Exemplo: criar e implantar uma habilidade personalizada com o Azure Machine Learning (arquivado)
Este exemplo está arquivado e sem suporte. Ele explicou como criar uma habilidade personalizada usando o Azure Machine Learning para extrair o sentimento baseado em aspecto das revisões. Isso permitiu que a atribuição de sentimentos positivos e negativos na mesma revisão fosse atribuída corretamente a entidades identificadas, como funcionários, sala, lobby ou pool.
Para treinar o modelo de sentimentos baseado em aspectos no Azure Machine Learning, você usará o repositório de receitas nlp. O modelo será então implantado como um ponto de extremidade em um cluster do Kubernetes do Azure. Depois de implantado, o ponto de extremidade é adicionado ao pipeline de enriquecimento como uma habilidade do AML para uso pelo serviço Cognitive Search.
Dois conjuntos de dados são fornecidos. Se você quiser treinar o modelo por conta própria, o arquivo hotel_reviews_1000.csv será necessário. Prefere ignorar a etapa de treinamento? Baixe o hotel_reviews_100.csv.
- Criar uma instância do Azure Cognitive Search
- Criar um Workspace do Azure Machine Learning (o serviço de pesquisa e o workspace devem estar na mesma assinatura)
- Treinar e implantar um modelo em um cluster Kubernetes do Azure
- Vincular um pipeline de enriquecimento de IA ao modelo implantado
- Ingerir a saída do modelo implantado como uma habilidade personalizada
Importante
A habilidade está em versão prévia pública sob os termos de uso complementares. A versão prévia da API REST dá suporte a essa habilidade.
Pré-requisitos
- Assinatura do Azure – obtenha uma assinatura gratuita.
- Serviço Cognitive Search
- Recurso dos Serviços Cognitivos
- Conta de Armazenamento do Azure)
- Workspace do Azure Machine Learning
Instalação
- Clonar ou baixar os conteúdos do repositório de exemplo.
- Extraia o conteúdo se o download for um arquivo zip. Verifique se os arquivos são de leitura/gravação.
- Ao configurar as contas e os serviços do Azure, copie os nomes e as chaves para um arquivo de texto facilmente acessado. Os nomes e as chaves serão adicionados à primeira célula no notebook, em que as variáveis para acessar os serviços do Azure são definidas.
- Se você não estiver familiarizado com Azure Machine Learning e os respectivos requisitos, convém examinar estes documentos antes de começar:
- Configurar um ambiente de desenvolvimento para Azure Machine Learning
- Criar e gerenciar workspaces do Azure Machine Learning no portal do Azure
- Ao configurar o ambiente de desenvolvimento para o Azure Machine Learning, considere o uso da instância de computação baseada em nuvem para uma introdução rápida e fácil.
- Carregue o arquivo do conjunto de dados em um contêiner na conta de armazenamento. O arquivo maior será necessário se você quiser executar a etapa de treinamento no notebook. Se você preferir ignorar a etapa de treinamento, será recomendável usar o arquivo menor.
Abra o notebook e conecte-se aos serviços do Azure
- Coloque dentro da primeira célula todas as informações necessárias para as variáveis que permitirão o acesso aos serviços do Azure e execute essa célula.
- A execução da segunda célula confirmará que você se conectou ao serviço de pesquisa para a assinatura.
- As seções 1,1 a 1,5 criarão o indexador, o índice, o conjunto de habilidades e o armazenamento de dados de serviços de pesquisa.
Neste ponto, você pode optar por ignorar as etapas para criar o conjunto de dados de treinamento e experimentar no Azure Machine Learning, bem como ignorar diretamente o registro dos dois modelos fornecidos na pasta de modelos do repositório GitHub. Se você ignorar essas etapas, no notebook, você passará direto para a seção 3.5, Escrever um script de pontuação. Isso economizará tempo; as etapas de download e upload de dados podem levar até 30 minutos para ser concluídas.
Como criar e treinar os modelos
A seção 2 tem seis células que baixam o arquivo de incorporações GloVe do repositório de receitas NLP. Após o download, o arquivo é carregado para o armazenamento de dados do Azure Machine Learning. O arquivo .zip é sobre 2G e levará algum tempo para executar essas tarefas. Depois de carregado, os dados de treinamento são então extraídos e agora você está pronto para passar para a seção 3.
