Grupos de disponibilidade distribuídos
Aplica-se a:![]() SQL Server
SQL Server
Um AG (grupo de disponibilidade) distribuído é um tipo especial de grupo de disponibilidade que abrange dois grupos de disponibilidade separados. Os grupos de disponibilidade distribuídos estão disponíveis a partir do SQL Server 2016.
Este artigo descreve o recurso de grupo de disponibilidade distribuído. Para configurar um grupo de disponibilidade distribuído, consulte Configurar grupos de disponibilidade distribuídos.
Visão geral
Um grupo de disponibilidade distribuído é um tipo especial de grupo de disponibilidade que abrange dois grupos de disponibilidade separados. Os grupos de disponibilidade que fazem parte de um grupo de disponibilidade distribuído não precisam estar no mesmo local. Eles podem ser físicos, virtuais, locais, estar na nuvem pública ou em qualquer lugar compatível com uma implantação de grupo de disponibilidade. Isso inclui domínios cruzados e multiplataforma, por exemplo, entre um grupo de disponibilidade hospedado no Linux e outro hospedado no Windows. Contanto que dois grupos de disponibilidade possam se comunicar, você pode configurar um grupo de disponibilidade distribuído com eles.
Um grupo de disponibilidade tradicional tem recursos configurados em um WSFC (Cluster de Failover do Windows Server) ou, quando o ambiente é Linux, no Pacemaker. Um grupo de disponibilidade distribuído não configura nada no cluster subjacente (WSFC ou Pacemaker). Tudo sobre ele é mantido no SQL Server. Para saber como exibir informações de um grupo de disponibilidade distribuído, consulte Exibindo informações do grupo de disponibilidade distribuído.
Um grupo de disponibilidade distribuído exige que os grupos de disponibilidade subjacentes tenham um ouvinte. Em vez de fornecer o nome do servidor subjacente de uma instância autônoma (ou, no caso de uma instância de cluster de failover do SQL Server [FCI], o valor associado ao recurso de nome de rede) como você faria com um grupo de disponibilidade tradicional, especifique o ouvinte configurado para o grupo de disponibilidade distribuído com o parâmetro ENDPOINT_URL ao criá-lo. Embora cada grupo de disponibilidade subjacente do grupo de disponibilidade distribuído tenha um ouvinte, um grupo de disponibilidade distribuído não tem nenhum ouvinte.
A figura a seguir mostra uma exibição de alto nível de um grupo de disponibilidade distribuído que abrange dois grupos de disponibilidade (AG 1 e AG 2), cada um configurado no próprio cluster do WSFC. O grupo de disponibilidade distribuído tem um total de quatro réplicas, com dois em cada grupo de disponibilidade. Cada grupo de disponibilidade pode dar suporte a até o número máximo de réplicas, ou seja, um grupo de disponibilidade distribuído pode ter um total de até 18 réplicas.

Você pode configurar a movimentação de dados em grupos de disponibilidade distribuídos como síncrona ou assíncrona. No entanto, a movimentação de dados é ligeiramente diferente nos grupos de disponibilidade distribuídos comparado a um grupo de disponibilidade tradicional. Embora cada grupo de disponibilidade tenha uma réplica primária, há apenas uma cópia dos bancos de dados que fazem parte de um grupo de disponibilidade distribuído que pode aceitar inserções, atualizações e exclusões. Conforme mostrado na figura a seguir, o AG 1 é o grupo de disponibilidade primário. Sua réplica primária envia transações para as réplicas secundárias do AG 1 e a réplica primária do AG 2. A réplica primária do AG 2 também é conhecida como um encaminhador. Um encaminhador é uma réplica primária em um grupo de disponibilidade secundário em um grupo de disponibilidade distribuída. O encaminhador recebe as transações da réplica primária no grupo de disponibilidade primária e os encaminha para as réplicas secundárias em seu próprio grupo de disponibilidade. O encaminhador mantém as réplicas secundárias do AG 2 atualizadas.
