Integrar o Azure Stream Analytics com o Azure Machine Learning
Você pode implementar modelos de aprendizado de máquina como um UDF (função definida pelo usuário) em seus trabalhos do Azure Stream Analytics para fazer previsões e estimativas em tempo real em seus dados de entrada de streaming. O Azure Machine Learning permite que você use qualquer ferramenta de open-source popular, como Tensorflow, scikit-learn ou PyTorch, para preparar, treinar e implantar modelos.
Pré-requisitos
Conclua as etapas a seguir antes de adicionar um modelo de machine learning como uma função do seu trabalho de Stream Analytics:
Use o Azure Machine Learning para implantar seu modelo como um serviço Web.
Seu ponto de extremidade de aprendizado de máquina deve ter um swagger associado que ajude o Stream Analytics a entender o esquema de entrada e saída. Você pode usar esta definição de Swagger de exemplo como uma referência para garantir que você a configurou corretamente.
Verifique se o serviço Web aceita e retorna dados serializados JSON.
Implante seu modelo no Serviço de Kubernetes do Azure para implantações de produção em grande escala. Se o serviço Web não puder lidar com o número de solicitações provenientes do seu trabalho, o desempenho do trabalho no Stream Analytics será prejudicando, afetando a latência. Modelos implantados em Instâncias de Contêiner do Azure têm suporte apenas quando você usa o portal do Azure.
Adicionar um modelo de machine learning ao seu trabalho
Você pode adicionar funções do Azure Machine Learning ao seu trabalho de Stream Analytics diretamente do portal do Azure ou Visual Studio Code.
Portal do Azure
Navegue até o trabalho de Stream Analytics no portal do Azure e selecione Funções em Topologia de trabalho. Em seguida, selecione Serviço do Azure Machine Learning no menu suspenso +Adicionar.
Preencha o formulário Função de serviço do Azure Machine Learning com os seguintes valores de propriedade:
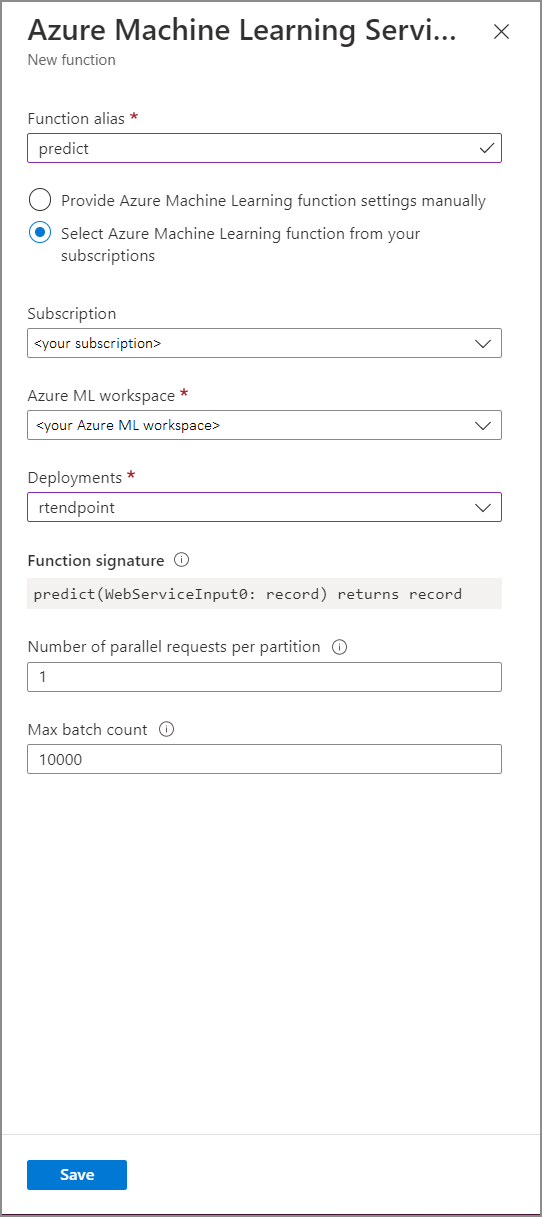
A tabela a seguir descreve cada propriedade das funções de serviço do Azure Machine Learning no Stream Analytics.
