Mapeando campos com relações em fluxos de dados padrão
No fluxo de dados padrão, você pode mapear facilmente campos da consulta de fluxo de dados para tabelas do Dataverse. No entanto, se a tabela Dataverse tiver campos de pesquisa ou relação, será necessária uma consideração adicional para garantir que esse processo funcione.
Qual é a relação e por que você precisa dela?
Se você estiver vindo de uma experiência anterior com desenvolvimento de banco de dados, estará familiarizado com o conceito de relação entre tabelas. No entanto, muitos usuários dos serviços do Microsoft Power Platform não têm essa experiência prévia. Você pode se perguntar qual é a relação ou por que você deve criar uma relação entre tabelas.
As tabelas e suas relações são conceitos fundamentais na criação de um banco de dados. Saber tudo sobre relacionamentos está além do escopo deste artigo. No entanto, discutiremos isso de uma forma geral aqui.
Digamos que você queira armazenar informações sobre clientes e os respectivos detalhes, incluindo a região, no Dataverse. Você pode manter tudo em uma tabela. Sua tabela pode ser chamada de Clientes e pode conter campos, como CustomerID, Nome, Data de nascimento e Região. Agora imagine que você tenha outra tabela que também tenha as informações da loja. Essa tabela pode ter campos, como ID da Loja, Nome e Região. Como você pode ver, a região é repetida em ambas as tabelas. Não há um único lugar em que você possa obter todas as regiões; alguns dos dados de região estão na tabela Clientes e outros estão na tabela Lojas. Se você criar um aplicativo ou um relatório com base nessas informações, sempre precisará combinar as informações das duas regiões em uma só.
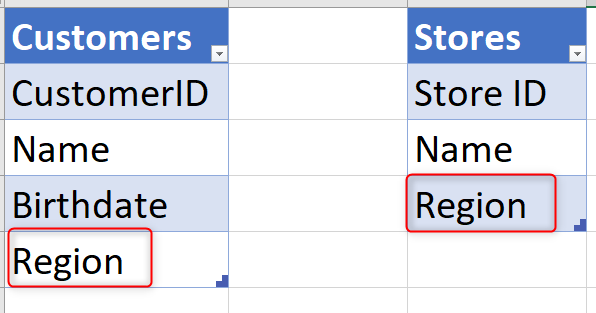
O que é feito na prática de design do banco de dados é criar uma tabela para Região em cenários como o descrito acima. Essa tabela Região teria uma ID da Região, Nome e outras informações sobre a região. As outras duas tabelas (Clientes e Lojas) terão vínculos com essa tabela usando um campo (que pode ser a ID da Região se tivermos a ID em ambas as tabelas ou Nome, se for exclusivo o suficiente para determinar uma região). Isso significa ter uma relação da tabela Lojas e Clientes com a tabela Região.
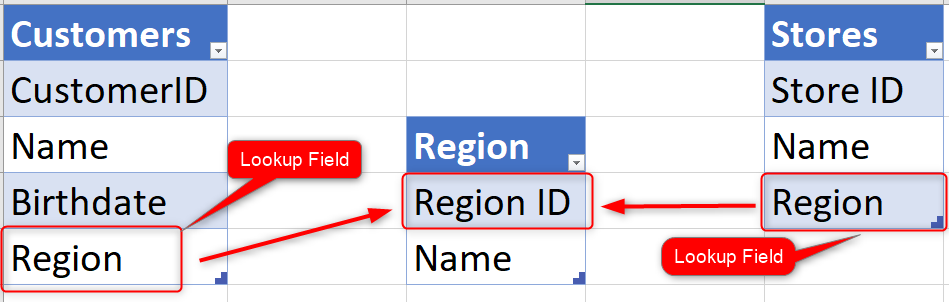
No Dataverse, há várias maneiras de criar uma relação. Uma forma é criar uma tabela e criar um campo em uma tabela que seja uma relação (ou pesquisa) com outra tabela, conforme descrito na próxima seção.
O que são campos de pesquisa ou relação?
No Dataverse, você pode ter um campo definido como um campo de pesquisa, que aponta para outra tabela.
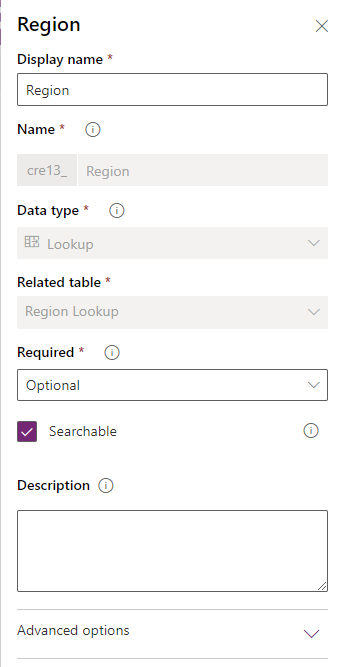
Na imagem anterior, o campo Região é um campo de pesquisa para outra tabela chamada Pesquisa de Região. Para saber mais sobre os diferentes tipos de relacionamentos, acesse Criar um relacionamento entre tabelas.