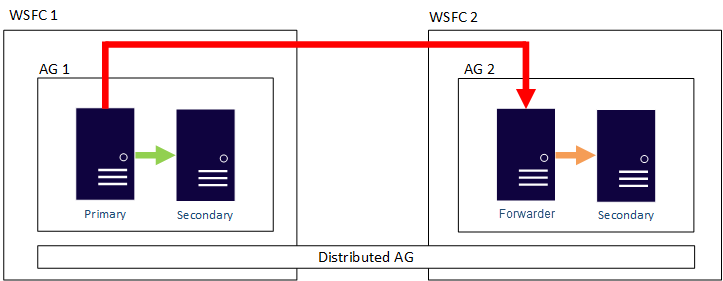
A única maneira de fazer com que a réplica primária do AG 2 aceite inserções, atualizações e exclusões é fazer failover manual do grupo de disponibilidade distribuído do AG 1. Na figura anterior, como o AG 1 contém a cópia gravável do banco de dados, a emissão de um failover faz com que o grupo de disponibilidade AG 2 possa manipular inserções, atualizações e exclusões. Para obter informações sobre como fazer failover de um grupo de disponibilidade distribuído para outro, consulte Failover para um grupo de disponibilidade secundário.
Observação
Os grupos de disponibilidade distribuídos do SQL Server 2016 dão suporte ao failover somente de um grupo de disponibilidade para outro usando a opção FORCE_FAILOVER_ALLOW_DATA_LOSS.
Observação
Ao usar a replicação transacional com grupos de disponibilidade distribuídos, a réplica de encaminhador não pode ser configurada como um publicador.
Requisitos de versão e edição
Grupos de disponibilidade distribuídos no SQL Server 2017 ou posterior podem combinar versões principais do SQL Server no mesmo grupo de disponibilidade distribuído. O AG que contém o primário de leitura/gravação pode ser de uma versão igual ou inferior a de outros AGs que participam do AG distribuído. Outros AGs podem ser de uma versão igual ou superior. Esse cenário é direcionado a cenários de atualização e migração. Por exemplo, se o AG que contém a réplica primária de leitura/gravação for SQL Server 2016, mas você quiser atualizar/migrar para o SQL Server 2017 ou posterior, o outro AG que participa do AG distribuído poderá ser configurado com o SQL Server 2017.
Como o recurso de grupos de disponibilidade distribuídos não existe no SQL Server 2012 ou 2014, os grupos de disponibilidade que foram criados com essas versões não podem fazer parte de grupos de disponibilidade distribuídos.
Observação
Dependendo da versão do SQL Server, ao se conectar aos serviços do Azure (como o Link de Instância Gerenciada), é possível configurar um grupo de disponibilidade distribuído com a edição Standard ou uma combinação das edições Standard e Enterprise. Consulte o artigo KB5016729 para saber mais.
Como há dois grupos de disponibilidade separados, o processo de instalação de um service pack ou de uma atualização cumulativa em uma réplica que faz parte de um grupo de disponibilidade distribuído é ligeiramente diferente do processo de um grupo de disponibilidade tradicional:
Comece atualizando as réplicas do segundo grupo de disponibilidade do grupo de disponibilidade distribuído.
Aplique patch às réplicas do grupo de disponibilidade primário do grupo de disponibilidade distribuído.
Assim como você faz com um grupo de disponibilidade padrão, faça failover do grupo de disponibilidade primário para uma de suas próprias réplicas (não para o primário do segundo grupo de disponibilidade) e aplique patch a ele. Se não houver nenhuma réplica que não seja o primário, um failover manual para o segundo grupo de disponibilidade será necessário.
Versões do Windows Server e grupos de disponibilidade distribuídos
Um grupo de disponibilidade distribuído abrange vários grupos de disponibilidade, cada um no próprio cluster do WSFC subjacente. Um grupo de disponibilidade distribuído é um constructo somente do SQL Server. Isso significa que os WSFCs que abrigam os grupos de disponibilidade individuais podem ter diferentes versões principais do Windows Server. As versões principais do SQL Server devem ser as mesmas, conforme abordado na seção anterior. Assim como a figura inicial, a figura a seguir mostra o AG 1 e o AG 2 que participam de um grupo de disponibilidade distribuído, mas cada um dos WSFCs é uma versão diferente do Windows Server.
