Enriquecimento de IA na IA do Azure Search
Na Pesquisa de IA do Azure, enriquecimento de IA refere-se à integração com serviços de IA do Azure para processar o conteúdo não pesquisável em sua forma bruta. Através de enriquecimento, análise e inferência são usados para criar conteúdo pesquisável e estrutura onde não existia anteriormente.
Como a Pesquisa de IA do Azure é uma solução de busca em vetores e texto, o objetivo do enriquecimento de IA é melhorar a utilidade do seu conteúdo em cenários relacionados à pesquisa. O conteúdo de origem deve ser textual (não é possível enriquecer vetores), mas o conteúdo criado por um pipeline de enriquecimento pode ser vetorizado e indexado em um índice vetorial usando habilidades como habilidade de divisão de texto para fragmentação e habilidade AzureOpenAIEmbedding para codificação.
O enriquecimento de IA é baseado em habilidades.
As habilidades incorporadas utilizam os serviços de IA do Azure. Eles aplicam as seguintes transformações e processamento ao conteúdo bruto:
- Tradução e a detecção de idioma para pesquisa multilíngue
- Reconhecimento de entidades para extrair nomes de pessoas, lugares e outras entidades de grandes partes do texto
- Extração de frases-chave para identificar e gerar termos importantes
- Reconhecimento Óptico de Caracteres (OCR) para reconhecer texto impresso e manuscrito em arquivos binários
- Análise de imagem para descrever o conteúdo da imagem e gerar as descrições como campos de texto pesquisáveis
As habilidades personalizadas executam seu código externo. As habilidades personalizadas podem ser usadas para qualquer processamento personalizado que você queira incluir no pipeline.
O enriquecimento de IA é uma extensão de um pipeline do indexador que se conecta às fontes de dados do Azure. Um pipeline de enriquecimento tem todos os componentes de um pipeline de indexador (indexador, fonte de dados, índice), além de um conjunto de habilidades que especifica as etapas de enriquecimento atômico.
O diagrama a seguir mostra a progressão do enriquecimento de IA:
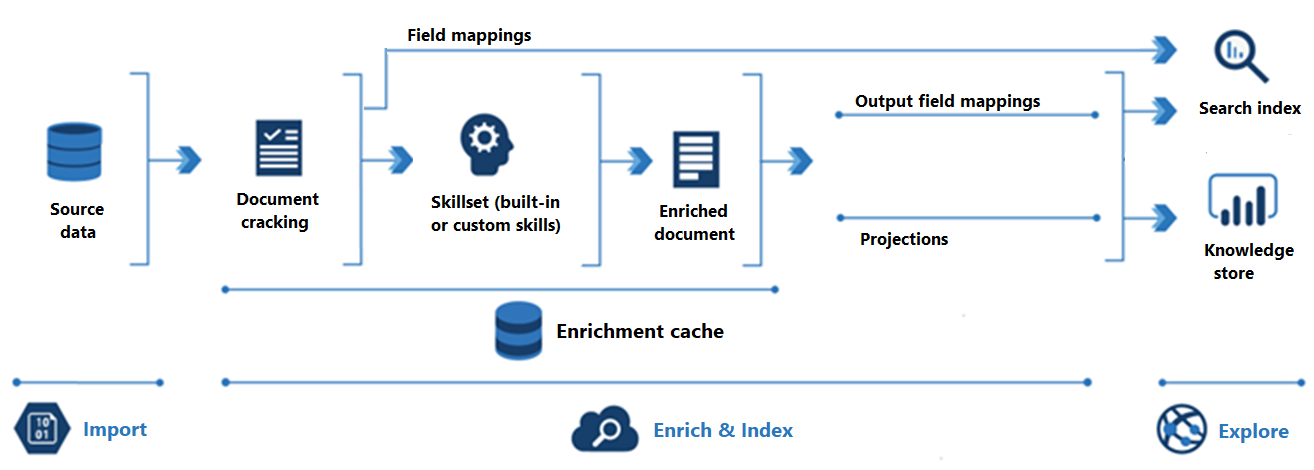
A importação é a primeira etapa. Aqui, o indexador se conecta a uma fonte de dados e efetua pull do conteúdo (documentos) para o serviço de pesquisa. O Armazenamento de Blobs do Azure é o recurso mais comum usado em cenários de enriquecimento de IA, mas qualquer fonte de dados com suporte pode fornecer conteúdo.
Enriquecer e Indexar cobre a maior parte do pipeline de enriquecimento de IA:
O enriquecimento começa quando o indexador "decifra documentos" e extrai imagens e texto. O tipo de processamento que ocorre a seguir depende dos seus dados e de quais habilidades foram adicionadas a um conjunto de habilidades. Se você tiver imagens, elas poderão ser encaminhadas para as habilidades que processam a imagem. O conteúdo de texto está na fila para processamento de texto e linguagem natural. Internamente, as habilidades criam um “documento enriquecido” que coleta as transformações conforme elas ocorrem.
