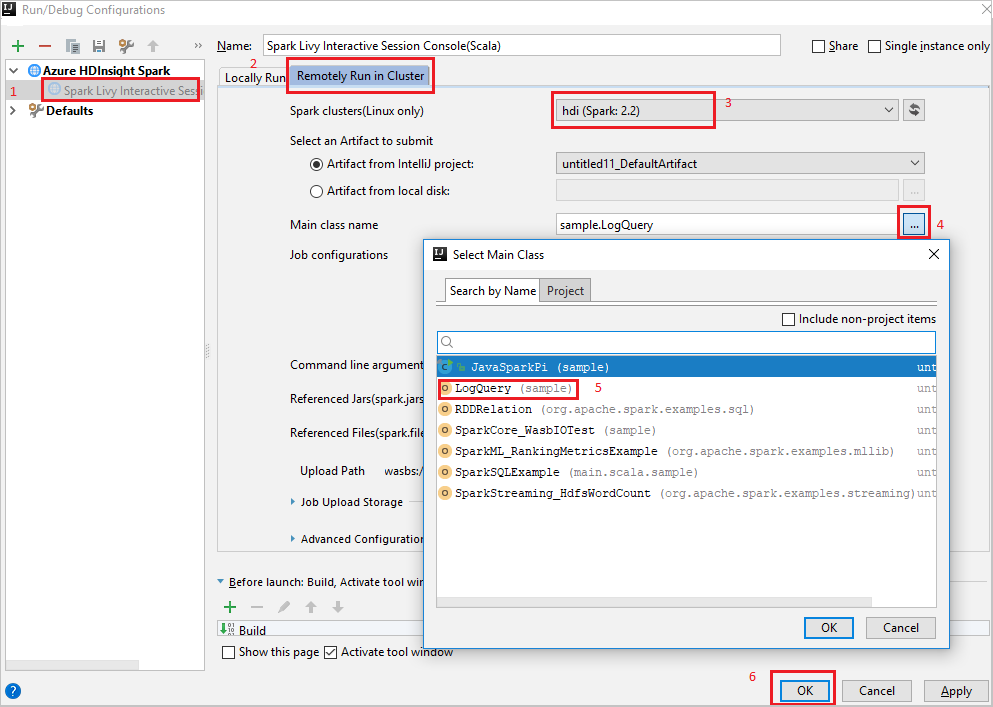
De Projeto, navegue até myApp>src>main>scala>myApp.
Na barra de menus, navegue até Ferramentas>Console do Spark>Executar Console de Sessão Interativa do Spark Livy (Scala) .
O console deve ser semelhante à imagem abaixo. Na janela do console, digite
sc.appNamee pressione ENTER. O resultado será exibido. Você pode interromper o console local clicando no botão vermelho.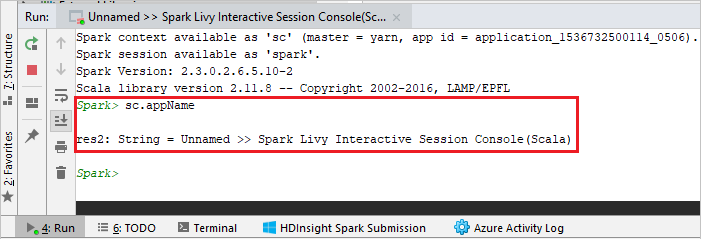
Enviar seleção para o Console do Spark
É conveniente para você prever o resultado do script enviando algum código para o console local ou Console (Scala) de sessão interativa Livy. Você pode realçar código no arquivo do Scala e, em seguida, clicar com o botão direito do mouse em Enviar Seleção ao Console do Spark. O código selecionado será enviado ao console. O resultado será exibido após o código no console. O console verificará erros, se houver.
