Tutorial: detectar sinais de parada em imagens com o Model Builder
Saiba como criar um modelo de detecção de objetos usando o ML.NET Model Builder e o Azure Machine Learning para detectar e localizar sinais de parada em imagens.
Neste tutorial, você aprenderá a:
- Preparar e compreender os dados
- Criar um arquivo de configuração do Model Builder
- Escolher o cenário
- Escolher o ambiente de treinamento
- Carregar os dados
- Treinar o modelo
- Avaliar o modelo
- Usar o modelo para previsões
Pré-requisitos
Para ver uma lista de pré-requisitos e instruções de instalação, acesse o guia de instalação do Model Builder.
Visão geral da detecção de objeto do Model Builder
A detecção de objetos é um problema da pesquisa visual computacional. Embora esteja bem relacionada à classificação de imagem, a detecção de objetos executa a classificação de imagem em uma escala mais granular. A detecção de objetos localiza e categoriza entidades dentro de imagens. Os modelos de detecção de objetos são normalmente treinados usando redes neurais e de aprendizado profundo. Para obter mais informações, consulte Aprendizado profundo versus aprendizado de máquina.
Use a detecção de objetos quando as imagens contiverem vários objetos de tipos diferentes.

Alguns casos de uso para detecção de objetos incluem:
- Carros autônomos
- Robótica
- Detecção Facial
- Segurança do local de trabalho
- Contagem de objetos
- Reconhecimento de atividades
Este exemplo cria um aplicativo de console do .NET Core em C# que detecta sinais de parada em imagens in usando um modelo de machine learning criado com o Model Builder. Encontre o código-fonte deste tutorial no repositório dotnet/machinelearning-samples do GitHub.
Preparar e compreender os dados
O conjunto de dados Stop Sign consiste em 50 imagens baixadas do Unsplash, cada uma contendo pelo menos um sinal de parada.
Criar um novo projeto VoTT
Baixe o conjunto de dados de 50 sinais de parada em imagens e descompacte.
Baixe a VoTT (Ferramenta de Marcação de Objeto Visual).
Abra a VoTT e selecione Novo projeto.
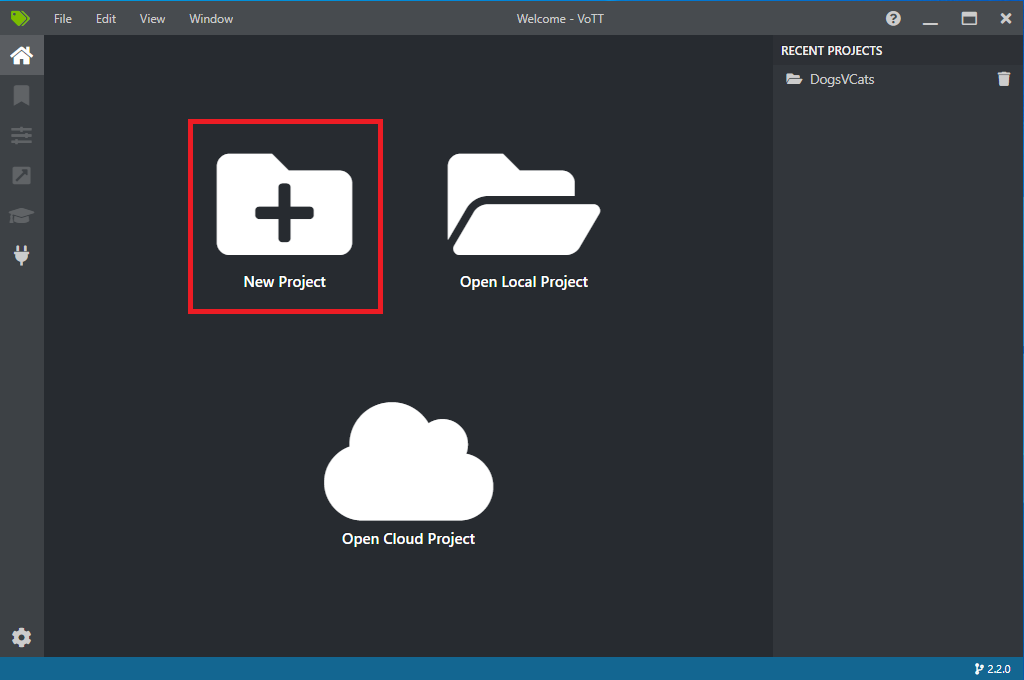
Nas Configurações do projeto, altere o Nome para exibição para "StopSignObjDetection".
Altere o Token de segurança para Gerar novo token de segurança.
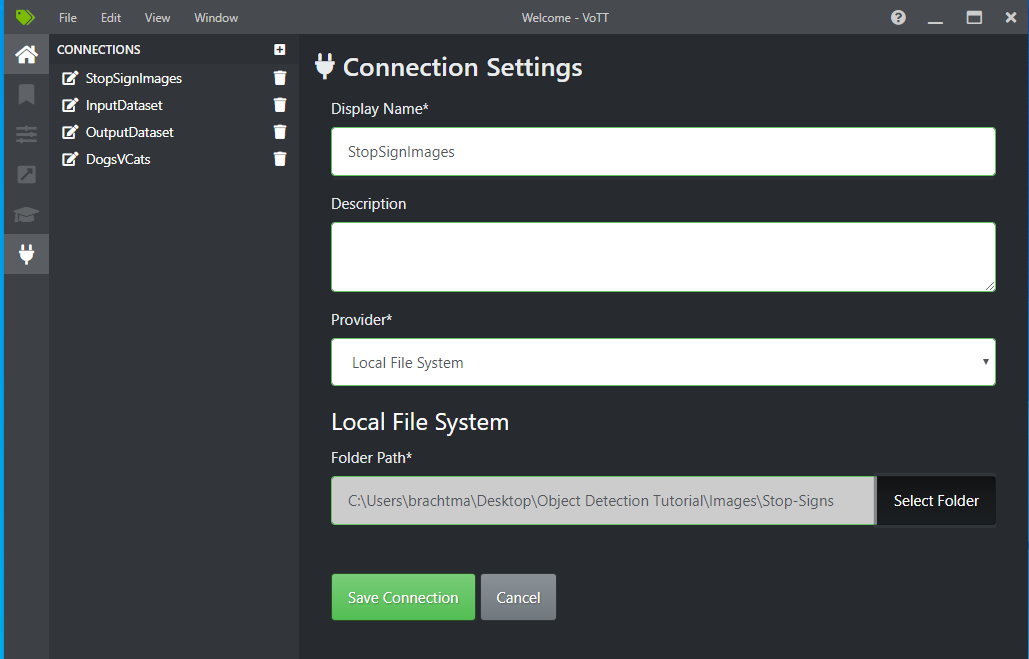
Ao lado da Conexão de origem, selecione Adicionar conexão.