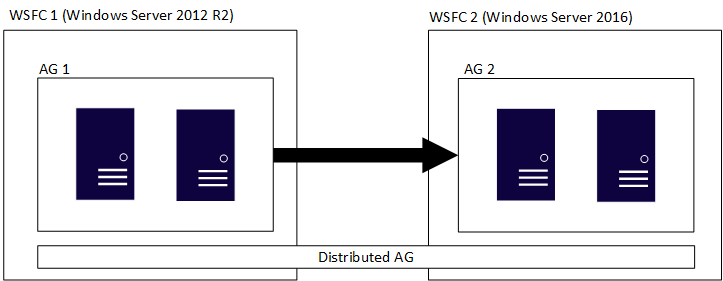
Os WSFCs individuais e os grupos de disponibilidade correspondentes seguem as regras tradicionais. Ou seja, eles podem ser ingressados ou não em um domínio (Windows Server 2016 ou posterior). Quando dois grupos de disponibilidade diferentes são combinados em um único grupo de disponibilidade distribuído, há quatro cenários:
- Os dois WSFCs são ingressados no mesmo domínio.
- Cada WSFC é ingressado em um domínio diferente.
- Um WSFC é ingressado em um domínio, e um WSFC não é ingressado a nenhum domínio.
- Nenhum dos WSFCs é ingressado em um domínio.
Quando os dois WSFCs são ingressados no mesmo domínio (não em domínios confiáveis), você não precisa fazer nada especial ao criar o grupo de disponibilidade distribuído. Para grupos de disponibilidade e WSFCs que não ingressaram no mesmo domínio, use certificados para fazer com que o grupo de disponibilidade distribuído funcione, como quando você cria um grupo de disponibilidade para um grupo de disponibilidade independente de domínio. Para saber como configurar certificados para um grupo de disponibilidade distribuído, siga as etapas 3 a 13 em Criar um grupo de disponibilidade independente de domínio.
Com um grupo de disponibilidade distribuído, as réplicas primárias de cada grupo de disponibilidade subjacente devem ter os certificados umas das outras. Se você já tiver pontos de extremidade que não estejam usando certificados, reconfigure os pontos de extremidade usando ALTER ENDPOINT para refletir o uso de certificados.
Cenários de uso
Estes são os três principais cenários de uso de um grupo de disponibilidade distribuído:
- Recuperação de desastre e configurações multissite mais fáceis
- Migração para o novo hardware ou para as novas configurações, que pode incluir o uso do novo hardware ou a alteração dos sistemas operacionais subjacentes
- Aumentar o número de réplicas de leitura além de oito em um único grupo de disponibilidade, abrangendo vários grupos de disponibilidade
Cenários de recuperação de desastre e multissite
Um grupo de disponibilidade tradicional exige que todos os servidores façam parte do mesmo WSFC, o que pode dificultar a abrangência de vários data centers. A figura a seguir mostra a aparência da arquitetura de um grupo de disponibilidade multissite tradicional, incluindo o fluxo de dados. Há uma réplica primária que envia transações para todas as réplicas secundárias. Essa configuração é menos flexível de algumas maneiras do que um grupo de disponibilidade distribuído. Por exemplo, você precisa implementar itens como o Active Directory (se aplicável) e a testemunha para um quorum no WSFC. Talvez você também precise considerar outros aspectos de um WSFC, como a alteração dos votos de nó.

Os grupos de disponibilidade distribuídos oferecem um cenário de implantação mais flexível para grupos de disponibilidade que abrangem vários data centers. Você pode usar até mesmo grupos de disponibilidade distribuídos nos quais recursos como o envio de logs foram usados no passado para cenários como recuperação de desastre. No entanto, ao contrário do envio de logs, os grupos de disponibilidade distribuídos não podem ter a aplicação atrasada de transações. Isso significa que os grupos de disponibilidade ou os grupos de disponibilidade distribuídos não podem ajudar, em caso de erro humano em que os dados são atualizados incorretamente ou excluídos.
Os grupos de disponibilidade distribuídos são acoplados de modo flexível, o que, nesse caso, significa que eles não exigem nenhum WSFC e são mantidos pelo SQL Server. Como os WSFCs são mantidos individualmente e a sincronização é principalmente assíncrona entre os dois grupos de disponibilidade, é mais fácil configurar a recuperação de desastre em outro site. As réplicas primárias em cada grupo de disponibilidade sincronizam suas próprias réplicas secundárias.
