Particionar Reliable Services do Service Fabric
Este artigo fornece uma introdução aos conceitos básicos de particionamento de Reliable Services do Azure Service Fabric. O particionamento permite o armazenamento de dados em computadores locais para que dados e computação sejam dimensionados juntos.
Dica
Um exemplo completo do código neste artigo está disponível no GitHub.
Particionamento
O particionamento não é exclusivo para o Service Fabric. Na verdade, é um padrão núcleo da criação de serviços escalonáveis. Em um sentido mais amplo, podemos pensar em particionamento como um conceito de divisão de estado (dados) e computar unidades menores acessíveis para melhorar o desempenho e a escalabilidade. Uma forma bem conhecida de particionamento é o particionamento de dados, também conhecido como fragmentação.
Particionar serviços sem estado do Service Fabric
Para serviços sem estado, você pode pensar em uma partição como uma unidade lógica que contém uma ou mais instâncias de um serviço. A Figura 1 mostra um serviço sem estado com cinco instâncias distribuídas em um cluster usando uma partição.
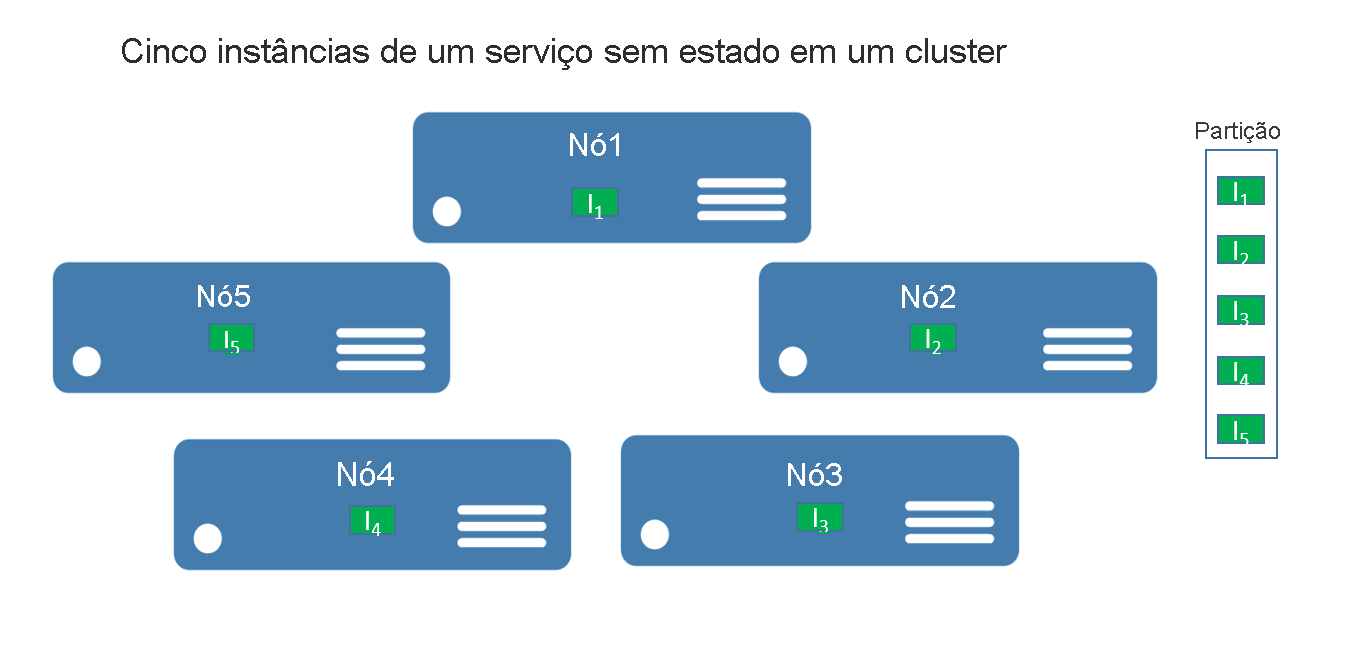
Há realmente dois tipos de soluções de serviço sem estado. O primeiro é um serviço que mantém o estado externamente, por exemplo, em um banco de dados no Banco de Dados SQL do Azure (como um site que armazena dados e informações de sessão). A segunda são serviços apenas de computação (como uma calculadora ou a criação de miniaturas imagem) que não gerenciam nenhum estado persistente.
