Arquitetura de recuperação de desastre do VMware para o Azure – Clássico
Este artigo descreve a arquitetura e os processos usados quando você implanta a replicação de recuperação de desastre, o failover e a recuperação de VMs (máquinas virtuais) do VMware entre um site local da VMware e o Azure usando o serviço Azure Site Recovery – Clássico.
Para obter detalhes sobre a arquitetura modernizada, consulte este artigo
Componentes de arquitetura
A tabela e o gráfico a seguir fornecem uma visão geral dos componentes usados para recuperação de desastre de VMs/Computadores físicos da VMware para o Azure.
| Componente | Requisito | Detalhes |
|---|---|---|
| Azure | Uma assinatura do Azure, uma conta de Armazenamento do Azure para cache, disco gerenciado e rede do Azure. | Os dados replicados de VMs locais são armazenados no armazenamento do Azure. As VMs do Azure são criadas com os dados replicados quando você faz um failover do local para o Azure. As VMs do Azure se conectam à rede virtual do Azure quando são criadas. |
| Máquina do servidor de configuração | Uma única máquina local. É recomendável executar como uma VM de VMware que possa ser implantada desde um modelo de OVF baixado. A máquina executa todos os componentes do Site Recovery locais, que incluem o servidor de configuração, servidor de processo e o servidor de destino mestre. |
Servidor de configuração: coordena a comunicação entre o ambiente local e o Azure e gerencia a replicação de dados. Servidor de processo: instalado por padrão no servidor de configuração. Recebe dados de replicação, otimiza-os com caching, compactação e criptografia e os envia para o Armazenamento do Microsoft Azure. O servidor de processo também instala o Serviço de Mobilidade do Azure Site Recovery nas VMs que você deseja replicar e executa a descoberta automática de máquinas locais. À medida que a implantação cresce, você pode adicionar outros servidores de processo separados para lidar com volumes maiores de tráfego de replicação. Servidor de destino mestre: instalado por padrão no servidor de configuração. Lida com os dados de replicação durante o failback do Azure. Para grandes implantações, você pode adicionar um servidor de destino mestre separado adicional para failback. |
| Servidores VMware | VMs de VMware são hospedadas em servidores ESXi do vSphere locais. Recomendamos um servidor vCenter para gerenciar os hosts. | Durante a implantação do Site Recovery, você pode adicionar servidores VMware no cofre dos Serviços de Recuperação. |
| Computadores replicados | O Serviço de Mobilidade é instalado em cada VM de VMware que você replicar. | É recomendável permitir a instalação automática do servidor em processo. Como alternativa, você pode instalar o serviço manualmente ou usar um método de implantação automatizado, como o Configuration Manager. |

Configurar a conectividade de rede de saída
Para que o Site Recovery funcione conforme o esperado, você precisa modificar a conectividade de rede de saída para permitir que seu ambiente seja replicado.
Observação
O Site Recovery de computadores do VMware/Físicos usando a arquitetura Clássica não dá suporte ao uso de um proxy de autenticação para controlar a conectividade de rede. O mesmo é compatível com o uso da arquitetura modernizada.
Conectividade de saída para URLs
Caso esteja usando um proxy de firewall baseado em URL para controlar a conectividade de saída, permita acesso a estas URLs:
| Nome | Comercial | Governo | Descrição |
|---|---|---|---|
| Armazenamento | *.blob.core.windows.net |
*.blob.core.usgovcloudapi.net |
Permite que os dados sejam gravados da VM para a conta de armazenamento de cache da região de origem. |
| ID do Microsoft Entra | login.microsoftonline.com |
login.microsoftonline.us |
Fornece autorização e autenticação para as URLs do serviço Site Recovery. |
| Replicação | *.hypervrecoverymanager.windowsazure.com |
*.hypervrecoverymanager.windowsazure.us |
Permite que a VM se comunique com o serviço Site Recovery. |
| Barramento de Serviço | *.servicebus.windows.net |
*.servicebus.usgovcloudapi.net |
Permite que a VM grave o monitoramento do Site Recovery e os dados de diagnóstico. |
Para obter uma lista completa de URLs a serem filtradas para comunicação entre a infraestrutura do Azure Site Recovery local e os serviços do Azure, confira a seção de requisitos de rede no artigo de pré-requisitos.
Processo de replicação
Ao habilitar a replicação para uma VM, a replicação inicial para o armazenamento do Azure começa, usando a política de replicação especificada. Observe o seguinte:
- Para as VMs de VMware, a replicação é em nível de bloco, quase contínua, usando o agente do serviço Mobilidade em execução na VM.