- Apenas há suporte para o failover manual em um grupo de disponibilidade distribuído. Em uma situação de recuperação de desastre em que você está alternando data centers, você não deve configurar o failover automático (com raras exceções).
- Provavelmente, não será necessário definir alguns dos itens ou parâmetros tradicionais dos WSFCs multissite ou de sub-rede, como CrossSubnetThreshold, mas será necessário considerar a latência de rede em uma camada diferente para o transporte de dados. A diferença é que cada WSFC mantém a própria disponibilidade. O cluster não é uma entidade grande de quatro nós. Você tem dois WSFCs de dois nós separados, conforme mostrado na figura anterior.
- Recomendamos a movimentação de dados assíncrona, porque essa abordagem será para fins de recuperação de desastre.
- Se você configurar a movimentação de dados síncrona entre a réplica primária e, pelo menos, uma réplica secundária do segundo grupo de disponibilidade e configurar a movimentação síncrona no grupo de disponibilidade distribuído, um grupo de disponibilidade distribuído aguardará até que todas as cópias síncronas reconheçam que contêm os dados. Se vários grupos de disponibilidade distribuídos são encadeados em cascata (AG1 –> AG2 –> AG3) e definidos como síncronos, um grupo de disponibilidade distribuído aguardará até que a última réplica do último grupo de disponibilidade seja atualizada.
Migrações
Como os grupos de disponibilidade distribuídos dão suporte a duas configurações de grupo de disponibilidade completamente diferentes, eles permitem não apenas cenários de recuperação de desastre e multissite mais fáceis, mas também cenários de migração. Se você estiver migrando para um novo hardware ou novas máquinas virtuais (IaaS na nuvem pública ou local), a configuração de um grupo de disponibilidade distribuído permitirá que uma migração ocorra, quando, no passado, você poderia ter usado o backup, a cópia e a restauração ou o envio de logs.
A capacidade de migrar é especialmente útil em cenários em que você está alterando ou fazendo upgrade do sistema operacional subjacente, ao mesmo tempo que mantém a mesma versão do SQL Server. Embora o Windows Server 2016 permita uma atualização sem interrupção do Windows Server 2012 R2 no mesmo hardware, a maioria dos usuários opta por implantar um novo hardware ou novas máquinas virtuais.
Para concluir a migração para a nova configuração, no final do processo, pare todo o tráfego de dados do grupo de disponibilidade original e altere o grupo de disponibilidade distribuído para a movimentação de dados síncrona. Essa ação garante que a réplica primária do segundo grupo de disponibilidade está totalmente sincronizada, de modo que não haja nenhuma perda de dados. Depois de verificar a sincronização, faça failover do grupo de disponibilidade distribuída para o grupo de disponibilidade secundária. Para obter mais informações, consulte Fazer failover em um grupo de disponibilidade secundária.
Após a migração, na qual o segundo grupo de disponibilidade agora é o novo grupo de disponibilidade primário, talvez seja necessário fazer as seguintes etapas:
- Renomeie o ouvinte no grupo de disponibilidade secundário (e possivelmente exclua ou renomeie o antigo no grupo de disponibilidade primário original) ou recrie-o com o ouvinte do grupo de disponibilidade primário original, para que os aplicativos e os usuários possam acessar a nova configuração.
- Se uma renomeação ou recriação não for possível, aponte os aplicativos e os usuários para o ouvinte no segundo grupo de disponibilidade.
Migrar para versões mais altas do SQL Server
Durante um cenário de migração, embora seja possível configurar um AG distribuído para migrar seus bancos de dados para um destino SQL Server que seja uma versão mais alta do que a origem, há algumas limitações.
Quando você configura o AG distribuído com um destino de migração de SQL Server com uma versão superior à origem, não há suporte para a propagação automática, portanto o modo de propagação deve ser definido como MANUAL. Se você não desabilitar o AUTO-SEEDING, sua migração falhará e você verá o erro 946 "Não é possível abrir a versão do banco de dados 'DistributionAG' xxx. Atualize o banco de dados para a versão mais recente" no log de erros. Você deve definir o modo de propagação como MANUAL e executar manualmente um backup completo e de log de transações do banco de dados de origem do AG primário. Em seguida, restaure-o manualmente, juntamente com o log de transações, para o AG secundário. Para saber mais, examine as etapas de propagação manual para configurar seu AG distribuído e os scripts para fazer backup e restaurar seu banco de dados do AG primário para o AG secundário.
