Apresentamos os Clusters de Big Data do SQL Server
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
No SQL Server 2019 (15.x), os Clusters de Big Data do SQL Server permitem implantar clusters escalonáveis de contêineres do SQL Server, do Spark e do HDFS em execução no Kubernetes. Esses componentes são executados lado a lado para permitir que você leia, grave e processe Big Data do Transact-SQL ou do Spark, permitindo combinar e analisar facilmente seus dados relacionais de alto valor com Big Data de alto volume.
Introdução
- Primeiro, confira Introdução aos clusters de Big data do SQL Server
- Para ver novos recursos da versão mais recente, confira as notas sobre a versão
- Para perguntas frequentes, confira Perguntas frequentes sobre Clusters de Big Data
Arquitetura de clusters de Big Data
O seguinte diagrama mostra os componentes de um cluster de Big Data do SQL Server:

Controller
O controlador fornece gerenciamento e segurança para o cluster. Ele contém o serviço de controle, o repositório de configurações e outros serviços no nível do cluster, como Kibana, Grafana e Pesquisa Elástica.
Pool de computação
O pool de computação fornece recursos computacionais para o cluster. Ele contém nós que executam pods do SQL Server em Linux. Os pods no pool de computação são divididos em instâncias de computação do SQL para tarefas de processamento específicas.
Pool de dados
O pool de dados é usado para persistência de dados. O pool de dados é composto por um ou mais pods em execução no SQL Server em Linux. Ele é usado para ingerir dados de consultas SQL ou de trabalhos do Spark.
Pool de armazenamento
O pool de armazenamento é composto por pods do pool de armazenamento compostos pelo SQL Server em Linux, pelo Spark e pelo HDFS. Todos os nós de armazenamento em um cluster de Big Data do SQL Server são membros de um cluster do HDFS.
Dica
Para obter uma análise detalhada da arquitetura e da instalação do cluster de Big Data, confira Workshop: Arquitetura de Clusters de Big Data do Microsoft SQL Server.
Pool de aplicativos
A implantação de aplicativos permite que esse tipo de implantação ocorra nos Clusters de Big Data do SQL Server, fornecendo interfaces para criar, gerenciar e executar aplicativos.
Cenários e recursos
Clusters de Big Data do SQL Server oferecem flexibilidade na maneira como você interage com seu Big Data. Você pode consultar fontes de dados externas, armazenar Big Data no HDFS gerenciado pelo SQL Server ou consultar dados de várias fontes de dados externas por meio do cluster. Depois, você pode usar os dados para IA, aprendizado de máquina e outras tarefas de análise.
Use Clusters de Big Data do SQL Server para:
- Implantar clusters escalonáveis de contêineres do SQL Server, do Spark e do HDFS em execução no Kubernetes.
- Ler, gravar e processar Big Data do Transact-SQL ou do Spark.
- Combine e analise facilmente dados relacionais de valor elevado com Big Data de volume grande.
- Consultar fontes de dados externas.
- Armazenar Big Data no HDFS gerenciado por SQL Server.
- Consultar dados de várias fontes de dados externas por meio do cluster.
- Usar os dados para IA, aprendizado de máquina e outras tarefas de análise.
- Implantar e executar aplicativos em Clusters de Big Data.
- Virtualizar dados com o PolyBase. Consulte dados do SQL Server, do Oracle, do Teradata e do MongoDB externos e fontes de dados ODBC genéricas com tabelas externas.
- Forneça alta disponibilidade para a instância mestra do SQL Server e todos os bancos de dados usando a tecnologia de grupo de disponibilidade Always On.
As seções a seguir fornecem mais informações sobre estes cenários.
Virtualização de dados
Utilizando o PolyBase, os Clusters de Big Data do SQL Server podem consultar fontes de dados externas sem mover nem copiar os dados. O SQL Server 2019 (15.x) apresenta novos conectores para fontes de dados. Para obter mais informações, confira Novidades do PolyBase 2019.