Em ambos os casos o particionamento de um serviço sem estado é um cenário muito raro – a escalabilidade e disponibilidade normalmente são obtidas pela adição de mais instâncias. As únicas vezes em que você deve considerar várias partições para instâncias de serviço sem estado é quando precisar atender a solicitações especiais de roteamento.
Por exemplo, considere um caso em que os usuários com IDs de um determinado intervalo só devem ser atendidos por uma instância de determinado serviço. Outro exemplo de quando é possível particionar um serviço sem estado é quando você tem um back-end realmente particionado (por exemplo, um banco de dados fragmentado no Banco de Dados SQL) e você deseja controlar qual instância de serviço deve gravar o fragmento do banco de dados ou executar outras tarefas de preparação dentro do serviço sem estado que requer as mesmas informações de particionamento como usadas no back-end. Esses tipos de cenários também podem ser resolvidos de diferentes maneiras e não exigem, necessariamente, particionamento de serviço.
O restante deste passo a passo se concentra nos serviços sem estado.
Particionar serviços com estado do Service Fabric
A Malha de Serviço facilita o desenvolvimento serviços com estado escalonáveis, oferecendo uma ótima forma para o estado de partição (dados). Conceitualmente, uma partição de um serviço com estado é uma unidade de escala altamente confiável por meio de réplicas distribuídas e balanceadas entre os nós de um cluster.
No contexto dos serviços com estado do Service Fabric, o particionamento se refere ao processo de determinar que uma partição de serviço específica é responsável por uma parte do estado completo do serviço. (Conforme mencionado anteriormente, uma partição é um conjunto de réplicas). Uma grande vantagem do Service Fabric é que ele coloca as partições em nós diferentes. Isso permite aumentar o limite de recursos do nó. Conforme os dados precisam crescer, as partições crescem e o Service Fabric redistribui as partições entre os nós. Isso garante o uso contínuo eficiente dos recursos de hardware.
Para dar um exemplo, digamos que você comece com um cluster de cinco nós e um serviço configurado para ter 10 partições e um destino de três réplicas. Nesse caso, o Service Fabric deveria balancear e distribuir as réplicas no cluster e – você acabaria com duas réplicas principais por nó. Caso você precise escalar horizontalmente nosso cluster para 10 nós, o Service Fabric rebalanceará as réplicas principais entre todos os 10 nós. Da mesma forma, se você dimensionar para cinco nós, o Service Fabric rebalanceará todas as réplicas entre todos os cinco nós.
A Figura 2 mostra a distribuição de 10 partições antes e depois do dimensionamento do cluster.

Como resultado a expansão é atingida pois as solicitações de clientes são distribuídas entre computadores, o desempenho geral do aplicativo é aprimorado e a contenção no acesso a partes de dados é reduzida.
Plano de particionamento
Antes de implementar um serviço, você sempre deve considerar a estratégia de particionamento necessária para escalar. Há diferentes maneiras, mas todas elas se concentram no que o aplicativo precisa alcançar. Para o contexto deste artigo, vamos considerar alguns dos aspectos mais importantes.
Uma boa abordagem é pensar sobre a estrutura do estado que precisará ser particionado como a primeira etapa.
Veja abaixo um exemplo simples Se você fosse criar um serviço em uma pesquisa regional, poderia criar uma partição de cada cidade na região. Em seguida, poderia armazenar os votos para cada pessoa na cidade na partição que corresponde à cidade. A Figura 3 ilustra um conjunto de pessoas e a cidade em que residem.
