O que é AutoML (machine learning automatizado)?
APLICA-SE A:  SDK do Python azure-ai-ml v2 (atual)
SDK do Python azure-ai-ml v2 (atual)
O machine learning automatizado, também conhecido como ML automatizado ou AutoML, é o processo de automatizar as tarefas demoradas e iterativas do desenvolvimento de modelo de machine learning. Com ele, cientistas de dados, analistas e desenvolvedores podem criar modelos de ML com alta escala, eficiência e produtividade, ao mesmo tempo em que dão suporte à qualidade do modelo. O ML automatizado no Azure Machine Learning se baseia em uma inovação de nossa divisão do Microsoft Research.
- Para clientes experientes em código, SDK do Python do Azure Machine Learning. Introdução ao Tutorial: treinar um modelo de detecção de objetos (versão prévia) com AutoML e o Python.
Como o AutoML funciona?
Durante o treinamento, o Azure Machine Learning cria um número de pipelines em paralelo que experimentam diferentes parâmetros e algoritmos para você. O serviço é iterado por meio de algoritmos de ML emparelhados com seleções de recursos, em que cada iteração produz um modelo com uma pontuação de treinamento. Quanto melhor a pontuação para a métrica para a qual você deseja otimizar, melhor o modelo será considerado para "ajustar" seus dados. Ela vai parar depois que atingir os critérios de saída definidos no experimento.
Usando o Azure Machine Learning, você pode criar e executar seus experimentos de treinamento de ML automatizado com estas etapas:
Identificar o problema de ML a ser resolvido: classificação, previsão, regressão, pesquisa visual computacional ou NLP.
Escolha se deseja ter uma experiência code-first ou uma experiência na Web no estúdio sem código: os usuários que preferem ter uma experiência code-first podem usar o SDK v2 do Azure Machine Learning ou a CLI v2 do Azure Machine Learning. Introdução ao Tutorial: treinar um modelo de detecção de objetos com o AutoML e o Python. Os usuários que preferem uma experiência limitada/sem código podem usar a interface da Web no Estúdio do Azure Machine Learning em https://ml.azure.com. Introdução ao Tutorial: Criar um modelo de classificação com ML automatizado no Azure Machine Learning.
Especificar a origem dos dados de treinamento rotulados: você pode trazer seus dados para o Azure Machine Learning de várias maneiras diferentes.
Configure os parâmetros de machine learning automatizado que determinam quantas iterações em diferentes modelos, configurações de hiperparâmetro, pré-processamento/definição de recursos avançados e quais métricas examinar ao determinar o melhor modelo.
Envie o trabalho de treinamento.
Examine os resultados
O diagrama a seguir ilustra esse processo.
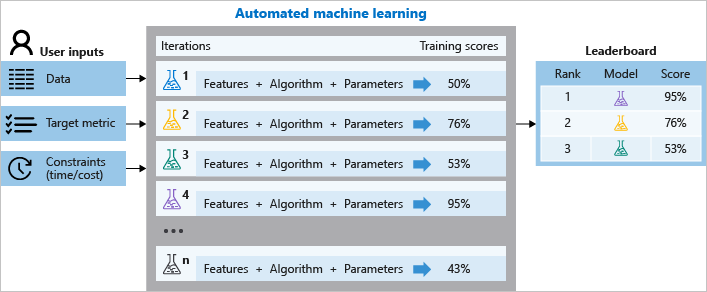
Também é possível inspecionar as informações do trabalho registradas, que contêm métricas coletadas durante a execução dele. O trabalho de treinamento produz um objeto serializado Python (arquivo .pkl) que contém o modelo e o pré-processamento de dados.
Embora a criação de modelos seja automatizada, você também pode saber como são os recursos importantes ou relevantes para os modelos gerados.
Quando usar o AutoML: classificação, regressão, previsão, pesquisa visual computacional e NLP
Aplique o ML automatizado quando quiser que o Azure Machine Learning treine e ajuste um modelo para você usando a métrica de destino especificada. O ML automatizado democratiza o processo de desenvolvimento do modelo de machine learning e capacita os usuário, independentemente do conhecimento em ciência de dados deles, a identificar um pipeline de machine learning de ponta a ponta para qualquer problema.