Nas Configurações de conexão, altere o Nome de exibição da conexão de origem para "StopSignImages" e selecione Sistema de arquivos local como Provedor. Para o Caminho da pasta, selecione a pasta Stop-Signs que contém as 50 imagens de treinamento e selecione Salvar conexão.
Em Configurações do projeto, altere a Conexão de origem para StopSignImages (a conexão que você acabou de criar).
Altere a Conexão de destino para StopSignImages também. As Configurações do projeto agora devem ser semelhantes a esta captura de tela:
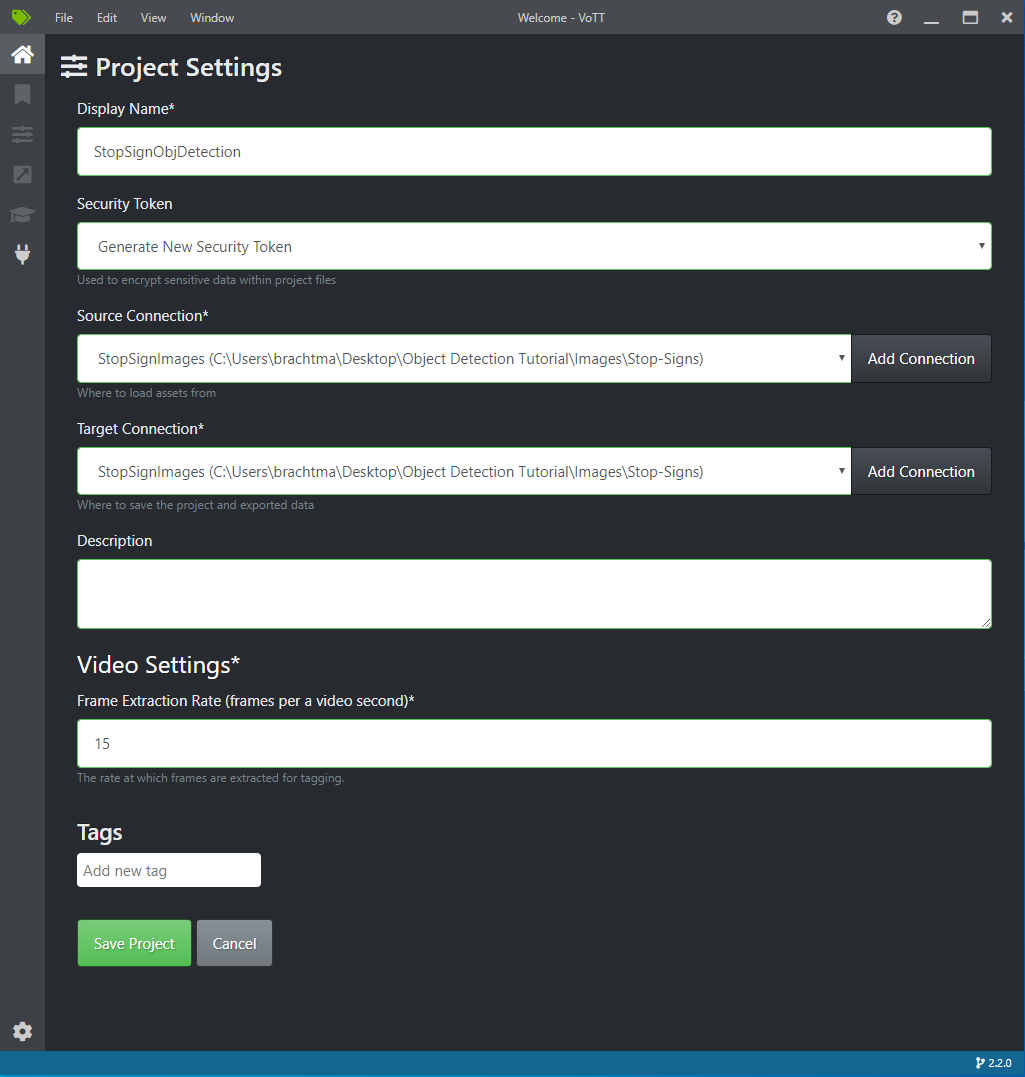
Selecione Salvar projeto.
Adicionar imagens de marca e rótulo
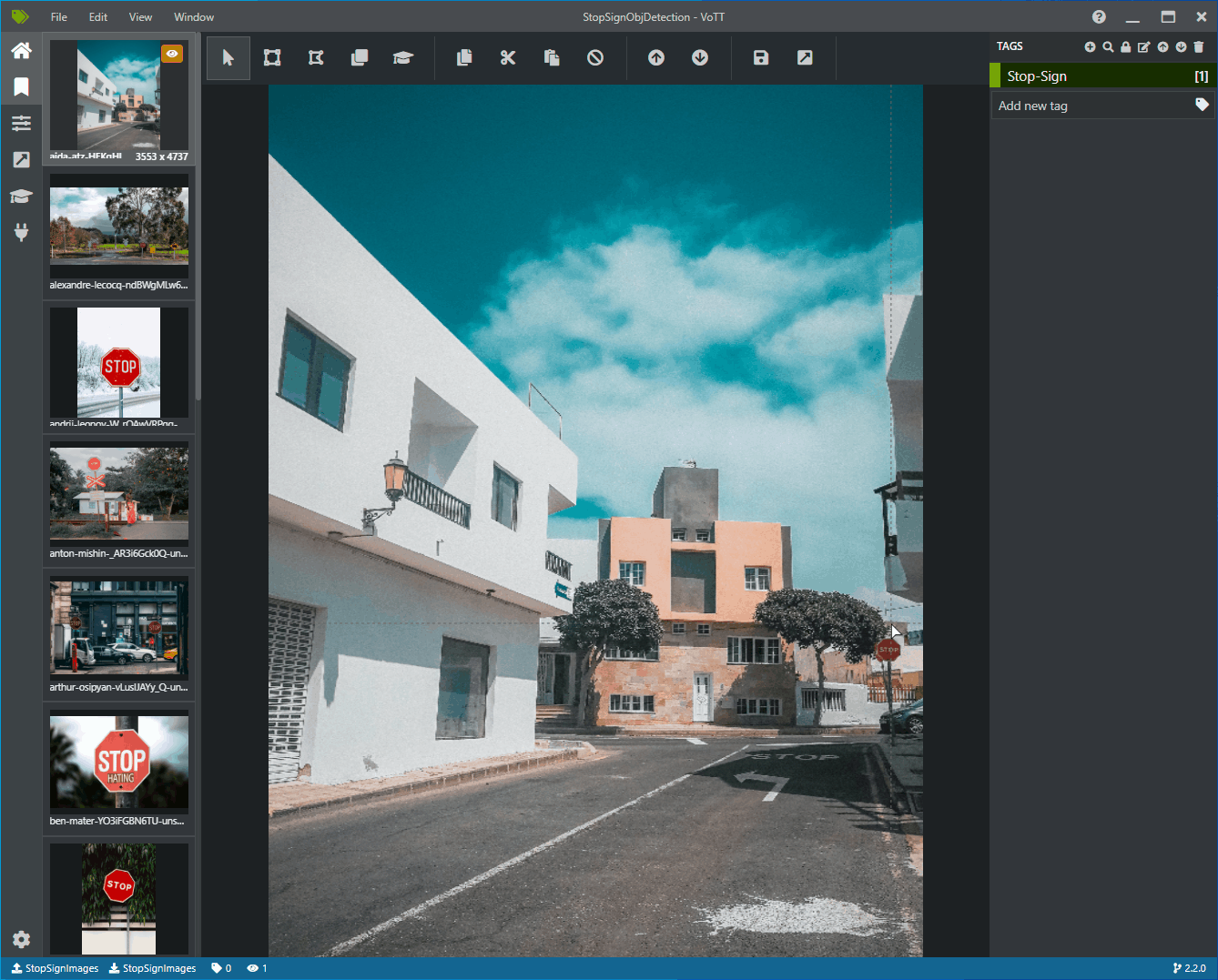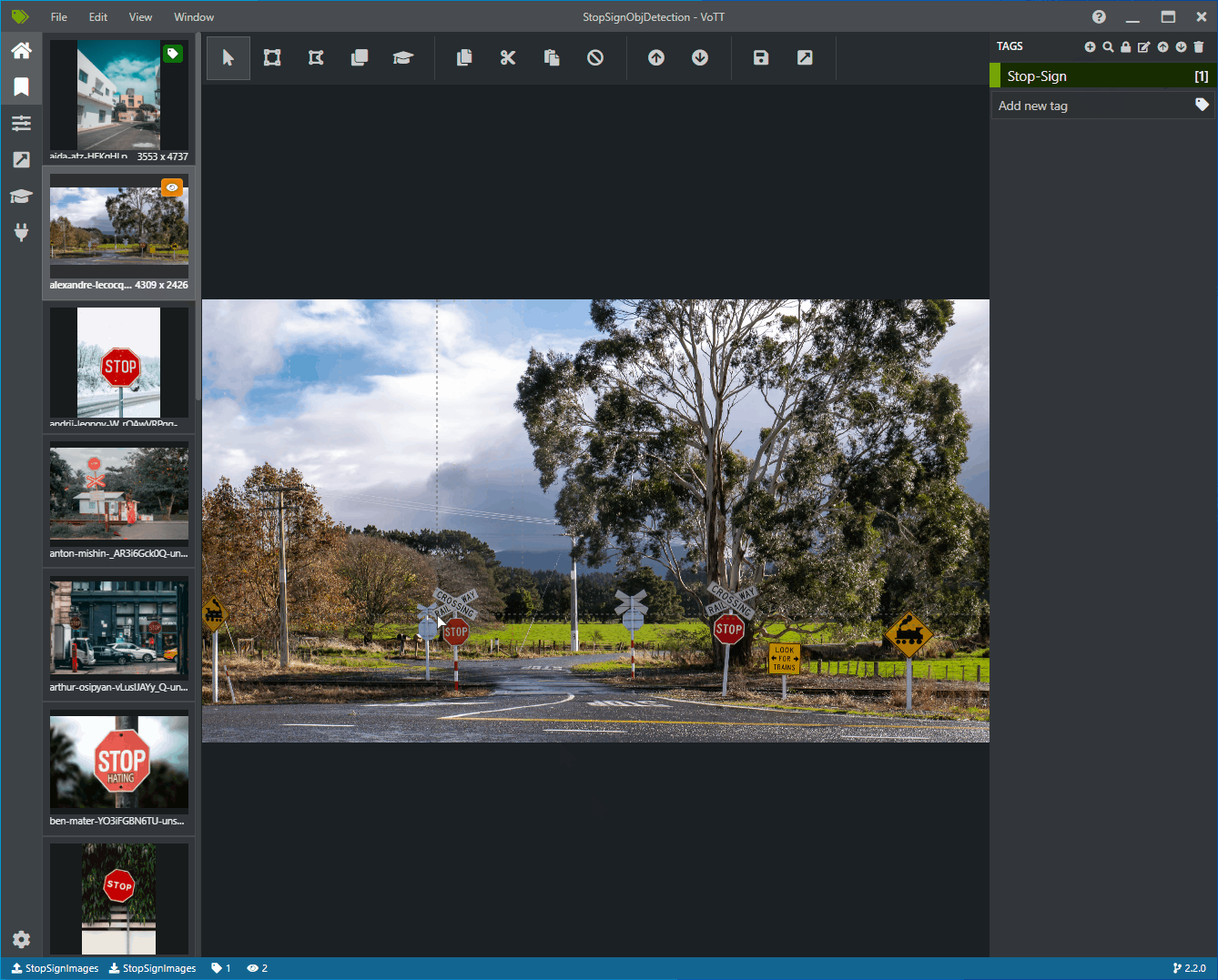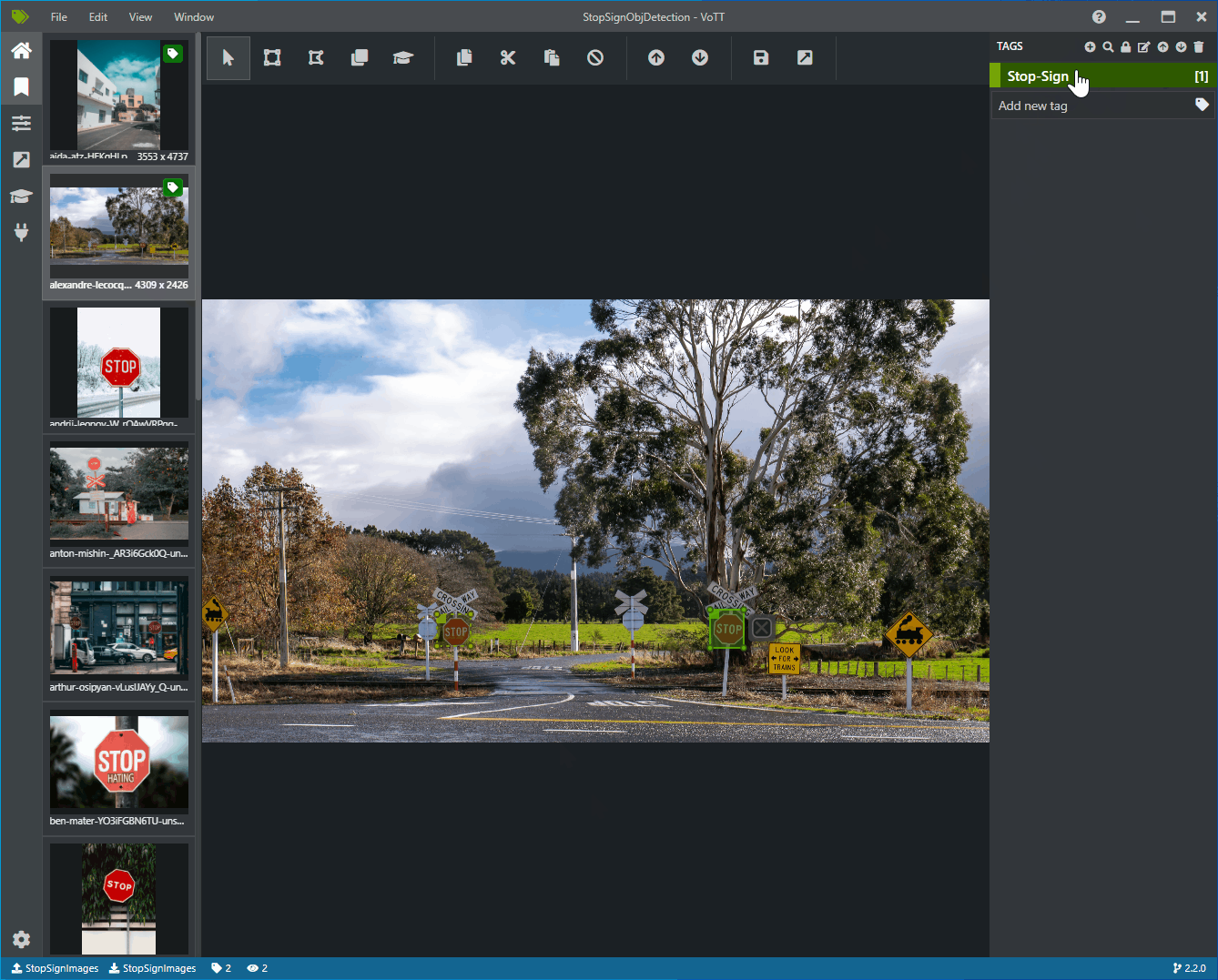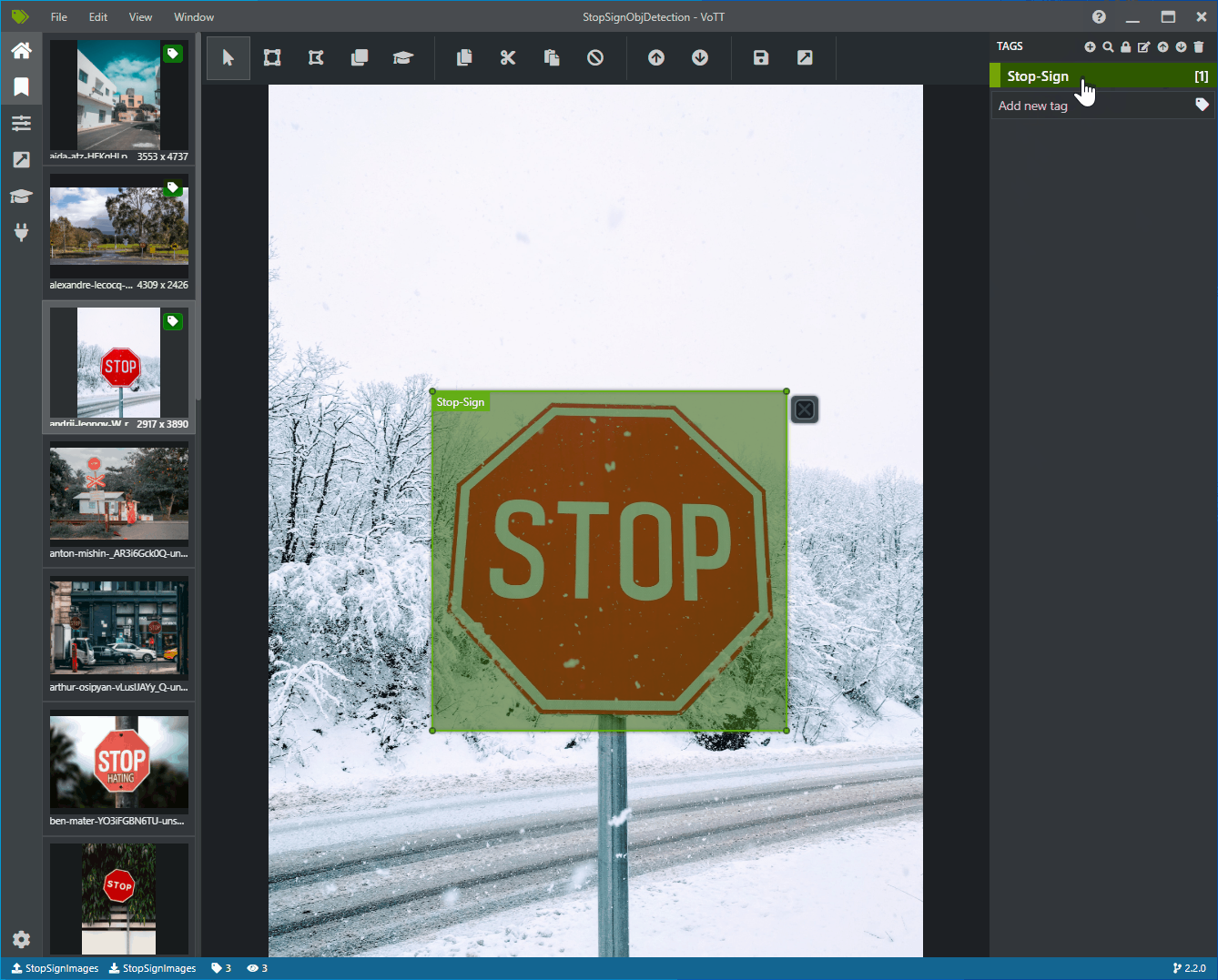
Agora você deve ver uma janela com imagens de visualização de todas as imagens de treinamento à esquerda, uma visualização da imagem selecionada no meio e uma coluna Marcas à direita. Essa tela é o Editor de marcas.
Selecione o primeiro ícone (em forma de adição) na barra de ferramentas Marcas para adicionar uma nova marca.

Nomeie a marca "Stop-Sign" e toque em Enter no teclado.

