Escolher uma camada de serviço para a IA do Azure Search
Parte da criação de um serviço de pesquisa é escolher um tipo de preço (ou SKU) corrigido para o tempo de vida do serviço. No portal, a camada é especificada na página Selecionar tipo de preço quando você cria o serviço. Se você estiver provisionando por meio do PowerShell ou da CLI do Azure, a camada será especificada por meio do parâmetro -Sku
A camada selecionada determina:
- O número máximo de índices e outros objetos permitidos no serviço.
- Tamanho e velocidade de partições (armazenamento físico)
- A taxa faturável como custo mensal fixo, mas também um custo incremental se você adicionar capacidade.
Em algumas instâncias, a camada escolhida determina a disponibilidade dos recursos Premium.
Os preços – ou o custo mensal estimado de execução do serviço – são mostrados na página Selecionar tipo de preço do portal. Verifique o preço do serviço para saber mais sobre os custos estimados.
Observação
Os serviços de pesquisa criados após 3 de abril de 2024 têm partições maiores e cotas de vetores mais altas em quase todas as camadas. Para saber mais, confira Limites do serviço.
Descrições de camada
As camadas são: Gratuito, Básico, Standard e Otimizado para Armazenamento. O Standard e Otimizado para Armazenamento estão disponíveis com várias configurações e capacidades. A captura de tela a seguir do portal do Azure mostra as camadas disponíveis, menos os preços (que você pode encontrar no portal e na página de preços).
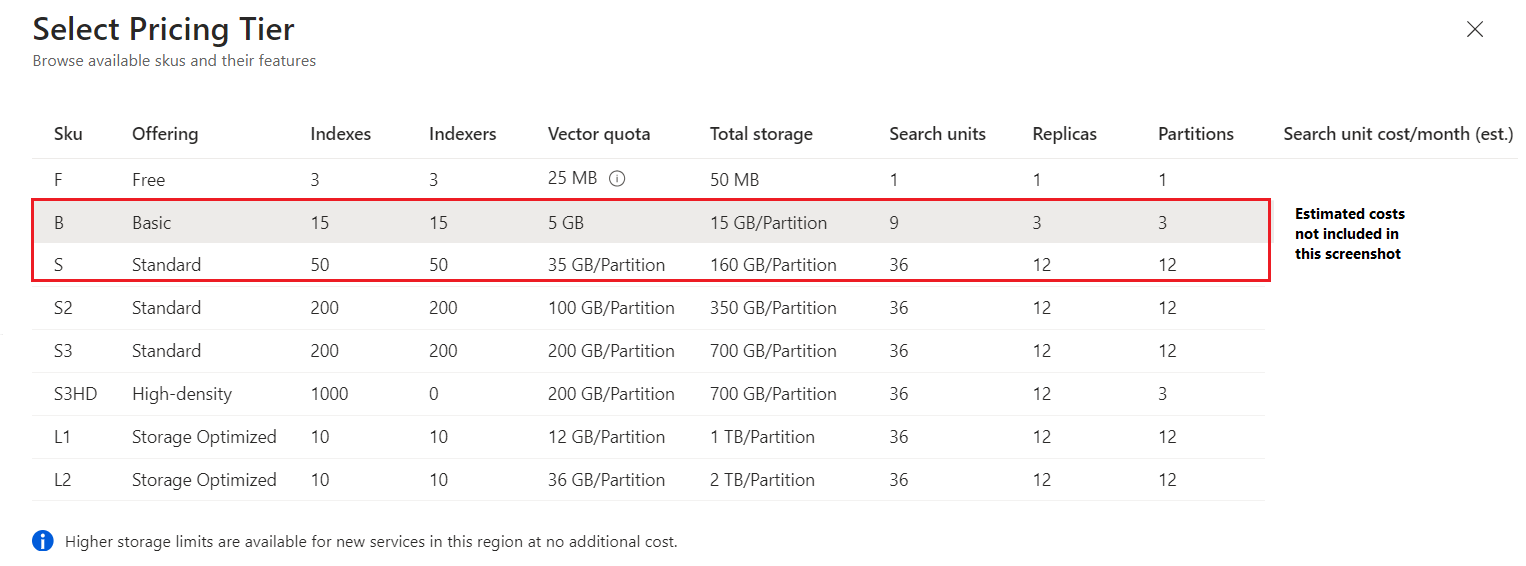
Gratuito cria um serviço de pesquisa limitado para projetos menores, como a execução de tutoriais e exemplos de código. Internamente, os recursos do sistema são compartilhados entre vários assinantes. Você não pode dimensionar um serviço gratuito ou executar cargas de trabalho significativas. Você pode ter um serviço de pesquisa gratuito por assinatura do Azure.
As camadas faturáveis mais usadas incluem o seguinte:
Básico tem a capacidade de atender ao SLA com suporte para três réplicas.
Standard (S1, S2, S3) é o padrão. Isso oferece mais flexibilidade no dimensionamento das cargas de trabalho. Você pode escalar partições e réplicas. Com recursos dedicados sob seu controle, é possível implantar projetos maiores, otimizar o desempenho e aumentar a capacidade.
Algumas camadas são projetadas para determinados tipos de trabalho:
Standard 3 High Density (S3 HD) é um modo de hospedagem para S3, em que o hardware subjacente é otimizado para um grande número de índices menores e se destina a cenários de multilocação. O S3 HD tem o mesmo preço por unidade que S3, mas o hardware é otimizado para leituras rápidas de arquivos em um grande número de índices menores.
