Guia de arquitetura de processamento de consultas
Aplica-se a:![]() SQL Server
SQL Server![]() Banco de Dados SQL do Azure
Banco de Dados SQL do Azure![]() Instância Gerenciada de SQL do Azure
Instância Gerenciada de SQL do Azure
O Mecanismo de Banco de Dados do SQL Server processa consultas em diversas arquiteturas de armazenamento de dados, como tabelas locais, particionadas e distribuídas entre vários servidores. As seções a seguir abordam como o SQL Server processa consultas e otimiza a reutilização de consultas por meio do cache de planos de execução.
Modos de execução
O Mecanismo de Banco de Dados do SQL Server pode processar instruções Transact-SQL usando dois modos de processamento diferentes:
- Execução em modo de linha
- Execução em modo de lote
Execução em modo de linha
A execução em modo de linha é um método de processamento de consulta usado com tabelas RDMBS tradicionais, em que os dados são armazenados no formato de linha. Quando uma consulta é executada e acessa dados em tabelas com armazenamento em linha, os operadores de árvore de execução e os operadores filho leem cada linha necessária, em todas as colunas especificadas no esquema de tabela. De cada linha lida, o SQL Server recupera as colunas necessárias para o conjunto de resultados, conforme referenciado por uma instrução SELECT, um predicado JOIN ou um predicado de filtro.
Observação
A execução em modo de linha é muito eficiente para cenários OLTP, mas pode ser menos eficiente na verificação de grandes quantidades de dados, por exemplo, em cenários de Data Warehouse.
Execução em modo de lote
A execução em modo de lote é um método de processamento de consulta usado para processar várias linhas simultaneamente (por isso o termo lote). Cada coluna em um lote é armazenada como um vetor em uma área separada da memória, de modo que o processamento em modo de lote é baseado em vetor. O processamento em modo de lote também usa algoritmos que são otimizados para CPUs de vários núcleos e maior taxa de transferência de memória, características encontradas no hardware moderno.
Quando foi introduzida, a execução em modo de lote era estreitamente integrada ao formato de armazenamento columnstore e otimizado com base nele. No entanto, a partir do SQL Server 2019 (15.x) e no Banco de Dados SQL do Azure, a execução do modo em lote não requer mais índices columnstore. Para saber mais, confira Modo de lote em rowstore.
O processamento em modo de lote opera nos dados compactados quando possível e elimina o operador de troca usado pela execução em modo de linha. O resultado é um melhor paralelismo e um desempenho mais rápido.
Quando uma consulta é executada em modo de lote e acessa dados em índices columnstore, os operadores de árvore de execução e operadores filho leem várias linhas juntas em segmentos de coluna. O SQL Server lê apenas as colunas necessárias para o resultado, conforme referenciado por uma instrução SELECT, um predicado JOIN ou um predicado de filtro. Para obter mais informações sobre índices columnstore, consulte Arquitetura de índice columnstore.
Observação
A execução em modo de lote é muito eficiente em cenários de Data Warehouse, em que grandes quantidades de dados são lidas e agregadas.
Processamento de instruções SQL
O processamento de uma única instrução Transact-SQL é o modo mais básico para o SQL Server executar instruções Transact-SQL. As etapas usadas para processar uma única instrução SELECT que referencia apenas as tabelas base locais (nenhuma exibição ou tabelas remotas) ilustram o processo básico.
Precedência de operador lógico
Quando mais de um operador lógico é usado em uma instrução, NOT é avaliado primeiro, em seguida, AND e, finalmente, OR. Operadores aritméticos e bit a bit são tratados antes dos operadores lógicos. Para obter mais informações, confira Operator Precedence (Precedência de operador).