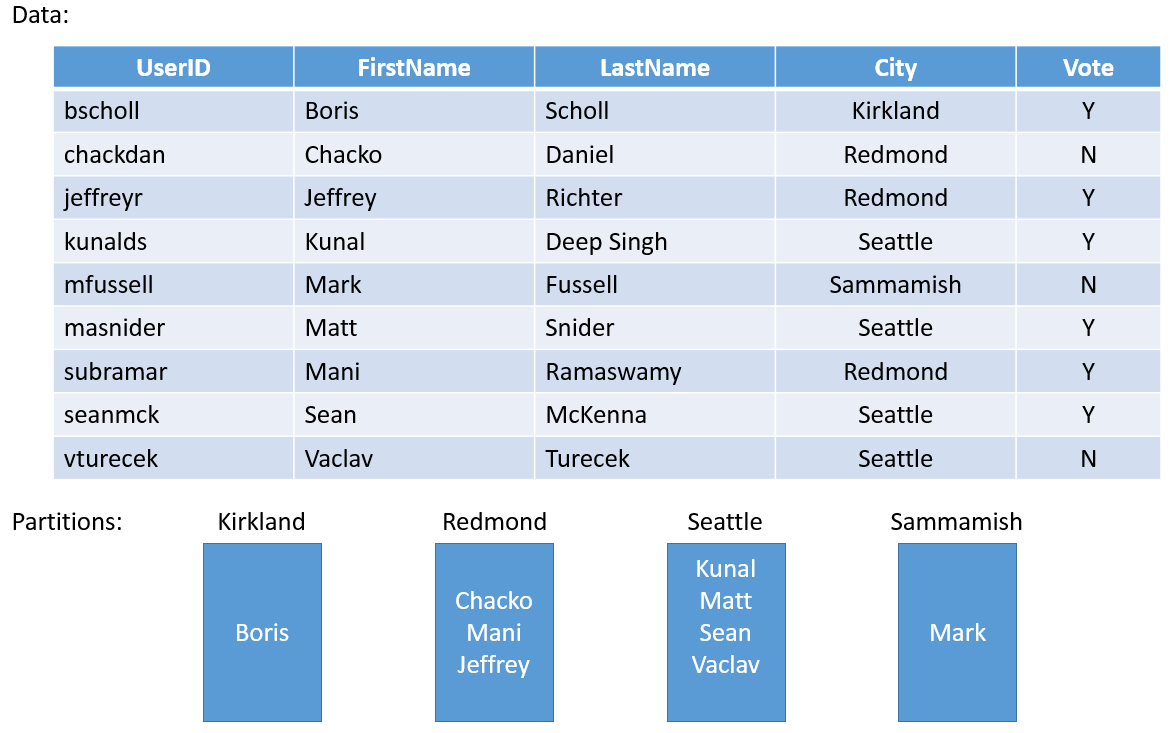
Como a população das cidades varia muito, você poderia acabar com algumas partições que contêm muitos dados (por exemplo, Seattle) e outras partições com muito pouco estado (por exemplo, Kirkland). Então, qual é o impacto de ter partições com quantidades irregulares de estado?
Se você pensar sobre o exemplo novamente, poderá facilmente ver que a partição que contém os votos de Seattle obterá mais tráfego do que a de Kirkland. Por padrão, o Service Fabric garante que haja aproximadamente o mesmo número de réplicas primárias e secundárias em cada nó. Assim, você pode acabar com nós que hospedam réplicas que atendem a mais tráfego e outras que atendem a menos tráfego. Você deve, de preferência, evitar pontos altos e baixos assim em um cluster.
Para evitar isso, você deve realizar duas ações do ponto de vista de particionamento:
- Tente particionar o estado que ele seja distribuído igualmente entre todas as partições.