Supondo que o AG2 (AG secundário) seja o destino de migração com uma versão superior à do AG1 (AG primário), considere as seguintes limitações:
- Você não terá acesso de leitura a nenhuma réplica dos bancos de dados no AG secundário, pois o AG primário tem uma versão inferior.
- Durante esse tempo, as atualizações continuarão fluindo do AG primário (AG1) para o AG secundário (AG2), mas o status do AG secundário será exibido como parcialmente íntegro, e os bancos de dados em réplicas secundárias do AG secundário (AG2) aparecerão como sincronizando/em recuperação, mesmo se o AG estiver em uma confirmação de sincronização.
- Uma vez que o AG distribuído é transferido para a versão superior (AG2), o AG2 deve se tornar íntegro.
- Durante esse tempo, o failback para AG1 não será possível, pois ele está em uma versão inferior.
- Como o AG1 está em uma versão inferior, as atualizações do AG2 após o failover para o AG2 não serão replicadas para o AG1.
- A partir daqui, escolha se deseja encerrar o AG original (primário) ou se deseja atualizar o AG1 e manter o AG distribuído.
- Se você optar por encerrar o AG1, remova o AG primário original do AG distribuído e o processo estará concluído.
- Se você optar por manter o AG distribuído, atualize a versão do SQL Server para AG1 para corresponder ao AG2. Depois que o AG1 é atualizado, o AG1 fica íntegro, o AG distribuído fica íntegro, as réplicas se atualizam para sincronizar e o failback se torna possível.
Expandir réplicas legíveis
Um único grupo de disponibilidade distribuído pode ter até 16 réplicas secundárias, conforme necessário. Portanto, ele pode ter até 18 cópias para leitura, incluindo as duas réplicas primárias dos grupos de disponibilidade diferentes. Essa abordagem significa que mais de um site pode ter acesso quase em tempo real para relatar para vários aplicativos.
Os grupos de disponibilidade distribuídos podem ajudar você a expandir um farm somente leitura mais do que conseguirá com apenas um único grupo de disponibilidade. Um grupo de disponibilidade distribuído pode expandir réplicas legíveis de duas maneiras:
- Use a réplica primária do segundo grupo de disponibilidade em um grupo de disponibilidade distribuído para criar outro grupo de disponibilidade distribuído, mesmo que o banco de dados não esteja no estado RECOVERY.
- Você também pode usar a réplica primária do primeiro grupo de disponibilidade para criar outro grupo de disponibilidade distribuído.
Em outras palavras, uma réplica primária pode fazer parte de dois grupos de disponibilidade distribuídos diferentes. A figura a seguir mostra AG 1 e AG 2 fazendo parte do AG 1 Distribuído, enquanto AG 2 e AG 3 fazem parte do AG 2 Distribuído. A réplica primária (ou encaminhador) do AG 2 é uma réplica secundária para o AG 1 Distribuído e uma réplica primária do AG 2 Distribuído.
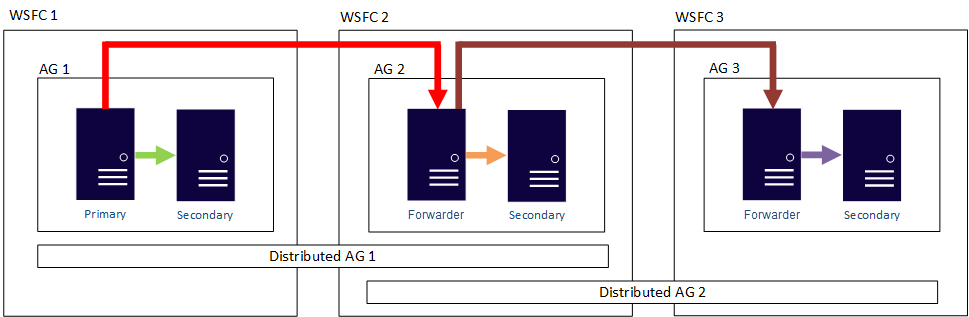
A figura a seguir mostra o AG 1 como a réplica primária para dois grupos de disponibilidade distribuídos diferentes: AG 1 Distribuído (composto por AG 1 e AG 2) e AG 2 Distribuído (composto por AG 1 e AG 3).

