Tratar falhas parciais
Dica
Esse conteúdo é um trecho do eBook da Arquitetura de Microsserviços do .NET para os Aplicativos .NET em Contêineres, disponível no .NET Docs ou como um PDF para download gratuito que pode ser lido offline.

Em sistemas distribuídos como aplicativos baseados em microsserviços, há um risco de falha parcial sempre presente. Por exemplo, um único microsserviço/contêiner pode falhar ou pode não estar disponível para responder por um curto período, ou um único servidor ou VM pode falhar. Como clientes e serviços são processos separados, um serviço pode não conseguir responder de forma oportuna a uma solicitação do cliente. O serviço pode estar sobrecarregado e respondendo a solicitações de maneira muito lenta ou pode simplesmente não estar acessível durante um curto período devido a problemas de rede.
Por exemplo, considere a página de detalhes Ordem do aplicativo de exemplo eShopOnContainers. Se o microsserviço de ordenação não estiver respondendo quando o usuário tentar enviar uma ordem, uma implementação incorreta do processo do cliente (o aplicativo Web MVC) – por exemplo, se o código do cliente usasse RPCs síncronos sem tempo limite – bloqueará threads indefinidamente que estão aguardando uma resposta. Além de criar uma experiência de usuário ruim, toda espera sem resposta consome ou bloqueia um thread, e os threads são extremamente valiosos em aplicativos altamente escalonáveis. Se houver muitos threads bloqueados, o runtime do aplicativo poderá eventualmente ficar sem threads. Nesse caso, o aplicativo poderá ficar globalmente sem resposta, em vez de apenas parcialmente sem resposta, como mostra a Figura 8-1.

Figura 8-1. Falhas parciais devido a dependências que afetam a disponibilidade do thread de serviço
Em um aplicativo grande baseado em microsserviços, falhas parciais poderão ser amplificadas, principalmente se a maioria da interação interna dos microsserviços for baseada em chamadas HTTP síncronas (o que é considerado um antipadrão). Pense em um sistema que recebe milhões de chamadas de entrada por dia. Se o sistema tiver um design ruim que é baseado em longas cadeias de chamadas HTTP síncronas, essas chamadas de entrada poderão resultar em muito mais milhões de chamadas de saída (vamos supor uma razão de 1:4) a dezenas de microsserviços internos como dependências síncronas. Essa situação é mostrada na Figura 8-2, especialmente na dependência nº 3, que inicia uma cadeia, chamando a dependência nº 4, que chama o nº 5.
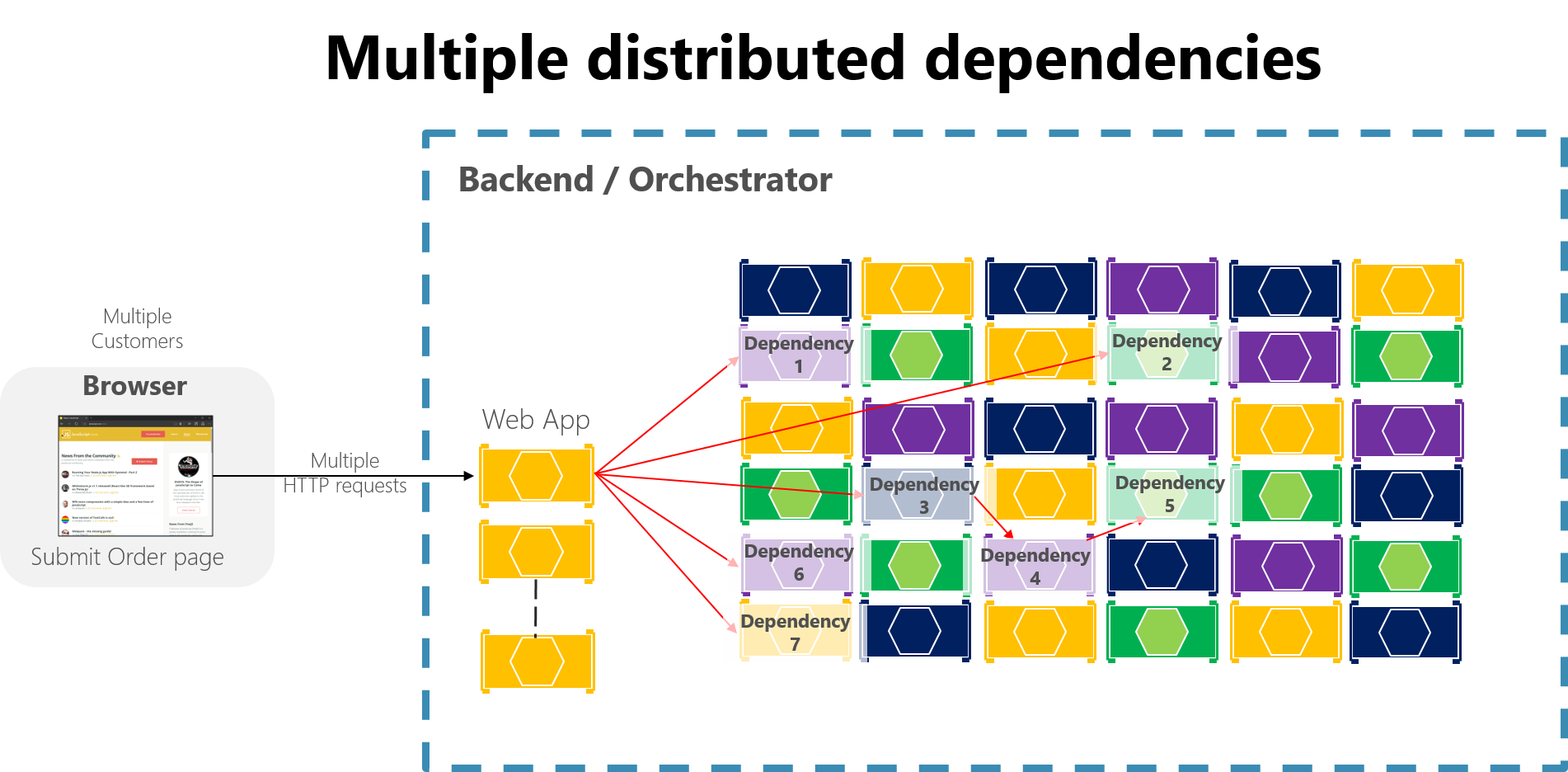
Figura 8-2. O impacto de ter um design incorreto com longas cadeias de solicitações HTTP
A falha intermitente é garantida em um sistema distribuído e baseado em nuvem, mesmo quando cada dependência têm uma disponibilidade excelente. Esse um fato que você precisa considerar.
Se você não criar nem implementar técnicas para garantir a tolerância a falhas, até mesmo pequenos tempos de inatividade poderão ser amplificados. Por exemplo, 50 dependências, cada uma com 99,99% de disponibilidade, poderia resultar em várias horas de tempo de inatividade por mês devido a esse efeito de ondulação. Quando uma dependência de microsserviço falhar ao manipular um alto volume de solicitações, essa falha poderá saturar rapidamente todos os threads de solicitação disponíveis em cada serviço e causar uma pane em todo o aplicativo.

Figura 8-3. Falha parcial amplificada por microsserviços com longas cadeias de chamadas HTTP síncronas
Para minimizar esse problema, na seção A integração assíncrona do microsserviço impõe a autonomia do microsserviço, esse guia indica o uso da comunicação assíncrona entre os microsserviços internos.
Além disso, é essencial que você crie seus aplicativos cliente e microsserviços para lidar com falhas parciais, ou seja, crie microsserviços e aplicativos cliente resilientes.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de