Configurar um ambiente de desenvolvimento com o Azure Databricks e AutoML no Azure Machine Learning
Saiba como configurar um ambiente de desenvolvimento no Azure Machine Learning, que usa Azure Databricks e ML automatizado.
Azure Databricks é ideal para executar fluxos de trabalho de aprendizado de máquina intensivos em grande escala na plataforma de Apache Spark escalonável na nuvem do Azure. Oferece um ambiente colaborativo baseado em Notebook com um cluster de computação baseado em CPU ou GPU.
Para mais informações sobre outros ambientes de desenvolvimento de aprendizado de máquina, consulte Configurar o ambiente de desenvolvimento do Python.
Pré-requisito
Workspace do Azure Machine Learning. Para criar um, siga as etapas no artigo Criar recursos do workspace.
Azure Databricks com Azure Machine Learning e o AutoML
Azure Databricks integra-se ao Azure Machine Learning e às suas funcionalidades de AutoML.
Por que usar o Azure Databricks:
- Para treinar um modelo por meio do Spark MLlib e implantar o modelo no ACI/AKS.
- Com as funcionalidades de machine learning automatizado por meio de um SDK do Azure Machine Learning.
- Como um destino de computação de um pipeline Azure Machine Learning.
Interromper um cluster do Databricks
Criar um cluster do Databricks. Algumas configurações serão aplicadas somente se você instalar o SDK para aprendizado de máquina automatizado no Databricks.
São necessários alguns minutos para criar o cluster.
Use estas configurações:
| Configuração | Aplica-se a | Valor |
|---|---|---|
| Nome do cluster | always | nomedoseucluster |
| Versão do Databricks Runtime | always | 9.1 LTS |
| Versão do Python | always | 3 |
| Tipo de Trabalho (determina o número máximo de iterações simultâneas) |
ML automatizado rápido |
Uma VM otimizada para memória é preferível |
| Trabalhos | always | 2 ou superior |
| Habilitar o dimensionamento automático | ML automatizado rápido |
Desmarcar |
Aguarde até que o cluster está em execução antes de continuar.
Adicionar o SDK do Azure Machine Learning ao Databricks
Depois que o cluster for executado, crie uma biblioteca para anexar o pacote Azure Machine Learning SDK apropriado ao cluster.
Para usar o ML automatizado, vá para Adicionar o SDK do Azure Machine Learning com o AutoML.
Clique com o botão direito do mouse na pasta do espaço de trabalho atual onde você deseja armazenar a biblioteca. Selecione criar>biblioteca.
Dica
Se você tiver uma versão antiga do SDK, anule sua seleção das bibliotecas instaladas do cluster e mova-a para a lixeira. Instale a nova versão do SDK e reinicie o cluster. Se houver um problema depois de reiniciar, desanexe e anexe novamente o cluster.
Escolha a opção a seguir (não há suporte para outras instalações do SDK)
Extras do pacote do SDK Fonte Nome do PyPi Para Databricks Carregar Python Egg ou PyPI azureml-sdk[databricks] Aviso
Nenhum outro adicional do SDK pode ser instalado. Escolha apenas a [
databricks] opção.- Não selecione Anexar automaticamente a todos os clusters.
- Selecione Anexar ao lado do nome do cluster.
Monitorar erros até que o status seja alterado para Anexado, o que pode levar vários minutos. Se esse passo não funcionar:
Tente reiniciar o cluster fazendo o seguinte:
- No painel esquerdo, selecione Clusters.
- Na tabela, selecione o nome do cluster.
- Na guia Bibliotecas, selecione Reiniciar.
Uma instalação bem-sucedida se assemelha ao seguinte:
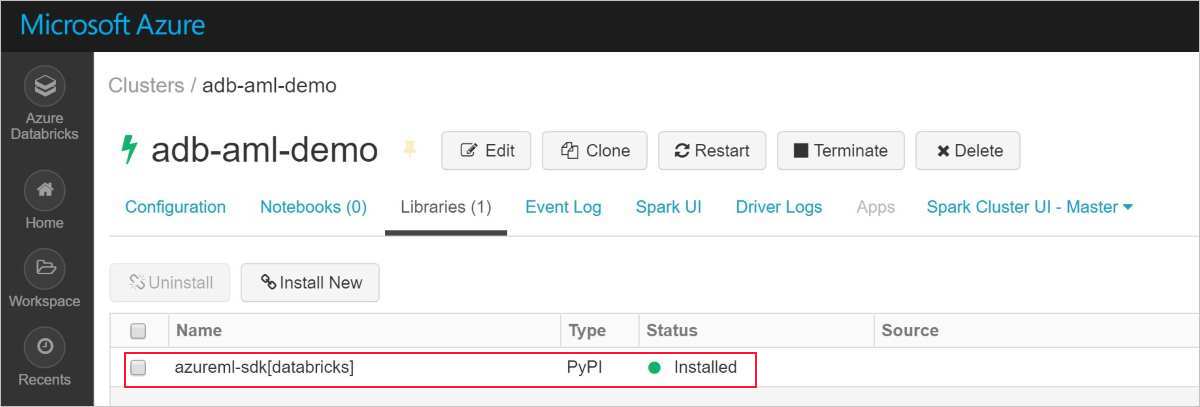
Adicionar o SDK do Azure Machine Learning com o AutoML ao Databricks
Se o cluster foi criado com o Databricks Runtime 7.3 LTS (não o ML), execute o comando a seguir na primeira célula do notebook para instalar o SDK do Azure Machine Learning.