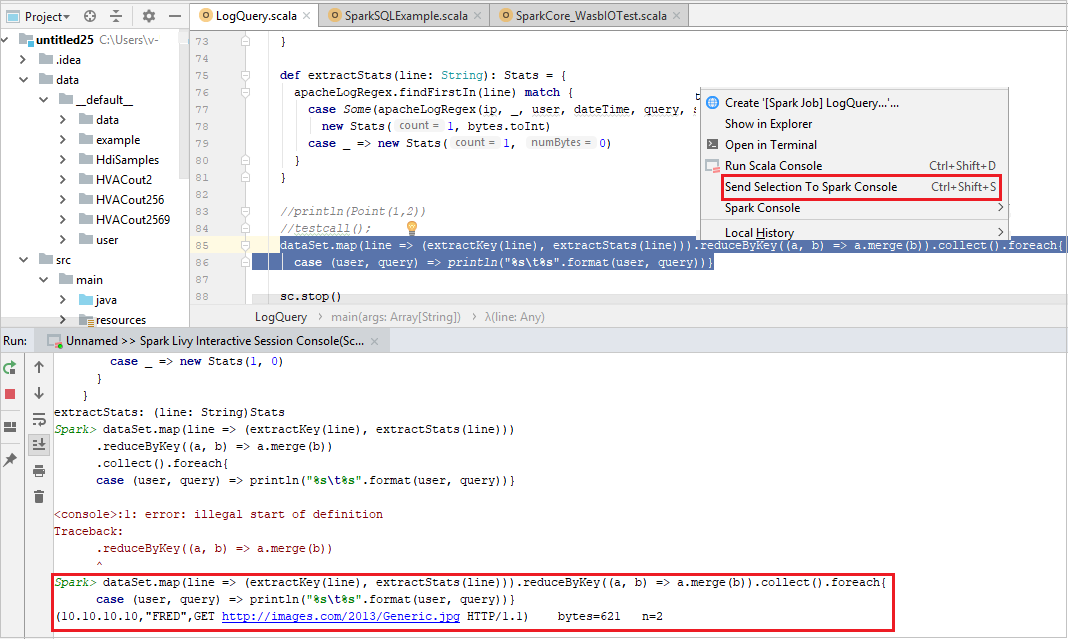
Integrar com o (HIB) Agente de Identidade do HDInsight
Conectar-se ao cluster do HDInsight ESP com o HIB (Agente de IDs)
Você pode seguir as etapas normais para entrar na assinatura do Azure para se conectar a seu cluster do HDInsight ESP com o HIB (Agente de IDs). Depois de entrar, você verá a lista de clusters no Azure Explorer. Para obter mais instruções, confira Conectar-se a seu cluster do HDInsight.
Executar um aplicativo do Spark Scala em um cluster do HDInsight com HIB (Agente de IDs)
Você pode seguir as etapas normais para enviar o trabalho ao cluster do HDInsight ESP com o HIB (Agente de IDs). Veja Executar um aplicativo do Spark Scala em um cluster do HDInsight Spark para obter mais instruções.
Fazemos upload dos arquivos necessários em uma pasta nomeada com sua conta de entrada e você pode ver o caminho de upload no arquivo de configuração.

Console do Spark em um cluster do HDInsight ESP com o HIB (Agente de IDs)
Você pode executar o Console Local do Spark (Scala) ou executar o Console de Sessão Interativa do Spark Livy (Scala) em um cluster do HDInsight ESP com o HIB (Agente de IDs). Veja o Console do Spark para obter mais instruções.
Observação
No momento, o cluster do HDInsight ESP com o HIB (Agente de IDs) não é compatível com a vinculação de um cluster e a depuração de aplicativos do Apache Spark remotamente.
Função somente leitura
Quando os usuários enviam um trabalho a um cluster com permissão de função somente leitura, as credenciais do Ambari são solicitadas.
Vincular cluster do menu de contexto
Entrar com conta com função somente leitura.
No Azure Explorer, expanda HDInsight para exibir os clusters do HDInsight em sua assinatura. Os clusters marcados "Role:Reader" só tem permissão para a função somente leitura.
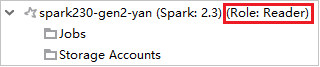
Clique com botão direito do mouse no cluster com permissão para a função somente leitura. Selecione Vincular este cluster no menu de contexto para vincular o cluster. Insira o nome de usuário e a senha do Ambari.

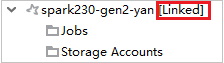
Se o cluster for vinculado com êxito, o HDInsight será atualizado. O estágio do cluster será se tornará vinculado.

Vincular cluster expandindo o nó Trabalhos
Clique no nó Trabalhos, a janela Acesso negado ao cluster Trabalhos é exibida.
Clique em Vincular este cluster para vincular o cluster.

Vincular cluster da janela Configurações de execução/depuração
Crie uma configuração do HDInsight. Depois selecione Executar Remotamente em Cluster.
Selecione um cluster, que tenha a permissão de função somente leitura, para Clusters do Spark (somente Linux). A mensagem de aviso é mostrada. Você pode clicar em Vincular este cluster para vincular o cluster.