- Qualquer configuração de política de replicação é aplicada:
- Limite de RPO. Essa configuração não afeta a replicação. Isso ajuda no monitoramento. Um evento é gerado e, opcionalmente, um email enviado, se o RPO atual exceder o limite que você especificar.
- Retenção do ponto de recuperação. Essa configuração especifica o tempo retroativo da recuperação quando ocorrer uma interrupção. A retenção máxima é de 15 dias no disco gerenciado.
- Instantâneos consistentes com o aplicativo. Um instantâneo consistente com o aplicativo pode de demorar de 1 a 12 horas, dependendo das necessidades do aplicativo. Instantâneos são instantâneos de blob padrão do Azure. O agente de Mobilidade executando em uma VM solicita um instantâneo de VSS de acordo com essa configuração e indica esse ponto no tempo como um ponto consistente do aplicativo no fluxo de replicação.
Observação
Um alto período de retenção do ponto de recuperação pode ter uma implicação no custo de armazenamento, pois pode ser necessário salvar mais pontos de recuperação.
O tráfego é replicado para pontos de extremidade públicos do Armazenamento do Microsoft Azure pela Internet. Como alternativa, você pode usar o Azure ExpressRoute com emparelhamento da Microsoft. Não há suporte para replicação de tráfego através de uma VPN (rede virtual privada) site a site de um site local para o Azure.
A operação de replicação inicial garante que todos os dados no computador no momento da habilitação da replicação sejam enviados para o Azure. Após a conclusão da replicação inicial, a replicação de alterações delta para o Azure é iniciada. As alterações controladas de uma máquina são enviadas para o servidor de processo.
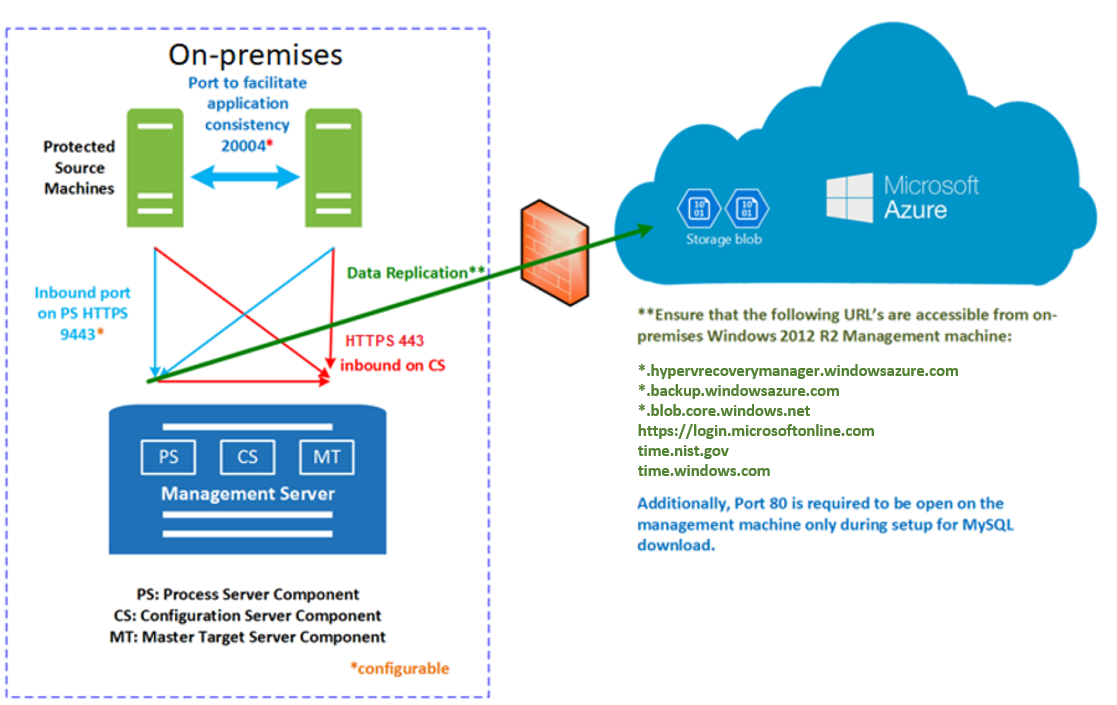
A comunicação ocorre da seguinte maneira:
- As VMs se comunicam com o servidor de configuração local na porta HTTPS 443 de entrada para o gerenciamento de replicação.
- O servidor de configuração coordena a replicação com o Azure pela porta HTTPS 443 de saída.