No exemplo a seguir, a condição de cor pertence ao modelo de produto 21 e não ao modelo de produto 20, porque AND tem precedência em relação a OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Você pode alterar o significado da consulta adicionando parênteses para forçar a avaliação de OR primeiro. A consulta a seguir só encontra produtos nos modelos 20 e 21 que são vermelhos.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Usar parênteses, até mesmo quando eles não são necessários, pode melhorar a legibilidade das consultas e reduzir a chance de cometer um erro sutil devido à precedência do operador. Não há penalidade de desempenho significativa usando parênteses. O exemplo a seguir é mais legível que o exemplo original, embora eles sejam sintaticamente semelhantes.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Otimizar instruções SELECT
Uma instrução SELECT não é processual; ela não determina as etapas exatas que o servidor de banco de dados deve usar para recuperar os dados solicitados. Isso significa que o servidor de banco de dados deve analisar a instrução para determinar o modo mais eficiente para extrair os dados solicitados. Isso é conhecido como otimização da instrução SELECT . O componente que faz isso é chamado de Otimizador de Consulta. A entrada do Otimizador de Consulta consiste em uma consulta, o esquema de banco de dados (definições de tabela e de índice) e as estatísticas de banco de dados. A saída do Otimizador de Consulta é um plano de execução de consulta, às vezes chamado de plano de consulta ou plano de execução. O conteúdo de um plano de execução é descrito com mais detalhes posteriormente neste artigo.
As entradas e as saídas do Otimizador de Consulta durante a otimização de uma única instrução SELECT são ilustradas no seguinte diagrama:
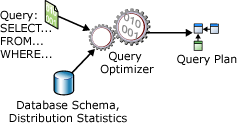
Uma instrução SELECT define apenas o seguinte:
- O formato do conjunto de resultados. Isso é especificado principalmente na lista de seleção. Porém, outras cláusulas como
ORDER BYeGROUP BYtambém afetam a forma final do conjunto de resultados. - As tabelas que contêm os dados de origem. Isso é especificado na cláusula
FROM. - A forma pela qual as tabelas estão logicamente relacionadas à finalidade da instrução
SELECT. Isso é definido nas especificações de junção, que podem ser exibidas na cláusulaWHEREou em uma cláusulaONseguida deFROM. - As condições que as linhas das tabelas de origem devem satisfazer para serem qualificadas para a instrução
SELECT. Essas são especificadas nas cláusulasWHEREeHAVING.
Um plano de execução de consulta é uma definição do seguinte:
A sequência em que as tabelas de origem são acessadas.
Normalmente, há muitas sequências pelas quais o servidor de banco de dados pode acessar as tabelas base para criar o conjunto de resultados. Por exemplo, se a instruçãoSELECTfizesse referência a três tabelas, o servidor de banco de dados poderia acessarTableAprimeiro, usar os dados deTableApara extrair as linhas correspondentes deTableBe usar os dados deTableBpara extrair dados deTableC. As outras sequências em que o servidor de banco de dados poderia acessar as tabelas são:
TableC,TableB,TableAou
TableB,TableA,TableCou
TableB,TableC,TableAou
TableC,TableA,TableBOs métodos usados para extrair dados de cada tabela.
Geralmente, há métodos diferentes para acessar os dados em cada tabela. Se forem necessárias apenas algumas linhas com valores de chave específicos, o servidor de banco de dados poderá usar um índice. Se forem necessárias todas as linhas da tabela, o servidor de banco de dados poderá ignorar os índices e executar um exame na tabela. Se forem necessárias todas as linhas de uma tabela, mas houver um índice cujas colunas de chave estão em umORDER BY, executando um exame de índice em vez de um exame de tabela, uma classificação separada do conjunto de resultados poderá ser salva. Se uma tabela for muito pequena, os exames de tabela poderão ser o método mais eficiente para quase todos os acessos à tabela.Os métodos usados para computar cálculos e como filtrar, agregar e classificar dados de cada tabela.
Como os dados são acessados a partir de tabelas, existem métodos diferentes para executar cálculos em dados, como a computação de valores escalares, e para agregar e classificar dados conforme definido no texto da consulta, por exemplo, ao usar uma cláusulaGROUP BYouORDER BY, e como filtrar dados, por exemplo, ao usar uma cláusulaWHEREouHAVING.
O processo de selecionar um plano de execução de muitos planos possíveis é chamado de otimização. O Otimizador de Consulta é um dos componentes mais importantes do Mecanismo de Banco de Dados. Enquanto alguma sobrecarga estiver sendo usada pelo otimizador de consulta para analisar a consulta e selecionar um plano, ela será salva várias vezes quando o otimizador de consulta escolher um plano de execução eficiente. Por exemplo, duas empresas de construção podem oferecer projetos idênticos para uma casa. Se, no início, uma empresa ficar alguns dias planejando como a casa será construída, e a outra empresa começar a construir sem planejamento, a empresa que gasta algumas horas para planejar o projeto provavelmente terminará primeiro.
