Soberania de dados por microsserviço
Dica
Esse conteúdo é um trecho do eBook da Arquitetura de Microsserviços do .NET para os Aplicativos .NET em Contêineres, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Uma regra importante para a arquitetura de microsserviços é que cada um deles precisa ter dados e lógica de domínio. Assim como um aplicativo completo tem sua própria lógica e dados, cada microsserviço precisa tê-los em um ciclo de vida autônomo, com implantação independente por microsserviço.
Isso significa que o modelo conceitual do domínio será diferente entre subsistemas ou microsserviços. Imagine aplicativos empresariais, em que os aplicativos de gerenciamento de relacionamento com o cliente (CRM), subsistemas de compras transacionais e subsistemas de suporte ao cliente exigem atributos e dados únicos de entidade do cliente e aplicam um contexto delimitado diferente.
Esse princípio é semelhante no DDD (design controlado por domínio), em que cada Contexto Delimitado ou subsistema autônomo ou serviço precisa ter seu próprio modelo de domínio (dados, lógica e comportamento). Cada Contexto Delimitado por DDD se correlaciona a um microsserviço de negócios (um ou vários serviços). Esse ponto do padrão do Contexto Delimitado é expandido na próxima seção.
Por outro lado, a abordagem tradicional (dados monolíticos) usada em diversos aplicativos é ter um banco de dados único centralizado ou poucos bancos de dados. Geralmente, trata-se de um Banco de Dados SQL normalizado utilizado para o aplicativo inteiro e todos seus subsistemas internos, conforme mostrado na Figura 4-7.
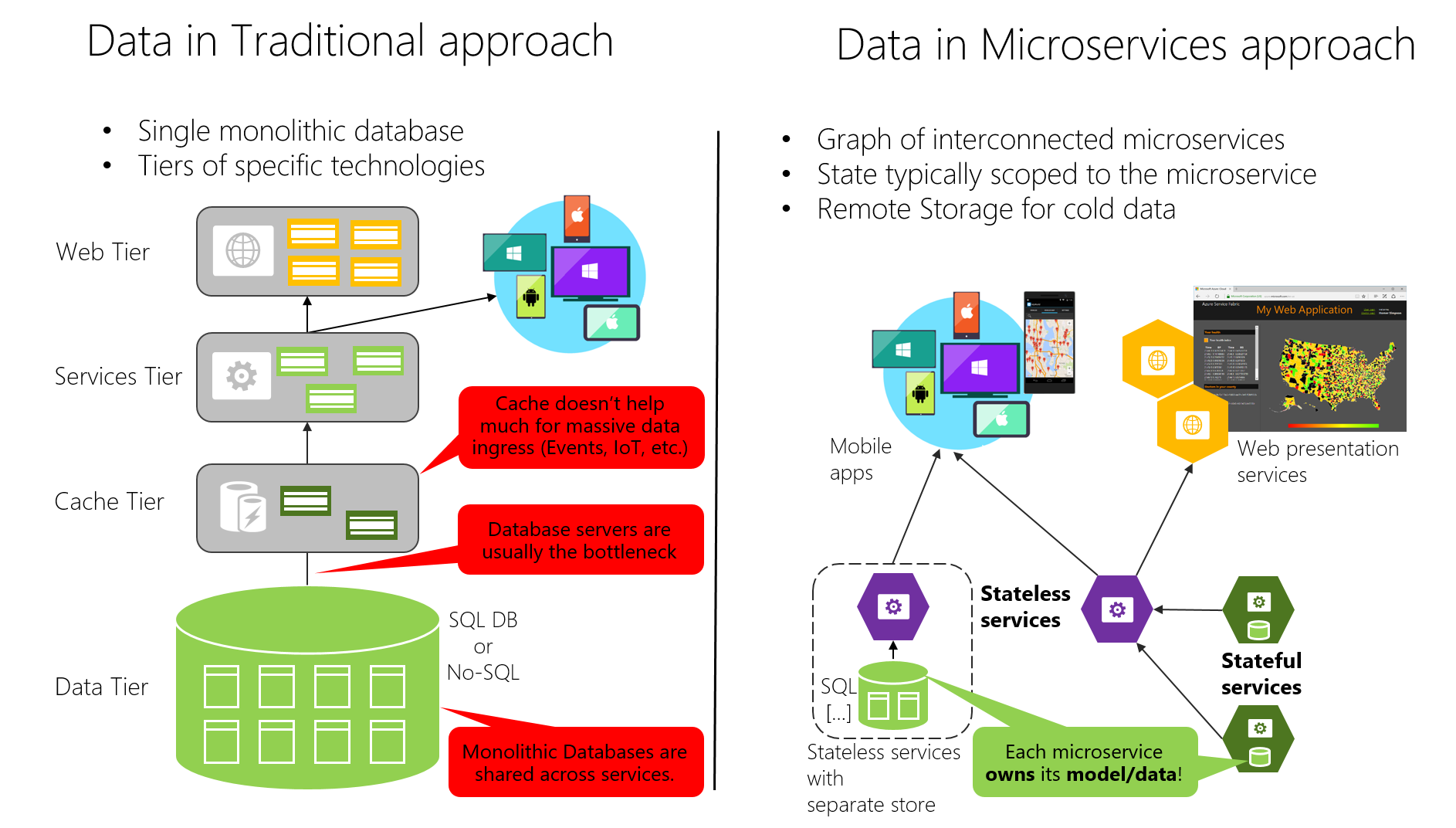
Figura 4-7. Comparação de soberania de dados: banco de dados monolítico x microsserviços
Na abordagem tradicional, há um único banco de dados individual entre todos os serviços, normalmente em uma arquitetura em camadas. Na abordagem de microsserviços, cada microsserviço possui o modelo/dados. A abordagem de banco de dados centralizado aparenta ser mais simples inicialmente e parece permitir a reutilização de entidades