Componente Avaliar Modelo
Este artigo descreve o componente no Azure Machine Learning Designer.
Use esse componente para medir a precisão de um modelo treinado. Você fornece um conjunto de dados que contém pontuações geradas por um modelo, e o componente Avaliar Modelo calcula um conjunto de métricas de avaliação padrão do setor.
As métricas retornadas por Avaliar modelo dependem do tipo de modelo em avaliação:
- Modelos de classificação
- Modelos de regressão
- Modelos de clustering
Dica
Se a avaliação de modelo for novidade para você, recomendamos a série de vídeos do Dr. Stephen Elston, como parte do curso de aprendizado de máquina da EdX.
Como usar Avaliar modelo
Conecte a saída Conjunto de dados pontuados da saída do conjunto de dados Modelo de pontuação ou Resultado de Atribuir dados aos clusters à porta de entrada esquerda de Avaliar modelo.
Observação
Se usar componentes, como "Selecionar colunas no conjunto de dados", para selecionar parte do conjunto de dados de entrada, verifique se as colunas de rótulo “Real” (usada no treinamento), “Probabilidades pontuadas” e “Rótulos pontuados” existem para calcular métricas, como AUC, Precisão para classificação binária/detecção de anomalias. A coluna de rótulo real e a coluna “Rótulos pontuados” existem para calcular métricas para classificação/regressão multiclasse. A coluna "Atribuições" e as colunas "DistancesToClusterCenter no.X" (X é o índice do centroide, de 0, ..., número de centroides-1) existem para calcular métricas para clustering.
Importante
- Para avaliar os resultados, o conjunto de dados de saída deve conter nomes de coluna de pontuação específicos, que atendem aos requisitos do componente Avaliar Modelo.
- A coluna
Labelsserá considerada como rótulos reais. - Para a tarefa de regressão, o conjunto de dados a ser avaliado precisa ter uma coluna, denominada
Regression Scored Labels, que representa rótulos pontuados. - Para a tarefa de classificação binária, o conjunto de dados a ser avaliado precisa ter duas colunas, chamadas
Binary Class Scored Labels,Binary Class Scored Probabilities, que representam rótulos pontuados e probabilidades, respectivamente. - Para a tarefa de várias classificações, o conjunto de dados a ser avaliado precisa ter uma coluna, denominada
Multi Class Scored Labels, que representa rótulos pontuados. Se as saídas do componente upstream não tiverem essas colunas, você precisará modificá-las de acordo com os requisitos acima.
[Opcional] Conecte a saída Conjunto de dados pontuado da saída de conjunto de dados Modelo de pontuação ou Resultado de Atribuir dados a clusters para o segundo modelo à porta de entrada direita de Avaliar modelo. Você pode comparar facilmente os resultados de dois modelos diferentes nos mesmos dados. Os dois algoritmos de entrada devem ter o mesmo tipo de algoritmo. Ou, você pode comparar pontuações de duas execuções diferentes sobre os mesmos dados com parâmetros diferentes.
Observação
O tipo de algoritmo consulta “Classificação de duas classes”, “Classificação multiclasse”, “Regressão”, “Clustering” em “Algoritmos de aprendizado de máquina”.
Envie o pipeline para gerar as pontuações de avaliação.
Resultados
Depois de executar Avaliar modelo, selecione o componente para abrir o painel de navegação Avaliar Modelo à direita. Depois, escolha a guia Saídas + Logs e, nessa guia, a seção Saída de dados tem vários ícones. O ícone Visualizar tem ícone de gráfico de barra e é a primeira maneira de ver os resultados.
Para a classificação binária, depois de clicar no ícone Visualizar, você poderá visualizar a matriz de confusão binária. Para várias classificações, você pode encontrar o arquivo de plotagem da matriz de confusão na guia Saídas + Logs, como o seguinte:

Se você conectar conjuntos de dados a ambas as entradas de Avaliar modelo, os resultados conterão as métricas para o conjunto de dados ou ambos os modelos. O modelo ou os dados anexados à porta à esquerda são apresentados primeiro no relatório, seguidos pelas métricas do conjunto de dados ou pelo modelo anexado na porta à direita.