O Otimizador de Consulta do SQL Server é um otimizador baseado no custo. Cada plano de execução possível tem um custo associado em termos de quantidade de recursos de computação usados. O otimizador de consulta deve analisar os possíveis planos e escolher o que tenha o menor custo estimado. Algumas instruções SELECT complexas têm milhares de planos de execução possíveis. Nesses casos, o Otimizador de Consulta não analisa todas as combinações possíveis. Em vez disso, usa algoritmos complexos para encontrar um plano de execução que tenha um custo razoavelmente próximo do custo mínimo possível.
O Otimizador de Consulta do SQL Server não escolhe apenas o plano de execução com o menor custo de recurso. Ele escolhe o plano que retorna resultados ao usuário com um custo razoável em recursos de forma rápida. Por exemplo, o processamento de uma consulta em paralelo normalmente usa mais recursos que o processamento em série, mas completa a consulta de forma mais rápida. O Otimizador de Consulta do SQL Server usará um plano de execução paralelo para retornar resultados se a carga do servidor não for afetada negativamente.
O Otimizador de Consulta do SQL Server se baseia nas estatísticas de distribuição ao estimar os custos de recursos de métodos diferentes para extrair informações de uma tabela ou um índice. As estatísticas de distribuição são mantidas para colunas e índices, além de reter as informações sobre a densidade1 dos dados subjacentes. Isso é usado para indicar a seletividade dos valores em um índice ou uma coluna específica. Por exemplo, em uma tabela que representa carros, muitos carros têm o mesmo fabricante, mas cada carro tem um VIN (número de identificação de veículo) exclusivo. Um índice no VIN é mais seletivo que um índice no fabricante, porque o VIN tem densidade menor que o fabricante. Se as estatísticas de índice não forem atuais, o otimizador de consulta poderá não fazer a melhor escolha para o estado atual da tabela. Para saber mais sobre densidades, confira Estatísticas.
1 A densidade define a distribuição de valores únicos que existem nos dados ou o número médio de valores duplicados para uma determinada coluna. Conforme a densidade diminui, aumenta a seletividade de um valor.
O Otimizador de Consulta do SQL Server é importante porque habilita o servidor de banco de dados a ajustar de forma dinâmica conforme as alterações das condições no banco de dados sem exigir a entrada de um programador ou administrador de banco de dados. Isso habilita os programadores a se concentrarem na descrição do resultado final da consulta. Eles podem confiar que o Otimizador de Consulta do SQL Server compilará um plano de execução eficiente para o estado do banco de dados toda vez que a instrução for executada.
Observação
O SQL Server Management Studio tem três opções para exibir planos de execução:
- O Plano de Execução Estimado, que é o plano compilado, conforme produzido pelo Otimizador de Consulta.
- O Plano de Execução Real, que é o mesmo que o plano compilado, mais o contexto de execução. Isso inclui informações de runtime disponíveis depois que a execução é concluída, como avisos de execução ou, em versões mais recentes do Mecanismo de Banco de Dados, o tempo decorrido e o tempo de CPU usados durante a execução.
- As Estatísticas de Consulta Dinâmica, que são o mesmo que o plano compilado, mais o contexto de execução. Isso inclui informações de runtime durante o progresso da execução e é atualizado a cada segundo. As informações de runtime incluem, por exemplo, o número real de linhas que fluem pelos operadores.
Processar uma instrução SELECT
As etapas básicas usadas pelo SQL Server para processar uma única instrução SELECT incluem o seguinte:
- O analisador examina a instrução
SELECTe a divide em unidades lógicas, como palavras-chave, expressões, operadores e identificadores. - Uma árvore de consulta, às vezes chamada de árvore de sequência, é criada descrevendo as etapas lógicas necessárias para transformar os dados de origem no formato solicitado pelo conjunto de resultados.
- O otimizador de consulta analisa modos diferentes pelos quais as tabelas de origem podem ser acessadas. Ele então seleciona a série de etapas que retorna os resultados mais rapidamente, usando menos recursos. A árvore de consulta é atualizada para registrar essa série exata de etapas. A versão final, otimizada da árvore de consulta é chamada de plano de execução.