em subsistemas diferentes para tornar tudo consistente. Mas a realidade é que você acaba com uma quantidade enorme de tabelas que servem para muitos subsistemas diferentes e incluem atributos e colunas que não são necessárias na maioria dos casos. É como tentar usar o mesmo mapa físico para uma caminhada em uma trilha pequena, uma viagem de carro de um dia e para aprender geografia.
Um aplicativo monolítico com um banco de dados relacional único conta com duas vantagens: transações ACID e a linguagem SQL, ambas em funcionamento em todas as tabelas e dados relacionados ao aplicativo. Essa abordagem é uma maneira fácil de gravar consultas que combinam dados de diversas tabelas.
No entanto, o acesso a dados se tornará muito mais complicado quando você mudar para uma arquitetura de microsserviços. Mesmo ao usar as transações ACID dentro de um microsserviço ou Contexto Delimitado, será fundamental considerar que os dados pertencentes a cada microsserviço são particulares desse microsserviço e deverão ser acessados apenas de forma síncrona por meio dos pontos de extremidade de API (REST, gRPC, SOAP, etc) ou de forma assíncrona por meio de mensagens (AMQP ou similar).
Encapsular os dados garante que os microsserviços sejam acoplados de forma flexível e evoluam de modo independente. Se vários serviços acessarem os mesmos dados, as atualizações de esquema exigirão atualizações coordenadas de todos os serviços. Isso interrompe a autonomia do ciclo de vida do microsserviço. Entretanto, as estruturas de dados distribuídos impedem você de realizar transações ACID nos microsserviços. Por sua vez, isso significa que é necessário utilizar consistência eventual quando um processo de negócios abrange vários microsserviços. Isso é muito mais difícil de implementar do que junções SQL, porque você não pode criar restrições de integridade nem usar transações distribuídas entre bancos de dados separados, conforme explicaremos mais adiante. Da mesma forma, muitos outros recursos do banco de dados relacional não estão disponíveis em vários microsserviços.
