Implantar o cluster de Big Data do SQL Server com alta disponibilidade
Aplica-se a:![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
O complemento Clusters de Big Data do Microsoft SQL Server 2019 será desativado. O suporte para Clusters de Big Data do SQL Server 2019 será encerrado em 28 de fevereiro de 2025. Todos os usuários existentes do SQL Server 2019 com Software Assurance terão suporte total na plataforma e o software continuará a ser mantido por meio de atualizações cumulativas do SQL Server até esse momento. Para obter mais informações, confira a postagem no blog de anúncio e as opções de Big Data na plataforma do Microsoft SQL Server.
Como Clusters de Big Data do SQL Server estão no Kubernetes como aplicativos em contêineres e usam recursos como conjuntos com estado e armazenamento persistente, essa infraestrutura tem monitoramento de integridade, detecção de falha e mecanismos de failover internos que os componentes do cluster utilizam para manter a integridade do serviço. Para proporcionar maior confiabilidade, você também pode configurar a instância mestra do SQL Server e/ou o nó de nome do HDFS e serviços compartilhados do Spark para implantar com réplicas adicionais em uma configuração de alta disponibilidade. O monitoramento, a detecção de falha e o failover automático são gerenciados pelo serviço de gerenciamento de cluster de Big Data, ou seja, o serviço de controle. Esse serviço é fornecido sem a intervenção do usuário – tudo, desde a configuração do grupo de disponibilidade e da configuração dos pontos de extremidade de espelhamento de banco de dados, à adição do bancos de dados ao grupo de disponibilidade ou à coordenação de failover e atualização.
A imagem a seguir representa como um grupo de disponibilidade é implantado em um Cluster de Big Data do SQL Server:
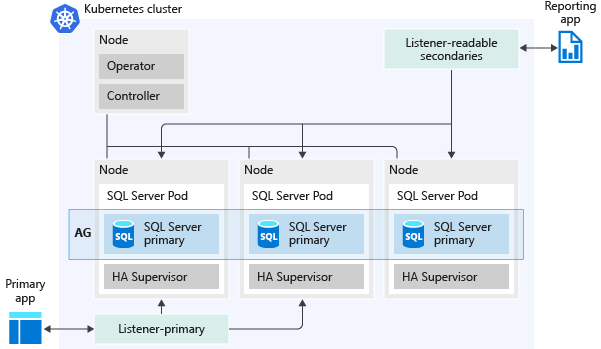
Aqui estão alguns dos recursos que os grupos de disponibilidade habilitam:
Se as configurações de alta disponibilidade forem especificadas no arquivo de configuração de implantação, será criado um único grupo de disponibilidade chamado
containedag. Por padrão,containedagtem três réplicas, incluindo a primária. Todas as operações CRUD para o grupo de disponibilidade são gerenciadas internamente, incluindo a criação do grupo de disponibilidade ou a adição de réplicas ao grupo de disponibilidade criado. Não é possível criar grupos de disponibilidade adicionais na instância mestra do SQL Server em um cluster de Big Data.Todos os bancos de dados são adicionados automaticamente ao grupo de disponibilidade, incluindo todos os bancos de dados do usuário e do sistema, como
masteremsdb. Essa funcionalidade fornece um modo de exibição do sistema único entre as réplicas do grupo de disponibilidade. Bancos de dados de modelo adicionais (model_replicatedmasteremodel_msdb) são usadas para propagar a parte replicada dos bancos de dados do sistema. Além desses bancos de dados, você verá bancos de dadoscontainedag_masterecontainedag_msdbcaso conecte-se diretamente à instância. Os bancos de dados docontainedagrepresentam omastere omsdbdentro do grupo de disponibilidade.Importante
Os bancos de dados criados na instância como resultado de um fluxo de trabalho, como anexar banco de dados, não são adicionados automaticamente ao grupo de disponibilidade. Os administradores dos Clusters de Big Data do SQL Server terão que fazer isso manualmente. Para saber como habilitar um ponto de extremidade temporário para o banco de dados mestre da instância do SQL Server, confira Conectar-se a uma instância do SQL Server. Antes da versão do SQL Server 2019 CU2, os bancos de dados criados como resultado de uma instrução de restauração tinham o mesmo comportamento e precisavam ser adicionados manualmente ao grupo de disponibilidade contido.
