Arquitetura preferencial do Exchange 2019
A cada nova versão do Exchange Server para nossos clientes locais, atualizamos nossa Arquitetura Preferencial e discutimos quais mudanças gostaríamos que nossos clientes soubessem. Exchange Server 2013 nos trouxe a primeira das Arquiteturas Preferenciais na história moderna do Exchange e foi seguida com uma atualização para Exchange Server 2016 fornecendo refinamentos para as alterações que vieram com a versão de 2016. Com essa atualização para Exchange Server 2019, iteraremos na PA anterior para aproveitar novas tecnologias e melhorias.
A arquitetura preferencial
A PA é a recomendação de melhores práticas da equipe de engenharia Exchange Server para o que acreditamos ser a melhor arquitetura de implantação para Exchange Server 2019 em um ambiente local.
Embora o Exchange 2019 ofereça uma ampla variedade de opções de arquitetura para implantações locais, a arquitetura discutida aqui é a mais examinada. Embora haja outras arquiteturas de implantação com suporte, elas não são nossa prática recomendada.
Seguir a PA ajuda os clientes a se tornarem membros de uma comunidade de organizações com implantações de Exchange Server semelhantes. Essa estratégia permite o compartilhamento de conhecimento mais fácil e fornece uma resposta mais rápida a circunstâncias imprevistas. Nossa própria organização de suporte está ciente de como deve ser uma implantação de PA Exchange Server e impede que eles passem ciclos longos aprendendo e entendendo o ambiente altamente personalizado de um cliente antes de trabalhar com eles para uma resolução de caso de suporte.
O PA foi projetado com vários requisitos de negócios em mente, como a exigência de que a arquitetura seja capaz de:
Incluir alta disponibilidade dentro do datacenter e resiliência do site entre datacenters
Suporte a várias cópias de cada banco de dados, permitindo a ativação rápida
Reduzir o custo da infraestrutura de mensagens
Aumentar a disponibilidade otimizando em torno de domínios de falha e reduzindo a complexidade
A natureza prescritiva específica da PA significa que nem todos os clientes poderão implantá-lo palavra por palavra. Por exemplo, nem todos os nossos clientes têm vários data centers. Alguns de nossos clientes podem ter requisitos comerciais diferentes ou políticas internas que devem seguir que exigem uma arquitetura de implantação diferente. Se você se enquadra nessas categorias e deseja implantar o Exchange localmente, ainda há vantagens para aderir o mais próximo possível à PA e desviar somente onde seus requisitos ou políticas o forçam a diferir. Como alternativa, você sempre pode considerar o Microsoft 365 ou Office 365 em que não precisa mais implantar ou gerenciar um grande número de servidores.
A PA remove a complexidade e a redundância quando necessário para levar a arquitetura a um modelo de recuperação previsível: quando ocorre uma falha, outra cópia do banco de dados afetado é ativada.
O PA aborda as quatro áreas de foco a seguir:
Para Exchange Server 2019, não há alterações em três das quatro categorias da Arquitetura Preferencial Exchange Server 2016. As áreas de design do Namespace, design do Datacenter e design da DAG não estão recebendo alterações importantes. Ficamos satisfeitos com as implantações de clientes que acompanharam de perto o Exchange Server pa de 2016 e não veem necessidade de desviar das recomendações nessas áreas.
As alterações mais notáveis no Exchange Server pa de 2019 se concentram na área de design do servidor devido a algumas tecnologias novas e interessantes.
Design do namespace
Nos artigos Princípios de Planejamento e Balanceamento de Carga do Namespace para Exchange Server 2016, Ross Smith IV esboçou as várias opções de configuração que estavam disponíveis com o Exchange 2016 e esses conceitos continuam se aplicando ao Exchange Server 2019. Para o namespace, as opções são implantar um namespace vinculado (tendo uma preferência para que os usuários operem fora de um datacenter específico) ou um namespace desvinculado (fazendo com que os usuários se conectem a qualquer datacenter sem preferência).
