Componente Treinar Modelo
Este artigo descreve o componente no designer do Azure Machine Learning.
Use este componente para treinar um modelo de classificação ou regressão. O treinamento ocorre depois que você define um modelo e define seus parâmetros e os dados de marcação necessários. Você também pode usar Treinar Modelo para treinar novamente um modelo existente com novos dados.
Como funciona o processo de treinamento
No Azure Machine Learning, criar e usar um modelo de machine learning normalmente é um processo de três etapas.
Você configura um modelo escolhendo um tipo específico de algoritmo e definindo seus parâmetros ou hiperparâmetros. Escolha um dos seguintes tipos de modelo:
- Modelos de Classificação, com base em redes neurais, árvores de decisão, florestas de decisão e outros algoritmos.
- Modelos de Regressão, que podem incluir regressão linear padrão ou que usam outros algoritmos, incluindo redes neurais e regressão bayesiana.
Forneça um conjunto de dados que seja etiquetado e que seja compatível com o algoritmo. Conecte os dados e o modelo a Treinar Modelo.
O treinamento produz um formato binário específico, o iLearner, que encapsula os padrões estatísticos aprendidos com os dados. Você não pode modificar ou ler diretamente esse formato; no entanto, outros componentes podem usar esse modelo treinado.
Você também pode exibir as propriedades do modelo. Para obter mais informações, consulte a seção Resultados.
Após a conclusão do treinamento, use o modelo treinado com um dos componentes de pontuação para fazer previsões sobre os novos dados.
Como usar Treinar Modelo
Adicione o componente Treinar Modelo ao pipeline. Esse componente pode ser encontrado na categoria Machine Learning. Expanda a opção Treinar e arraste o componente Treinar Modelo para seu pipeline.
Na entrada à esquerda, anexe o modo não treinado. Anexe o conjunto de dados de treinamento na entrada à direita do módulo Treinar Modelo.
O conjuntos de dados de treinamento deve conter uma coluna de etiqueta. Todas as linhas sem etiqueta são ignoradas.
Para Coluna de etiqueta, clique em Editar coluna no painel direito do componente e escolha uma única coluna que contenha resultados que o modelo pode usar para treinamento.
Para problemas de classificação, a coluna de etiqueta deve conter valores categóricos ou valores discretos. Alguns exemplos podem ser uma classificação sim/não, um nome ou código de classificação de doença ou um grupo de renda. Se você escolher uma coluna não-categórica, o componente retornará um erro durante o treinamento.
Para problemas de regressão, a coluna de etiqueta deve conter dados numéricos que representam a variável de resposta. O ideal é que os dados numéricos representem uma escala contínua.
Exemplos podem ser uma pontuação de risco de crédito, o tempo projetado para a falha de um disco rígido ou o número previsto de chamadas para uma central de atendimento em um determinado dia ou hora. Se você não escolher uma coluna numérica, poderá receber um erro.
- Se você não especificar qual coluna de rótulo usar, o Aprendizado de Máquina do Azure tenta inferir qual é a coluna de rótulo apropriada, usando os metadados do conjunto de dados. Se ele escolher a coluna errada, use o seletor de coluna para corrigir.
Dica
Se você tiver problemas ao usar o Seletor de coluna, consulte o artigo Selecionar colunas no conjunto de dados para obter dicas. Ele descreve alguns cenários e dicas comuns para usar as opções WITH RULES e BY NAME.
Envie o pipeline. Se você tiver muitos dados, pode levar algum tempo.
Importante
Se você tiver uma coluna de ID que é a ID de cada linha, ou uma coluna de texto que contém muitos valores exclusivos, Treinar Modelo poderá ocorrer um erro como "Número de valores exclusivos na coluna: "{nome_da_coluna}" é maior que o permitido.
Isso ocorre porque a coluna atingiu o limite de valores exclusivos e pode causar memória insuficiente. Você pode usar Editar Metadados para marcar essa coluna como Desmarcar recurso e ela não será usada no treinamento, ou Extrair recursos N-Gram do componente Texto para pré-processar a coluna de texto. Consulte Código de erro do designer para obter mais detalhes de erro.
Interpretabilidade do modelo
A interpretação de modelo fornece a possibilidade de compreender o modelo do AML e apresentar a base subjacente para tomada de decisões de maneira compreensível para os seres humanos.
