Diagnosticar cenários comuns com o Service Fabric
Este artigo ilustra os cenários comuns que os usuários encontraram na área de monitoramento e diagnóstico com o Service Fabric. Os cenários apresentados abrangem todas as 3 camadas do service fabric: Aplicativos, Cluster e infraestrutura. Cada solução usa o Application Insights, os logs do Azure Monitor e as ferramentas de monitoramento do Azure para concluir cada cenário. As etapas em cada solução dão aos usuários uma introdução sobre como usar o Application Insights e os logs do Azure Monitor no contexto do Service Fabric.
Observação
Este artigo foi atualizado recentemente para usar o termo logs do Azure Monitor em vez de Log Analytics. Os dados de log ainda são armazenados em um espaço de trabalho do Log Analytics e ainda são coletados e analisados pelo mesmo serviço do Log Analytics. Estamos atualizando a terminologia para refletir melhor a função dos logs no Azure Monitor. Confira as alterações de terminologia do Azure Monitor para obter detalhes.
Pré-requisitos e recomendações
As soluções neste artigo usará as ferramentas a seguir. Recomendamos que você tenha os itens a seguir instalados e configurados:
- Application Insights com Service Fabric
- Habilite o Diagnóstico do Azure no seu cluster
- Configurar um espaço de trabalho do Log Analytics
- Agente do Log Analytics para rastrear Contadores de Desempenho
Como posso ver exceções sem tratamento no meu aplicativo?
Navegue até o recurso do Application Insights com o qual seu aplicativo está configurado.
Clique em Pesquisa no canto superior esquerdo. Em seguida,clique no filtro no painel seguinte.
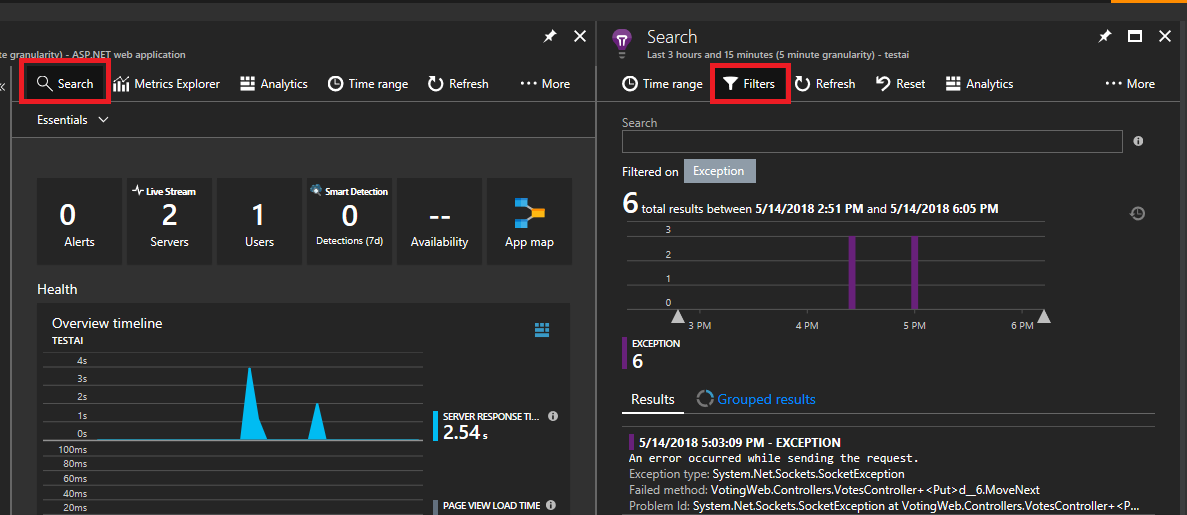
Você verá muitos tipos de eventos (rastreamentos, solicitações, eventos personalizados). Escolha "Exceção" como filtro.

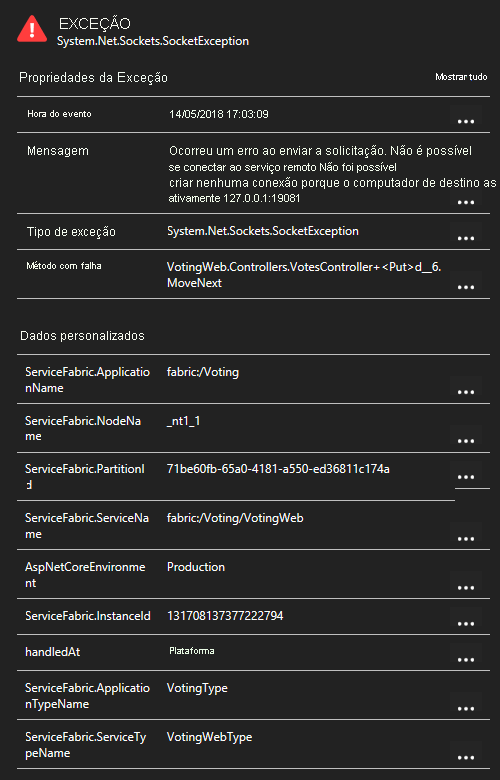
Clicando em uma exceção na lista, você pode ver mais detalhes, incluindo o contexto do serviço se você estiver usando o SDK do Application Insights do Service Fabric.
Como visualizo quais chamadas HTTP são usadas em meus serviços?
No mesmo recurso do Application Insights, você pode filtrar "solicitações" em vez de exceções e exibir todas as solicitações feitas
Se estiver usando o SDK do Application Insights do Service Fabric, você poderá ver uma representação visual dos seus serviços conectados um ao outro e o número de solicitações com êxito e falha. À esquerda, clique em "Mapa do aplicativo"