- Relatar carga de cada uma das réplicas para o serviço. (Para obter informações sobre como fazer isso, leia este artigo sobre métricas e carga). A Service Fabric oferece a capacidade de relatar a carga consumida por serviços, como a quantidade de memória ou o número de registros. Com base nas métricas relatadas, o Service Fabric detecta que algumas partições estão atendendo a cargas mais altas que outras e faz um novo balanceamento do cluster, movendo réplicas para nós mais adequados de modo que, no geral, nenhum nó seja sobrecarregado.
Às vezes, você não tem como saber quantos dados haverá em uma determinada partição. Uma recomendação geral é realizar ambas as ações – primeiro, adotar uma estratégia de particionamento que distribua os dados uniformemente entre as partições; segundo, relatar a carga. O primeiro método impede as situações descritas no exemplo de votação, enquanto o segundo ajuda a amenizar diferenças temporárias no acesso ou carga ao longo do tempo.
Outro aspecto do planejamento de partição é escolher o número correto de partições para começar. Do ponto de vista do Service Fabric, não há nada que impeça começar com um número de partições maior do o previsto para o cenário. Na verdade, suponha que o número máximo de partições seja uma abordagem válida.
Em casos raros, você acabará precisando de mais partições do que escolheu inicialmente. Como você não pode alterar a contagem de partições após o fato, precisará aplicar algumas abordagens de partição avançadas, como criar uma nova instância de serviço do mesmo tipo de serviço. Você também precisaria implementar alguma lógica no lado do cliente que encaminhe as solicitações para a instância de serviço correta, com base no conhecimento do lado do cliente que o seu código de cliente deve manter.
Outra consideração de planejamento de particionamento são os recursos disponíveis do computador. Como o estado precisa ser acessado e armazenados, você deve fazer o seguinte:
- Limites de largura de banda de rede
- Limites de memória do sistema
- Limites de armazenamento de disco
O que acontece se você tiver restrições de recursos em um cluster em execução? A resposta é que você pode simplesmente escalar horizontalmente o cluster para acomodar os novos requisitos.
O guia de planejamento de capacidade oferece orientação sobre como determinar a quantidade necessária de nós no cluster.
Introdução ao particionamento
Esta seção descreve como começar com o particionamento do seu serviço.
O Service Fabric oferece uma variedade de três esquemas de partição:
- Intervalo de particionamento (também conhecido como UniformInt64Partition).
- Particionamento nomeado. Aplicativos que usam esse modelo geralmente têm dados em bucket, dentro de um conjunto limitado. Alguns exemplos comuns de campos de dados usados como chaves de partição nomeada seriam regiões, códigos postais, grupos de clientes ou outros limites de negócios.
- Particionamento de singleton. Partições de singleton normalmente são usadas quando o serviço não requer qualquer roteamento adicional. Por exemplo, serviços sem estado usam esse esquema de particionamento por padrão.
Os esquemas de particionamento Singleton e Nomeado são formulários especiais de partições de intervalos. Por padrão os modelos do Visual Studio para o Service Fabric usam o particionamento nomeado, já que é o mais comum e o mais útil. O restante deste artigo se concentra no esquema de particionamento por intervalo.
Esquema de particionamento por intervalos
Usado para especificar um intervalo inteiro (identificado por uma chave alta e uma chave baixa) e um várias partições (n). Cria n partições, cada uma responsável por um subintervalo sem sobreposição do intervalo de chave de partição geral. Por exemplo, um esquema de particionamento por intervalos com uma chave baixa de 0, uma chave de alta de 99 e uma contagem de 4 criaria quatro partições, conforme mostrado abaixo.