| Propriedade | Descrição |
|---|---|
| Alias da função | Insira um nome para invocar a função em sua consulta. |
| Subscription | Sua assinatura do Azure. |
| Workspace do Azure Machine Learning | O workspace do Azure Machine Learning usado para implantar seu modelo como um serviço Web. |
| Ponto de extremidade | O serviço Web que hospeda seu modelo. |
| Assinatura de função | A assinatura do serviço Web inferida da especificação de esquema da API. Se a sua assinatura não for carregada, verifique se você forneceu a entrada e a saída de exemplo em seu script de pontuação para gerar automaticamente o esquema. |
| Número de solicitações paralelas por partição | Essa é uma configuração avançada para otimizar a taxa de transferência de alta escala. Esse número representa as solicitações simultâneas enviadas de cada partição do seu trabalho para o serviço Web. Trabalhos com seis SUs (unidades de streaming) ou menos têm uma partição. Trabalhos com 12 SUs têm duas partições, com 18 SUs tem três partições e assim por diante. Por exemplo, se seu trabalho tiver duas partições e você definir esse parâmetro como quatro, haverá oito solicitações simultâneas de seu trabalho para o serviço Web. |
| Contagem máxima do lote | Essa é uma configuração avançada para otimização da taxa de transferência de alta escala. Esse número representa o número máximo de eventos que serão agrupados em lote em uma única solicitação enviada ao serviço Web. |
Chamar o ponto de extremidade de aprendizado de máquina de sua consulta
Quando a consulta de Stream Analytics invoca um UDF do Azure Machine Learning, o trabalho cria uma solicitação JSON serializada para o serviço Web. A solicitação tem base em um esquema específico do modelo do qual o Stream Analytics infere no swagger do ponto de extremidade.
Aviso
Os pontos de extremidade do Machine Learning não são chamados quando você está testando com o editor de consultas do portal do Azure porque o trabalho não está em execução. Para testar a chamada de ponto de extremidade do portal, o trabalho do Stream Analytics precisa estar em execução.
A consulta do Stream Analytics a seguir é um exemplo de como invocar um UDF do Azure Machine Learning:
SELECT udf.score(<model-specific-data-structure>)
INTO output
FROM input
WHERE <model-specific-data-structure> is not null
Se os dados de entrada enviados ao UDF de ML estiverem inconsistentes com o esquema esperado, o ponto de extremidade retornará uma resposta com o código de erro 400, o que fará com que seu trabalho do Stream Analytics entre em um estado de falha. É recomendável que você habilite os logs de recursos do trabalho, o que permitirá depurar e solucionar esses problemas facilmente. Portanto, é altamente recomendável que você:
- Valide se a entrada para o UDF de ML não é nula
- Verifique o tipo de cada campo que representa uma entrada para o UDF de ML para garantir que corresponde ao que o é esperado pelo ponto de extremidade
Observação
Os UDFs de ML são avaliadas para cada linha de uma determinada etapa de consulta, mesmo quando chamadas por meio de uma expressão condicional (ou seja, CASE WHEN [A] IS NOT NULL THEN udf.score(A) ELSE '' END). Se necessário, use a cláusula WITH para criar caminhos divergentes, chamando o UDF de ML somente quando necessário, antes de usar UNION para mesclar os caminhos novamente.
Passar vários parâmetros de entrada para o UDF
Os exemplos mais comuns de entradas para modelos de aprendizado de máquina são matrizes e DataFrames de numpy. Você pode criar uma matriz usando um UDF JavaScript e criar um DataFrame serializado em JSON usando a cláusula WITH.