Profissionais de ML e desenvolvedores de todos os setores podem usar o ML automatizado para:
- Implementar soluções de ML sem conhecimento abrangente de programação
- Economize tempo e recursos
- Aproveite as melhores práticas de ciência de dados
- Fornecer solução de problemas ágil
classificação
A classificação é um tipo de aprendizado supervisionado no qual os modelos aprendem a usar dados de treinamento e aplicam esses aprendizados a novos dados. O Azure Machine Learning oferece personalizações especificamente para essas tarefas, como personalizadores de texto de rede neural profunda para classificação. Saiba mais sobre as opções de definição de recursos. Você também pode encontrar a lista de algoritmos com suporte no AutoML aqui.
A principal meta dos modelos de classificação é prever em quais categorias novos dados se encaixarão com base em aprendizados de dados de treinamento. Exemplos de classificação comuns incluem detecção de fraudes, reconhecimento de manuscrito e detecção de objetos.
Veja um exemplo de classificação e aprendizado de máquina automatizado neste notebook do Python: Marketing bancário.
Regressão
De maneira semelhante à classificação, as tarefas de regressão também são uma tarefa de aprendizado supervisionado comum. O Azure Machine Learning oferece a definição de recursos específica para problemas de regressão. Saiba mais sobre as opções de definição de recursos. Você também pode encontrar a lista de algoritmos com suporte no AutoML aqui.
Diferentemente da classificação em que os valores de saída previstos são categóricos, os modelos de regressão preveem valores de saída numéricos com base em preditores independentes. Na regressão, o objetivo é ajudar a estabelecer a relação entre essas variáveis de preditores independentes estimando como uma variável afeta as outras. Por exemplo, o preço de automóveis baseado em características como gasto de combustível por quilometragem, classificação de segurança etc.
Veja um exemplo de regressão e machine learning automatizado para previsões nestes notebooks do Python: Desempenho do Hardware.
Previsão de série temporal
Criar previsões é uma parte integrante de qualquer negócio, independentemente de ser para receita, inventário, vendas ou demanda do cliente. Você pode usar o ML automatizado para combinar técnicas e abordagens e obter uma previsão de série temporal de alta qualidade recomendada. Você pode encontrar a lista de algoritmos com suporte no AutoML aqui.
Um experimento de série temporal automatizado é tratado como um problema de regressão multivariada. Os valores de série temporal passados são “dinamizados” para se tornarem dimensões adicionais para o regressor junto com outros preditores. Essa abordagem, diferentemente de métodos de série temporal clássicos, tem uma vantagem de incorporar naturalmente muitas variáveis contextuais e a relação delas entre si durante o treinamento. O ML automatizado aprende um modelo único, mas geralmente ramificado internamente, para todos os itens no conjunto de dados e horizontes de previsão. Assim, mais dados estão disponíveis para estimar os parâmetros de modelo e se torna possível fazer generalizações para séries não vistas.
A configuração de previsão avançada inclui:
- detecção de feriados e definição de recursos
- série temporal e aprendizes DNN (Auto-ARIMA, Prophet, ForecastTCN)
- suporte a muitos modelos por meio do agrupamento
- validação cruzada de origem sem interrupção
- retardos configuráveis
- recursos de agregação de janela sem interrupção
Veja um exemplo de previsão e aprendizado de máquina automatizado neste notebook do Python: Demanda de Energia.
Visual computacional
O suporte a tarefas de Pesquisa Visual Computacional permite que você gere com facilidade modelos treinados em dados de imagem para cenários como classificação de imagem e detecção de objetos.
Com esse recurso, você pode:
- Integrar de forma perfeita com a funcionalidade de rotulação de dados do Azure Machine Learning
- Usar dados rotulados para gerar modelos de imagem
- Otimize o desempenho do modelo especificando o algoritmo do modelo e ajustando os hiperparâmetros.
- Baixe ou implante o modelo resultante como um serviço Web no Azure Machine Learning.
- Operacionalize em escala, aproveitando os recursos do Azure Machine Learning de MLOps e Pipelines de ML.
Há suporte para a criação de modelos do AutoML para tarefas de pesquisa visual computacional por meio do SDK do Python para o Azure Machine Learning. Os trabalhos, modelos e saídas de experimentação resultantes podem ser acessados na interface do usuário do estúdio do Azure Machine Learning.
Saiba como Configurar o treinamento do AutoML para modelos de pesquisa visual computacional.