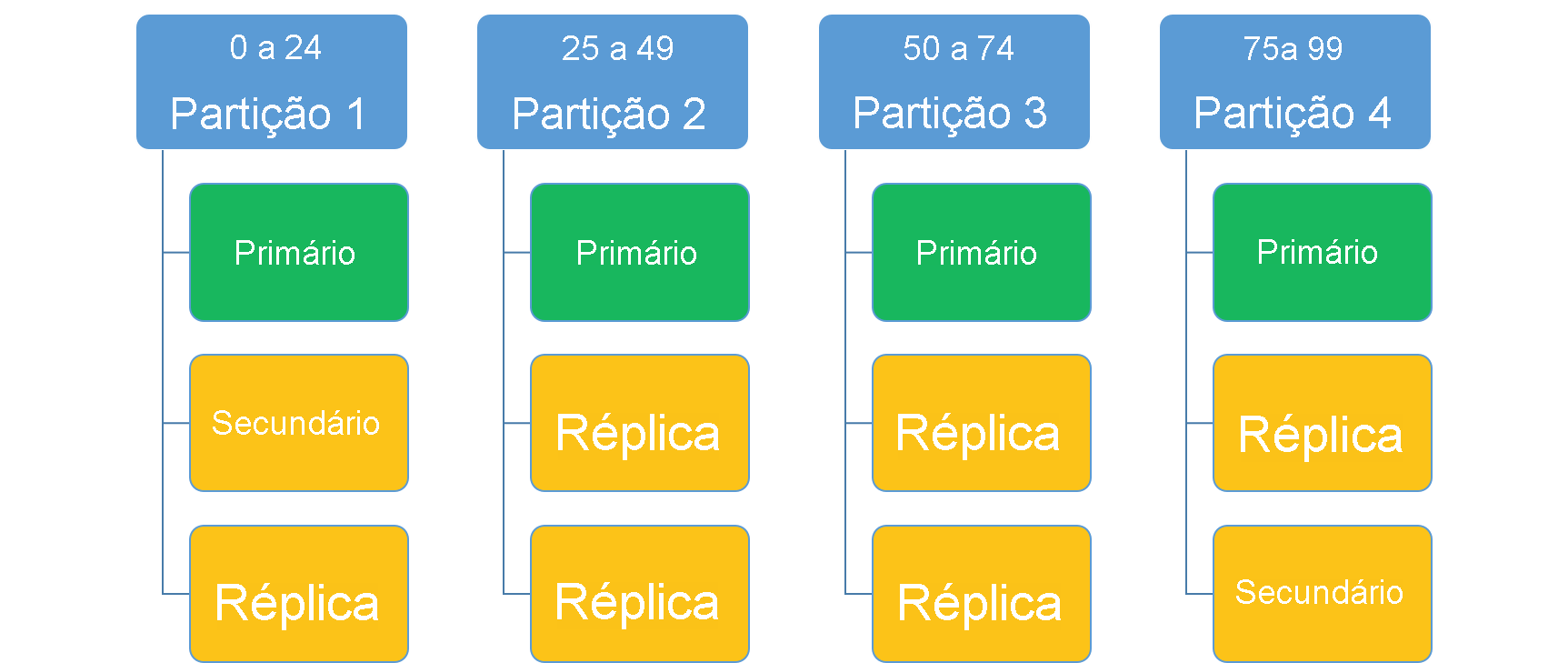
Uma abordagem comum é criar um hash com base em uma chave exclusiva dentro do conjunto de dados. Alguns exemplos comuns de chaves seriam um número de identificação de veículo (VIN), uma ID de funcionário ou uma cadeia de caracteres exclusiva. Usando essa chave exclusiva, você criaria um código de hash longo, o módulo do intervalo de chaves, para usar como sua chave. Você pode especificar os limites superior e inferior do intervalo de chave permitido.
Selecionar um algoritmo de hash
Uma parte importante de hash é selecionar o algoritmo de hash. Uma consideração é se o objetivo é agrupar chaves semelhantes próximas umas das outras (hash sensível à localidade) ou se a atividade precisa ser distribuída amplamente em todas as partições (hash de distribuição), que é o mais comum.
As características de um bom algoritmo de hash de distribuição são facilidade de computar, poucas colisões e distribuição uniforme de chaves. Um bom exemplo de algoritmo de hash eficiente é o algoritmo de hash FNV-1 .
Um bom recurso para opções gerais de algoritmo de código de hash é a página do Wikipedia sobre funções de hash.