Crie uma matriz de entrada
Você pode criar um UDF de JavaScript que aceita N números de entradas e cria uma matriz que pode ser usada como entrada para o UDF do Azure Machine Learning.
function createArray(vendorid, weekday, pickuphour, passenger, distance) {
'use strict';
var array = [vendorid, weekday, pickuphour, passenger, distance]
return array;
}
Depois de adicionar o UDF JavaScript ao trabalho, você pode invocar o UDF do Azure Machine Learning usando a seguinte consulta:
WITH
ModelInput AS (
#use JavaScript UDF to construct array that will be used as input to ML UDF
SELECT udf.createArray(vendorid, weekday, pickuphour, passenger, distance) as inputArray
FROM input
)
SELECT udf.score(inputArray)
INTO output
FROM ModelInput
#validate inputArray is not null before passing it to ML UDF to prevent job from failing
WHERE inputArray is not null
O JSON a seguir é uma solicitação de exemplo:
{
"Inputs": {
"WebServiceInput0": [
["1","Mon","12","1","5.8"],
["2","Wed","10","2","10"]
]
}
}
Criar um DataFrame do Pandas ou PySpark
Você pode usar a cláusula WITH para criar um DataFrame JSON serializado que pode ser passado como entrada para o UDF do Azure Machine Learning, conforme mostrado abaixo.
A consulta a seguir cria um DataFrame selecionando os campos necessários e usa o DataFrame como entrada para o UDF do Azure Machine Learning.
WITH
Dataframe AS (
SELECT vendorid, weekday, pickuphour, passenger, distance
FROM input
)
SELECT udf.score(Dataframe)
INTO output
FROM Dataframe
WHERE Dataframe is not null
O JSON a seguir é uma solicitação de exemplo da consulta anterior:
{
"Inputs": {
"WebServiceInput0": [
{
"vendorid": "1",
"weekday": "Mon",
"pickuphour": "12",
"passenger": "1",
"distance": "5.8"
},
{
"vendorid": "2",
"weekday": "Tue",
"pickuphour": "10",
"passenger": "2",
"distance": "10"
}]
}
}
Otimizar o desempenho dos UDFs do Azure Machine Learning
Ao implantar seu modelo no Serviço de Kubernetes do Azure, você pode fazer o perfil do seu modelo para determinar a utilização de recursos. Você também pode habilitar o App Insights nas suas implantações para entender as taxas de solicitação, os tempos de resposta e as tarifas de falha.
Se você tiver um cenário com alta taxa de transferência de eventos, talvez seja necessário alterar os seguintes parâmetros no Stream Analytics para obter o desempenho ideal com baixas latências de ponta a ponta:
- Contagem máxima de lotes.
- Número de solicitações paralelas por partição.
Determinar o tamanho do lote certo
Depois de implantar o serviço Web, envie uma solicitação de exemplo com tamanhos de lote variados começando em 50 e aumentando na ordem de centenas. Por exemplo, 200, 500, 1000, 2000 e assim por diante. Você observará que, após um determinado tamanho de lote, aumentará a latência da resposta. O ponto após o qual aumenta a latência de resposta deve ser a contagem de lotes máxima para o seu trabalho.
Determinar o número de solicitações paralelas por partição
No dimensionamento ideal, seu trabalho no Stream Analytics deve ser capaz de enviar várias solicitações paralelas para o serviço Web e obter uma resposta em poucos milissegundos. A latência da resposta do serviço Web pode afetar diretamente a latência e o desempenho de seu trabalho no Stream Analytics. Se a chamada do trabalho para o serviço Web demorar muito tempo, provavelmente ocorrerá um aumento no atraso da marca-d'água e também no número de eventos de entrada da lista de pendências.
Alcance uma latência baixa garantindo que o cluster AKS (Serviço de Kubernetes do Azure) tenha sido provisionado com o número correto de nós e réplicas. É fundamental que seu serviço Web esteja altamente disponível e retorne respostas com êxito. Se o trabalho receber um erro que permita novas tentativas, como resposta de serviço não disponível (503), ele tentará novamente automaticamente com a retirada exponencial desativada. Se o trabalho receber um desses erros como resposta do ponto de extremidade, ele passará para um estado de falha.
- Solicitação incorreta (400)
- Conflito (409)
- Não encontrado (404)
- Não autorizado (401)
Limitações
Se você estiver usando um serviço de ponto de extremidade gerenciado do Azure ML, atualmente, o Stream Analytics só poderá acessar pontos de extremidade que tenham o acesso à rede pública habilitado. Leia mais sobre isso na página sobre pontos de extremidade privados do Azure ML.