Exemplos nas Máquinas Virtuais de Ciência de Dados
As Máquinas Virtuais de Ciência de Dados do Azure (DSVMs) incluem um conjunto abrangente de código de exemplo. Esses exemplos incluem notebooks e scripts do Jupyter em linguagens como Python e R.
Observação
Para obter mais informações sobre como executar notebooks do Jupyter nas suas máquinas virtuais de ciência de dados, veja a seção Acessar o Jupyter.
Pré-requisitos
Para executar esses exemplos, você deve ter provisionado uma Máquina Virtual de Ciência de Dados Ubuntu.
Exemplos disponíveis
| Categoria de exemplos | Descrição | Locais |
|---|---|---|
| Linguagem Python | Os exemplos explicam cenários como conectar-se a armazenamentos de dados em nuvem baseados no Azure e trabalhar com o Azure Machine Learning. Linguagem Python |
~notebooks |
| Linguagem Julia | Fornece uma descrição detalhada de plotagem e aprendizado profundo no Julia. Também explica como chamar C e Python a partir do Julia. Linguagem Julia |
Windows: ~notebooks/Julia_notebooksLinux: ~notebooks/julia |
| Azure Machine Learning | Ilustra como criar modelos de aprendizado de máquina e de aprendizagem profunda com o Machine Learning. Implante modelos em qualquer lugar. Use aprendizado de máquina automatizado e ajuste de hiperparâmetro inteligente. Use também o gerenciamento de modelos e treinamento distribuído. Machine Learning |
~notebooks/AzureML |
| Notebooks do PyTorch | Exemplos de aprendizagem profunda que usam redes neurais baseadas no PyTorch. Os notebooks vão de cenários iniciantes a avançados. Notebooks do PyTorch |
~notebooks/Deep_learning_frameworks/pytorch |
| TensorFlow | Exemplos de rede neural diferentes e técnicas implementadas usando a estrutura TensorFlow. TensorFlow |
~notebooks/Deep_learning_frameworks/tensorflow |
| H2O | Exemplos baseados no Python que usam o H2O para problemas de situações reais. H2O |
~notebooks/h2o |
| Linguagem SparkML | Exemplo que usam recursos do kit de ferramentas MLLib do Apache Spark por meio do pySpark e do MMLSpark: Microsoft Machine Learning para Apache Spark no Apache Spark 2.x. Linguagem SparkML |
~notebooks/SparkML/pySpark~notebooks/MMLSpark |
| XGBoost | Exemplos padrão de aprendizado de máquina no XGBoost para cenários como classificação e regressão. XGBoost |
Windows: \dsvm\samples\xgboost\demo |
Acessar o Jupyter
Para acessar o Jupyter, selecione o ícone Jupyter no menu da área de trabalho ou do aplicativo. Você também pode acessar o Jupyter em uma edição do Linux de uma DSVM. Para acessar remotamente a partir de um navegador da Web, vá para https://<Full Domain Name or IP Address of the DSVM>:8000 no Ubuntu.
Para adicionar exceções e disponibilizar o acesso ao Jupyter em um navegador, consulte a captura de tela a seguir:
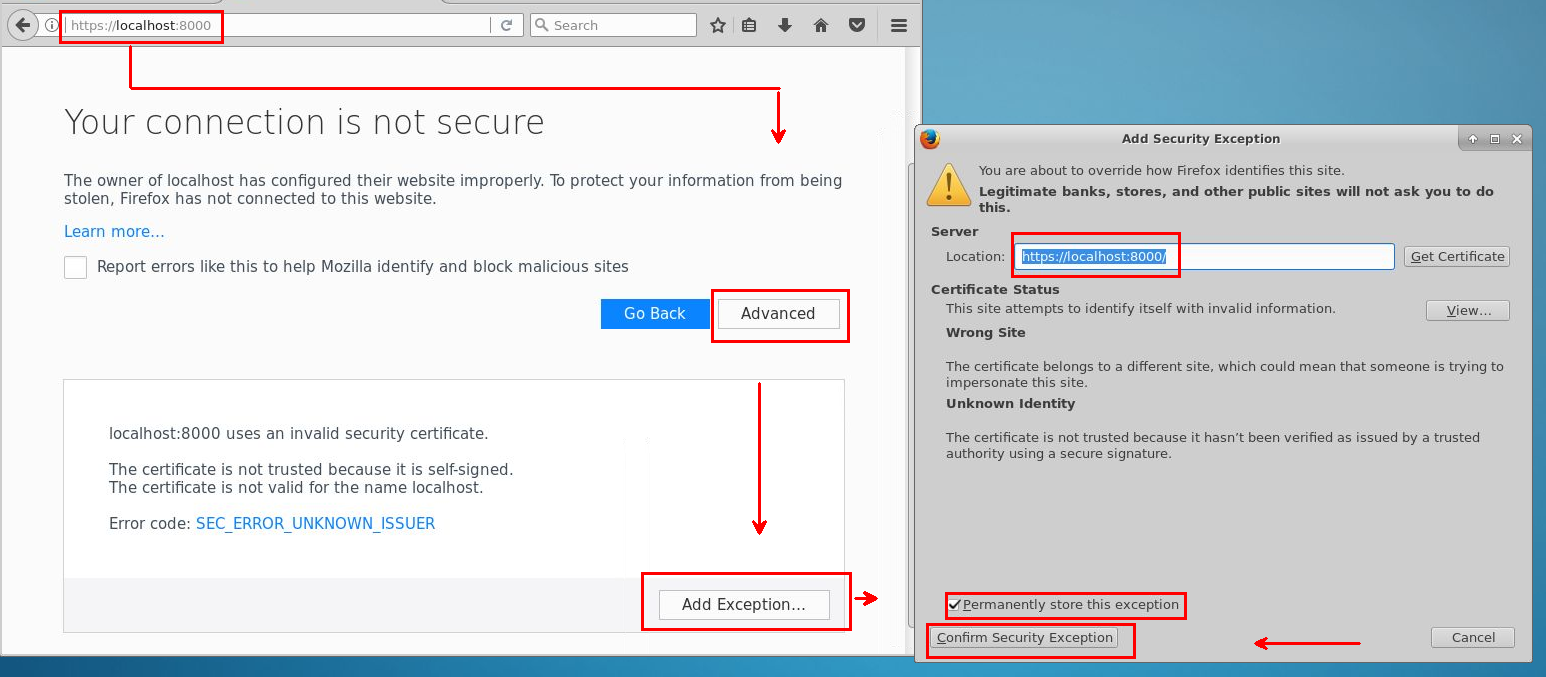
Entre com a mesma senha que você usa para fazer logon na Máquina Virtual de Ciência de Dados.
Página inicial do Jupyter
Linguagem R
Linguagem Python
Linguagem Julia
Azure Machine Learning
PyTorch
TensorFlow

H2O
SparkML
XGBoost