Criar um serviço com estado com várias partições
Vamos criar seu primeiro serviço com estado confiável com várias partições. Neste exemplo, você criará um aplicativo muito simples no qual deseja armazenar todos os sobrenomes que começam com a mesma letra na mesma partição.
Antes de escrever qualquer código, você precisa pensar sobre as chaves de partição e partições. Você precisa de 26 partições (uma para cada letra no alfabeto), mas e quanto às chaves baixas e altas? Uma vez que queremos literalmente ter uma partição por letra, podemos usar 0 como a chave baixa e 25 como a chave alta, já que cada letra é sua própria chave.
Observação
Esse é um cenário simplificado, pois, na realidade, a distribuição seria irregular. Sobrenomes começando com a letra “S” ou “M” são mais comuns do que os que começam com “X” ou “Y”.
Abra Visual Studio>Arquivo>Novo>Projeto.
Na caixa de diálogo Novo Projeto escolha um aplicativo do Service Fabric.
Dê ao projeto o nome de “AlphabetPartitions”.
Na caixa de diálogo Criar um Serviço, escolha o serviço Com Estado e nomeie-o "Alphabet.Processing".
Defina o número de partições. Abra o arquivo ApplicationManifest.xml localizado na pasta ApplicationPackageRoot do projeto AlphabetPartitions e atualize o parâmetro Processing_PartitionCount para 26, conforme mostrado abaixo.
<Parameter Name="Processing_PartitionCount" DefaultValue="26" />Você também deve atualizar as propriedades LowKey e HighKey do elemento StatefulService no ApplicationManifest.xml, como mostrado abaixo.
<Service Name="Alphabet.Processing"> <StatefulService ServiceTypeName="Alphabet.ProcessingType" TargetReplicaSetSize="[Processing_TargetReplicaSetSize]" MinReplicaSetSize="[Processing_MinReplicaSetSize]"> <UniformInt64Partition PartitionCount="[Processing_PartitionCount]" LowKey="0" HighKey="25" /> </StatefulService> </Service>Para que o serviço fique acessível, abra um ponto de extremidade em uma porta adicionando o elemento de ponto de extremidade do ServiceManifest.xml (localizado na pasta PackageRoot) para o serviço Alphabet.Processing, conforme mostrado abaixo:
<Endpoint Name="ProcessingServiceEndpoint" Port="8089" Protocol="http" Type="Internal" />Agora o serviço está configurado para escutar um ponto de extremidade interno com 26 partições.
Em seguida, substitua o método
CreateServiceReplicaListeners()da classe Processing.Observação
Para este exemplo, supomos que você esteja usando um HttpCommunicationListener simples. Para obter mais informações sobre comunicação de Reliable Service, consulte O modelo de comunicação de Reliable Service.
Um padrão recomendado para a URL que escuta uma réplica é o seguinte formato:
{scheme}://{nodeIp}:{port}/{partitionid}/{replicaid}/{guid}. Assim, você deseja configurar o ouvinte de comunicação para escutar nos pontos de extremidade corretos e com esse padrão.Várias réplicas do serviço podem ser hospedadas no mesmo computador, portanto, esse endereço deve ser exclusivo para a réplica. É por isso que a ID de partição + ID da réplica estão na URL. HttpListener pode escutar em vários endereços na mesma porta, se o prefixo de URL for exclusivo.
O GUID extra existe para um caso avançado em que as réplicas secundárias também escutam solicitações de somente leitura. Quando esse for o caso, você deve certificar-se de que um novo endereço exclusivo é usado durante a transição do principal para o secundário para forçar os clientes a resolver o endereço novamente. “+” é usado como o endereço aqui, de modo que a réplica escute em todos os hosts disponíveis (IP, FQDN, localhost etc.). O código abaixo mostra um exemplo.