A abordagem recomendada é usar o modelo não vinculado, implantando um único namespace do Exchange por protocolo cliente para o par de datacenter resiliente ao site (em que cada datacenter é assumido para representar seu próprio site do Active Directory - confira mais detalhes sobre isso abaixo). Por exemplo:
Para o serviço Autodiscover: autodiscover.contoso.com
Para clientes HTTP: mail.contoso.com
Para clientes IMAP: imap.contoso.com
Para clientes SMTP: smtp.contoso.com
Cada namespace do Exchange é balanceado em ambos os datacenters em uma configuração de camada 7 que não usa afinidade de sessão, resultando em 50% do tráfego sendo proxiedo entre datacenters. O tráfego é igualmente distribuído entre os datacenters no par resiliente ao site, por meio de DNS round robin, geoDNS ou outras soluções semelhantes. Em nossa perspectiva, a solução mais simples é a menos complexa e mais fácil de gerenciar, portanto, nossa recomendação é usar o DNS round robin.
Uma precaução que temos para os clientes é garantir que você atribua um valor TTL (tempo de vida) baixo para qualquer registro DNS associado à arquitetura do Exchange. Se uma interrupção completa do datacenter acontecer quando você estiver usando o DNS de round robin, você deverá manter a capacidade de atualizar rapidamente seus registros DNS. Você precisará remover os endereços IP do datacenter offline para que eles não sejam retornados para consultas DNS. Por exemplo, se os registros DNS tiverem um valor TTL mais longo de 24 horas, pode levar até um dia para que os caches DNS downstream sejam atualizados corretamente. Se você não fizer essa etapa, poderá descobrir que alguns clientes não podem fazer a transição correta para os endereços IP ainda disponíveis no datacenter restante. Não se esqueça de adicionar os endereços IP de volta aos seus registros DNS quando seu datacenter offline anteriormente estiver recuperado e pronto para hospedar serviços mais uma vez.
A afinidade do data center é necessária para as fazendas de Servidor do Office Online, portanto, um namespace é implantado por datacenter com o balanceador de carga que utiliza a camada 7 e mantém a afinidade da sessão por meio da persistência baseada em cookie.
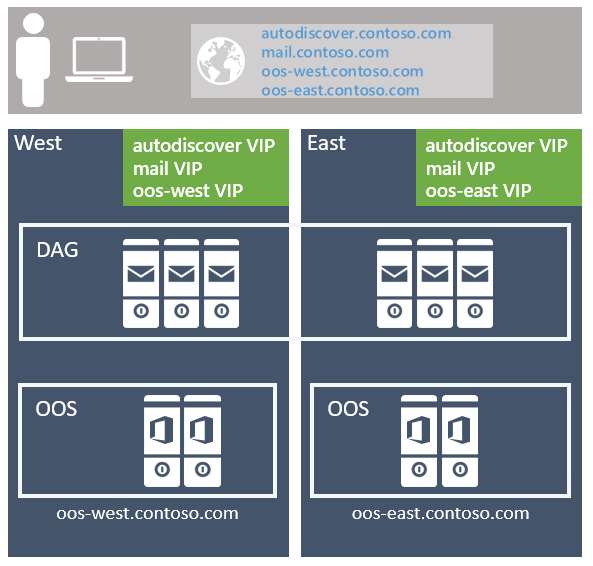
Se você tiver vários pares de datacenter resilientes ao site em seu ambiente, precisará decidir se deseja ter um único namespace mundial ou se deseja controlar o tráfego para cada datacenter específico usando namespaces regionais. Sua decisão depende da topologia de rede e do custo associado ao uso de um modelo desvinculado; por exemplo, se você tiver datacenters localizados no América do Norte e na África do Sul, o vínculo de rede entre essas regiões pode não ser apenas caro, mas também pode ter alta latência, o que pode introduzir problemas operacionais e de dor do usuário. Nesse caso, faz sentido implantar um modelo vinculado com um namespace separado para cada região. No entanto, opções como dNS geográfica oferecem a capacidade de implantar um único namespace unificado, mesmo quando você tem links de rede caros; O DNS geográfico permite que você tenha seus usuários direcionados para o datacenter mais próximo com base no endereço IP do cliente.