Bancos de dados de configuração do PolyBase não são incluídos no grupo de disponibilidade porque incluem metadados em nível de instância específicos de cada réplica.
Um ponto de extremidade externo é provisionado automaticamente para conectar-se a bancos de dados dentro do grupo de disponibilidade. Esse ponto de extremidade
master-svc-externaldesempenha a função do ouvinte do grupo de disponibilidade.Um segundo ponto de extremidade externo é provisionado para conexões somente leitura para as réplicas secundárias para escalar horizontalmente as cargas de trabalho de leitura.
Implantar
Para implantar o SQL Server mestre em um grupo de disponibilidade:
- Habilitar o recurso
hadr - Especifique o número de réplicas para o AG (o mínimo são 3)
- Configurar os detalhes do segundo ponto de extremidade externo criado para conexões com as réplicas secundárias somente leitura
Você pode usar o aks-dev-test-ha ou os perfis de configuração internos do kubeadm-prod para iniciar a personalização do cluster de Big Data. Esses perfis incluem as configurações necessárias para os recursos que você pode definir para alta disponibilidade adicional. Por exemplo, abaixo está uma seção no arquivo de configuração bdc.json relevante para habilitar grupos de disponibilidade para a instância mestra do SQL Server.
{
...
"spec": {
"type": "Master",
"replicas": 3,
"endpoints": [
{
"name": "Master",
"serviceType": "LoadBalancer",
"port": 31433
},
{
"name": "MasterSecondary",
"serviceType": "LoadBalancer",
"port": 31436
}
],
"settings": {
"sql": {
"hadr.enabled": "true"
}
}
}
...
}
As etapas a seguir explicam um exemplo de como iniciar do perfil do aks-dev-test-ha e personalizar sua configuração de implantação de cluster de Big Data. Para uma implantação em um cluster de kubeadm, etapas semelhantes seriam aplicáveis, mas verifique se você está usando NodePort para o serviceType na seção endpoints.
Clonar seu perfil de destino
azdata bdc config init --source aks-dev-test-ha --target custom-aks-haOpcionalmente, faça as edições no perfil personalizado conforme necessário.
Comece a implantação do cluster usando o perfil de configuração de cluster criado acima
azdata bdc create --config-profile custom-aks-ha --accept-eula yes
Conectar-se a bancos de dados do SQL Server no grupo de disponibilidade
Dependendo do tipo de carga de trabalho que você deseja executar no SQL Server mestre, você pode se conectar à primária para cargas de trabalho de leitura/gravação ou aos bancos de dados nas réplicas secundárias para o tipo somente leitura de cargas de trabalho. Aqui está uma estrutura de tópicos para cada tipo de conexão:
Conectar-se a bancos de dados na réplica primária
Para conexões com a réplica primária, use o ponto de extremidade sql-server-master. Esse ponto de extremidade também é o ouvinte para o AG. Ao usar esse ponto de extremidade, todas as conexões estão no contexto de bancos de dados dentro do grupo de disponibilidade. Por exemplo, uma conexão padrão usando esse ponto de extremidade resultará na conexão com o banco de dados master dentro do grupo de disponibilidade, não no banco de dados master da instância do SQL Server. Execute este comando para localizar o ponto de extremidade:
azdata bdc endpoint list -e sql-server-master -o table
Description Endpoint Name Protocol
------------------------------------ ------------------- ----------------- ----------
SQL Server Master Instance Front-End 11.11.111.111,11111 sql-server-master tds
Observação
Eventos de failover podem ocorrer durante uma execução de consulta distribuída que está acessando dados de fontes de dados remotas, como o HDFS ou o pool de dados. Como prática recomendada, os aplicativos devem ser projetados para ter lógica de repetição de conexão em caso de desconexões causadas por failover.
Conectar-se a bancos de dados nas réplicas secundárias
Para conexões somente leitura para bancos de dados em réplicas secundárias, use o ponto de extremidade sql-server-master-readonly. Esse ponto de extremidade funciona como um balanceador de carga em todas as réplicas secundárias. Ao usar esse ponto de extremidade, todas as conexões estão no contexto de bancos de dados dentro do grupo de disponibilidade. Por exemplo, uma conexão padrão usando esse ponto de extremidade resultará na conexão com o banco de dados master dentro do grupo de disponibilidade, não no banco de dados master da instância do SQL Server.
azdata bdc endpoint list -e sql-server-master-readonly -o table
Description Endpoint Name Protocol
--------------------------------------------- ------------------ -------------------------- ----------
SQL Server Master Readable Secondary Replicas 11.11.111.11,11111 sql-server-master-readonly tds
Conectar a uma instância do SQL Server
Para determinadas operações, como definir configurações em nível de servidor ou adicionar manualmente um banco de dados ao grupo de disponibilidade, você deve se conectar à instância do SQL Server. Antes do SQL Server 2019 CU2, operações como sp_configure, RESTORE DATABASE ou qualquer DDL do grupo de disponibilidade exigirão esse tipo de conexão. Por padrão, o cluster de Big Data não inclui um ponto de extremidade que habilita a conexão de instância e você deve expor esse ponto de extremidade manualmente.
Importante
O ponto de extremidade exposto para conexões da instância do SQL Server tem suporte apenas para autenticação SQL, mesmo em clusters em que o Active Directory está habilitado. Por padrão, durante uma implantação de cluster de Big Data, o logon do sa é desabilitado e um novo logon do sysadmin é provisionado com base nos valores fornecidos no momento da implantação para as variáveis de ambiente AZDATA_USERNAME e AZDATA_PASSWORD.
Importante
A DDL do grupo de disponibilidade contido é exclusivamente autogerenciada no BDC. Qualquer tentativa (de usuário externo) de descartar a disponibilidade contida ou o ponto de extremidade de espelhamento de banco de dados não tem suporte e pode resultar em um estado de BDC irrecuperável.
Aqui está um exemplo que mostra como expor esse ponto de extremidade e então adicionar o banco de dados criado com um fluxo de trabalho de restauração ao grupo de disponibilidade. Instruções semelhantes para configurar uma conexão com a instância mestra do SQL Server aplicam-se quando você deseja alterar as configurações de servidor com sp_configure.
Observação
Do SQL Server 2019 CU2 em diante os bancos de dados criados como resultado de um fluxo de trabalho de restauração são adicionados automaticamente ao grupo de disponibilidade contido.
Determine o pod que hospeda a réplica primária conectando-se ao ponto de extremidade
sql-server-mastere execute:SELECT @@SERVERNAMEExpor o ponto de extremidade externo criando um novo serviço do Kubernetes
Para um cluster do
kubeadm, execute o comando abaixo. SubstituapodNamepelo nome do servidor retornado na etapa anterior,serviceNamepelo nome preferencial para o serviço de Kubernetes criado enamespaceName* pelo nome do Cluster de Big Data.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPara uma execução de cluster do AKS, execute o mesmo comando, exceto que o tipo de serviço criado será
LoadBalancer. Por exemplo:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerAqui está um exemplo desse comando executado no AKS, em que o pod que hospeda o primário é
master-0:kubectl -n mssql-cluster expose pod master-0 --port=1533 --name=master-sql-0 --type=LoadBalancerObtenha o IP do serviço de Kubernetes criado:
kubectl get services -n <namespaceName>
Importante
Como melhor prática, limpe excluindo o serviço de Kubernetes criado acima executando este comando:
kubectl delete svc master-sql-0 -n mssql-cluster
Adicione um banco de dados ao grupo de disponibilidade.
Para que o banco de dados seja adicionado ao AG, ele precisa ser executado no modelo de recuperação completa e é necessário fazer backup de log. Use o IP do serviço Kubernetes criado acima para se conectar à instância de SQL Server, depois execute as instruções T-SQL conforme mostrado abaixo.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>O exemplo a seguir adiciona um banco de dados chamado
salesque foi restaurado na instância:ALTER DATABASE sales SET RECOVERY FULL; BACKUP DATABASE sales TO DISK='/var/opt/mssql/data/sales.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE sales
Limitações conhecidas
Esses são problemas e limitações conhecidos de grupos de disponibilidade contidos para o SQL Server mestre no cluster de Big Data:
- A configuração de alta disponibilidade deve ser criada quando o cluster de Big Data é implantado. Não é possível habilitar a configuração de alta disponibilidade com grupos de disponibilidade após a implantação. Neste momento, a única configuração habilitada é para réplicas de confirmação síncrona.
Aviso
A atualização do modo de sincronização para confirmação assíncrona em qualquer uma das réplicas na confirmação de quorum resultará em uma configuração inválida para alta disponibilidade. A execução nessa configuração envolve um risco de perda de dados, pois, no caso de eventos de falha que afetem a réplica primária, não há um failover automático disparado e o usuário deve aceitar o risco de perda de dados ao emitir o failover manual.
- Para restaurar com êxito um banco de dados habilitado para TDE de um backup criado em outro servidor, você deve garantir que os certificados necessários sejam restaurados no mestre de instância do SQL Server, bem como no mestre AG contido. Confira aqui para obter um exemplo de como fazer backup e restaurar os certificados.
- Determinadas operações, como a execução de definições de configuração do servidor com
sp_configure, exigem uma conexão com o banco de dadosmasterde instância do SQL Server, não com o grupo de disponibilidademaster. Você não pode usar o ponto de extremidade primário correspondente. Siga as instruções para expor um ponto de extremidade e conectar-se à instância do SQL Server e executarsp_configure. Você só pode usar a autenticação do SQL ao expor manualmente o ponto de extremidade para conectar-se ao banco de dadosmasterda instância do SQL Server. - Embora o banco de dados msdb contido esteja incluído no grupo de disponibilidade e os trabalhos do SQL Agent sejam replicados nele, os trabalhos são executados apenas por agendamento na réplica primária.
- Não há suporte para o recurso de replicação em grupos de disponibilidade contidos. As instâncias do SQL Server que fazem parte de um AG independente não podem funcionar como distribuidor nem publicador, seja no nível da instância ou do AG independente.
- Não há suporte para criar grupos de arquivo ao criar o banco de dados. Como alternativa, você pode criar o banco de dados primeiro e emitir uma instrução ALTER DATABASE para adicionar qualquer grupo de arquivo.
- Antes do SQL Server 2019 CU2, os bancos de dados criados como resultado de fluxos de trabalho que não
CREATE DATABASEeRESTORE DATABASEcomoCREATE DATABASE FROM SNAPSHOTnão são adicionados automaticamente ao grupo de disponibilidade. Conecte-se à instância e adicione o banco de dados ao grupo de disponibilidade manualmente. - Atualmente, não há suporte para o Service Broker e Database Mail em Clusters de Big Data implantados com alta disponibilidade.
Próximas etapas
- Para obter mais informações sobre o uso de arquivos de configuração em implantações de cluster de Big Data, confira Como implantar Clusters de Big Data do SQL Server no Kubernetes.
- Para obter mais informações sobre o recurso de grupos de disponibilidade para SQL Server, confira Visão geral de grupos de disponibilidade Always On (SQL Server).
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de