 Imagem de: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
Imagem de: http://cs231n.stanford.edu/slides/2021/lecture_15.pdf
O ML automatizado para imagens dá suporte às seguintes tarefas de pesquisa visual computacional:
| Tarefa | Descrição |
|---|---|
| Classificação de imagem de várias classes | Tarefas em que uma imagem é classificada com apenas um único rótulo de um conjunto de classes – por exemplo, cada imagem é classificada como uma imagem de um "gato" ou um "cachorro" ou "pato" |
| Classificação de imagem de vários rótulos | Tarefas em que uma imagem pode ter um ou mais rótulos de um conjunto de rótulos – por exemplo, uma imagem pode ser rotulada com "gato" e "cachorro" |
| Detecção de objetos | Tarefas para identificar objetos em uma imagem e localizar cada objeto com uma caixa delimitadora, por exemplo, localizar todos os cachorros e gatos em uma imagem e desenhe uma caixa delimitadora em volta de cada um. |
| Segmentação de instâncias | Tarefas para identificar objetos em uma imagem em nível de pixel, desenhando um polígono em volta de cada objeto na imagem. |
Processamento de linguagem natural: NLP
O suporte a tarefas de NLP (processamento da linguagem natural) no ML automatizado permite que você gere com facilidade modelos treinados em dados de texto para classificação de texto e cenários de reconhecimento de entidade nomeada. O SDK do Python no Azure Machine Learning oferece suporte para a criação de modelos de NLP treinados em ML automatizado. Os trabalhos, modelos e saídas de experimentação resultantes podem ser acessados na interface do usuário do estúdio do Azure Machine Learning.
A funcionalidade de NLP dá suporte a:
- Treinamento de NLP em rede neural profunda de ponta a ponta com os modelos de BERT pré-treinados mais recentes
- Integração sem emendas com a rotulagem de dados do Azure Machine Learning
- Usar dados rotulados para gerar modelos de NLP
- Suporte multilíngue com 104 idiomas
- Treinamento distribuído com Horovod
Saiba como configurar o treinamento do AutoML para modelos de NLP.
Dados de treinamento, validação e teste
Com o ML automatizado, você fornece os dados de treinamento para treinar modelos de ML e pode especificar o tipo de validação de modelo a ser executado. O ML automatizado executa a validação do modelo como parte do treinamento. Ou seja, o ML automatizado usa dados de validação para ajustar hiperparâmetros de modelo com base no algoritmo aplicado para encontrar a combinação que melhor se adapta aos dados de treinamento. No entanto, os mesmos dados de validação são usados para cada iteração de ajuste, que apresenta a tendência de avaliação do modelo, pois o modelo continua a melhorar e se ajustar aos dados de validação.
Para ajudar a confirmar que essa tendência não é aplicada ao modelo final recomendado, o ML automatizado suporta o uso de dados de teste para avaliar o modelo final que o ML automatizado recomenda no final do experimento. Quando você fornece dados de teste como parte de sua configuração de experimento do AutoML, esse modelo recomendado é testado por padrão no final do experimento (versão prévia).
Importante
Testar seus modelos com um conjunto de dados de teste para avaliar modelos gerados por ML automatizados é uma versão prévia do recurso. Esse recurso está em versão prévia experimental e pode mudar a qualquer momento.
Saiba como configurar experimentos do AutoML para usar dados de teste (versão prévia) com o SDK ou com o Estúdio do Azure Machine Learning.
Engenharia de recursos
Engenharia de recursos é o processo de usar o conhecimento de domínio dos dados para criar recursos que ajudem os algoritmos de ML a aprender melhor. No Azure Machine Learning, técnicas de colocação em escala e normalização são aplicadas para facilitar a engenharia de recursos. Coletivamente, essas técnicas e a engenharia de recursos são chamadas de definição de recursos.
Para experimentos com machine learning automatizado, a definição de recursos é aplicada automaticamente, mas também pode ser personalizada com base em seus dados. Saiba mais sobre qual definição de recursos está inclusa (SDK v1) e como o AutoML ajuda a evitar o ajuste excessivo e o desequilíbrio de dados nos seus modelos.
Observação
As etapas de definição de recursos de machine learning automatizado (normalização de recursos, manipulação de dados ausentes, conversão de texto em números, etc.) tornam-se parte do modelo subjacente. Ao usar o modelo para previsões, as mesmas etapas de definição de recursos aplicadas durante o treinamento são aplicadas aos dados de entrada automaticamente.