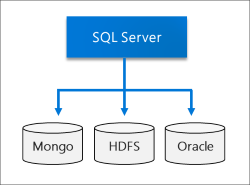
Data Lake
Um cluster de Big Data do SQL Server inclui um pool de armazenamento do HDFS escalonável. Ele pode ser usado para armazenar Big Data, potencialmente ingerido de várias fontes externas. Após o Big Data ser armazenado no HDFS no cluster de Big Data, você poderá analisar e consultar os dados e combiná-los com os dados relacionais.
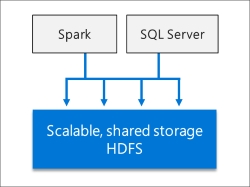
IA e aprendizado de máquina integrados
Clusters de Big Data do SQL Server habilitam tarefas de IA e de aprendizado de máquina nos dados armazenados em pools de armazenamento do HDFS e nos pools de dados. Você pode usar o Spark, bem como as ferramentas internas de IA no SQL Server, usando R, Python, Scala ou Java.
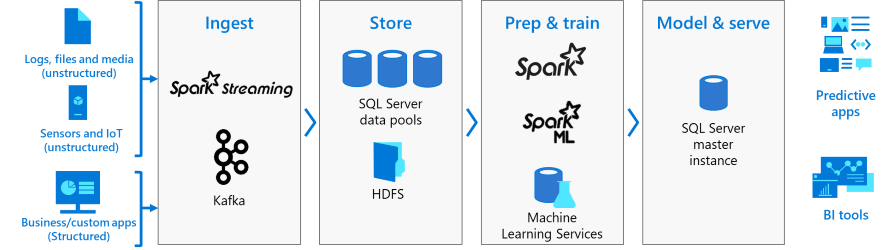
Gerenciamento e monitoramento
O gerenciamento e o monitoramento são fornecidos por meio de uma combinação de ferramentas de linha de comando, APIs, portais e exibições de gerenciamento dinâmico.
É possível usar o Azure Data Studio para executar uma variedade de tarefas no cluster de Big Data:
- Snippets internos para tarefas comuns de gerenciamento.
- Capacidade de navegar no HDFS, carregar arquivos, visualizar arquivos e criar diretórios.
- Capacidade de criar, abrir e executar notebooks compatíveis com Jupyter.
- Assistente de virtualização de dados para simplificar a criação de fontes de dados externas (habilitadas pela Extensão de Virtualização de Dados).
Conceitos do Kubernetes
Um cluster de Big Data do SQL Server é um cluster de contêineres Linux orquestrados pelo Kubernetes.
O Kubernetes é um orquestrador de contêineres de software livre que pode dimensionar implantações de contêiner de acordo com a necessidade. A tabela a seguir define algumas terminologias importantes do Kubernetes:
| Termo | Descrição |
|---|---|
| Cluster | Um cluster do Kubernetes é um conjunto de computadores, conhecidos como nós. Um nó controla o cluster e é designado como nó mestre; os nós restantes são nós de trabalho. O mestre do Kubernetes é responsável por distribuir o trabalho entre os trabalhadores e por monitorar a integridade do cluster. |
| Nó | Um nó executa aplicativos em contêineres. Ele pode ser um computador físico ou uma máquina virtual. Um cluster do Kubernetes pode conter uma combinação de nós de computadores físicos e de máquinas virtuais. |
| Pod | Um pod é a unidade de implantação atômica do Kubernetes. Um pod é um grupo lógico de um ou mais contêineres – e recursos associados – necessários para executar um aplicativo. Cada pod é executado em um nó; um nó pode executar um ou mais pods. O mestre do Kubernetes atribui pods automaticamente aos nós no cluster. |
Nos Clusters de Big Data do SQL Server, o Kubernetes é responsável pelo estado do cluster. O Kubernetes cria e configura os nós do cluster, atribui pods aos nós e monitora a integridade do cluster.
Próximas etapas
Para obter mais informações sobre como implantar Clusters de Big Data do SQL Server, confira Introdução aos Clusters de Big Data do SQL Server.
Em seguida, ele começa a carregar dados e executar um trabalho do Spark.
Saiba mais
- Workshop de arquitetura de Clusters de Big Data
- ASSISTA: Clusters de Big Data em resumo
- ASSISTA: Introdução ao Cluster de Big Data do SQL Server 2019 | Virtualização, Kubernetes e Contêineres
Módulos do Learn para tecnologias relacionadas:
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de