- O mecanismo relacional é iniciado com a execução do plano de execução. Como as etapas que exigem dados das tabelas base são processadas, o mecanismo relacional solicita que o mecanismo de armazenamento rejeite os dados dos conjuntos de linhas solicitados do mecanismo relacional.
- O mecanismo relacional processa os dados retornados do mecanismo de armazenamento no formato definido para o conjunto de resultados e retorna o conjunto de resultados ao cliente.
Dobragem constante e avaliação de expressões
O SQL Server avalia algumas expressões de constantes antecipadamente para melhorar o desempenho de consulta. Isto é chamado de dobra constante. Uma constante é um literal Transact-SQL, como 3, 'ABC', '2005-12-31', 1.0e3 ou 0x12345678.
Expressões dobráveis
O SQL Server usa a dobragem constante com os seguintes tipos de expressões:
- Expressões aritméticas, como
1 + 1e5 / 3 * 2, que contêm apenas constantes. - Expressões lógicas, como
1 = 1e1 > 2 AND 3 > 4, que contêm apenas constantes. - Funções internas consideradas dobráveis pelo SQL Server, incluindo
CASTeCONVERT. Geralmente, uma função intrínseca será dobrável se for uma função de suas entradas apenas e não outras informações contextuais, como opções SET, configurações de idioma, opções de banco de dados e chaves de codificação. Funções não determinísticas não são dobráveis. Funções internas determinísticas são dobráveis, com algumas exceções. - Métodos determinísticos de tipos de dado CLR definidos pelo usuário e funções CLR determinísticas com valor escalar definidas pelo usuário (a partir do SQL Server 2012 [11.x]). Para saber mais, veja Dobra constante para funções e métodos de CLR definidos pelo usuário.
Observação
Há uma exceção para tipos de objeto grandes. Se o tipo de saída do processo de dobragem for um tipo de objeto grande (text,ntext, image, nvarchar(max), varchar(max), varbinary(max), ou XML), então o SQL Server não dobrará a expressão.
Expressões não dobráveis
Todos os outros tipos de expressão são não dobráveis. Especificamente, os tipos seguintes de expressões não são dobráveis:
- Expressões não constantes, cujo resultado depende do valor de uma coluna.
- Expressões cujos resultados dependem de um variável local ou parâmetro, como @x.
- Funções não determinísticas.
- Funções Transact-SQL definidas pelo usuário1.
- Expressões cujos resultados dependem de configurações de idioma.
- Expressões cujos resultados dependem de opções SET.
- Expressões cujos resultados dependem de opções de configuração do servidor.
1 Antes do SQL Server 2012 (11.x), as funções CLR definidas pelo usuário com valor escalar determinístico e métodos de tipos de dado CLR definidos pelo usuário não eram dobráveis.
Exemplos de expressões de constantes dobráveis e não desdobráveis
Considere a consulta a seguir:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Se a opção de banco de dados PARAMETERIZATION não for definida como FORCED para esta consulta, então a expressão 117.00 + 1000.00 será avaliada e substituída por seu resultado, 1117.00, antes que a consulta seja compilada. Os benefícios da dobra constante incluem o seguinte:
- A expressão não precisa ser avaliada repetidamente em tempo de execução.
- O valor da expressão depois de avaliada é usado pelo Otimizador de Consulta para estimar o tamanho do conjunto de resultados da porção da consulta
TotalDue > 117.00 + 1000.00.
Por outro lado, se dbo.f for uma função escalar definida pelo usuário, a expressão dbo.f(100) não será dobrada, porque o SQL Server não dobra expressões que envolvem funções definidas pelo usuário, mesmo quando são determinísticas. Para obter mais informações sobre parametrização, consulte Parametrização forçada mais adiante neste artigo.
Avaliação de expressão
Além disso, algumas expressões que não são constantes desdobráveis, mas cujos argumentos são conhecidos no tempo de compilação, sejam esses argumentos parâmetros ou constantes, são avaliadas pelo avaliador de tamanho do conjunto de resultados (cardinalidade) que é parte do otimizador durante a otimização.