Design de par de datacenter resiliente ao site
Para obter uma arquitetura altamente disponível e resiliente ao site, você deve ter dois ou mais datacenters bem conectados (idealmente, você deseja uma baixa latência de rede de ida e volta, caso contrário, a replicação e a experiência do cliente são afetadas negativamente). Além disso, os datacenters devem ser conectados por meio de caminhos de rede redundantes fornecidos por diferentes operadoras operacionais.
Embora seja compatível com o alongamento de um site do Active Directory em vários datacenters, para a PA, recomendamos que cada datacenter seja seu próprio site do Active Directory. Há dois motivos:
A resiliência do site de transporte por meio da redundância do Shadow no Exchange Server e na Safety Net em Exchange Server só pode ser obtida quando o DAG tiver membros localizados em mais de um site do Active Directory.
O Active Directory publicou diretrizes que estabelecem que as sub-redes devem ser colocadas em diferentes sites do Active Directory quando a latência de ida e volta for maior que 10 ms entre as sub-redes.
Design do servidor
Na PA, todos os servidores são servidores físicos e usam armazenamento anexado localmente. O hardware físico é implantado em vez de hardware virtualizado por dois motivos:
Os servidores são dimensionados para usar 80% dos recursos durante o modo de pior falha.
A virtualização vem com uma pequena penalidade de desempenho e a adição de uma camada adicional de gerenciamento e complexidade, que introduz modos de recuperação adicionais que não agregam valor, especialmente porque Exchange Server fornece nativamente a mesma funcionalidade.
Servidores de commodities
As plataformas de servidor de commodities são usadas no PA. As plataformas atuais de commodities são e incluem:
2U, servidores de soquete duplo com até 48 núcleos de processador físico (um aumento de 24 núcleos no Exchange 2016)
Até 256 GB de memória (um aumento de 192 GB no Exchange 2016)
Um controlador de cache de gravação com suporte à bateria
12 ou mais compartimentos de unidade dentro do chassi do servidor
A capacidade de misturar o HDD (armazenamento de bandeja rotativo) tradicional e o SSD (armazenamento de estado sólido) no mesmo chassi.
Teoria da Escala
É importante observar que, embora tenhamos aumentado a capacidade permitida de processador e memória em Exchange Server 2019, a recomendação do Exchange Server PG permanece para escalar em vez de para cima. Escalar versus aumentar significa que preferimos ver você implantar um número maior de servidores com um número ligeiramente menor de recursos por servidor, em vez de um número menor de servidores densos usando recursos máximos e preenchidos com um grande número de caixas de correio. Ao localizar um número razoável de caixas de correio dentro de um servidor, você diminui o impacto de qualquer interrupção planejada ou não planejada e reduz o risco de descobrir outros gargalos do sistema.
Um aumento nos recursos do sistema não deve resultar na suposição de que você verá ganhos lineares de desempenho em Exchange Server 2019 usando os recursos máximos permitidos ao compará-los com os recursos máximos permitidos do Exchange 2016. Cada nova versão do Exchange traz novos processos e atualizações que, por sua vez, dificultam a comparação de uma versão atual com a versão anterior. Siga todas as diretrizes de dimensionamento da Microsoft ao determinar o design do servidor.
Armazenamento
Compartimentos de unidade adicionais podem ser anexados diretamente por servidor, dependendo do número de caixas de correio, tamanho da caixa de correio e escalabilidade de recursos do servidor.
Cada servidor abriga um único par de disco RAID1 para o sistema operacional, binários do Exchange, logs de protocolo/cliente e o banco de dados de transporte.
O armazenamento restante é configurado como JBOD (Apenas um monte de discos). Lembre-se de que alguns controladores de armazenamento de hardware podem exigir que cada disco seja configurado como um grupo RAID0 de disco único para que o cache de gravação seja utilizado. Consulte o fabricante de hardware para confirmar a configuração adequada para o sistema que garante que o cache de gravação será usado.
Nova no Exchange Server pa 2019 é a recomendação de ter duas classes de armazenamento para tudo que ainda não está localizado no par de disco RAID1 mencionado anteriormente.