Treinar o modelo de sentimentos baseado em aspectos e implantar seu ponto de extremidade
A seção 3 do notebook treinará os modelos que foram criados na seção 2, registrará esses modelos e os implantará como um ponto de extremidade em um cluster Kubernetes do Azure. Se você não estiver familiarizado com o Kubernetes do Azure, é altamente recomendável examinar os seguintes artigos antes de tentar criar um cluster de inferência:
- Visão geral do serviço de Kubernetes do Azure
- Conceitos de Kubernetes para o serviço de Kubernetes do Azure (AKS)
- Cotas, restrições de tamanho de máquina virtual e disponibilidade de região no AKS (Serviço de Kubernetes do Azure)
O processo de criação e implantação do cluster de inferência pode levar até 30 minutos. É recomendável testar o serviço Web antes de passar para as etapas finais, atualizar seu conjunto de habilidades e executar o indexador.
Atualizar o conjunto de habilidades
A seção 4 do notebook tem quatro células que atualizam o conjunto de habilidades e o indexador. Como alternativa, você pode usar o portal para selecionar e aplicar a nova habilidade ao conjunto de habilidades e, em seguida, executar o indexador para atualizar o serviço de pesquisa.
No portal, acesse o conjunto de habilidades e selecione o link Definição do Conjunto de Habilidades (JSON). O portal exibirá o JSON do seu conjunto de habilidades que foi criado nas primeiras células do notebook. À direita da exibição, há um menu suspenso em que você pode selecionar o modelo de definição de habilidade. Selecione o modelo do AML (Azure Machine Learning). Forneça o nome do workspace do Azure ML e o ponto de extremidade para o modelo implantado no cluster de inferência. O modelo será atualizado com o URI e a chave do ponto de extremidade.
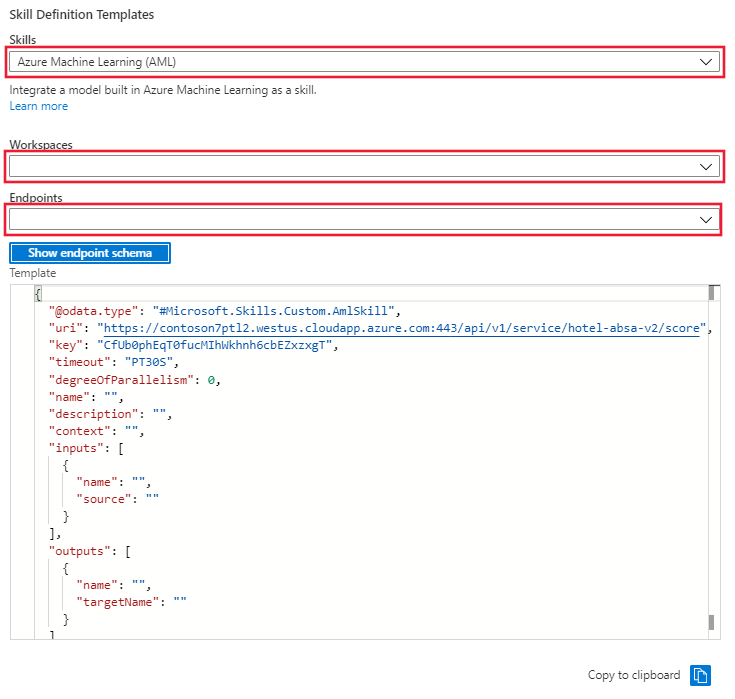
Copie o modelo do conjunto de habilidades da janela e cole-o na definição de conjunto de habilidades à esquerda. Edite o modelo para fornecer os valores ausentes para:
- Nome
- Descrição
- Contexto
- Nome e origem de "inputs"
- Nome e targetName de "outputs"
Salve o conjunto de habilidades.
Depois de salvar o conjunto de habilidades, vá para o indexador e selecione o link Definição do Indexador (JSON). O portal exibirá o JSON do indexador que foi criado nas primeiras células do notebook. Os mapeamentos de campo de saída precisarão ser atualizados com mapeamentos de campo adicionais para garantir que o indexador possa tratá-los e passá-los corretamente. Salve as alterações e, em seguida, selecione Executar.
Limpar os recursos
Quando você está trabalhando em sua própria assinatura, é uma boa ideia identificar, no final de um projeto, se você ainda precisa dos recursos criados. Recursos deixados em execução podem custar dinheiro. Você pode excluir os recursos individualmente ou excluir o grupo de recursos para excluir todo o conjunto de recursos.
Você pode localizar e gerenciar recursos no portal usando o link Todos os recursos ou Grupos de recursos no painel de navegação à esquerda.
Se você estiver usando um serviço gratuito, estará limitado a três índices, indexadores e fontes de dados. Você pode excluir itens individuais no portal para permanecer abaixo do limite.