Especificamente, serão avaliados as seguintes funções internas e operadores especiais em tempo de compilação se todas as suas entradas forem conhecidas: UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST e CONVERT. Os seguintes operadores também serão avaliados em tempo de compilação se todas as suas entradas forem conhecidas:
- Operadores aritméticos: +, -, *, /, unary -
- Operadores lógicos:
AND,OR,NOT - Operadores de comparação: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Nenhuma outra função ou operador será avaliada pelo Otimizador de Consulta durante a estimativa de cardinalidade.
Exemplos de avaliação de expressões em tempo de compilação
Considere este procedimento armazenado:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Durante a otimização da instrução SELECT no procedimento, o Otimizador de Consulta tenta avaliar a cardinalidade esperada do conjunto de resultados para a condição OrderDate > @d+1. A expressão @d+1 não é dobrada constantemente, pois @d é um parâmetro. Entretanto, no momento da otimização, o valor do parâmetro é conhecido. Isso permite que o Otimizador de Consulta calcule precisamente o tamanho do conjunto de resultados, o que o ajuda a selecionar um bom plano de consulta.
Agora considere um exemplo semelhante ao anterior, exceto pelo fato de que a variável local @d2 substitui @d+1 na consulta e a expressão é avaliada em uma instrução SET, e não na consulta.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Quando a instrução SELECT em MyProc2 for otimizada no SQL Server, o valor de @d2 não será conhecido. Portanto, o Otimizador de Consulta usa uma estimativa padrão para a seletividade de OrderDate > @d2 (nesse caso, 30 por cento).
Processar outras instruções
As etapas básicas descritas para o processamento de uma instrução SELECT se aplicam a outras instruções Transact-SQL, como INSERT, UPDATE e DELETE. As instruçõesUPDATE e DELETE devem ser direcionadas ao conjunto de linhas a ser modificado ou excluído. O processo de identificação dessas linhas é o mesmo processo usado para identificar as linhas de origem que contribuem para o conjunto de resultados de uma instrução SELECT . Ambas as instruções UPDATE e INSERT podem conter instruções SELECT inseridas que fornecem os valores de dados a serem atualizados ou inseridos.
Até as instruções DDL (linguagem de definição de dados), como CREATE PROCEDURE ou ALTER TABLE, são resolvidas no final para uma série de operações relacionais nas tabelas de catálogo de sistema e, algumas vezes, (como ALTER TABLE ADD COLUMN) nas tabelas de dados.
Tabelas de trabalho
O mecanismo relacional poderá precisar criar uma tabela de trabalho para executar uma operação lógica especificada em uma instrução Transact-SQL. As tabelas de trabalho são tabelas internas usadas para manter resultados intermediários. As tabelas de trabalho são geradas para determinadas consultas GROUP BY, ORDER BYou UNION . Por exemplo, se uma cláusula ORDER BY referenciar a colunas que não são abordadas por nenhum índice, o mecanismo relacional poderá precisar gerar uma tabela de trabalho para classificar o conjunto de resultados na ordem solicitada. Algumas vezes as tabelas de trabalho também são usadas como spools que mantêm temporariamente o resultado da execução de uma parte de um plano de consulta. As tabelas de trabalho são criadas em tempdb e são eliminadas automaticamente quando não são mais necessárias.
Resolução de exibição
O processador de consultas do SQL Server trata as exibições indexadas e não indexadas de forma diferente:
- As linhas de uma exibição indexada são armazenadas no banco de dados no mesmo formato de uma tabela. Se o otimizador de consulta decidir usar uma exibição indexada em um plano de consulta, a exibição indexada será tratada da mesma forma que uma tabela base.
- Somente a definição de uma exibição não indexada é armazenada, e não as linhas da exibição. O Otimizador de Consulta incorpora a lógica da definição de exibição no plano de execução criado para a instrução Transact-SQL que referencia a exibição não indexada.
A lógica usada pelo Otimizador de Consulta do SQL Server para decidir quando usar uma exibição indexada é semelhante à lógica usada para decidir quando usar um índice em uma tabela. Se os dados na exibição indexada abrangerem toda ou parte da instrução Transact-SQL e o Otimizador de Consulta determinar que um índice na exibição é o caminho de acesso de baixo custo, o Otimizador de Consulta escolherá o índice independentemente de a exibição ser referenciada pelo nome na consulta.