Nos dois exemplos anteriores, pode haver até 27 réplicas no total nos três grupos de disponibilidade, que podem ser usados para consultas somente leitura.
O roteamento de somente leitura não funciona totalmente com Grupos de Disponibilidade Distribuídos. Mais especificamente,
- o Roteamento de Somente Leitura pode ser configurado e funcionará no grupo de disponibilidade primária do grupo de disponibilidade distribuída.
- O Roteamento de Somente Leitura pode ser configurado, mas não funcionará no grupo de disponibilidade secundário do grupo de disponibilidade distribuído. Todas as consultas, se usarem o ouvinte para se conectar ao grupo de disponibilidade secundária, vão para a réplica primária do grupo de disponibilidade secundária. Caso contrário, você precisará configurar cada réplica para permitir todas as conexões como uma réplica secundária e acessá-las diretamente. No entanto, o roteamento somente leitura funcionará se o grupo de disponibilidade secundária se tornar primário após um failover. Esse comportamento pode ser alterado em uma atualização para o SQL Server 2016 ou em uma versão futura do SQL Server.
Inicializar grupos de disponibilidade secundários
Os grupos de disponibilidade distribuídos foram criados com a propagação automática como o principal método usado para inicializar a réplica primária no segundo grupo de disponibilidade. Uma restauração completa de banco de dados na réplica primária do segundo grupo de disponibilidade será possível se você fizer o seguinte:
- Restaure o backup de banco de dados com WITH NORECOVERY.
- Se necessário, restaure os backups de log de transações apropriados com WITH NORECOVERY.
- Crie o segundo grupo de disponibilidade sem especificar um nome de banco de dados e com SEEDING_MODE definido como AUTOMATIC.
- Crie o grupo de disponibilidade distribuído usando a propagação automática.
Quando você adicionar a réplica primária do segundo grupo de disponibilidade ao grupo de disponibilidade distribuído, a réplica será verificada nos bancos de dados primários do primeiro grupo de disponibilidade e a propagação automática atualizará o banco de dados com a origem. Há algumas advertências:
A saída mostrada em
sys.dm_hadr_automatic_seedingna réplica primária do segundo grupo de disponibilidade exibirá umcurrent_stateFAILED com o motivo “Tempo limite da mensagem de verificação da propagação”.O log de erros atual do SQL Server na réplica primária do segundo grupo de disponibilidade mostrará que a propagação automática funcionou e que os LSNs foram sincronizados.
A saída mostrada em
sys.dm_hadr_automatic_seedingna réplica primária do primeiro grupo de disponibilidade mostrará um current_state COMPLETED.A propagação automática também tem um comportamento diferente com grupos de disponibilidade distribuídos. Para que a propagação automática seja iniciada na segunda réplica, você deve emitir o comando
ALTER AVAILABILITY GROUP [AGName] GRANT CREATE ANY DATABASEna réplica. Embora essa condição ainda seja verdadeira sobre qualquer réplica secundária que faz parte do grupo de disponibilidade subjacente, a réplica primária do segundo grupo de disponibilidade já tem as permissões corretas para permitir o início da propagação automática depois que ela é adicionada ao grupo de disponibilidade distribuído.
Monitorar integridade
Um grupo de disponibilidade distribuído é um constructo somente do SQL Server e não é visto no WSFC subjacente. O exemplo de código a seguir mostra dois WSFCs diferentes (CLUSTER_A e CLUSTER_B), cada um com seus próprios grupos de disponibilidade. Somente o AG1 no CLUSTER_A e o AG2 no CLUSTER_B são abordados aqui.