Classe de armazenamento tradicional
Essa classe de armazenamento contém arquivos de banco de dados Exchange Server e arquivos de log de transações Exchange Server. Esses discos são discos SAS (SCS) de 7,2 K de capacidade grande e 7,2 K anexados serialmente. Embora os discos SATA também estejam disponíveis, observamos uma melhor E/S e uma taxa de falha anualizada menor usando o equivalente SAS.
Para garantir que a capacidade e a E/S de cada disco sejam usadas da forma mais eficiente possível, até quatro cópias de banco de dados são implantadas por disco. O layout normal de cópia em tempo de execução garante que não haja mais do que uma única cópia de banco de dados ativo por disco.
Pelo menos um disco no pool de disco de armazenamento tradicional é reservado como um hot spare. O AutoReseed está habilitado e restaura rapidamente a redundância do banco de dados após uma falha no disco, ativando o hot spare e iniciando as resseadas de cópia de banco de dados.
Classe de armazenamento de estado sólido
Essa classe de armazenamento contém os novos arquivos MCDB (Banco de Dados MetaCache) do Exchange 2019. Essas unidades de estado sólido podem vir em diferentes fatores de forma, como, mas não se limitando às unidades tradicionais de 2,5"/3,5" SAS conectadas ou pcie M.2 conectadas.
Os clientes devem esperar implantar cerca de 5 a 10% de armazenamento adicional como armazenamento de estado sólido. Por exemplo, se um único servidor tivesse 28 TB de arquivos de banco de dados de caixa de correio no armazenamento tradicional, um adicional de 1,4-2,8 TB de armazenamento de estado sólido também seria recomendado como armazenamento adicional para o mesmo servidor.
Discos tradicionais e de estado sólido devem ser implantados em uma proporção 3:1, sempre que possível. Para cada três discos tradicionais dentro do servidor, um único disco de estado sólido será implantado. Esses discos de estado sólido manterão os MCDBs para todos os DBs nos três discos tradicionais associados. Essa recomendação limita o domínio de falha que uma falha de unidade de estado sólido pode impor a um sistema. Quando um SSD falhar, o Exchange 2019 falhará em todas as cópias de banco de dados usando esse SSD para seu MCDB para outro nó DAG com recursos MCDB saudáveis para o banco de dados afetado. Limitar o número de failovers de banco de dados reduz a chance de afetar os usuários se muitos outros bancos de dados estiverem compartilhando um número menor de unidades de estado sólido.
Se houver uma falha de unidade de estado sólido, o Serviço de Alta Disponibilidade do Exchange tentará montar os bancos de dados afetados em diferentes nós DAG em que ainda existe um MCDB saudável para cada banco de dados afetado. Se por algum motivo nenhum MCDBs saudável existir para um dos bancos de dados afetados, os serviços de Alta Disponibilidade do Exchange deixarão a cópia do banco de dados afetada local em execução sem os benefícios de desempenho do MCDB.
Por exemplo, se um cliente implantar um sistema capaz de manter 20 unidades, ele poderá ter um layout como o seguinte.
2 HDDs para espelho do sistema operacional, Binários do Exchange e Banco de Dados de Transporte
12 HDDs para armazenamento do Banco de Dados do Exchange
1 HDD como o sobressalente AutoReseed
4 SSDs para MCDBs do Exchange que fornecem entre 5 a 10% da capacidade cumulativa de armazenamento de banco de dados.
Opcionalmente, um cliente pode optar por adicionar um SSD sobressalente ou uma segunda unidade AutoReseed.