Clique e arraste para desenhar um retângulo em torno de cada sinal de parada na imagem. Se o cursor não permitir que você desenhe um retângulo, tente selecionar a ferramenta Desenhar retângulo na barra de ferramentas na parte superior ou use o atalho de teclado R.
Depois de desenhar o retângulo, selecione a marca Stop-Sign que você criou nas etapas anteriores para adicionar a marca à caixa delimitadora.
Clique na imagem de visualização da próxima imagem no conjunto de dados e repita esse processo.
Continue as etapas 3 a 4 para cada sinal de parada em cada imagem.
Exportar seu JSON de VoTT
Depois de rotular todas as suas imagens de treinamento, você poderá exportar o arquivo que será usado pelo Model Builder para treinamento.
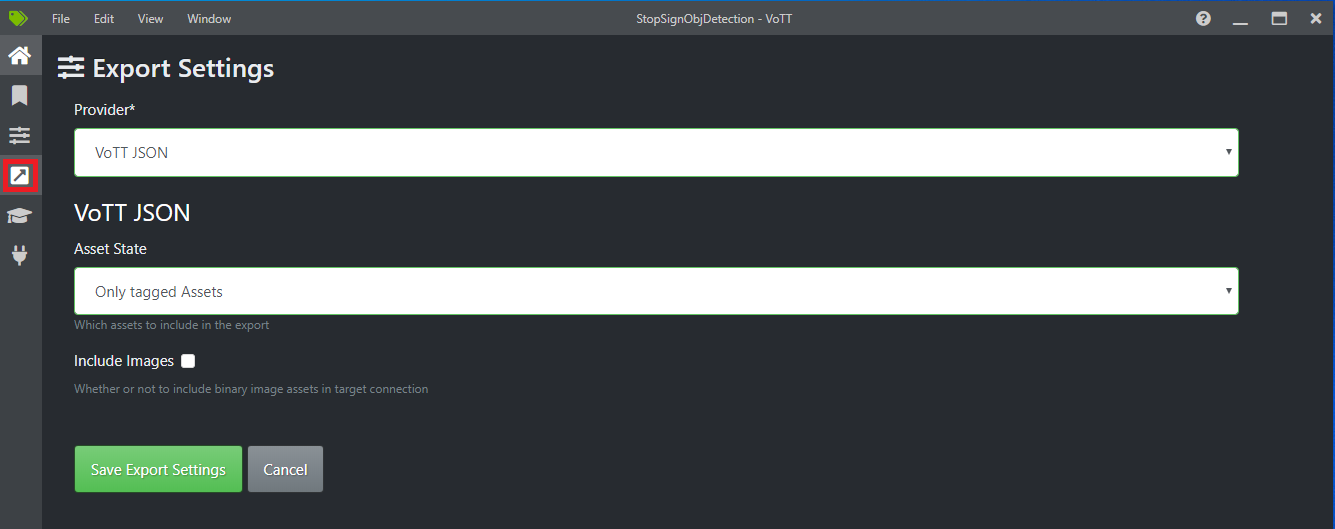
Selecione o quarto ícone na barra de ferramentas à esquerda (aquele com a seta diagonal em uma caixa) para ir até as Configurações de exportação.
Deixe o Provedor como JSON de VoTT.
Altere o Estado do ativo para Apenas ativos marcados.
Desmarque Incluir imagens. Se você incluir as imagens, as imagens de treinamento serão copiadas para a pasta de exportação gerada, o que não é necessário.
Selecione Salvar configurações de exportação.
Volte ao Editor de marcas (o segundo ícone na barra de ferramentas à esquerda em forma de faixa de opções). Na barra de ferramentas superior, selecione o ícone Exportar projeto (o último ícone em forma de seta em uma caixa) ou use o atalho de teclado Ctrl+E.

Essa exportação criará uma nova pasta chamada vott-json-export na pasta Stop-Sign-Images e gerará um arquivo JSON chamado StopSignObjDetection-export nessa nova pasta. Você usará esse arquivo JSON nas próximas etapas para treinar um modelo de detecção de objetos no Model Builder.
Criar um aplicativo de console
No Visual Studio, crie um aplicativo de console do .NET Core em C# chamado StopSignDetection.
Criar um arquivo mbconfig
- No Gerenciador de Soluções, clique com o botão direito do mouse no projeto StopSignDetection e selecione Adicionar>Modelo de machine learning... para abrir a interface do usuário do Model Builder.
- Na caixa de diálogo, nomeie o projeto do Model Builder como StopSignDetection e clique em Adicionar.
Escolha um cenário
Para este exemplo, o cenário é a detecção de objetos. Na etapa Cenário do Model Builder, selecione o cenário Detecção de objetos.
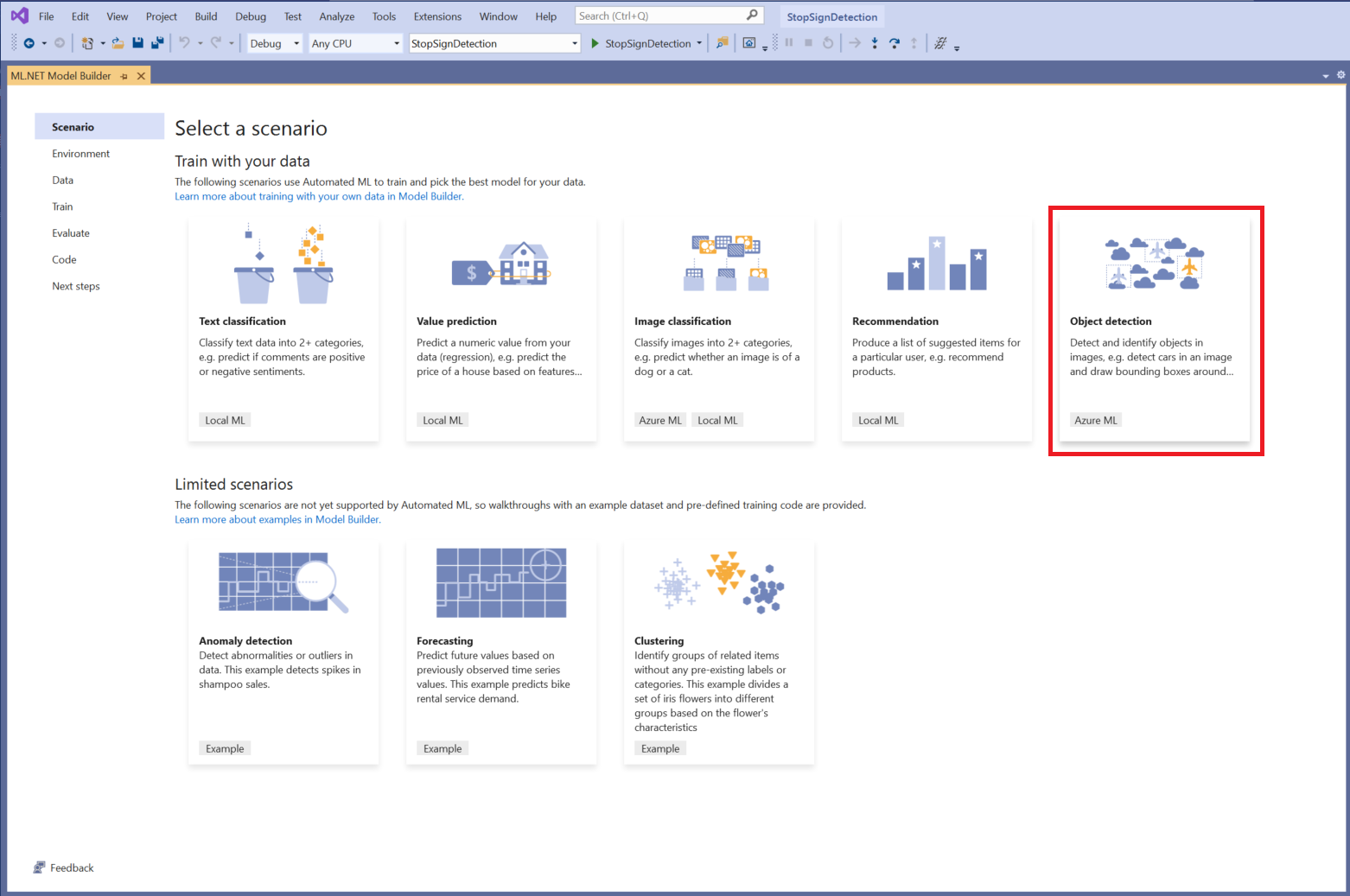
Se você não vir Detecção de objetos na lista de cenários, talvez seja necessário atualizar a versão do Model Builder.