Quando o mapeamento de campo não mostra os campos de relacionamento
Se você criou um campo de pesquisa em uma tabela, que aponta para outra tabela, esse campo poderá não aparecer no mapeamento do fluxo de dados. Isso porque a entidade de destino envolvida no relacionamento exige que um campo Chave seja definido. Essa prática recomendada vai garantir que o campo seja mapeável nos mapeamentos de tabela do fluxo de dados.
Definindo o campo de Chave na tabela
Para definir o campo de chave na tabela, acesse a guia Chaves e adicione uma chave a um campo que tenha valores exclusivos.
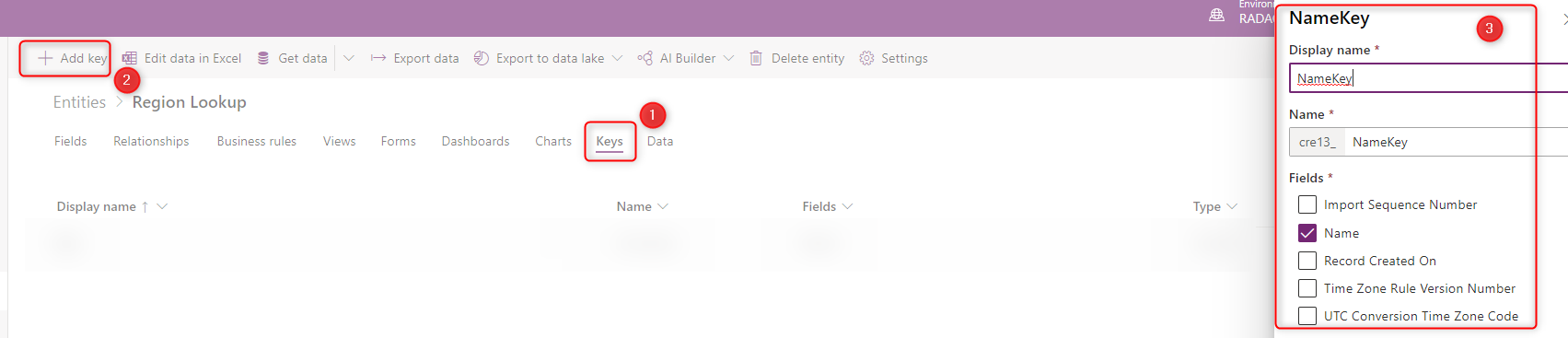
Depois de definir o campo de chave, você poderá ver o campo no mapeamento do fluxo de dados.
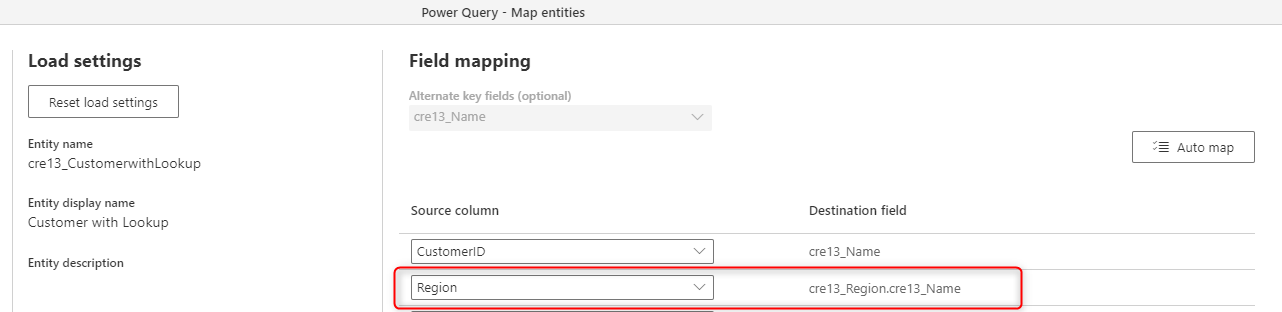
Limitações conhecidas
- Atualmente, não há suporte para mapeamento para campos de pesquisa polimórfica.
- Atualmente, não há suporte para o mapeamento para um campo de pesquisa de vários níveis, uma pesquisa que aponta para o campo de pesquisa de outras tabelas.
- Os campos de pesquisa para Tabelas Padrão, a menos que contenham campos de chave alternativos, conforme descrito neste documento, não aparecerão na caixa de diálogo Tabelas de Mapa.
- Os fluxos de dados não garantem a ordem de carregamento correta ao carregar-se dados em tabelas configuradas como estruturas de dados hierárquicas.
- Não há garantias sobre a ordem de execução da consulta ou ordem de carregamento das tabelas do Dataverse. Recomendamos que você separe as tabelas filho e pai em dois fluxos de dados e primeiro atualize o fluxo de dados que contém artefatos filho.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de