Por exemplo, a imagem a seguir representa uma comparação de resultados de dois modelos de clustering criados com os mesmos dados, mas com parâmetros diferentes.
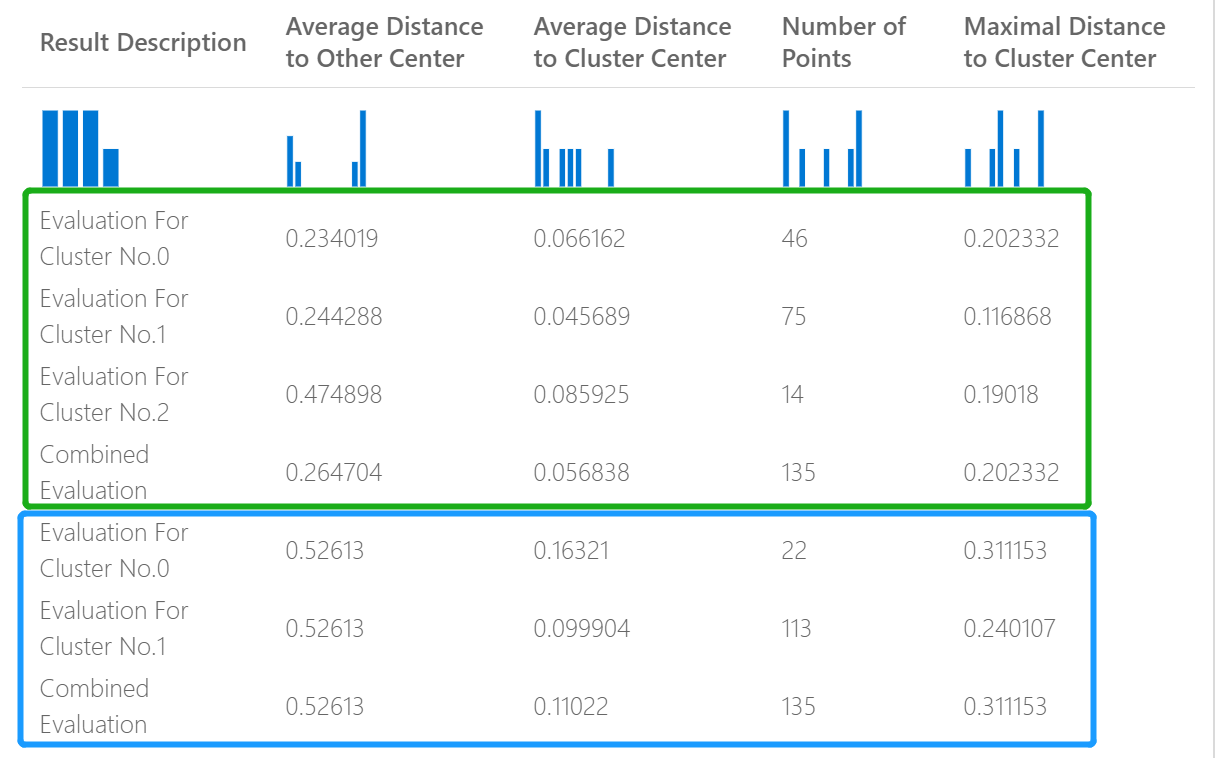
Como esse é um modelo de clustering, os resultados da avaliação são diferentes da comparação de pontuações de dois modelos de regressão ou de dois modelos de classificação. No entanto, a apresentação geral é a mesma.
Métricas
Esta seção descreve as métricas retornadas para os tipos específicos de modelos com suporte para uso com Avaliar modelo:
Métricas para modelos de classificação
As métricas a seguir são relatadas ao avaliar modelos de classificação binária.
Precisão mede a qualidade de um modelo de classificação como a proporção entre os resultados verdadeiros com o total de casos.