Atualmente, o componente Treinar Modelo dá suporte ao uso do pacote de interpretabilidade para explicar os modelos do AML. Há suporte para os seguintes algoritmos internos:
- Regressão Linear
- Regressão de Rede Neural
- Regressão de árvore de decisão aumentada
- Regressão de Floresta de Decisão
- Regressão de Poisson
- Regressão Logística de Duas Classes
- Computador de vetor de suporte de duas classes
- Árvore de decisão aumentada de duas classes
- Floresta de Decisão de Duas Classes
- Floresta de decisão multiclasse
- Regressão logística multiclasse
- Rede neural multiclasse
Para gerar explicações de modelo, você pode selecionar True na lista suspensa da Explicação do Modelo no componente Treinar Modelo. Por padrão, ele é definido como False no componente Treinar Modelo. Observe que a geração de explicações exige custo extra de computação.
Após a execução do pipeline ser concluída, você pode visitar a guia Explicações no painel direito do componente Treinar Modelo e explorar o desempenho do modelo, o conjuntos de dados e a importância do recurso.
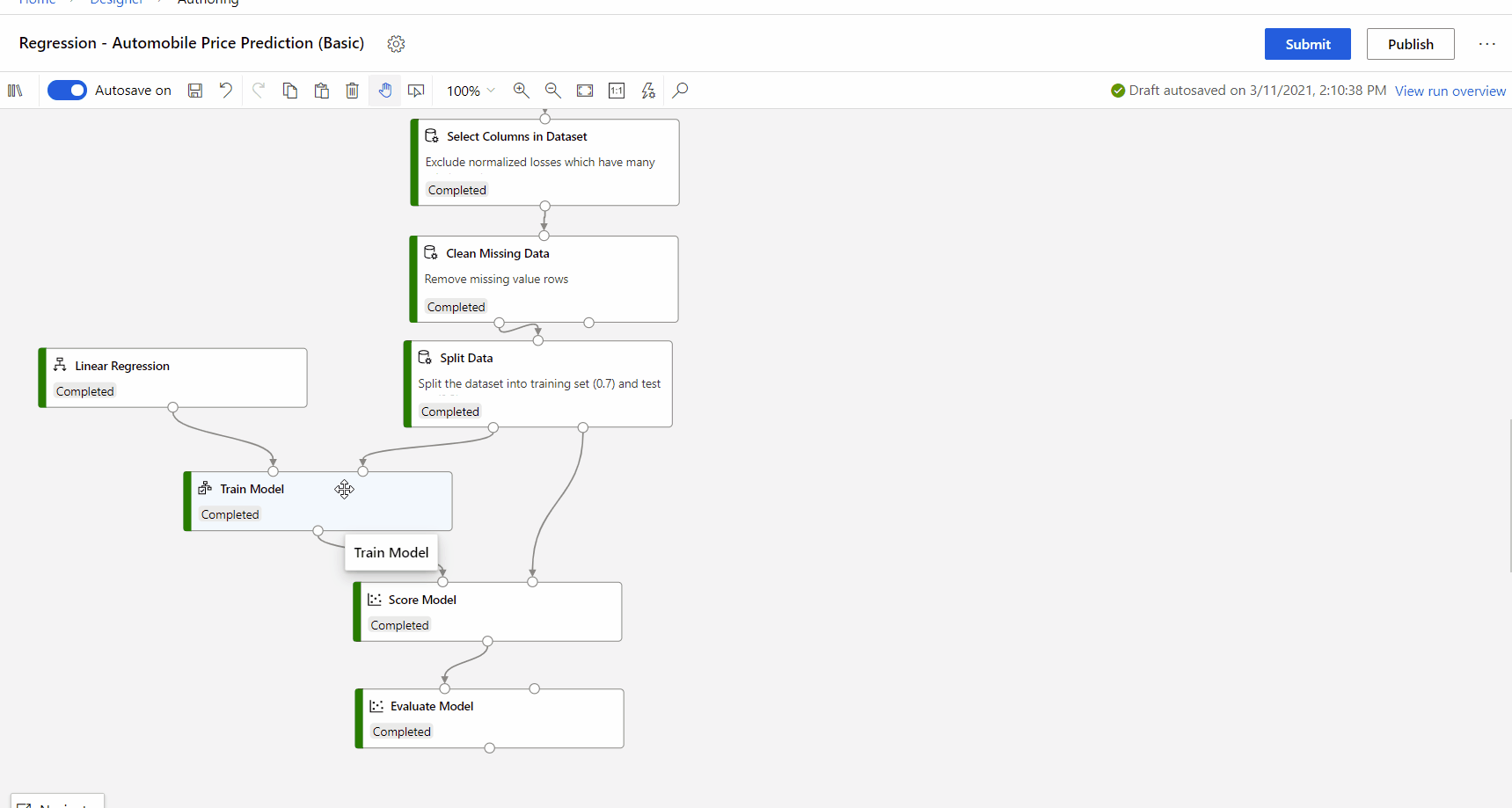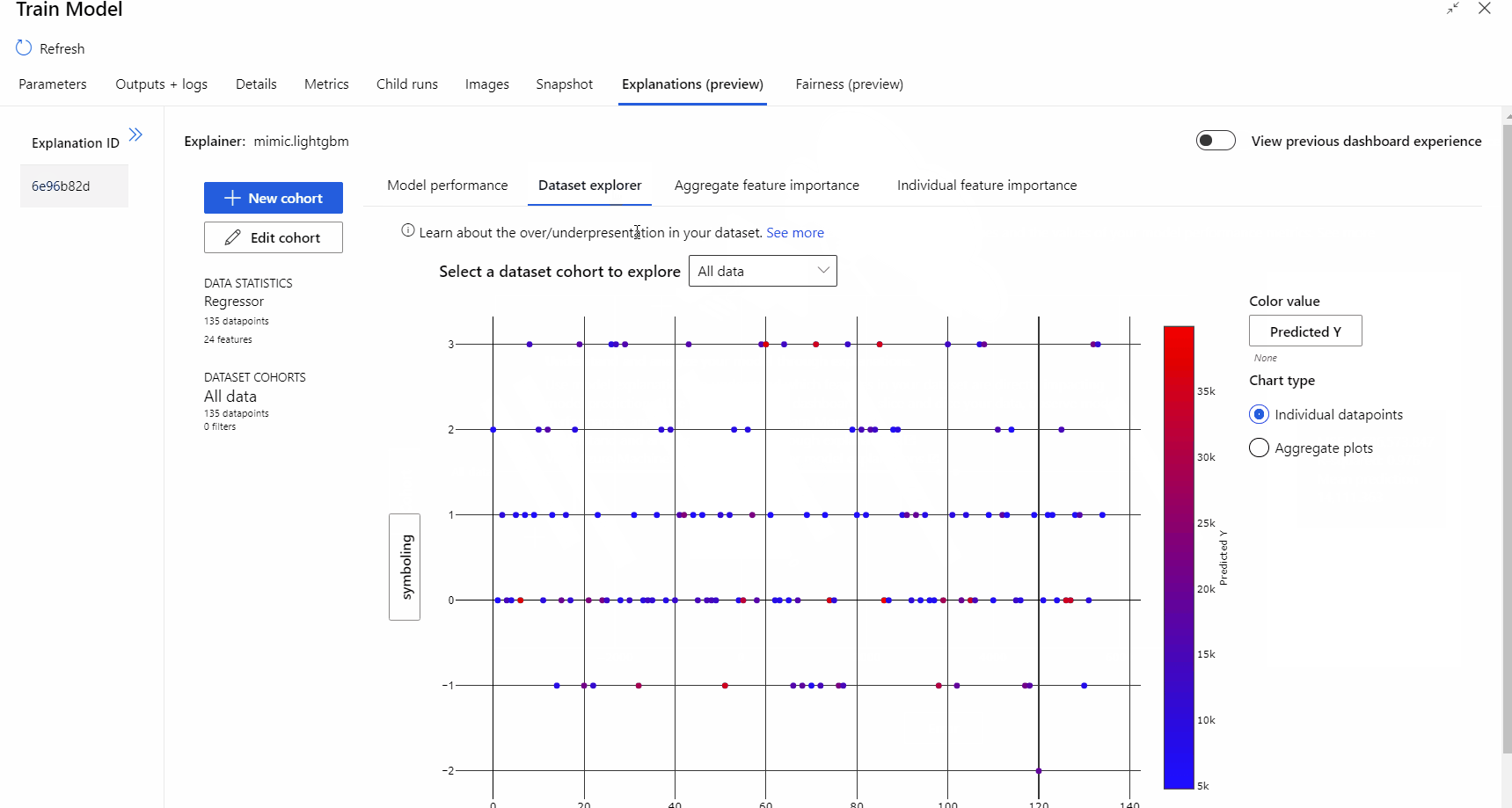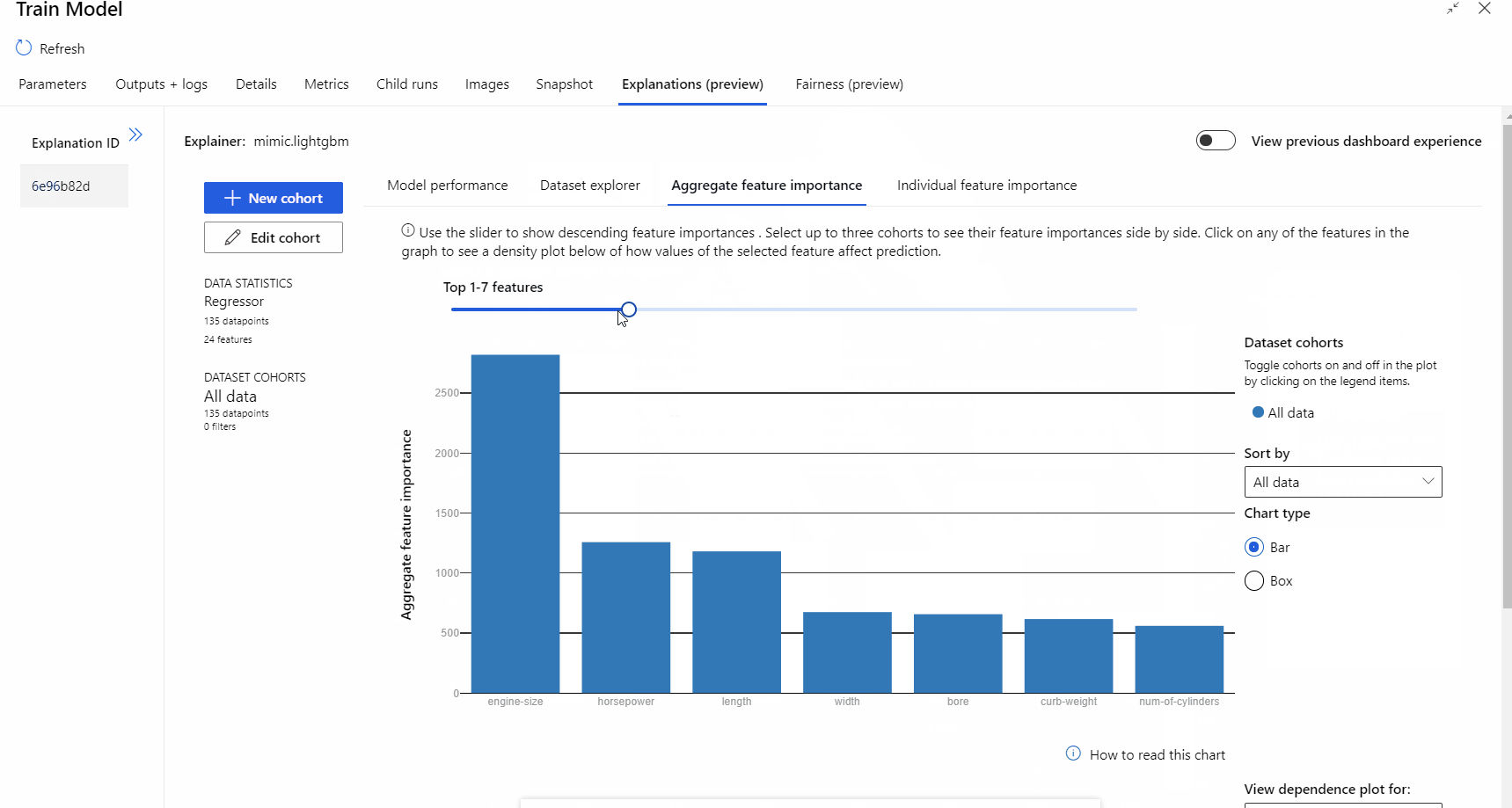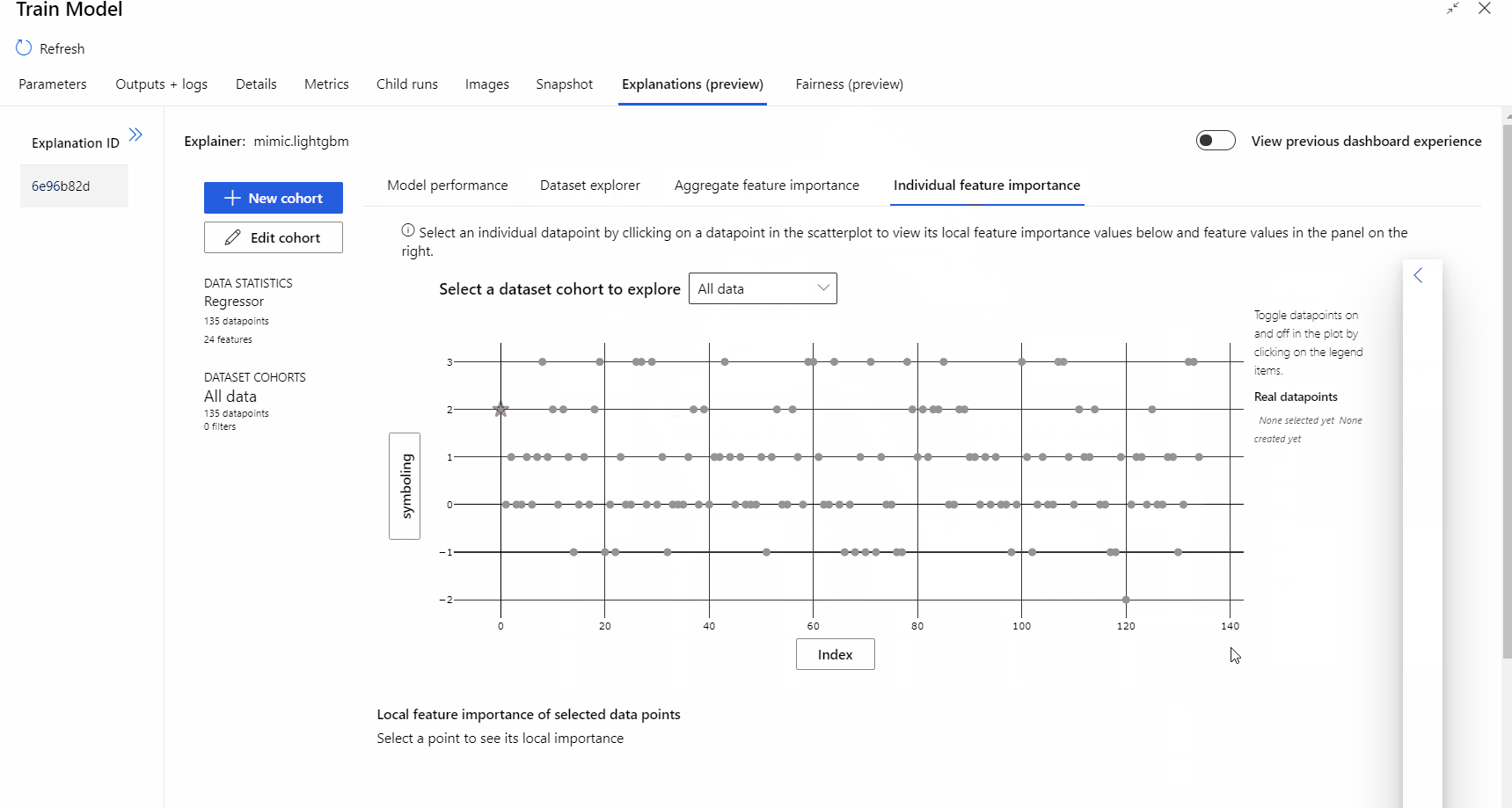
Para saber mais sobre como usar explicações do modelo no Microsoft Azure Machine Learning, consulte o artigo de como Interpretar modelos do AML.
Resultados
Depois que o modelo for treinado:
Para usar o modelo em outros pipelines, selecione o componente e selecione o ícone Registrar o conjunto de dados na guia Saídas no painel direito. Você pode acessar modelos salvos na paleta do componente em Conjuntos de dados.
Para usar o modelo na previsão de novos valores, conecte-o ao componente Modelo de Pontuação, junto com os novos dados de entrada.
Próximas etapas
Confira o conjunto de componentes disponíveis no Azure Machine Learning.