%pip install --upgrade --force-reinstall -r https://aka.ms/automl_linux_requirements.txt
Definições de configuração do AutoML
Na configuração do AutoML, ao usar Azure Databricks, adicione os seguintes parâmetros:
max_concurrent_iterationsé baseado no número de nós de trabalho no cluster.spark_context=scé baseado no contexto padrão do spark.
Notebooks ML que funcionam com Azure Databricks
Experimente:
Embora muitos notebooks de exemplo estão disponíveis, somente esses notebooks de exemplo funcionam com Azure Databricks.
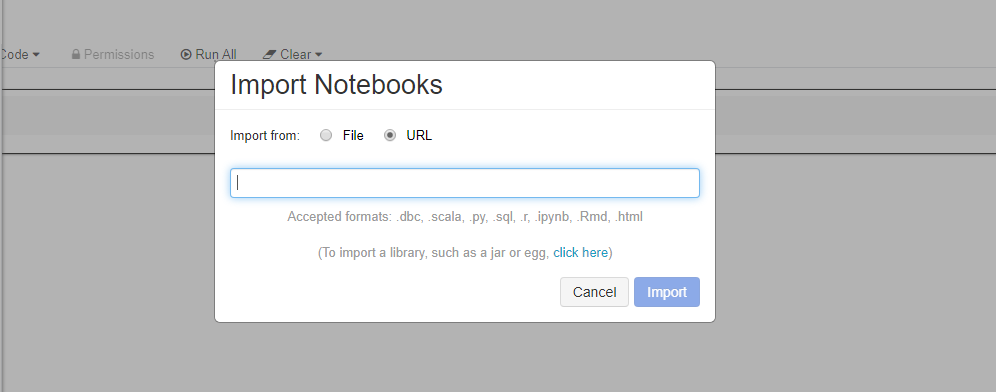
Importe esses exemplos diretamente do espaço de trabalho. Veja abaixo:
Aprenda a criar um pipeline com o Databricks como a computação de treinamento.
Solução de problemas
Se Databricks cancelar uma operação de AutoML: quando você usa recursos automatizados de aprendizado de máquina no Azure Databricks, para cancelar uma executar e iniciar uma nova operação de experimento, reinicie o cluster do Azure Databricks.
Se Databricks>10 ierações para AutoML: em configurações automatizadas de AutoML, se você tiver mais de 10 ierações, configure de
show_outputparaFalsequando você executá-las.Widget do Databricks para o SDK do Azure Machine Learning e AutoML: o widget do SDK do Azure Machine Learning não tem suporte em um notebook do Databricks porque os notebooks não podem analisar widgets HTML. Você pode exibir o widget no portal usando esse código Python em sua célula de notebook Azure Databricks:
displayHTML("<a href={} target='_blank'>Azure Portal: {}</a>".format(local_run.get_portal_url(), local_run.id))Falha na instalação de pacotes
Falhas na instalação do SDK do Azure Machine Learning no Databricks quando mais pacotes são instalados. Alguns pacotes, como
psutil, podem causar conflitos. Para evitar erros de instalação, instale pacotes congelando a versão biblioteca de códigos. Este problema está relacionado ao Databricks e não ao Azure Machine Learning SDK. Você também pode se deparar com esse problema com outras bibliotecas. Exemplo:psutil cryptography==1.5 pyopenssl==16.0.0 ipython==2.2.0Como alternativa, você pode usar scripts de inicialização caso continue tendo problemas de instalação com as bibliotecas de Python. Essa abordagem não tem suporte oficial. Para obter mais informações, consulte Scripts de init com escopo de cluster.
Erro de importação: não é impossível iportar o nome
Timedeltadepandas._libs.tslibs: se você vir esse erro ao usar o AutoML, execute as duas linhas a seguir no notebook:%sh rm -rf /databricks/python/lib/python3.7/site-packages/pandas-0.23.4.dist-info /databricks/python/lib/python3.7/site-packages/pandas %sh /databricks/python/bin/pip install pandas==0.23.4Erro de importação: nenhum módulo chamado 'pandas.core.indexes' :se você vir esse erro ao usar o AutoML:
Execute este comando para instalar dois pacotes no cluster do Azure Databricks:
scikit-learn==0.19.1 pandas==0.22.0Desconectar e, em seguida, reconectar o cluster ao notebook.
Se essas etapas não resolverem o problema, tente reiniciar o cluster.
FailToSendFeather: se você vir um erro
FailToSendFeatherao ler dados no cluster do Azure Databricks, tente o seguinte:- Atualize seu pacote
azureml-sdk[automl]para a versão mais recente. - Adicione a
azureml-dataprepversão 1.1.8 ou superior. - Adicione a
pyarrowversão 0.11 ou superior.
- Atualize seu pacote
Próximas etapas
- Treine e implante um modelo no Azure Machine Learning com o conjunto de dados MNIST.
- Confira a referência do SDK do Azure Machine Learning para Python.