protected override IEnumerable<ServiceReplicaListener> CreateServiceReplicaListeners() { return new[] { new ServiceReplicaListener(context => this.CreateInternalListener(context))}; } private ICommunicationListener CreateInternalListener(ServiceContext context) { EndpointResourceDescription internalEndpoint = context.CodePackageActivationContext.GetEndpoint("ProcessingServiceEndpoint"); string uriPrefix = String.Format( "{0}://+:{1}/{2}/{3}-{4}/", internalEndpoint.Protocol, internalEndpoint.Port, context.PartitionId, context.ReplicaOrInstanceId, Guid.NewGuid()); string nodeIP = FabricRuntime.GetNodeContext().IPAddressOrFQDN; string uriPublished = uriPrefix.Replace("+", nodeIP); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInternalRequest); }Também vale a pena observar que a URL publicada é ligeiramente diferente do prefixo da URL de escuta. A URL de escuta é dada ao HttpListener. A URL publicada é a URL que será publicada para o Serviço de Nomenclatura da Malha de Serviço, que é usado para descoberta de serviço. Os clientes pedirão esse endereço por meio desse serviço de descoberta. O endereço que os clientes obtêm precisa ter o IP ou o FQDN do nó real para se conectar. Por isso, você precisa substituir '+' pelo IP ou FQDN do nó conforme mostrado acima.
A última etapa é adicionar a lógica de processamento ao serviço, conforme mostrado abaixo.
private async Task ProcessInternalRequest(HttpListenerContext context, CancellationToken cancelRequest) { string output = null; string user = context.Request.QueryString["lastname"].ToString(); try { output = await this.AddUserAsync(user); } catch (Exception ex) { output = ex.Message; } using (HttpListenerResponse response = context.Response) { if (output != null) { byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } } private async Task<string> AddUserAsync(string user) { IReliableDictionary<String, String> dictionary = await this.StateManager.GetOrAddAsync<IReliableDictionary<String, String>>("dictionary"); using (ITransaction tx = this.StateManager.CreateTransaction()) { bool addResult = await dictionary.TryAddAsync(tx, user.ToUpperInvariant(), user); await tx.CommitAsync(); return String.Format( "User {0} {1}", user, addResult ? "successfully added" : "already exists"); } }ProcessInternalRequestlê os valores do parâmetro de cadeia de caracteres da consulta usada para chamar a partição e chamaAddUserAsyncpara adicionar o sobrenome ao dicionário confiáveldictionary.Vamos adicionar um serviço sem estado ao projeto para ver como você pode chamar uma partição específica.
Esse serviço serve como uma interface web simples que aceita lastname como um parâmetro de cadeia de caracteres de consulta, determina a chave de partição e envia-o para o serviço Alphabet.Processing para processamento.
Na caixa de diálogo Criar um Serviço, escolha o serviço Sem Estado e dê a ele o nome de "Alphabet.Web", como mostrado abaixo.
 .
.Atualize as informações de ponto de extremidade no ServiceManifest.xml do serviço Alphabet.WebApi para abrir uma porta, conforme mostrado abaixo.
<Endpoint Name="WebApiServiceEndpoint" Protocol="http" Port="8081"/>Você precisa retornar uma coleção de ServiceInstanceListeners na classe Web. Novamente, você pode optar por implementar um HttpCommunicationListener simples.