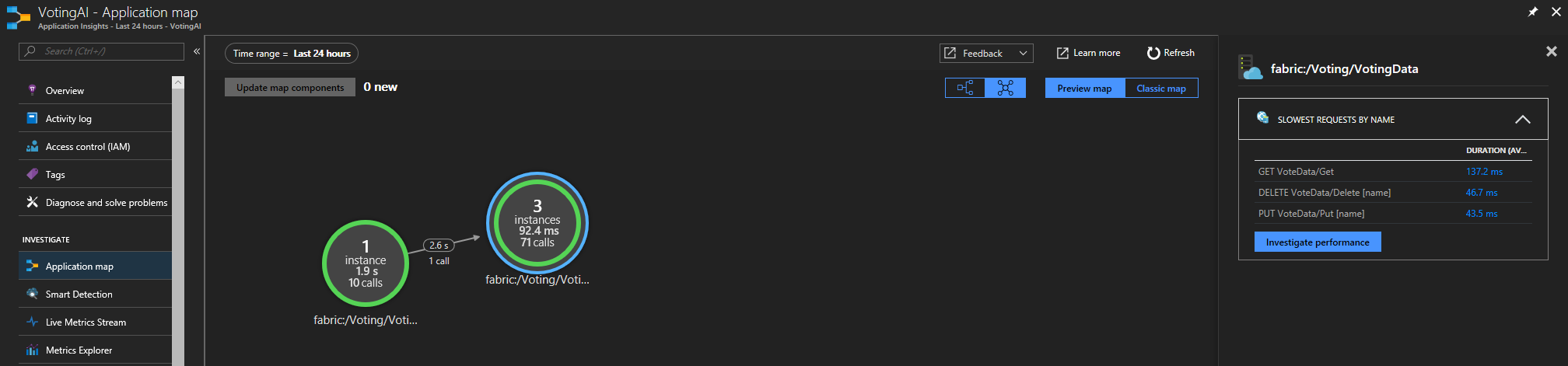
Para obter mais informações sobre o mapa de aplicativo, visite a documentação do Mapa do aplicativo
Como crio um alerta quando um nó falhar
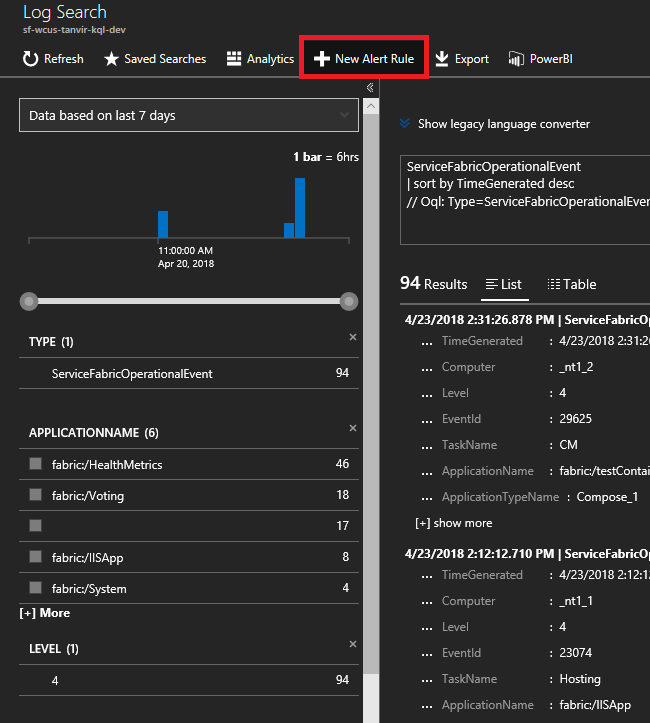
Eventos de nó são controlados pelo cluster do Service Fabric. Navegue para o recurso da solução de Análise do Service Fabric chamado ServiceFabric(NameofResourceGroup)
Clique no gráfico na parte inferior da folha intitulado "Resumo"