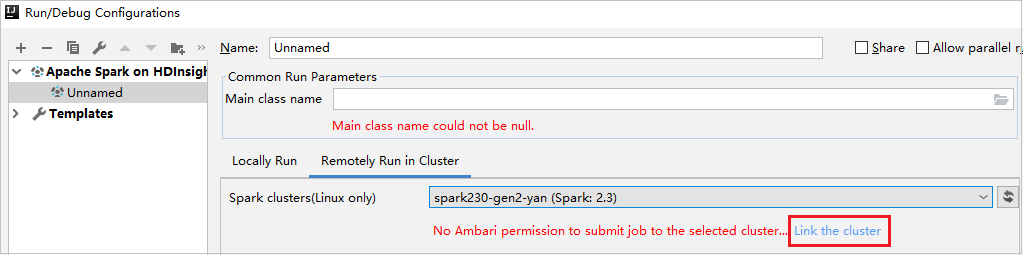
Exibir Contas de Armazenamento
Para clusters com permissão de função somente leitura, clique no nó Contas de Armazenamento, a janela Acesso Negado ao Armazenamento aparece. Você pode clicar em Abrir Gerenciador de Armazenamento do Azure para abrir o Gerenciador de Armazenamento.
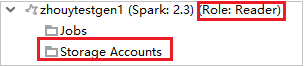

Para clusters vinculados, clique no nó Contas de Armazenamento, a janela Acesso Negado ao Armazenamento aparece. Você pode clicar em Abrir Armazenamento do Azure para abrir o Gerenciador de Armazenamento.

Converter aplicativos IntelliJ IDEA existentes a fim de usar o Kit de Ferramentas do Azure para IntelliJ
Você pode converter os aplicativos Scala Spark existentes criados no IDEA do IntelliJ para serem compatíveis com o Kit de Ferramentas do Azure para IntelliJ. Em seguida, você pode usar o plug-in para enviar os aplicativos a um cluster Spark do HDInsight.
Para um aplicativo do Scala Spark existente criado no IDEA do IntelliJ, abra o arquivo
.imlassociado.Há um elemento module no nível de raiz, como este texto:
<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4">Edite o elemento para adicionar
UniqueKey="HDInsightTool", de modo que o elemento module fique assim:<module org.jetbrains.idea.maven.project.MavenProjectsManager.isMavenModule="true" type="JAVA_MODULE" version="4" UniqueKey="HDInsightTool">Salve as alterações. Seu aplicativo deve ser compatível com o Kit de Ferramentas do Azure para IntelliJ. Você pode testar isso clicando com o botão direito do mouse no nome do projeto no Projeto. Agora, o menu pop-up tem a opção Enviar Aplicativo Spark ao HDInsight.