O conteúdo enriquecido é gerado durante a execução do conjunto de habilidades e é temporário, a menos que você o salve. Você pode habilitar um cache de enriquecimento para persistir documentos quebrados e saídas de habilidades para reutilização subsequente durante execuções futuras do conjunto de habilidades.
Para obter conteúdo em um índice de pesquisa, o indexador deve ter informações de mapeamento para enviar conteúdo enriquecido para o campo de destino. Mapeamentos de campo (explícitos ou implícitos) definem o caminho de dados dos dados de origem para um índice de pesquisa. Mapeamentos de campo de saída definem o caminho de dados de documentos enriquecidos para um índice.
A indexação é o processo em que o conteúdo bruto e enriquecido é ingerido nas estruturas de dados físicas em um índice de pesquisa (seus arquivos e pastas). A análise lexical e a tokenização ocorrem nesta etapa.
A exploração é a última etapa. A saída é sempre um índice de pesquisa que pode ser consultado de um aplicativo cliente. Opcionalmente, a saída pode ser um repositório de conhecimento que consiste em blobs e tabelas no Armazenamento do Microsoft Azure que são acessados pelas ferramentas de exploração de dados ou processos downstream. Se você estiver criando um repositório de conhecimento, as projeções determinarão o caminho de dados para conteúdo enriquecido. O mesmo conteúdo enriquecido pode aparecer em índices e repositórios de conhecimento.
Quando usar o enriquecimento de IA
O enriquecimento é útil se o conteúdo bruto for texto não estruturado, conteúdo de imagem ou conteúdo que precise de detecção e tradução de idioma. A aplicação de AI por meio de habilidades internas pode possibilitar o uso desse conteúdo para aplicativos de pesquisa de texto completo e ciência de dados.
Você também pode criar habilidades personalizadas para fornecer processamento externo. É possível integrar código aberto, de terceiros ou interno ao pipeline como uma habilidade personalizada. Modelos de classificação que identificam características distintas de vários tipos de documento se enquadram nessa categoria, mas é possível usar qualquer pacote externo que adiciona valor ao conteúdo.
Casos de uso para habilidades internas
As habilidades internas são baseadas nas APIs dos serviços de IA do Azure: Pesquisa Visual Computacional de IA do Azure e do Serviço de linguagem. A menos que sua entrada de conteúdo seja pequena, espere anexar um recurso de IA do Azure Search faturável para executar cargas de trabalho maiores.
Um conjunto de habilidades composto de habilidades internas é adequado para os seguintes cenários de aplicativo:
As habilidades de processamento de imagens incluem Reconhecimento Óptico de Caracteres (OCR) e identificação de recursos visuais, como detecção facial, interpretação de imagem, reconhecimento da imagem (pessoas e lugares famosos) ou atributos como cores ou orientação da imagem. Essas habilidades criam representações de texto de conteúdo de imagem para pesquisa de texto completo na IA do Azure Search.
A tradução automática é fornecida pela habilidade de tradução de texto, geralmente usada em conjunto com a detecção de idioma em soluções para vários idiomas.
O processamento de linguagem natural analisa partes do texto. As habilidades nessa categoria incluem Reconhecimento de Entidade, Detecção de Sentimento (incluindo mineração de opinião) e Detecção de Informações Identificáveis Pessoais. Com essas habilidades, o texto não estruturado pode ser mapeado como campos pesquisáveis e filtráveis em um índice.
Casos de uso para habilidades personalizadas
As Habilidades personalizadas executam código externo fornecido e encapsulado na interface da Web de habilidades personalizada. Vários exemplos de habilidades personalizadas podem ser encontrados no repositório GitHub azure-search-power-skills.
As habilidades personalizadas nem sempre são complexas. Por exemplo, se você tem um pacote que fornece correspondência de padrões ou um modelo de classificação de documentos, pode encapsulá-lo em uma habilidade personalizada.