PS C:\> Get-ClusterGroup -Cluster CLUSTER_A
Name OwnerNode State
---- --------- -----
AG1 DENNIS Online
Available Storage GLEN Offline
Cluster Group JY Online
New_RoR DENNIS Online
Old_RoR DENNIS Online
SeedingAG DENNIS Online
PS C:\> Get-ClusterGroup -Cluster CLUSTER_B
Name OwnerNode State
---- --------- -----
AG2 TOMMY Online
Available Storage JC Offline
Cluster Group JC Online
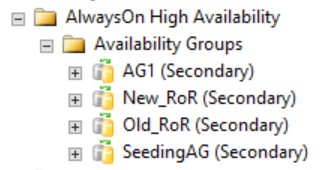
Todas as informações detalhadas sobre um grupo de disponibilidade distribuída estão no SQL Server, especificamente nas exibições de gerenciamento dinâmico do grupo de disponibilidade. Atualmente, as únicas informações mostradas no SQL Server Management Studio para um grupo de disponibilidade distribuída estão na réplica primária para os grupos de disponibilidade. Conforme mostrado na figura a seguir, na pasta Grupos de Disponibilidade, o SQL Server Management Studio mostra que há um grupo de disponibilidade distribuída. A figura mostra AG1 como uma réplica primária para um grupo de disponibilidade individual que é local para essa instância, e não para um grupo de disponibilidade distribuída.

No entanto, se você clicar com o botão direito do mouse no grupo de disponibilidade distribuída, nenhuma opção estará disponível (consulte a figura a seguir) e as pastas expandidas Grupos de Disponibilidade, Ouvintes do Grupo de Disponibilidade e Réplicas de Disponibilidade estarão vazias. O SQL Server Management Studio 16 exibe esse resultado, mas ele poderá ser alterado em uma versão futura do SQL Server Management Studio.

Conforme mostrado na figura a seguir, as réplicas secundárias não mostram nada no SQL Server Management Studio relacionado ao grupo de disponibilidade distribuída. Esses nomes de grupo de disponibilidade são mapeados para as funções mostradas anteriormente na imagem CLUSTER_A do WSFC.
DMV para listar todos os nomes de réplica de disponibilidade
Os mesmos conceitos são verdadeiros quando você usa as exibições de gerenciamento dinâmico. Ao usar a consulta a seguir, você pode ver todos os grupos de disponibilidade (regulares e distribuídos) e os nós que participam deles. Esse resultado será exibido apenas se você consultar a réplica primária em um dos WSFCs que participam do grupo de disponibilidade distribuído. Há uma nova coluna na exibição de gerenciamento dinâmico sys.availability_groups chamado is_distributed, que é 1 quando o grupo de disponibilidade é um grupo de disponibilidade distribuída. Para ver essa coluna:
-- shows replicas associated with availability groups
SELECT
ag.[name] AS [AG Name],
ag.Is_Distributed,
ar.replica_server_name AS [Replica Name]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id;
GO
Um exemplo de saída do segundo WSFC que está participando de um grupo de disponibilidade distribuído é mostrado na figura a seguir. SPAG1 é composto de duas réplicas: DENNIS e JY. No entanto, o grupo de disponibilidade distribuída denominado SPDistAG tem os nomes dos dois grupos de disponibilidade participantes (SPAG1 e SPAG2) em vez dos nomes de instâncias, assim como acontece com um grupo de disponibilidade tradicional.
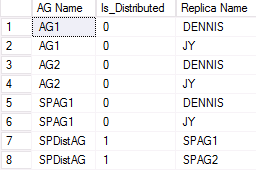
DMV para listar a integridade do AG distribuído
No SQL Server Management Studio, qualquer status mostrado no painel e em outras áreas é destinado à sincronização local somente dentro desse grupo de disponibilidade. Para exibir a integridade de um grupo de disponibilidade distribuída, consulte as exibições de gerenciamento dinâmico. A consulta de exemplo a seguir amplia e aprimora a consulta anterior:
-- shows sync status of distributed AG
SELECT
ag.[name] AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [Underlying AG],
ars.role_desc AS [Role],
ars.synchronization_health_desc AS [Sync Status]
FROM sys.availability_groups AS ag
INNER JOIN sys.availability_replicas AS ar
ON ag.group_id = ar.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV para exibir o desempenho subjacente
Para estender ainda mais a consulta anterior, você também pode ver o desempenho subjacente por meio de exibições de gerenciamento dinâmico ao adicionar em sys.dm_hadr_database_replicas_states. Atualmente, o modo de exibição de gerenciamento dinâmico armazena informações somente sobre o segundo grupo de disponibilidade. A consulta de exemplo a seguir, executada no grupo de disponibilidade primária, gera a saída de exemplo mostrada abaixo:
-- shows underlying performance of distributed AG
SELECT
ag.[name] AS [Distributed AG Name],
ar.replica_server_name AS [Underlying AG],
dbs.[name] AS [Database],
ars.role_desc AS [Role],
drs.synchronization_health_desc AS [Sync Status],
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate
FROM sys.databases AS dbs
INNER JOIN sys.dm_hadr_database_replica_states AS drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups AS ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states AS ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = ars.replica_id
WHERE ag.is_distributed = 1;
GO

DMV para exibir os contadores de desempenho para o AG distribuído
A consulta abaixo exibe os contadores de desempenho associados ao grupo de disponibilidade distribuído específico.