Limpar os recursos
Se não for continuar a usar este aplicativo, exclua o cluster que criou seguindo estas etapas:
Entre no portal do Azure.
Na caixa Pesquisar na parte superior, digite HDInsight.
Selecione Clusters do HDInsight em Serviços.
Na lista de clusters do HDInsight exibida, selecione … ao lado do cluster que você criou para este artigo.
Selecione Excluir. Selecione Sim.
Erros e solução
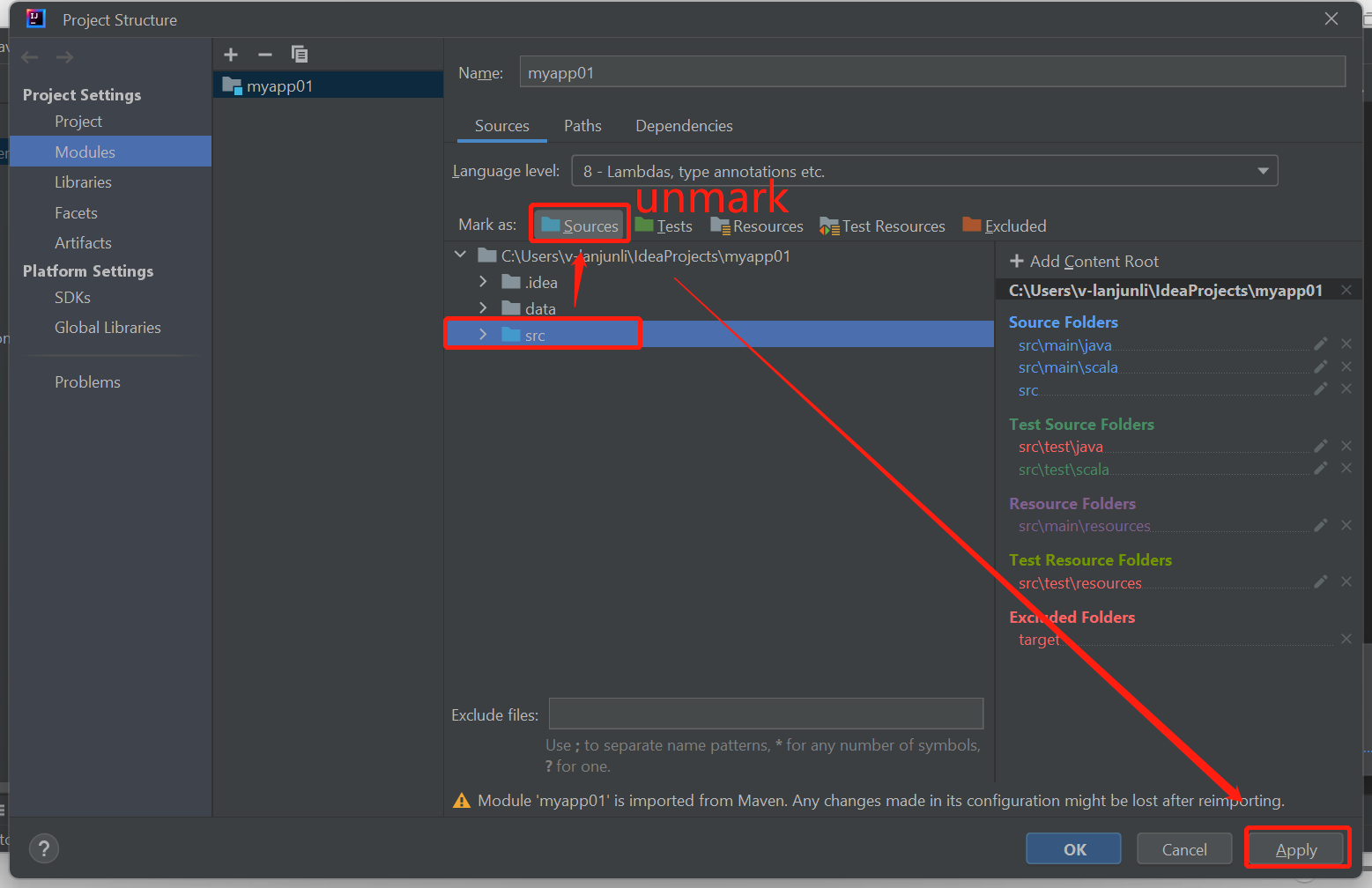
Desmarque a pasta src como Fontes se você receber erros de falha de build, conforme mostrado abaixo:
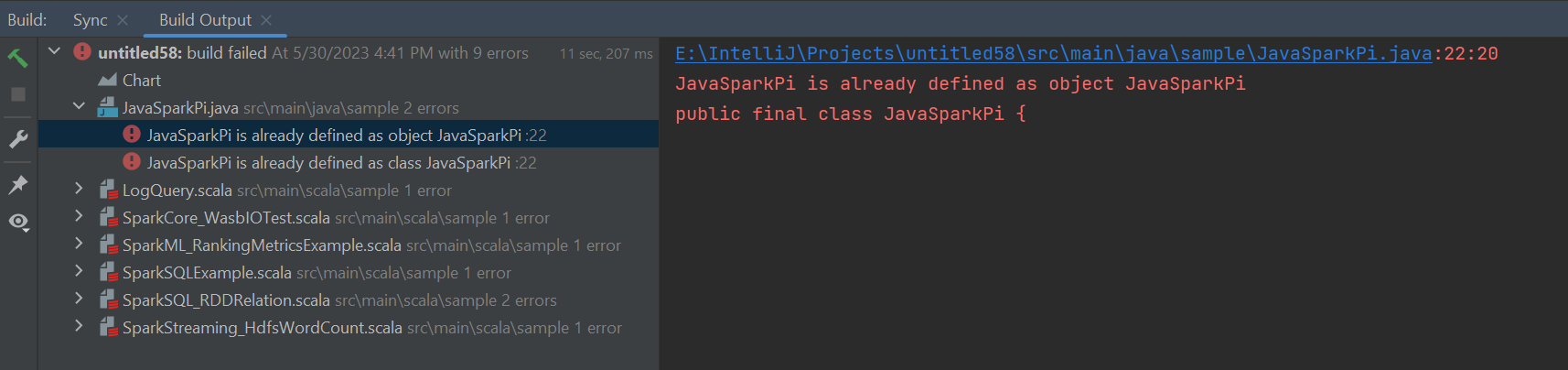
Desmarque a pasta src como Fontes para resolver esse problema:
Navegue até Arquivo e selecione a Estrutura do Projeto.
Selecione os Módulos nas Configurações do Projeto.
Selecione o arquivo src e desmarque como Fontes.
Clique no botão Aplicar e, em seguida, clique no botão OK para fechar a caixa de diálogo.
Próximas etapas
Neste artigo, você aprendeu a usar o plug-in Azure Toolkit for IntelliJ para desenvolver aplicativos do Apache Spark escritos no Scala. Em seguida, os enviou para um cluster do HDInsight Spark diretamente do IDE (ambiente de desenvolvimento integrado) do IntelliJ. Avance para o próximo artigo para ver como os dados que você registrou no Apache Spark podem ser removidos em uma ferramenta de análise de BI, assim como Power BI.