Escolher o ambiente de treinamento
Atualmente, o Model Builder dá suporte a modelos de detecção de objetos de treinamento apenas com o Azure Machine Learning, portanto, o ambiente de treinamento do Azure é selecionado por padrão.
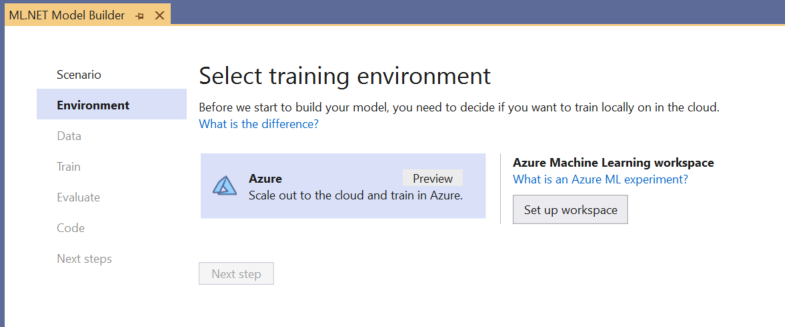
Para treinar um modelo usando o Azure ML, você deve criar um experimento do Azure ML do Model Builder.
Um experimento do Azure ML é um recurso que encapsula a configuração e os resultados de uma ou mais execuções de treinamento de machine learning.
Para criar um experimento do Azure ML, primeiro você precisa configurar seu ambiente no Azure. Um experimento precisa do seguinte para ser executado:
- Uma assinatura do Azure
- Um workspace: um recurso do Azure ML que fornece um local central para todos os recursos e artefatos do Azure ML criados como parte de uma execução de treinamento.
- Uma computação: uma computação do Azure Machine Learning é uma VM Linux baseada em nuvem usada para treinamento. Saiba mais sobre os tipos de computação compatíveis com o Model Builder.
Configuração de um workspace do Azure ML
Para configurar o ambiente:
Selecione o botão Configurar workspace.
Na caixa de diálogo Criar novo experimento, selecione sua assinatura do Azure.
Selecione um workspace existente ou crie um novo workspace do Azure ML.
Quando você cria um novo workspace, os seguintes recursos são provisionados:
- Workspace do Azure Machine Learning
- Armazenamento do Azure
- Azure Application Insights
- Registro de Contêiner do Azure
- Cofre de Chave do Azure
Como resultado, esse processo pode levar alguns minutos.
Selecione uma computação existente ou crie uma nova computação do Azure ML. Esse processo pode levar alguns minutos.
Deixe o nome do experimento padrão e selecione Criar.
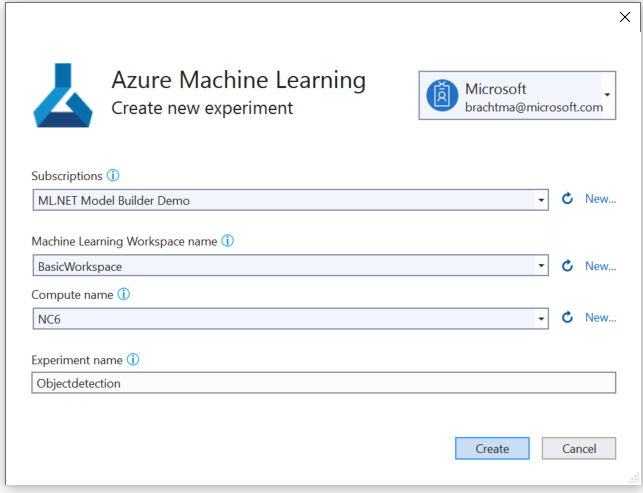
O primeiro experimento é criado, e o nome do experimento é registrado no workspace. Todas as execuções subsequentes (se o mesmo nome do experimento for usado) serão registradas como parte do mesmo experimento. Caso contrário, um novo experimento será criado.
Se você estiver satisfeito com a configuração, selecione o botão Próxima etapa no Model Builder para ir para a etapa Dados.
Carregar os dados
Na etapa Dados do Model Builder, você selecionará seu conjunto de dados de treinamento.
Importante
Atualmente, o Model Builder aceita apenas o formato JSON gerado pela VoTT.