-- displays OS performance counters related to the distributed ag named 'distributedag'
SELECT * FROM sys.dm_os_performance_counters WHERE instance_name LIKE '%distributed%'

Observação
O filtro LIKE deve ter o nome do grupo de disponibilidade distribuído. Neste exemplo, o nome do grupo de disponibilidade distribuído é “distributedag”. Altere o modificador LIKE para refletir o nome do seu grupo de disponibilidade distribuído.
DMV para exibir a integridade do AG e do AG distribuído
A consulta abaixo exibe uma grande quantidade de informações sobre a integridade do grupo de disponibilidade e do grupo de disponibilidade distribuído. (Reproduzido com permissão de Tracy Boggiano.)
-- displays sync status, send rate, and redo rate of availability groups,
-- including distributed AG
SELECT ag.name AS [AG Name],
ag.is_distributed,
ar.replica_server_name AS [AG],
dbs.name AS [Database],
ars.role_desc,
drs.synchronization_health_desc,
drs.log_send_queue_size,
drs.log_send_rate,
drs.redo_queue_size,
drs.redo_rate,
drs.suspend_reason_desc,
drs.last_sent_time,
drs.last_received_time,
drs.last_hardened_time,
drs.last_redone_time,
drs.last_commit_time,
drs.secondary_lag_seconds
FROM sys.databases dbs
INNER JOIN sys.dm_hadr_database_replica_states drs
ON dbs.database_id = drs.database_id
INNER JOIN sys.availability_groups ag
ON drs.group_id = ag.group_id
INNER JOIN sys.dm_hadr_availability_replica_states ars
ON ars.replica_id = drs.replica_id
INNER JOIN sys.availability_replicas ar
ON ar.replica_id = ars.replica_id
--WHERE ag.is_distributed = 1
GO

DMVs para exibir metadados do AG distribuído
As consultas abaixo exibirão as informações sobre as URLs de ponto de extremidade usadas pelos grupos de disponibilidade, incluindo o grupo de disponibilidade distribuído. (Reproduzido com permissão de David Barbarin.)
-- shows endpoint url and sync state for ag, and dag
SELECT
ag.name AS group_name,
ag.is_distributed,
ar.replica_server_name AS replica_name,
ar.endpoint_url,
ar.availability_mode_desc,
ar.failover_mode_desc,
ar.primary_role_allow_connections_desc AS allow_connections_primary,
ar.secondary_role_allow_connections_desc AS allow_connections_secondary,
ar.seeding_mode_desc AS seeding_mode
FROM sys.availability_replicas AS ar
JOIN sys.availability_groups AS ag
ON ar.group_id = ag.group_id;
GO

DMV para mostrar o estado atual da propagação
A consulta abaixo exibe informações sobre o estado atual da propagação. Isso é útil para solução de problemas de erros de sincronização entre as réplicas. (Reproduzido com permissão de David Barbarin.)
-- shows current_state of seeding
SELECT ag.name AS aag_name,
ar.replica_server_name,
d.name AS database_name,
has.current_state,
has.failure_state_desc AS failure_state,
has.error_code,
has.performed_seeding,
has.start_time,
has.completion_time,
has.number_of_attempts
FROM sys.dm_hadr_automatic_seeding AS has
INNER JOIN sys.availability_groups AS ag
ON ag.group_id = has.ag_id
INNER JOIN sys.availability_replicas AS ar
ON ar.replica_id = has.ag_remote_replica_id
INNER JOIN sys.databases AS d
ON d.group_database_id = has.ag_db_id;
GO

Conteúdo relacionado
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de