As camadas Otimizado para armazenamento (L1, L2) oferecem maior capacidade de armazenamento a um preço menor por TB do que as camadas Standard. Essas camadas são projetadas para índices grandes que não mudam com muita frequência. A principal vantagem é maior latência de consulta, que você deve validar para os requisitos de aplicativo específicos.
Saiba mais sobre as várias camadas na página de preços, no artigo Limites de serviço na IA do Azure Search, e na página do portal quando você estiver provisionando um serviço.
Disponibilidade de recursos por camada
A maioria dos recursos está disponível em todas as camadas, incluindo a camada gratuita. Em alguns casos, a camada determina a disponibilidade de um recurso. A tabela a seguir descreve as restrições.
| Recurso | Limitações |
|---|---|
| Indexadores | Os indexadores não estão disponíveis no S3 HD. Os indexadores têm mais limitações na camada gratuita. |
| Enriquecimento de IA | É executado na camada gratuita, mas não é recomendado. |
| Identidades gerenciadas ou confiáveis para acesso de saída (indexador) | Não disponível na camada gratuita. |
| Chaves de criptografia gerenciadas pelo cliente | Não disponível na camada gratuita. |
| Acesso de firewall de IP | Não disponível na camada gratuita. |
| Ponto de extremidade privado (integração com o Link Privado do Azure) | Para conexões de entrada para um serviço de pesquisa, não disponível na camada gratuita. Para conexões de saída de indexadores com outros recursos do Azure, não disponível em Gratuito ou S3 HD. Para indexadores que usam conjuntos de habilidades, não disponível em Gratuito, Básico, S1 ou S3 HD. |
| Zonas de Disponibilidade | Não disponível na camada Gratuita ou Básica. |
| Classificador semântico | Não disponível na camada gratuita. |
Recursos com uso intensivo de funcionalidades podem não funcionar bem, a menos que você forneça capacidade suficiente. Por exemplo, o Enriquecimento de IA tem habilidades de longa execução que atingirão o tempo limite em um serviço Gratuito, a menos que o conjunto de dados seja pequeno.
Limites superiores
As camadas determinam o armazenamento máximo do serviço propriamente dito, bem como o número máximo de índices, indexadores, fontes de dados, conjuntos de habilidades e mapas de sinônimos que você pode criar. Para obter uma interrupção completa de todos os limites, consulte Limites de serviço na IA do Azure Search.
Tamanho e velocidade da partição
O preço da camada inclui detalhes sobre o armazenamento por partição, que varia de 15 GB para camadas Básico a 2 TB para camadas Otimizadas para Armazenamento (L2). Outras características de hardware, como velocidade de operações, latência e taxas de transferência, não são publicadas, mas as camadas projetadas para arquiteturas de solução específicas são criadas em hardware que tem os recursos para dar suporte a esses cenários. Para obter mais informações sobre partições, consulte Estimar e gerenciar a capacidade e Confiabilidade na IA do Azure Search.
Taxas de cobrança
As camadas têm taxas de cobrança diferentes, com taxas mais altas para camadas que são executadas em hardware mais caro ou fornecem recursos mais caros. A taxa de cobrança da camada pode ser encontrada nas páginas de preços do Azure para a Pesquisa de IA do Azure.
Depois de criar um serviço, a taxa de cobrança torna-se um custo fixo de execução ininterrupta do serviço, e um custo incremental se você optar por adicionar mais capacidade.
Os serviços de pesquisa são recursos de computação alocados como partições (para armazenamento) e réplicas (instâncias do mecanismo de consulta). Inicialmente, um serviço é criado com um de cada, e a taxa de cobrança inclui os dois recursos. No entanto, se você dimensionar a capacidade, os custos aumentarão ou reduzirão em incrementos da taxa faturável.
O exemplo a seguir ilustra esse cenário. Imagine uma taxa de cobrança hipotética de US$ 100 por mês. Se você mantiver o serviço de pesquisa em sua capacidade inicial de uma partição e uma réplica, US$ 100 será o que você pode esperar pagar no final do mês. No entanto, se você adicionar mais duas réplicas para obter alta disponibilidade, a fatura mensal aumentará para US$ 300 (US$ 100 para o primeiro par de partição e réplica e US$ 200 para as duas réplicas).
Esse modelo de cobrança se baseia no conceito de aplicação da taxa de cobrança ao número de UAs (unidades de pesquisa) usadas por um serviço de pesquisa. Todos os serviços são inicialmente provisionados em uma UA, mas você pode aumentar o UAs adicionando partições ou réplicas para lidar com cargas de trabalho maiores. Para saber mais, confira Como estimar os custos de um serviço de pesquisa.
Atualização ou downgrade de camada
Não há suporte interno para atualizar ou fazer downgrade das camadas. Se você quiser mudar para uma camada diferente, a abordagem será:
Crie um novo serviço de pesquisa na nova camada.
Implante o conteúdo da sua pesquisa no novo serviço. Siga esta lista de verificação para verificar se você tem todo o conteúdo.
Exclua o antigo serviço de pesquisa quando tiver certeza de que ele não é mais necessário.
Nos índices grandes que você não quer recompilar do zero, considere usar a amostra de backup e restauração para movê-los.
Próximas etapas
A melhor maneira de escolher um tipo de preço é começar com uma camada de menor custo e, em seguida, fazer testes para tomar a decisão de manter o serviço ou criar outro em uma camada superior. Nas próximas etapas, é recomendável criar um serviço de pesquisa em uma camada acomode o nível de teste que você se propõe a fazer e, em seguida, examinar nas diretrizes a seguir as recomendações sobre como estimar o custo e a capacidade.