Além disso, microsserviços diferentes geralmente usam tipos diferentes de bancos de dados. Aplicativos modernos armazenam e processam tipos de dados diversificados e um banco de dados relacional nem sempre é a melhor opção. Em alguns casos de uso, um banco de dados NoSQL como o Azure CosmosDB ou o MongoDB podem ter um modelo de dados mais conveniente e oferecer desempenho e escalabilidade melhores que um banco de dados SQL como o SQL Server ou o Banco de Dados SQL do Azure. Em outros casos, um banco de dados relacional ainda é a melhor abordagem. Portanto, aplicativos baseados em microsserviço geralmente usam uma combinação de bancos de dados SQL e NoSQL, chamada às vezes de abordagem de persistência poliglota.
Uma arquitetura particionada e de persistência poliglota para armazenamento de dados traz muitos benefícios. Entre eles, serviços acoplados de forma flexível, desempenho e escalabilidade melhores e capacidade de gerenciamento. No entanto, essa arquitetura pode apresentar alguns desafios relacionados ao gerenciamento de dados distribuídos, conforme explicado mais adiante neste capítulo, em "Identificar os limites do modelo de domínio".
A relação entre os microsserviços e o padrão do Contexto Delimitado
O conceito de microsserviço tem origem no padrão de BC (Contexto Delimitado) na DDD (design controlado por domínio). A DDD aborda modelos grandes dividindo-os em vários BCs e explicitando seus limites. Cada BC precisa ter um modelo e banco de dados próprios. Da mesma forma, cada microsserviço tem seus próprios dados relacionados. Além disso, cada BC geralmente tem uma linguagem ubíqua própria para ajudar na comunicação entre desenvolvedores de software e especialistas em domínio.
Esses termos (principalmente entidades de domínio) na linguagem ubíqua podem ter nomes diferentes em Contextos Delimitados distintos, mesmo quando entidades de domínio diferentes compartilham a mesma identidade (ou seja, a ID exclusiva utilizada para ler a entidade do armazenamento). Por exemplo, em um Contexto Delimitado de perfil de usuário, a entidade de domínio Usuário pode compartilhar a identidade com a entidade de domínio Comprador no Contexto Delimitado de pedido.
Desse modo, um microsserviço é como um Contexto Delimitado, mas também especifica seu caráter de serviço distribuído. Ele é criado como um processo separado para cada Contexto Delimitado e precisa usar os protocolos distribuídos mencionados anteriormente, como HTTP/HTTPS, WebSockets ou AMQP. Entretanto, o padrão do Contexto Delimitado não especifica se é um serviço distribuído ou simplesmente um limite lógico (como um subsistema genérico) em um aplicativo de implantação monolítica.
É importante salientar que definir um serviço para cada Contexto Delimitado é uma boa maneira de começar. Porém, não é preciso restringir seu design a ele. Às vezes, é necessário criar um Contexto Delimitado ou microsserviço de negócios composto de vários serviços físicos. Mas, por fim, ambos os padrões — Contexto Delimitado e microsserviço — estão intimamente relacionados.
A DDD se beneficia dos microsserviços ao obter limites reais na forma de microsserviços distribuídos. Contudo, ideias como o não compartilhamento do modelo entre os microsserviços também são desejáveis em um Contexto Delimitado.
Recursos adicionais
Chris Richardson. Padrão: banco de dados por serviço
https://microservices.io/patterns/data/database-per-service.htmlMartin Fowler. BoundedContext
https://martinfowler.com/bliki/BoundedContext.htmlMartin Fowler. PolyglotPersistence
https://martinfowler.com/bliki/PolyglotPersistence.htmlAlberto Brandolini. Design controlado por domínio estratégico com mapeamento de contexto
https://www.infoq.com/articles/ddd-contextmapping
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de