- As VMs que estão sendo replicadas enviam dados de replicação para o servidor de processo (em execução no computador do servidor de configuração) na porta 9443 HTTPS de entrada. Essa porta pode ser modificada.
- O servidor de processo recebe, otimiza, criptografa e envia dados de replicação para o Armazenamento do Microsoft Azure pela porta 443 de saída.
Os registros de dados de replicação primeiro ficam em uma conta de armazenamento de cache no Azure. Esses logs são processados e os dados são armazenados em um Disco Gerenciado do Azure (chamado de disco de propagação do Azure Site Recovery). Os pontos de recuperação são criados nesse disco.
Processo de ressincronização
- Às vezes, durante a replicação inicial ou ao transferir alterações delta, poderão ocorrer problemas de conectividade de rede entre o computador de origem e o servidor de processo ou entre o servidor de processo para Azure. Qualquer um deles pode levar a falhas na transferência de dados para o Azure momentaneamente.
- Para evitar problemas de integridade de dados e minimizar os custos de transferência de dados, o Site Recovery marcará um computador para ressincronização.
- Um computador também pode ser marcado para ressincronização em situações como as indicadas a seguir, para manter a consistência entre o computador de origem e os dados armazenados no Azure
- Se um computador passar por um desligamento forçado
- Se um computador passar por alterações de configuração como o redimensionamento de disco (modificando o tamanho do disco de 2 TB para 4 TB)
- A ressincronização envia apenas dados delta para o Azure. Transferência de dados entre o local e o Azure minimizada pela computação de somas de verificação de dados entre o computador de origem e os dados armazenados no Azure.
- Por padrão, a ressincronização está agendada para execução automática fora das horas de trabalho. Se você não quiser aguardar a ressincronização fora do horário de trabalho, você poderá ressincronizar uma VM manualmente. Para fazer isso, acesse o portal do Azure e selecione VM >Ressincronizar.
- Se a ressincronização padrão falhar fora do horário comercial e uma intervenção manual for necessária, um erro será gerado no computador específico no portal do Azure. Você pode resolver o erro e disparar a ressincronização manualmente.
- Após a conclusão da ressincronização, a replicação de alterações delta será retomada.
Gerenciando políticas de replicação
- Você pode personalizar as configurações das políticas de replicação à medida que habilita a replicação.
- Crie uma política de replicação a qualquer momento e, em seguida, aplique-a quando habilitar a replicação.
Consistência de várias VMs
Caso deseje que as VMs sejam replicadas juntas e tenham pontos de recuperação consistentes com aplicativo e com falhas compartilhados no failover, você poderá reuni-las em um grupo de replicação. A consistência de várias VMs afeta o desempenho da carga de trabalho e só deve ser usada para VMs que executam cargas de trabalho que precisam de consistência em todos os computadores.
Instantâneos e pontos de recuperação
Os pontos de recuperação são criados com base em instantâneos de discos de VMs tirados em um ponto específico no tempo. Quando você faz failover de uma VM, você usa um ponto de recuperação para restaurar a VM na localização de destino.
Durante o failover, em geral, queremos garantir que a VM seja iniciada sem dados corrompidos nem perda de dados e que os dados da VM sejam consistentes para o sistema operacional e para os aplicativos executados na VM. Isso depende do tipo de instantâneos tirados.
O Site Recovery tira instantâneos da seguinte maneira:
- O Site Recovery tira instantâneos consistentes com falhas de dados por padrão e instantâneos consistentes com aplicativo se você especifica uma frequência para eles.
- Os pontos de recuperação são criados com base nos instantâneos e armazenados de acordo com as configurações de retenção na política de replicação.
Consistência
A tabela a seguir explica os diferentes tipos de consistência.