Aqui, você tem muitos gráficos e blocos exibindo várias métricas. Clique em um dos gráficos, e ele o levará para a Pesquisa de Logs. Aqui, você pode consultar quaisquer eventos de cluster ou os contadores de desempenho.
Insira a consulta a seguir. Essas IDs de evento são encontradas na Referência de eventos de nó
ServiceFabricOperationalEvent | where EventID >= 25622 and EventID <= 25626Clique em "Nova Regra de Alerta" na parte superior, e agora, sempre que um evento chegar com base nessa consulta, você receberá um alerta no seu método de comunicação escolhido.
Como posso ser avisado de reversões de atualização de aplicativo?
Na mesma janela de Pesquisa de Logs, como antes, digite a seguinte consulta para reversões de atualização. Essas IDs de evento são encontradas na Referência de eventos de aplicativo
ServiceFabricOperationalEvent | where EventID == 29623 or EventID == 29624Clique em "Nova Regra de Alerta" na parte superior, e agora, sempre que um evento chegar com base nessa consulta, você receberá um alerta.
Como posso ver as métricas de contêiner?
A mesma exibição com todos os gráficos, você verá alguns blocos para o desempenho de seus contêineres. Você precisa que o agente do Log Analytics e solução de Monitoramento de Contêiner para essas peças preencherem.

Observação
Para instrumentar a telemetria de dentro de seu contêiner, você precisará adicionar o pacote do nuget do Application Insights para contêineres.
Como posso monitorar contadores de desempenho?
Depois que você tiver adicionado o Agente do Log Analytics ao cluster de que você precisa para adicionar contadores de desempenho específicos que você deseja controlar. Navegue até a página do Espaço de Trabalho do Log Analytics no portal – na página da solução, a guia de espaço de trabalho está no menu à esquerda.

Uma vez na página do workspace, clique em "Configurações avançadas" no mesmo menu à esquerda.

Clique em Dados > Contadores de Desempenho do Windows (Dados > Contadores de Desempenho do Linux para Máquinas Linux) para começar a coletar contadores específicos de seus nós através do agente do Log Analytics. Aqui estão exemplos de formato para os contadores a serem adicionados
.NET CLR Memory(<ProcessNameHere>)\\# Total committed BytesProcessor(_Total)\\% Processor TimeNo início rápido, VotingData e VotingWeb são os nomes de processo usados, portanto, como seria o acompanhamento desses contadores
.NET CLR Memory(VotingData)\\# Total committed Bytes.NET CLR Memory(VotingWeb)\\# Total committed Bytes
Isso permitirá que você veja como sua infraestrutura está manipulando as cargas de trabalho e definirá alertas relevantes com base na utilização de recursos. Por exemplo, talvez você queira definir um alerta se a utilização total do processador ficar acima de 90% ou abaixo de 5%. O nome do contador que você usaria para isso é "% do Tempo do Processador". Você poderá fazer isso criando uma regra de alerta para a consulta a seguir:
Perf | where CounterName == "% Processor Time" and InstanceName == "_Total" | where CounterValue >= 90 or CounterValue <= 5.
Como acompanhar o desempenho de meu Reliable Services e Atores?
Para monitorar o desempenho de Reliable Services ou Atores em seus aplicativos, você deverá coletar o Ator do Service Fabric, o Método de Autor, o Serviço e os contadores de Método de Serviço também. Aqui estão exemplos de contadores de desempenho de serviço e ator confiáveis a serem coletados
Observação
Os contadores de desempenho do Service Fabric não podem ser coletados pelo agente do Log Analytics no momento, mas podem ser coletados por outras soluções de diagnóstico
Service Fabric Service(*)\\Average milliseconds per requestService Fabric Service Method(*)\\Invocations/SecService Fabric Actor(*)\\Average milliseconds per requestService Fabric Actor Method(*)\\Invocations/Sec
Verifique esses links para a lista completa de contadores de desempenho em Reliable Services e Atores
Próximas etapas
- Pesquisar erros comuns de ativação do Pacote de códigos
- Configurar alertas no AI para ser notificado sobre mudanças no desempenho ou uso
- Detecção Inteligente no Application Insights realiza uma análise pró-ativa da telemetria enviada ao AI para avisá-lo sobre possíveis problemas de desempenho
- Saiba mais sobre os alertas do Azure Monitor para auxiliar na detecção e no diagnóstico.
- Para clusters locais, os logs do Azure Monitor oferecem um gateway (Proxy de Encaminhamento HTTP) que pode ser usado para enviar dados aos logs do Azure Monitor. Leia mais sobre isso em Conectar computadores sem acesso à Internet aos logs do Azure Monitor usando o gateway do Log Analytics
- Familiarize-se com os recursos de pesquisa e consulta de logs oferecidos como parte dos logs do Azure Monitor
- Obtenha uma visão mais detalhada dos logs do Azure Monitor e o que eles oferecem, leia O que são os logs do Azure Monitor?