A precisão é a proporção entre os resultados verdadeiros com os resultados positivos. Precisão = TP/(TP+FP)
Recall é a fração da quantidade total de instâncias relevantes que foram realmente recuperadas. Recall = TP/(TP+FN)
A medida f é calculada como a média ponderada da precisão e do recall entre 0 e 1, em que a medida f ideal seria 1.
AUC mede a área sob a curva plotada com verdadeiros positivos no eixo y e falsos positivos no eixo x. Essa métrica é útil porque ele fornece um único número que permite comparar modelos de tipos diferentes. AUC tem limite de classificação invariável. Ele mede a qualidade das previsões do modelo, independentemente de qual limite de classificação é escolhido.
Métricas para modelos de regressão
As métricas retornadas para modelos de regressão são projetadas para estimar a quantidade de erros. Um modelo é considerado adequado para os dados se a diferença entre os valores observados e previstos for pequena. No entanto, observar o padrão dos resíduos (a diferença entre qualquer ponto previsto e seu valor real correspondente) pode fornecer muitas informações sobre o desvio potencial de um modelo.
As métricas a seguir são relatadas para avaliar modelos de regressão linear. Outros modelos de regressão, como a Regressão Quantílica Florestal Rápida , podem ter métricas diferentes.
Erro absoluto médio (MAE) mede a distância das previsões dos resultados reais, assim, quanto menor esse valor, melhor.
Raiz do quadrado médio (RMSE) cria um valor único que resume o erro no modelo. Ao elevar a diferença ao quadrado, a métrica desconsidera a diferença entre uma previsão abaixo e uma previsão acima do valor real.
Erro relativo absoluto (RAE) é a diferença relativa absoluta entre os valores esperado e real. Ele é relativo porque a diferença média é dividida pela média aritmética.
Erro relativo ao quadrado (RSE) normaliza similarmente o erro ao quadrado total dos valores previstos ao dividir pelo erro total ao quadrado dos valores reais.
Coeficiente de determinação, frequentemente chamado de R2, representa o poder de previsão do modelo como um valor entre 0 e 1. Zero significa que o modelo é aleatório (não explica nada) e 1 significa que há um ajuste perfeito. No entanto, deve-se ter cuidado ao interpretar valores de R2, pois valores baixos podem ser totalmente normais e valores altos podem ser suspeitos.
Métricas para modelos de clustering
Como os modelos de clustering diferem significativamente dos modelos de classificação e regressão em muitos aspectos, Avaliar modelo também retorna um conjunto diferente de estatísticas para modelos de clustering.
As estatísticas retornadas para um modelo de clustering descrevem quantos pontos de dados foram atribuídos a cada cluster, o valor de separação entre clusters e a densidade dos pontos de dados dentro de cada cluster.
As estatísticas para o modelo de clustering são calculadas em média em todo o conjunto de dados, com linhas adicionais contendo as estatísticas por cluster.
As métricas a seguir são relatadas para avaliar modelos de clustering.
As pontuações na coluna Distância média a outros centros representam a proximidade, em média, de cada ponto no coluna em relação aos centroides de todos os outros clusters.
As pontuações na coluna Distância média ao centro de cluster representam a proximidade de todos os pontos em um cluster ao centroide desse cluster.
A coluna Número de pontos mostra quantos pontos de dados foram atribuídos a cada cluster, juntamente com o número total geral de pontos de dados em qualquer cluster.
Se o número de pontos de dados atribuídos a clusters for menor que o número total de pontos de dados disponíveis, isso significará que não foi possível atribuir os pontos de dados a um cluster.
As pontuações na coluna Distância máxima ao centro do cluster representam a distância máxima entre cada ponto e o centroide do cluster desse ponto.
Se esse número for alto, pode significar que o cluster é amplamente disperso. Você deve examinar essa estatística junto com a Distância média ao centro de cluster para determinar o espalhamento do cluster.
A pontuação Avaliação Combinada na parte inferior de cada seção de resultados lista as pontuações médias dos clusters criados nesse modelo específico.
Próximas etapas
Confira o conjunto de componentes disponíveis no Azure Machine Learning.