Personalizar a definição de recursos
Técnicas adicionais de engenharia de recursos, como codificação e transformações, também estão disponíveis.
Habilite essa configuração com:
Azure Machine Learning Studio: Habilite a Definição de recursos automática na seção Exibir configuração adicionalcom essas etapas.
SDK do Python: especifique a definição de recursos no objeto de Trabalho do AutoML. Saiba mais sobre como habilitar a definição de recursos.
Modelos do conjunto
O machine learning automatizado dá suporte a modelos ensemble, que são habilitados por padrão. O aprendizado Ensemble aprimora os resultados do machine learning e o desempenho preditivo combinando vários modelos em contraste com o uso de modelos únicos. As iterações do conjunto aparecem como as iterações finais do trabalho. O machine learning automatizado usa métodos Ensemble de votação e empilhamento para combinar modelos:
- Votação: prevê com base na média ponderada das probabilidades de classe previstas (para tarefas de classificação) ou destinos de regressão previstos (para tarefas de regressão).
- Empilhamento: o empilhamento combina modelos heterogêneos e treina um metamodelo com base na saída dos modelos individuais. Os metamodelos padrão atuais são LogisticRegression para tarefas de classificação e ElasticNet para tarefas de regressão/previsão.
O algoritmo de seleção Caruana Ensemble com a inicialização Ensemble classificada é usado para decidir quais modelos usar dentro do Ensemble. Em um alto nível, esse algoritmo Inicializa o Ensemble com até cinco modelos com as melhores pontuações individuais e verifica se esses modelos estão dentro do limite de 5% da melhor pontuação para evitar um Ensemble inicial inadequado. Em seguida, para cada iteração Ensemble, um novo modelo é adicionado ao Ensemble existente e a pontuação resultante é calculada. Se um novo modelo tiver aprimorado a pontuação Ensemble existente, o Ensemble será atualizado para incluir o novo modelo.
Confira o pacote do AutoML para alterar as configurações do Ensemble padrão no machine learning automatizado.
AutoML e ONNX
Com o Azure Machine Learning, você pode usar o ML automatizado para criar um modelo do Python e fazê-lo ser convertido no formato ONNX. Depois que os modelos estiverem no formato ONNX, eles poderão ser executados em vários serviços e plataformas. Saiba mais sobre como acelerar modelos de ML com ONNX.
Veja como converter em formato ONNX neste exemplo de notebook Jupyter. Saiba quais algoritmos têm suporte no ONNX.
O runtime do ONNX também dá suporte ao C#, assim você pode usar o modelo criado automaticamente em seus aplicativos C# sem a necessidade de registrar ou sem nenhuma latência de rede que os pontos de extremidade REST introduzem. Saiba mais sobre como usar um modelo ONNX de AutoML em um aplicativo .NET com ML.NET e os modelos ONNX de inferência com a API de C# do runtime do ONNX.
Próximas etapas
Há vários recursos para que você possa começar a usar o AutoML.
Tutoriais e instruções
Os tutoriais são exemplos introdutórios de ponta a ponta de cenários do AutoML.
Para uma experiência Code First, siga o Tutorial: treinar um modelo de detecção de objetos com AutoML e Python
Para uma experiência Low Code ou No-code, confira o Tutorial: treinar um modelo de classificação com AutoML sem código no Estúdio do Azure Machine Learning.
Artigos de instruções fornecem detalhes adicionais sobre a funcionalidade que o ML automatizado oferece. Por exemplo,
Definir as configurações para testes de treinamento automático
Saiba como treinar modelos de pesquisa visual computacional com o Python.
Saiba como exibir o código gerado de seus modelos de ML automatizado (SDK v1).
Exemplos do Jupyter Notebook
Examine exemplos de código detalhados e casos de uso no Repositório do notebook do GitHub para obter amostras de machine learning automatizado.
Referência do SDK do Python
Aprofunde sua experiência com padrões de design de SDK e especificações de classe com a documentação de referência de classes de Trabalho do AutoML.
Observação
As funcionalidades de machine learning automatizado também estão disponíveis em outras soluções da Microsoft como ML.NET, HDInsight, Power BI e SQL Server