Armazenamento de saída
Na IA do Azure Search, um indexador salva a saída que criar. Uma única execução de indexador pode criar até três estruturas de dados com saída enriquecida e indexada.
| Armazenamento de dados | Obrigatório | Location | Descrição |
|---|---|---|---|
| índice pesquisável | Obrigatório | Serviço Search | Usado para pesquisa de texto completo e outros formulários de consulta. A especificação de um índice é um requisito do indexador. O conteúdo do índice é preenchido a partir de saídas de habilidades, além de todos os campos de origem mapeados diretamente para os campos no índice. |
| repositório de conhecimento | Opcional | Armazenamento do Azure | Usado para aplicativos downstream, como mineração de conhecimento ou ciência de dados. Um repositório de conhecimento é definido por um conjunto de qualificações. Essa definição determina se os documentos enriquecidos são projetados como tabelas ou objetos (arquivos ou blobs) no Armazenamento do Microsoft Azure. |
| cache de enriquecimento | Opcional | Armazenamento do Azure | Usado para enriquecimentos de cache para reutilização em execuções subsequentes do conjunto de habilidades. O cache armazena conteúdo importado e não processado (documentos decifrados). Ele também armazena os documentos enriquecidos criados durante a execução do conjunto de habilidades. O armazenamento em cache é útil quando você está usando análise de imagem ou OCR e que economizar o tempo e as despesas de reprocessamento de arquivos de imagem. |
Os índices e os repositórios de conhecimento são totalmente independentes entre si. Embora seja necessário anexar um índice para cumprir os requisitos do indexador, se o seu único objetivo for ter um repositório de conhecimento, você poderá ignorar esse índice depois que ele for preenchido.
Explorando o conteúdo
Depois de definir e carregar um índice depesquisa ou um repositório de conhecimento, você poderá explorar seus dados.
Consultar um índice de pesquisa
Execute consultas para acessar o conteúdo enriquecido gerado pelo pipeline. O índice é como qualquer outro item que você cria na IA do Azure Search: é possível complementar análises de texto com analisadores personalizados, invocar consultas de pesquisa difusa, adicionar filtros ou fazer experimentos com perfis de pontuação para ajustar a relevância da pesquisa.
Usar ferramentas de exploração de dados em um repositório de conhecimento
No Armazenamento do Microsoft Azure, um repositório de conhecimento pode assumir duas formas: um contêiner de blob de documento JSON, um contêiner de blob de objetos de imagem ou tabelas no Armazenamento de Tabelas. É possível usar o Gerenciador de Armazenamento, o Power BI ou qualquer aplicativo que se conecte ao Armazenamento do Azure para acessar seu conteúdo.
Um contêiner de blob captura documentos enriquecidos em sua totalidade, o que é útil se você estiver criando um feed em outros processos.
A tabela é útil se você precisar de fatias de documentos enriquecidos ou se quiser incluir ou excluir partes específicas da saída. Para análise no Power BI, as tabelas são a fonte de dados recomendada para exploração e visualização de dados.
Disponibilidade e preços
O enriquecimento está disponível em regiões que têm serviços de IA do Azure. Você pode verificar a disponibilidade do enriquecimento na página Produtos do Azure disponíveis por região.
A cobrança segue um modelo de preços pagamento conforme o uso. Os custos do uso de habilidades integrados são informados quando uma chave de serviços de IA do Azure de várias regiões é especificada no conjunto de habilidades. Também há custos associados à extração de imagem, conforme o cálculo da IA do Azure Search. Mas a extração de texto e as habilidades de utilitário não são cobradas. Para obter mais informações, consulte Como é cobrado o serviço de IA do Azure Search.
Lista de verificação: um fluxo de trabalho típico
Um pipeline de enriquecimento consiste em indexadores que têm habilidades. Após a indexação, você pode consultar um índice para validar seus resultados.
Comece com um subconjunto de dados em uma fonte de dados com suporte. O design de indexador e conjunto de habilidades é um processo iterativo. O trabalho é mais rápido com um pequeno conjunto de dados representativo.
Criar uma fonte de dados que especifique uma conexão com os seus dados.
Criar um conjunto de habilidades. Você deve anexar um recurso de vários serviços de IA do Azure, a menos que seu projeto seja pequeno. Se você estiver criando um repositório de conhecimento, defina-o dentro do conjunto de habilidades.
Criar um esquema de índice que defina um índice de pesquisa.
Crie e execute o indexador para colocar todos os componentes acima juntos. Esta etapa recupera os dados, executa o conjunto de habilidades e carrega o índice.
Um indexador também é onde você especifica mapeamentos de campo e mapeamentos de campo de saída que configuram o caminho de dados para um índice de pesquisa.
Opcionalmente, habilite o cache de enriquecimento na configuração do indexador. Esta etapa permite que os enriquecimentos existentes sejam reutilizados posteriormente.
Execute consultas para avaliar resultados ou iniciar uma sessão de depuração para resolver problemas de conjunto de habilidades.
Para repetir alguma das etapas acima, redefina o indexador antes da execução. Ou exclua e recrie os objetos em cada execução (recomendado se você estiver usando a camada de serviço gratuita). Se você tiver habilitado o cache, o indexador efetuará pull do cache se os dados não forem alterados na origem e se as edições no pipeline não invalidarem o cache.