Essa configuração pode ser visualizada usando o seguinte diagrama:
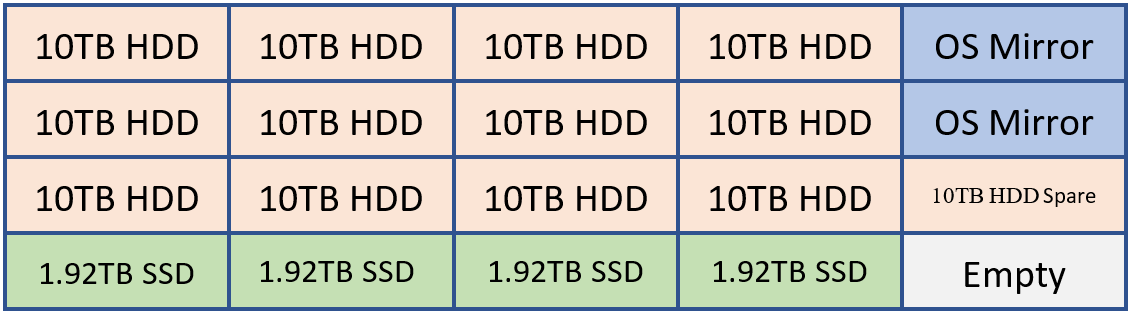
No exemplo acima, temos 120 TB de armazenamento de banco de dados do Exchange e 7,68 TB de armazenamento MCDB que é cerca de 6,4% do espaço de armazenamento de banco de dados tradicional. Com essa quantidade de armazenamento mcbd, estamos perfeitamente alinhados dentro da diretriz de 5 a 10%. Cada uma das unidades de 10 TB conterá quatro cópias de banco de dados e cada unidade MCDB conterá 12 MCDBs.
Configurações de armazenamento comuns
Seja De Estado Tradicional ou Sólido, todos os discos que abrigam dados do Exchange são formatados com ReFS (com o recurso de integridade desabilitado) e o DAG é configurado de modo que o AutoReseed formate os discos com o ReFS:
Set-DatabaseAvailabilityGroup -Identity <DAGIdentity> -FileSystem ReFS
O BitLocker é usado para criptografar cada disco, fornecendo criptografia de dados em repouso e mitigando preocupações em relação ao roubo de dados ou substituição de disco. Para obter mais informações, confira Habilitando o BitLocker no Exchange Servers.
Design do grupo de disponibilidade de banco de dados
Em cada par de datacenter resiliente ao site, você terá um ou mais DAGs. Não é recomendável esticar um DAG em mais de dois datacenters.
Configuração da DAG
Assim como acontece com o modelo de namespace, cada DAG dentro do par de datacenter resiliente ao site opera em um modelo de desvinculação com cópias ativas distribuídas igualmente em todos os servidores do DAG. Este modelo:
Garante que a pilha completa de serviços de cada membro DAG (conectividade do cliente, pipeline de replicação, transporte etc.) esteja sendo validada durante operações normais.
Distribui a carga entre o maior número possível de servidores durante um cenário de falha, aumentando gradualmente o uso de recursos entre os membros restantes no DAG.
Cada datacenter é simétrico, com um número igual de membros DAG em cada datacenter. Isso significa que cada DAG tem um número par de servidores e usa um servidor testemunha para manutenção de quorum.
O DAG é o bloco de construção fundamental no Exchange 2019. Em relação ao tamanho do DAG, um DAG com um maior número de nós membros participantes fornece mais redundância e recursos. Dentro da PA, o objetivo é implantar DAGs com um número maior de nós membros, normalmente começando com um DAG de oito membros e aumentando o número de servidores conforme necessário para atender às suas necessidades. Você só deve criar novos DAGs quando a escalabilidade introduz preocupações sobre o layout de cópia de banco de dados existente.
Design de rede DAG
A PA usa uma interface de rede única e não em equipe para conectividade do cliente e replicação de dados. Uma única interface de rede é tudo o que é necessário porque, em última análise, nosso objetivo é alcançar um modelo de recuperação padrão independentemente da falha - se ocorrer uma falha de servidor ou ocorrer uma falha de rede, o resultado é o mesmo: uma cópia de banco de dados é ativada em outro servidor dentro do DAG. Essa alteração arquitetônica simplifica a pilha de rede e evita a necessidade de eliminar manualmente a conversa cruzada de pulsação.
Posicionamento do servidor testemunha
O posicionamento do servidor testemunha determina se a arquitetura pode fornecer recursos automáticos de failover do datacenter ou se exigirá uma ativação manual para habilitar o serviço se houver uma falha no site.
Se sua organização tiver um terceiro local com uma infraestrutura de rede isolada de falhas de rede que afetam o par de datacenter resiliente ao site no qual o DAG é implantado, a recomendação é implantar o servidor testemunha do DAG nesse terceiro local. Essa configuração fornece ao DAG a capacidade de fazer failover automático de bancos de dados para o outro datacenter em resposta a um evento de falha no nível do datacenter, independentemente de qual datacenter tenha a interrupção.