Quando uma instrução Transact-SQL referencia uma exibição não indexada, o analisador e o otimizador de consulta analisam a origem da instrução Transact-SQL e a exibição. Depois, as resolvem em um único plano de execução. Não há um plano para a instrução Transact-SQL e um plano separado para a exibição.
Por exemplo, considere a seguinte exibição:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Com base nessa exibição, essas duas instruções Transact-SQL executam as mesmas operações nas tabelas base e produzem os mesmos resultados:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
O recurso Plano de Execução do SQL Server Management Studio mostra que o mecanismo relacional cria o mesmo plano de execução para as duas instruções SELECT .
Usar dicas com exibições
As dicas colocadas em exibições em uma consulta podem entrar em conflito com outras dicas descobertas quando a exibição é expandida para acessar suas tabelas base. Quando isso ocorre, a consulta retorna um erro. Por exemplo, considere a seguinte exibição que contém uma dica de tabela em sua definição:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Agora suponha que você insira esta consulta:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Há uma falha na consulta, porque a dica SERIALIZABLE aplicada na exibição Person.AddrState na consulta é propagada nas tabelas Person.Address e Person.StateProvince na exibição ao ser expandida. No entanto, a expansão da exibição também revela a dica NOLOCK em Person.Address. Como há conflito das dicas SERIALIZABLE e NOLOCK , a consulta resultante está incorreta.
As dicas de tabela PAGLOCK, NOLOCK, ROWLOCK, TABLOCKou TABLOCKX entram em conflito umas com as outras, assim como as dicas de tabela HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREAD, SERIALIZABLE .
As dicas podem ser propagadas pelos níveis de exibições aninhadas. Por exemplo, suponha que uma consulta se aplique à dica HOLDLOCK em uma v1. Quando v1 é expandida, observamos que a exibição v2 faz parte da sua definição. A definição dev2inclui uma dica NOLOCK em uma de suas tabelas base. Mas essa tabela também herda a dica HOLDLOCK da consulta na exibição v1. Como há conflito nas dicas NOLOCK e HOLDLOCK , há falha na consulta.
Quando a dica FORCE ORDER é usada em uma consulta que contém uma exibição, a ordem de junção das tabelas na exibição é determinada pela posição da exibição na construção ordenada. Por exemplo, a seguinte consulta faz a seleção a partir de três tabelas e uma exibição:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
E View1 é definido como mostrado abaixo:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
A ordem de junção no plano de consulta é Table1, Table2, TableA, TableB, Table3.
Resolver índices em exibições
Como com qualquer índice, o SQL Server escolhe usar uma exibição indexada em seu plano de consulta apenas se o Otimizador de Consulta determinar que é benéfico fazê-lo.
Podem ser criadas exibições indexadas em qualquer edição do SQL Server. Em algumas edições de versões mais antigas do SQL Server, o Otimizador de Consulta considera automaticamente a exibição indexada. Em algumas edições de versões mais antigas do SQL Server, para usar uma exibição indexada, a dica de tabela NOEXPAND deve ser usada. Antes do SQL Server 2016 (13.x) Service Pack 1, o uso automático de uma exibição indexada pelo otimizador de consulta era compatível apenas em edições específicas do SQL Server. Desde então, todas as edições oferecem suporte ao uso automático de uma exibição indexada. O Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure também oferecem suporte ao uso automático de exibições indexadas sem especificar a dica NOEXPAND.
O Otimizador de Consulta do SQL Server usa uma exibição indexada quando as seguintes condições são atendidas:
- Estas opções de sessão são definidas como
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- A opção de sessão
NUMERIC_ROUNDABORTestá definida como OFF. - O Otimizador de Consulta encontra uma correspondência entre as colunas de índice de exibição e os elementos na consulta, tais como:
- Predicados de critérios de pesquisa na cláusula WHERE
- Operações de união
- Funções de agregação
- Cláusulas
GROUP BY - Referências de tabela
- O custo estimado do uso do índice é o custo mais baixo de qualquer mecanismo de acesso considerado pelo otimizador de consulta.
- Toda tabela referenciada na consulta (diretamente ou ao expandir uma exibição para acessar suas tabelas subjacentes) que corresponde a uma referência de tabela na exibição indexada deve ter o mesmo conjunto de dicas aplicado na consulta.