Selecione o botão dentro da seção Entrada e use o Explorador de Arquivos para localizar o
StopSignObjDetection-export.json, que deve estar localizado no diretório Stop-Signs/vott-json-export.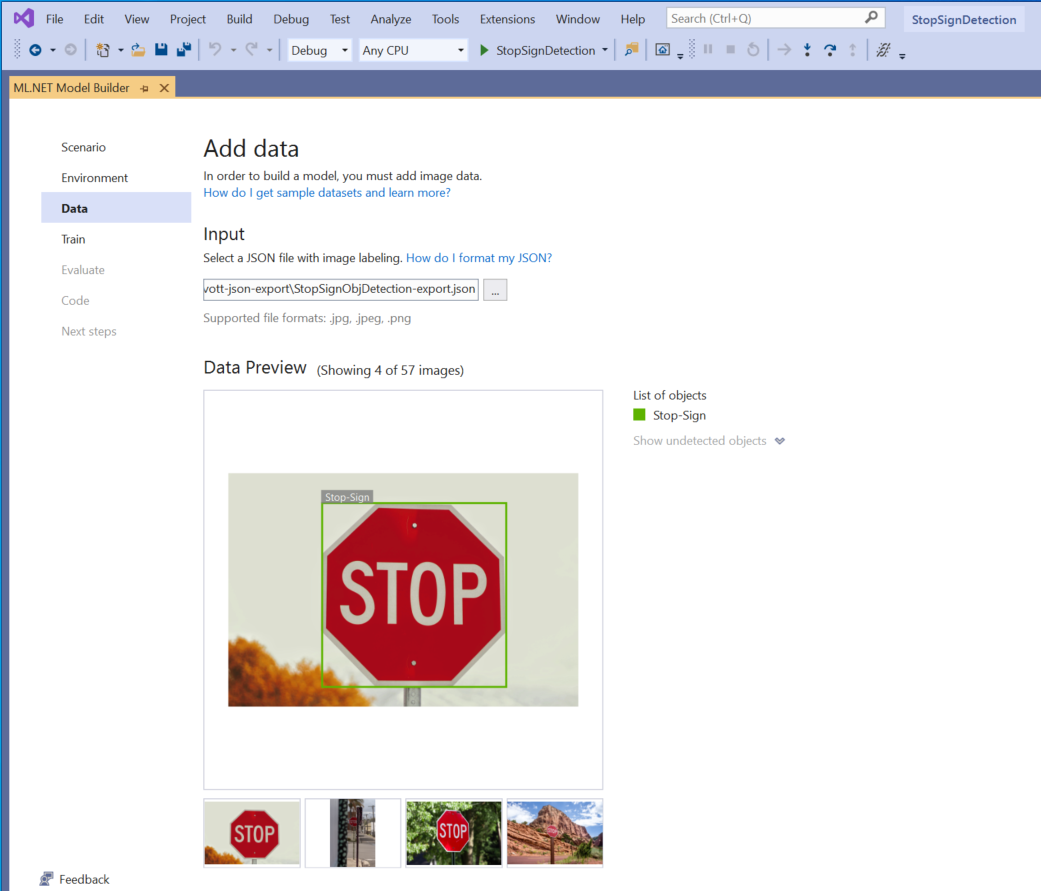
Se os dados parecerem corretos na Visualização de Dados, selecione Próxima etapa para passar para a etapa Treinar.
Treinar o modelo
A próxima etapa é treinar seu modelo.
Na tela Treinar do Model Builder, selecione o botão Iniciar treinamento.
Neste ponto, seus dados são carregados no Armazenamento do Microsoft Azure, e o processo de treinamento começa no Azure ML.
O processo de treinamento leva algum tempo, e a quantidade de tempo pode variar dependendo do tamanho da computação selecionada, bem como da quantidade de dados. Na primeira vez que um modelo é treinado no Azure, você pode esperar um tempo de treinamento um pouco mais longo porque os recursos precisam ser provisionados. Para este exemplo de 50 imagens, o treinamento levou cerca de 16 minutos.
Você pode acompanhar o progresso de suas execuções no portal do Azure Machine Learning selecionando o link Execução atual do Monitor em portal do Azure no Visual Studio.
Depois que o treinamento for concluído, selecione o botão Próxima etapa para passar para a etapa Avaliar.
Avaliar o modelo
Na tela Avaliar, você obtém uma visão geral dos resultados do processo de treinamento, incluindo a precisão do modelo.
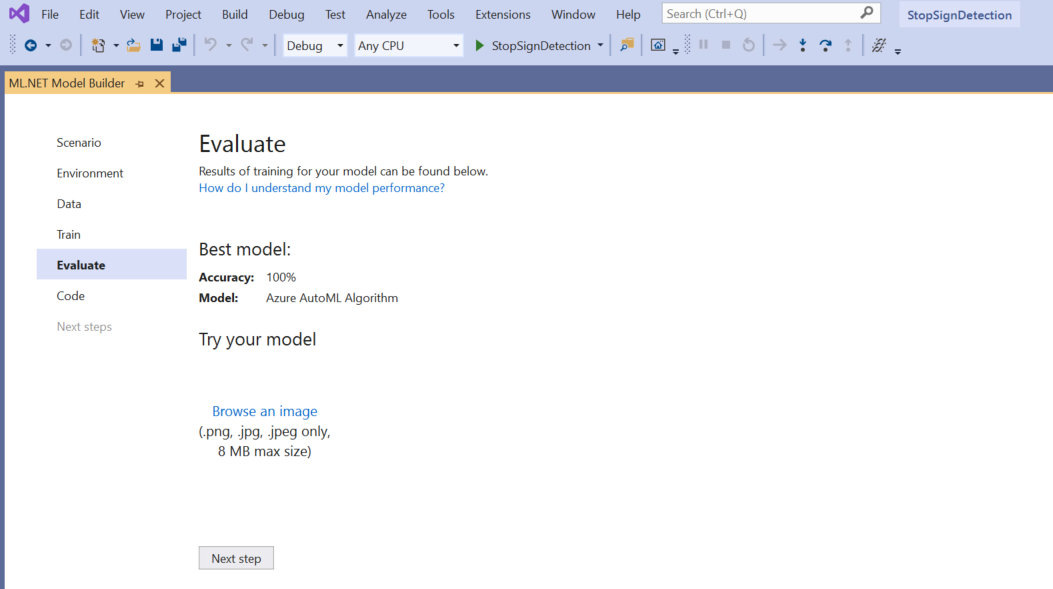
Nesse caso, a precisão diz 100%, o que significa que o modelo é mais do que provável sobreajuste devido a poucas imagens no conjunto de dados.
Você pode usar a experiência Experimentar seu modelo para verificar rapidamente se o modelo está funcionando conforme o esperado.
Selecione Procurar uma imagem e forneça uma imagem de teste, preferencialmente aquela que o modelo não usou como parte do treinamento.