Se sua organização não tiver um terceiro local, considere colocar a testemunha do servidor no Azure; como alternativa, coloque o servidor testemunha em um dos datacenters dentro do par de datacenter resiliente ao site. Se você tiver vários DAGs no par de datacenter resiliente ao site, coloque o servidor testemunha para todos os DAGs no mesmo datacenter (normalmente o datacenter em que a maioria dos usuários está fisicamente localizada). Além disso, verifique se o PAM (Primary Active Manager) para cada DAG também está localizado no mesmo datacenter.
Exchange Server 2019 e todas as versões anteriores não dão suporte ao uso do recurso Cloud Witness introduzido pela primeira vez no Cluster de Failover Windows Server 2016.
Resiliência de dados
A resiliência de dados é obtida com a implantação de várias cópias de banco de dados. Na PA, as cópias de banco de dados são distribuídas entre o par de datacenter resiliente ao site, garantindo assim que os dados da caixa de correio sejam protegidos contra falhas de software, hardware e até datacenter.
Cada banco de dados tem quatro cópias, com duas cópias em cada datacenter, o que significa que, no mínimo, a PA requer quatro servidores. Dessas quatro cópias, três delas são configuradas como altamente disponíveis. A quarta cópia (a cópia com o número mais alto de preferência de ativação) é configurada como uma cópia de banco de dados defasada. Devido ao design do servidor, cada cópia de um banco de dados é isolada de suas outras cópias, reduzindo assim os domínios de falha e aumentando a disponibilidade geral da solução, conforme discutido no DAG: Além do "A".
A finalidade da cópia de banco de dados defasada é fornecer um mecanismo de recuperação para o raro evento de corrupção lógica catastrófica em todo o sistema. Ele não se destina à recuperação individual de caixa de correio ou recuperação de item de caixa de correio.
A cópia de banco de dados defasada é configurada com um ReplayLagTime de sete dias. Além disso, o Replay Lag Manager também está habilitado para fornecer reprodução de arquivo de log dinâmico para cópias defasadas quando a disponibilidade é comprometida devido à perda de cópias não registradas.
Ao usar a cópia de banco de dados defasada dessa maneira, é importante entender que a cópia de banco de dados defasada não é um backup ponto a tempo garantido. A cópia de banco de dados defasada terá um limite de disponibilidade, normalmente em torno de 90%, devido a períodos em que o disco que contém uma cópia defasada é perdido devido a uma falha no disco, a cópia defasada se tornando uma cópia ha (devido à reprodução automática) e, os períodos em que a cópia de banco de dados defasada está recompilando a fila de reprodução.
Para proteger contra exclusão de item acidental (ou mal-intencionada), tecnologias de recuperação de item único ou retenção in-place são usadas e a janela Retenção de Item Excluída é definida como um valor que atende ou excede qualquer SLA de recuperação de nível de item definido.
Com todas essas tecnologias em jogo, os backups tradicionais são desnecessários; como resultado, a PA usa o Exchange Native Data Protection.
design Servidor do Office Online
No mínimo, você deseja implantar um farm de Servidor do Office Online (OOS) com pelo menos dois nós OOS em cada datacenter que hospeda servidores do Exchange 2019. Cada Servidor do Office Online deve ter pelo menos 8 núcleos de processador, 32 GB de memória e pelo menos 40 GB de espaço dedicado para arquivos de log. Os servidores de caixa de correio do Exchange 2019 devem ser configurados para contar com o farm OOS local em seu datacenter para garantir a menor latência possível e a maior largura de banda possível entre os servidores para renderizar o conteúdo do arquivo aos usuários.
Resumo
Exchange Server 2019 continua aprimorando os investimentos introduzidos em versões anteriores do Exchange e apresenta tecnologias adicionais originalmente inventadas para uso no Microsoft 365 e Office 365.
Ao se alinhar com a Arquitetura Preferencial, você aproveitará essas alterações e fornecerá a melhor experiência de usuário local possível. Você continuará a tradição de ter uma implantação do Exchange altamente confiável, previsível e resiliente.