Implante o nó de nome do HDFS e serviços compartilhados do Spark em uma configuração altamente disponível
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
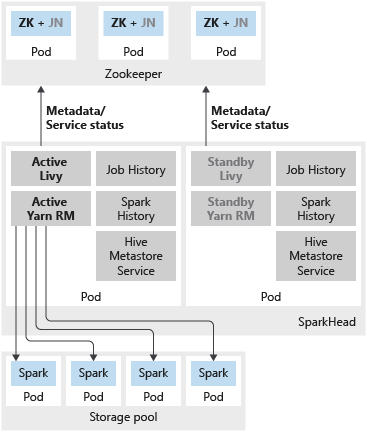
Além de implantar a instância mestre do SQL Server em uma configuração altamente disponível usando grupos de disponibilidade, você pode implantar outros serviços críticos no cluster de Big Data para garantir um nível maior de confiabilidade. Você pode configurar o HDFS name node e os serviços compartilhados do Spark agrupados em sparkhead com uma réplica adicional. Nesse caso, Zookeeper também é implantado no cluster de Big Data para servir como coordenador de clusters e repositório de metadados para os seguintes serviços:
- Nó de nome do HDFS
- Livy e Yarn Resource Manager.
O Spark History, o Histórico de Trabalhos e o serviço de metadados do Hive são serviços sem estado. O ZooKeeper não está envolvido na garantia da integridade do serviço desses componentes.
Implantar várias réplicas nesses serviços gera melhorias de escalabilidade, confiabilidade e balanceamento de carga das cargas de trabalho entre as réplicas disponíveis.
Observação
Os seguintes serviços são implantados como contêineres no pod sparkhead:
- Livy
- Yarn Resource Manager
- Spark History
- Histórico de Trabalhos
- Serviço de metadados do Hive
A imagem a seguir mostra uma implantação de HA do Spark em um cluster de Big Data do SQL Server:
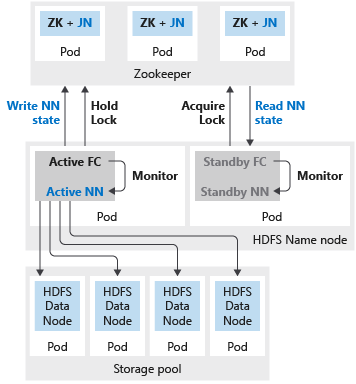
A imagem a seguir mostra uma implantação de HA do HDFS em um cluster de Big Data do SQL Server:
Implantar
Se o nó de nome ou o cabeçalho do Spark estiver configurado com duas réplicas, você também precisará configurar o recurso do ZooKeeper com três réplicas. Em uma configuração altamente disponível para o nó de nome do HDFS, dois pods hospedam as duas réplicas. Os pods são nmnode-0 e nmnode-1. Esta configuração é ativa-passiva. Somente um dos nós de nome fica ativo por vez. O outro fica em espera e se torna ativo como resultado de um evento de failover.
Você pode usar o aks-dev-test-ha ou os perfis de configuração internos do kubeadm-prod para começar a personalizar a implantação do cluster de Big Data. Esses perfis incluem as configurações necessárias para os recursos que você pode definir para alta disponibilidade adicional. Por exemplo, abaixo está uma seção do arquivo de configuração bdc.json que é relevante para implantar o nó de nome do HDFS, o ZooKeeper e recursos compartilhados do Spark (sparkhead) com alta disponibilidade.
{
...
"nmnode-0": {
"spec": {
"replicas": 2
}
},
"sparkhead": {
"spec": {
"replicas": 2
}
},
"zookeeper": {
"spec": {
"replicas": 3
}
},
...
}
Como melhor prática, em uma implantação de produção, você também deve configurar a replicação de bloco do HDFS para 3. Essa configuração já está especificada nos perfis aks-dev-test-ha e kubeadm-prod. Veja a seção abaixo do arquivo de configuração bdc.json:
{
...
"hdfs": {
"resources": [
"nmnode-0",
"zookeeper",
"storage-0",
"sparkhead"
],
"settings": {
"hdfs-site.dfs.replication": "3"
}
},
...
}
Limitações conhecidas
Os problemas e limitações conhecidos com a configuração de alta disponibilidade para os serviços do Hadoop nos Clusters de Big Data do SQL Server incluem:
- Todas as configurações devem ser especificadas no momento da implantação do cluster de Big Data. Com a versão SQL Server 2019 CU1, você não pode habilitar a configuração de alta disponibilidade após a implantação.
Próximas etapas
- Para obter mais informações sobre o uso de arquivos de configuração em implantações de cluster de Big Data, confira Como implantar Clusters de Big Data do SQL Server no Kubernetes.
- Para obter mais informações sobre as opções de alta disponibilidade do SQL Server mestre nos clusters de Big Data, confira o tópico Implantar a instância mestre do SQL Server com alta disponibilidade.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de