Consistente com falhas
| Descrição | Detalhes | Recomendação |
|---|---|---|
| Um instantâneo consistente com falha captura os dados que estavam no disco quando o instantâneo foi tirado. Ele não inclui nada na memória. Ele contém o equivalente dos dados em disco que estariam presentes se a VM falhasse ou se o cabo de alimentação fosse puxado do servidor no instante em que o instantâneo foi tirado. Um ponto de recuperação consistente com falhas não garante a consistência dos dados para o sistema operacional nem para os aplicativos na VM. |
O Site Recovery cria pontos de recuperação consistentes com falhas a cada cinco minutos por padrão. Essa configuração não pode ser modificada. |
Hoje, a maioria dos aplicativos pode se recuperar bem de pontos consistentes com falhas. Os pontos de recuperação consistentes com falhas geralmente são suficientes para a replicação de sistemas operacionais e aplicativos, como servidores DHCP e servidores de impressão. |
Consistente com aplicativo
| Descrição | Detalhes | Recomendação |
|---|---|---|
| Os pontos de recuperação consistentes com aplicativo são criados com base nos instantâneos consistentes com aplicativo. Um instantâneo consistente com aplicativo contêm todas as informações em um instantâneo consistente com falhas, além de todos os dados na memória e as transações em andamento. |
Os instantâneos consistentes com aplicativo usam o VSS (Serviço de Cópias de Sombra de Volume): 1) O Azure Site Recovery usa o método de backup Somente Cópia (VSS_BT_COPY) que não altera o tempo de backup do log de transações nem o número de sequência de SQL da Microsoft 2) Quando um instantâneo é iniciado, o VSS executa uma operação COW (cópia na gravação) no volume. 3) Antes de executar a COW, o VSS informa todos os aplicativos do computador de que precisa liberar seus dados residentes na memória para o disco. 4) Em seguida, o VSS permite que o aplicativo de backup/recuperação de desastre (nesse caso, o Site Recovery) leia os dados de instantâneo e continue. |
Os instantâneos consistentes com aplicativo são tirados de acordo com a frequência especificada. Essa frequência sempre deve ser inferior àquela definida para a retenção de pontos de recuperação. Por exemplo, se você retém os pontos de recuperação usando a configuração padrão de 24 horas, defina a frequência como inferior a 24 horas. Eles são mais complexos e levam mais tempo para serem concluídos do que os instantâneos consistentes com falhas. Elas afetam o desempenho de aplicativos executados em uma VM habilitada para replicação. |
Processo de failover e failback
Depois que a replicação é configurada e você executou uma simulação de recuperação de desastre (failover de teste) para verificar se tudo está funcionando conforme o esperado, você poderá executar failover e failback conforme necessário.
É possível fazer failover de uma única máquina ou criar planos de recuperação para fazer failover de várias VMs ao mesmo tempo. As vantagens de um plano de recuperação em vez de failover de única máquina incluem:
- Você pode modelar dependências do aplicativo, incluindo todas as VMs entre o aplicativo em um único plano de recuperação.
- Você pode adicionar scripts, runbooks do Azure e pausar para ações manuais.
Depois de disparar o failover inicial, você confirma-o para começar a acessar a carga de trabalho da VM do Azure.
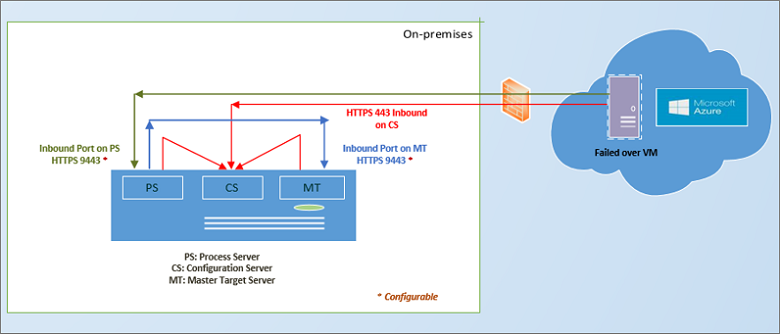
Quando o site primário local estiver disponível novamente, você poderá se preparar executar o failback. Para executar o failback, você precisa configurar uma infraestrutura de failback, incluindo:
- Servidor em processo temporário no Azure: para fazer failback do Azure, você configura uma VM do Azure para atuar como um servidor em processo, a fim de manipular a replicação do Azure. Você pode excluir a VM após a conclusão do failback.
- Conexão VPN: para fazer failback, você precisa de uma conexão VPN (ou ExpressRoute) da rede do Azure para o site local.
- Servidor de destino mestre separado: por padrão, o servidor de destino mestre que foi instalado com o servidor de configuração na VM do VMware local manipula o failback. Se for necessário fazer failback de grandes volumes de tráfego, configure um servidor de destino mestre local separado para essa finalidade.
- Política de failback: para replicar volta para seu site local, você precisa de uma política de failback. Essa política é criada automaticamente quando você cria uma política de replicação de local para o Azure.
Depois que os componentes estão em vigor, o failback ocorre em três ações:
- Estágio 1: proteja novamente as VMs do Azure para que elas comecem a replicação para as VMs de VMware locais.
- Estágio 2: execute um failover para o site local.
- Etapa 3: depois que as cargas de trabalho fizeram failback, você reabilitará a replicação para as VMs locais.
Próximas etapas
Siga este tutorial para habilitar a replicação de VMware para o Azure.