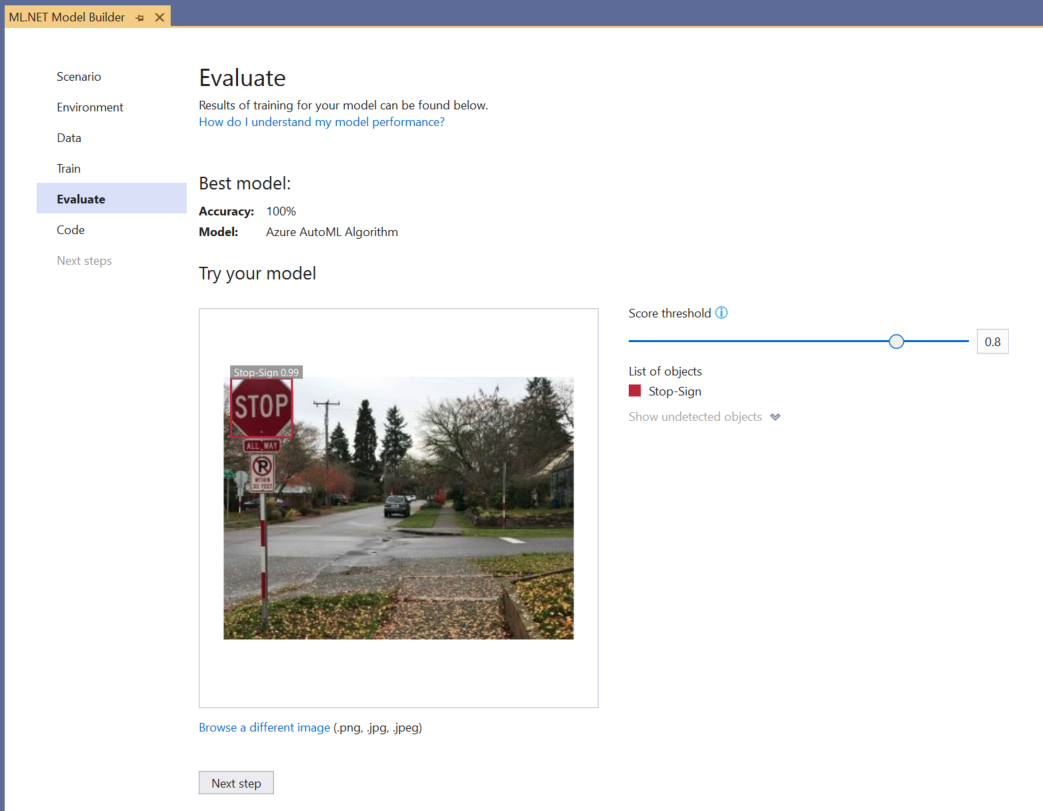
A pontuação mostrada em cada caixa delimitadora detectada indica a confiança do objeto detectado. Por exemplo, na captura de tela acima, a pontuação na caixa delimitadora ao redor do sinal de parada indica que o modelo tem 99% de certeza de que o objeto detectado é um sinal de parada.
O Limite de pontuação, que pode ser aumentado ou reduzido com o controle deslizante de limite, adicionará e removerá objetos detectados com base em suas pontuações. Por exemplo, se o limite for 0,51, o modelo mostrará apenas objetos que têm uma pontuação de confiança igual a 0,51 ou superior. Conforme você aumenta o limite, verá objetos menos detectados e, à medida que diminuir o limite, verá mais objetos detectados.
Se você não estiver satisfeito com suas métricas de precisão, uma maneira fácil de tentar melhorar a precisão do modelo é usar mais dados. Caso contrário, selecione o link Próxima etapa para passar para a etapa Consumir no Model Builder.
(Opcional) Consumir o modelo
Esta etapa terá modelos de projeto que você poderá usar para consumir o modelo. Ela é opcional, e você pode escolher o método que melhor atende às suas necessidades sobre como fornecer o modelo.
- Aplicativo de Console
- API Web
Aplicativo de Console
Ao adicionar um aplicativo de console à sua solução, você precisará nomear o projeto.
Nomeie o projeto do console StopSignDetection_Console.
Clique em Adicionar à solução para adicionar o projeto à solução atual.
Executar o aplicativo.
A saída gerada pelo programa deve ser semelhante ao snippet a seguir:
Predicted Boxes: Top: 73.225296, Left: 256.89764, Right: 533.8884, Bottom: 484.24243, Label: stop-sign, Score: 0.9970765
API Web
Ao adicionar uma API Web à sua solução, você precisará nomear o projeto.
Nomeie o projeto da API Web StopSignDetection_API.
Clique em Adicionar à solução para adicionar o projeto à solução atual.
Executar o aplicativo.
Abra o PowerShell e insira o código a seguir, em que PORT é a porta que o seu aplicativo escuta.
$body = @{ ImageSource = <Image location on your local machine> } Invoke-RestMethod "https://localhost:<PORT>/predict" -Method Post -Body ($body | ConvertTo-Json) -ContentType "application/json"Se houver sucesso, a saída será semelhante ao texto abaixo.
boxes labels scores boundingBoxes ----- ------ ------ ------------- {339.97797, 154.43184, 472.6338, 245.0796} {1} {0.99273646} {}- A coluna
boxesfornece as coordenadas da caixa delimitadora do objeto detectado. Os valores aqui pertencem às coordenadas esquerda, superior, direita e inferior, respectivamente. labelssão o índice dos rótulos previstos. Nesse caso, o valor 1 é um sinal de parada.scoresdefine o quão confiante é o modelo de a que a caixa delimitadora pertence para esse rótulo.
Observação
(Opcional) As coordenadas da caixa delimitadora são normalizadas para uma largura de 800 pixels e uma altura de 600 pixels. Para dimensionar as coordenadas da caixa delimitadora para sua imagem em mais pós-processamento, você precisa:
- Multiplicar as coordenadas superior e inferior pela altura da imagem original e multiplicar as coordenadas esquerda e direita pela largura da imagem original.
- Dividir as coordenadas superior e inferior por 600 e dividir as coordenadas esquerda e direita por 800.
Por exemplo, dadas as dimensões de imagem originais,
actualImageHeighteactualImageWidth, e umModelOutputchamadoprediction, o seguinte snippet de código mostra como dimensionar as coordenadasBoundingBox:var top = originalImageHeight * prediction.Top / 600; var bottom = originalImageHeight * prediction.Bottom / 600; var left = originalImageWidth * prediction.Left / 800; var right = originalImageWidth * prediction.Right / 800;Uma imagem pode ter mais de uma caixa delimitadora, portanto, o mesmo processo precisa ser aplicado a cada uma das caixas delimitadoras na imagem.
- A coluna
Parabéns! Você criou com êxito um modelo de machine learning para detectar sinais de parada em imagens usando o Model Builder. Encontre o código-fonte deste tutorial no repositório dotnet/machinelearning-samples do GitHub.
Recursos adicionais
Para saber mais sobre os tópicos mencionados neste tutorial, visite os seguintes recursos:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de