protected override IEnumerable<ServiceInstanceListener> CreateServiceInstanceListeners() { return new[] {new ServiceInstanceListener(context => this.CreateInputListener(context))}; } private ICommunicationListener CreateInputListener(ServiceContext context) { // Service instance's URL is the node's IP & desired port EndpointResourceDescription inputEndpoint = context.CodePackageActivationContext.GetEndpoint("WebApiServiceEndpoint") string uriPrefix = String.Format("{0}://+:{1}/alphabetpartitions/", inputEndpoint.Protocol, inputEndpoint.Port); var uriPublished = uriPrefix.Replace("+", FabricRuntime.GetNodeContext().IPAddressOrFQDN); return new HttpCommunicationListener(uriPrefix, uriPublished, this.ProcessInputRequest); }Agora você precisa implementar a lógica de processamento. O HttpCommunicationListener chama
ProcessInputRequestquando chega uma solicitação. Vamos prosseguir e adicionar o código a abaixo.private async Task ProcessInputRequest(HttpListenerContext context, CancellationToken cancelRequest) { String output = null; try { string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A'); ResolvedServicePartition partition = await this.servicePartitionResolver.ResolveAsync(alphabetServiceUri, partitionKey, cancelRequest); ResolvedServiceEndpoint ep = partition.GetEndpoint(); JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri); output = String.Format( "Result: {0}. <p>Partition key: '{1}' generated from the first letter '{2}' of input value '{3}'. <br>Processing service partition ID: {4}. <br>Processing service replica address: {5}", result, partitionKey, firstLetterOfLastName, lastname, partition.Info.Id, primaryReplicaAddress); } catch (Exception ex) { output = ex.Message; } using (var response = context.Response) { if (output != null) { output = output + "added to Partition: " + primaryReplicaAddress; byte[] outBytes = Encoding.UTF8.GetBytes(output); response.OutputStream.Write(outBytes, 0, outBytes.Length); } } }Vamos ver o passo a passo. O código lê a primeira letra do parâmetro da cadeia de caracteres de consulta
lastnamedentro de um char. Isso determina a chave de partição para essa letra, subtraindo o valor hexadecimal deAdo valor hexadecimal da primeira letra do último nome.string lastname = context.Request.QueryString["lastname"]; char firstLetterOfLastName = lastname.First(); ServicePartitionKey partitionKey = new ServicePartitionKey(Char.ToUpper(firstLetterOfLastName) - 'A');Lembre-se de que, neste exemplo, estamos usando 26 partições com uma chave de partição por partição. Em seguida, obtemos a partição de serviço
partitionpara essa chave usando o métodoResolveAsyncno objetoservicePartitionResolver.servicePartitionResolveré definido comoprivate readonly ServicePartitionResolver servicePartitionResolver = ServicePartitionResolver.GetDefault();O método
ResolveAsyncusa o URI do serviço, a chave da partição e um token de cancelamento como parâmetros. O URI do serviço para o serviço de processamento éfabric:/AlphabetPartitions/Processing. Em seguida, obtemos o ponto de extremidade da partição.ResolvedServiceEndpoint ep = partition.GetEndpoint()Por fim, criamos a URL do ponto de extremidade mais a querystring e chamamos o serviço de processamento.
JObject addresses = JObject.Parse(ep.Address); string primaryReplicaAddress = (string)addresses["Endpoints"].First(); UriBuilder primaryReplicaUriBuilder = new UriBuilder(primaryReplicaAddress); primaryReplicaUriBuilder.Query = "lastname=" + lastname; string result = await this.httpClient.GetStringAsync(primaryReplicaUriBuilder.Uri);Após a conclusão do processamento, podemos gravar a saída de volta.
A última etapa é testar o serviço. O Visual Studio usa parâmetros do aplicativo para implantação local e na nuvem. Para testar o serviço com 26 partições localmente, atualize o arquivo
Local.xmlna pasta ApplicationParameters do projeto AlphabetPartitions, como mostrado abaixo:<Parameters> <Parameter Name="Processing_PartitionCount" Value="26" /> <Parameter Name="WebApi_InstanceCount" Value="1" /> </Parameters>Depois de concluir a implantação, você pode verificar o serviço e todas as respectivas partições no Gerenciador do Service Fabric.
Insira
http://localhost:8081/?lastname=somenameem um navegador para testar a lógica de particionamento. Você verá que cada sobrenome iniciado com a mesma letra está sendo armazenado na mesma partição.
A solução completa do código usado neste artigo está disponível aqui: https://github.com/Azure-Samples/service-fabric-dotnet-getting-started/tree/classic/Services/AlphabetPartitions.
Próximas etapas
Saiba mais sobre os serviços do Service Fabric: