Início Rápido: Criar um cluster do Apache Spark no Azure HDInsight usando o portal do Azure
Neste início rápido, você usará o portal do Azure para criar um cluster Apache Spark do Azure HDInsight. Em seguida, você criará um Jupyter Notebook e o usará para executar consultas SQL do Spark em tabelas do Apache Hive. O Azure HDInsight é um serviço de análise de software livre gerenciado e de amplo espectro para empresas. A estrutura Apache Spark para HDInsight permite análises rápidas de dados e computação de cluster usando o processamento na memória. O Jupyter Notebook permite que você interaja com os seus dados, combine o código com texto Markdown e realizar visualizações simples.
Para obter explicações detalhadas sobre as configurações disponíveis, confira Configurar clusters no HDInsight. Para obter mais informações sobre o uso do portal para criar clusters, confira Criar clusters no portal.
Se estiver usando vários clusters juntos, você pode optar por criar uma rede virtual e, se estiver usando um cluster do Spark, você talvez queira usar o Hive Warehouse Connector. Para obter mais informações, confira Planejar uma rede virtual para o Azure HDInsight e Integrar o Apache Spark e o Apache Hive com o Hive Warehouse Connector.
Importante
A cobrança dos clusters do HDInsight será proporcional por minuto, independentemente de eles estarem sendo usados ou não. Exclua seu cluster depois de terminar de usá-lo. Para saber mais, confira a seção Recursos de limpeza deste artigo.
Pré-requisitos
Uma conta do Azure com uma assinatura ativa. Crie uma conta gratuitamente.
Criar um cluster Apache Spark no HDInsight
Você usará o portal do Azure para criar um cluster HDInsight que usa blobs do Armazenamento do Azure como o armazenamento de cluster. Para obter mais informações sobre como usar o Data Lake Storage Gen2, consulte o Guia de Início Rápido: Configurar clusters no HDInsight.
Entre no portal do Azure.
No menu superior, selecione + Criar um recurso.
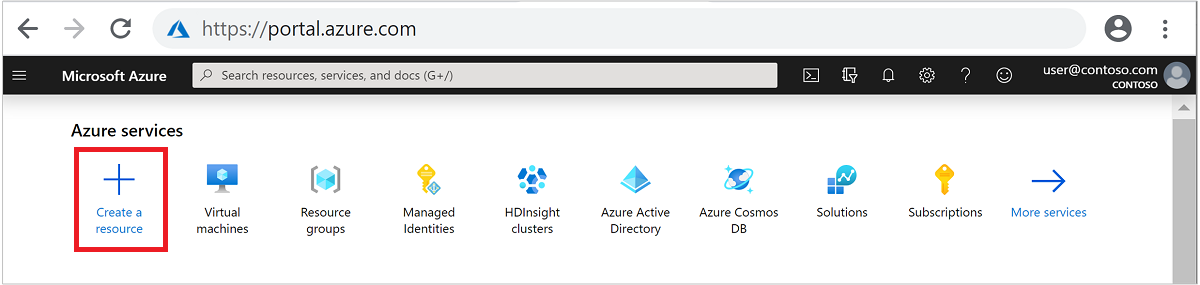
Selecione Análise>Azure HDInsight para acessar a página Criar cluster HDInsight.
Na guia Informações Básicas, forneça as seguintes informações:
Propriedade Descrição Subscription Na lista suspensa, selecione a assinatura do Azure usada para o cluster. Resource group Na lista suspensa, selecione o grupo de recursos existente ou selecione Criar. Nome do cluster Insira um nome global exclusivo. Região Na lista suspensa, selecione uma região em que o cluster foi criado. Zona de disponibilidade Opcional: é possível especificar uma zona de disponibilidade na qual implantar o cluster Tipo de cluster Selecione o tipo de cluster para abrir uma lista. Na lista, selecione Spark. Versão do cluster Esse campo será preenchido automaticamente com a versão padrão depois que o tipo de cluster tiver sido selecionado. Nome de usuário de logon do cluster Insira o nome de logon do usuário do cluster. O nome padrão é admin. Você pode usar essa conta fazer logon no Jupyter Notebook mais tarde no início rápido. Senha de logon do cluster Insira a senha de logon do cluster. Nome de usuário do Secure Shell (SSH) Insira um Nome de Usuário SSH. O nome de usuário de SSH usado para este início rápido é sshuser. Por padrão, essa conta tem a mesma senha que a conta denome de usuário de logon do cluster. 
Selecione Avançar: armazenamento >> para continuar na página Armazenamento.
Em Armazenamento, forneça os seguintes valores:
Propriedade Descrição Tipo de armazenamento primário Use o valor padrão Armazenamento do Azure. Método de seleção Use o valor padrão Selecione na lista. Conta de armazenamento primária Use o valor preenchido automaticamente. Contêiner Use o valor preenchido automaticamente. 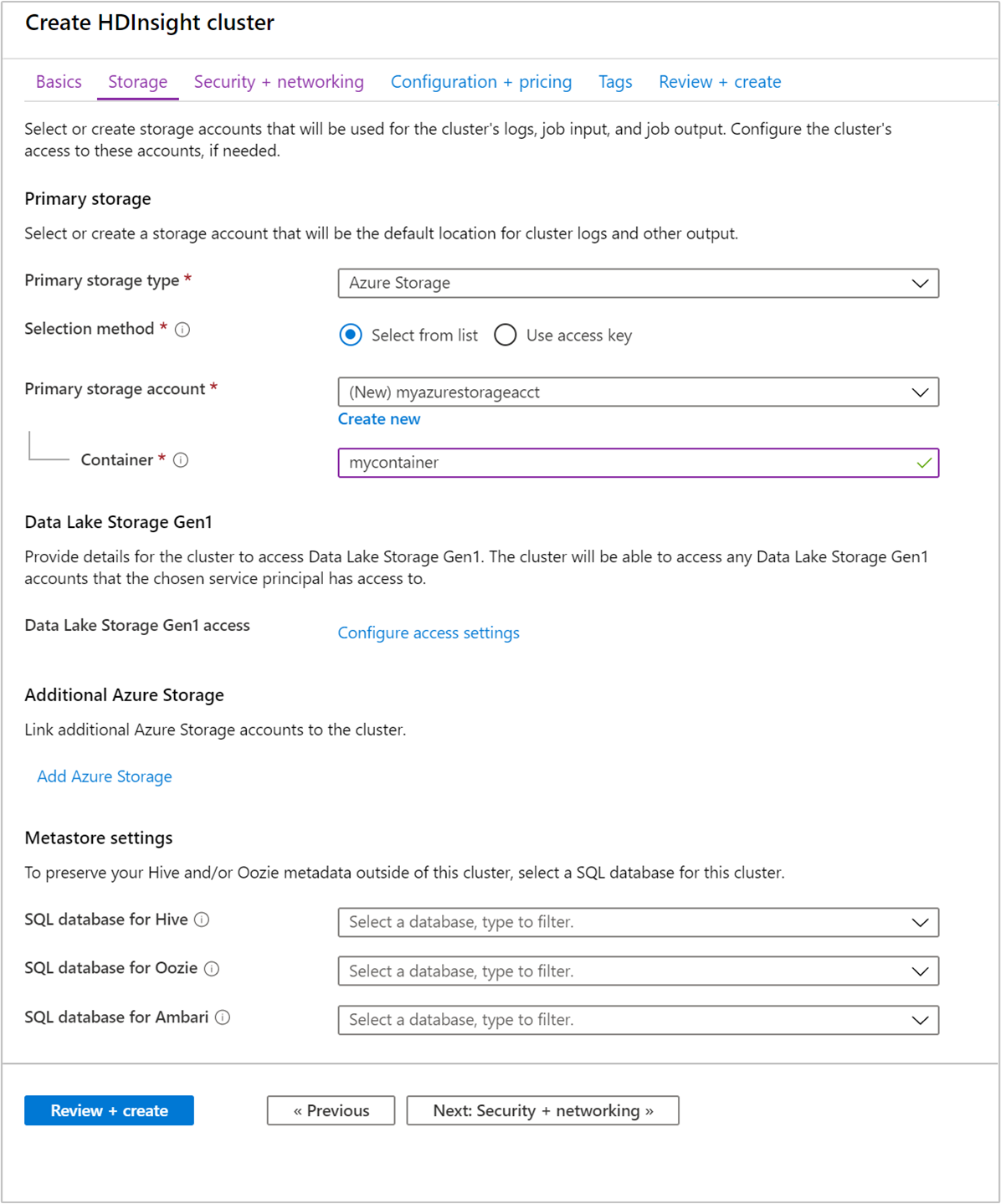
Selecione Examinar + criar para continuar.
Em Examinar + criar, selecione Criar. Demora cerca de 20 minutos para criar o cluster. O cluster deve ser criado antes de prosseguir para a próxima sessão.
Se você tiver um problema com a criação de clusters HDInsight, talvez não tenha as permissões corretas para fazer isso. Para saber mais, confira Requisitos do controle de acesso.
Criará um Jupyter Notebook
O Jupyter Notebook é um ambiente de notebook interativo que oferece suporte a várias linguagens de programação. O notebook permite que você interaja com seus dados, combine código com texto markdown e execute visualizações simples.
Em um navegador da Web, navegue até
https://CLUSTERNAME.azurehdinsight.net/jupyter, em queCLUSTERNAMEé o nome do cluster. Em caso de solicitação, insira as credenciais de logon do cluster.Selecione Novo>PySpark para criar um notebook.
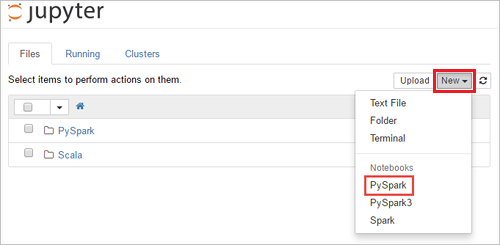
Um novo bloco de anotações é criado e aberto com o nome Untitled(Untitled.pynb).
Executar instruções SQL do Apache Spark
O SQL (Structured Query Language) é a linguagem mais comum e amplamente usada para consultar e definição de dados. O Spark SQL funciona como uma extensão do Apache Spark para processar dados estruturados, usando a sintaxe SQL familiar.
Verifique se o kernel está pronto. O kernel estará pronto quando você vir um círculo vazio ao lado do nome do kernel no notebook. Círculo sólido indica que o kernel está ocupado.

Quando você inicia o notebook pela primeira vez, o kernel executa algumas tarefas em segundo plano. Aguarde a leitura do kernel.
Cole o código a seguir em uma célula vazia e pressione SHIFT + ENTER para executar o código. O comando lista as tabelas de Hive no cluster:
%%sql SHOW TABLESQuando você usa um Jupyter Notebook com o cluster HDInsight, obtém uma predefinição
sqlContextque pode ser usada para executar consultas do Hive usando o Spark SQL.%%sqlinforma ao Notebook Jupyter para usar a predefiniçãosqlContextpara executar a consulta Hive. A consulta recupera as primeiras 10 linhas de uma tabela Hive (hivesampletable) que vem com todos os clusters HDInsight por padrão. Ele leva aproximadamente 30 segundos para obter os resultados. A saída se parece com isso: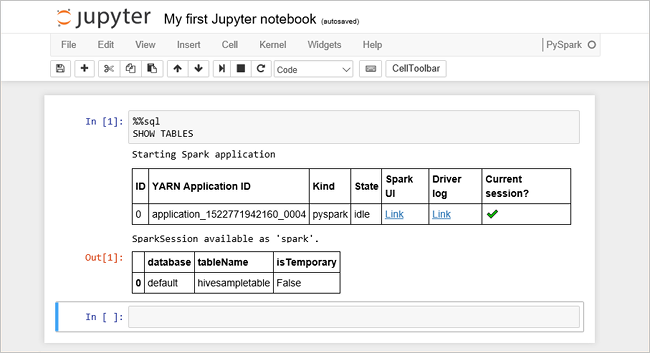 is quickstart." border="true":::
is quickstart." border="true":::Toda vez que você executar uma consulta no Jupyter, o título da janela do navegador da Web mostrará um status (Ocupado) com o título do bloco de anotações. Você também verá um círculo sólido ao lado do texto PySpark no canto superior direito.
Execute outra consulta para ver os dados em
hivesampletable.%%sql SELECT * FROM hivesampletable LIMIT 10A tela deve ser atualizada para mostrar a saída da consulta.
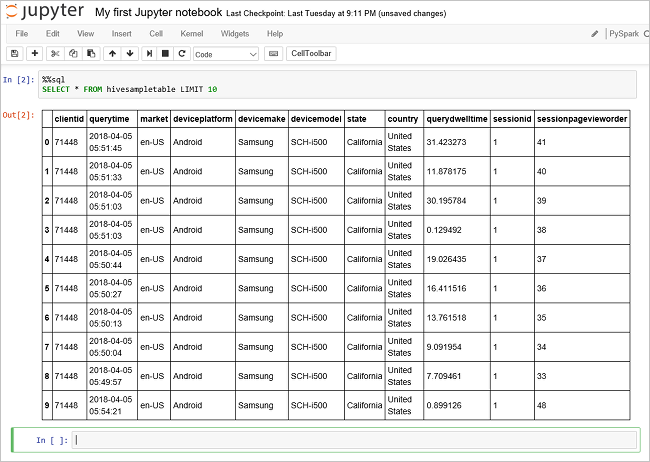 Insight" border="true":::
Insight" border="true":::No menu Arquivo do notebook, selecione Fechar e Interromper. O desligamento do bloco de anotações libera os recursos do cluster.
Limpar os recursos
O HDInsight salva seus dados no Armazenamento do Azure ou no Azure Data Lake Storage, de modo que você possa excluir um cluster com segurança quando ele não estiver em uso. Você também é cobrado por um cluster HDInsight, mesmo quando ele não está em uso. Como os encargos para o cluster são muitas vezes maiores do que os encargos para armazenamento, faz sentido, do ponto de vista econômico, excluir os clusters quando não estiverem em uso. Se você planeja trabalhar no tutorial listado em Próximas etapas imediatamente, convém manter o cluster.
Retorne ao Portal do Azure e selecione Excluir.
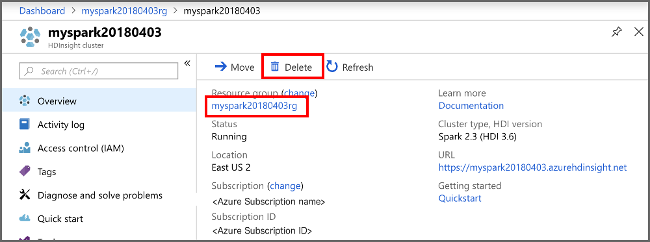 sight cluster" border="true":::
sight cluster" border="true":::
Também é possível selecionar o nome do grupo de recursos para abrir a página do grupo de recursos, e depois selecionar Excluir grupo de recursos. Ao excluir o grupo de recursos, você exclui o cluster HDInsight e a conta de armazenamento padrão.
Próximas etapas
Neste início rápido, você aprendeu a criar um cluster Apache Spark no HDInsight e executar uma consulta SQL básica do Spark. Avance para o próximo tutorial para saber como usar um cluster HDInsight para executar consultas interativas em dados de exemplo.