Observação
As dicas READCOMMITTED e READCOMMITTEDLOCK sempre são dicas diferentes consideradas nesse contexto, independentemente do nível de isolamento da transação atual.
Diferentemente dos requisitos das opções SET e dicas de tabela, essas são as mesmas regras que o otimizador de consulta usa para determinar se um índice de tabela abrange uma consulta. Não é necessário especificar mais nada na consulta para uma exibição indexada a ser utilizada.
Uma consulta não precisa fazer referência explícita a uma exibição indexada na cláusula FROM para que o Otimizador de Consulta use a exibição indexada. Se a consulta tiver referências a colunas nas tabelas base, que também estão presentes na exibição indexada, e o otimizador de consulta estimar que o uso da exibição indexada fornecerá o menor custo de mecanismo de acesso, o otimizador de consulta escolherá a exibição indexada, semelhante ao modo pelo qual escolhe índices de tabela base quando eles não são referenciados diretamente em uma consulta. O otimizador de consulta pode escolher a exibição quando ela contém colunas que não são referenciadas pela consulta, contanto que a exibição ofereça a opção de menor custo para cobrir uma ou mais das colunas especificadas na consulta.
O otimizador de consulta trata uma exibição indexada referenciada na cláusula FROM como uma exibição padrão. O otimizador de consulta expande a definição da exibição da consulta no início do processo de otimização. Depois, a correspondência da exibição indexada é executada. A exibição indexada pode ser usada no plano de execução final selecionado pelo Otimizador de Consulta ou, em vez disso, o plano pode materializar os dados necessários da exibição acessando as tabelas base referenciadas pela exibição. O Otimizador de Consulta escolhe a alternativa de menor custo.
Usar dicas com exibições indexadas
Você pode evitar que os índices de exibições sejam usados para uma consulta usando a dica de consulta EXPAND VIEWS . Ou, então, pode usar a dica de tabela NOEXPAND para forçar o uso de um índice para uma exibição indexada especificada na cláusula FROM de uma consulta. Porém, deve deixar o otimizador de consulta determinar dinamicamente os melhores métodos de acesso a serem usados para cada consulta. Limite seu uso de EXPAND e NOEXPAND a casos específicos em que os testes têm mostrado que melhoram o desempenho consideravelmente.
A opção
EXPAND VIEWSespecifica que o otimizador de consulta não usa nenhum índice de exibição para a consulta inteira.Quando
NOEXPANDé especificado para uma exibição, o otimizador de consulta considera o uso de qualquer índice definido na exibição. ONOEXPANDespecificado com a cláusulaINDEX()opcional força o otimizador de consulta a usar os índices especificados. ONOEXPANDpode ser especificado apenas para uma exibição indexada e não pode ser especificado para uma exibição não indexada. Antes do SQL Server 2016 (13.x) Service Pack 1, o uso automático de uma exibição indexada pelo otimizador de consulta era compatível apenas em edições específicas do SQL Server. Desde então, todas as edições oferecem suporte ao uso automático de uma exibição indexada. O Banco de Dados SQL do Azure e a Instância Gerenciada de SQL do Azure também oferecem suporte ao uso automático de exibições indexadas sem especificar a dicaNOEXPAND.
Quando NOEXPAND ou EXPAND VIEWS não é especificado em uma consulta que contém uma exibição, a exibição é expandida para acessar as tabelas subjacentes. Se a consulta que compõe a exibição tiver quaisquer dicas de tabela, as dicas serão propagadas às tabelas subjacentes. (Esse processo é explicado com mais detalhes em Resolução de exibição.) Contanto que o conjunto de dicas existente nas tabelas subjacentes da exibição sejam idênticos, a consulta será elegível para ser correspondida a uma exibição indexada. Na maioria das vezes, essas dicas corresponderão umas às outras porque estão sendo diretamente herdadas da exibição. No entanto, se a consulta referenciar tabelas em vez de exibições e as dicas aplicadas diretamente nessas tabelas não forem idênticas, a consulta não será elegível para correspondência com uma exibição indexada. Se as dicas INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK ou XLOCK forem aplicadas às tabelas referenciadas na consulta depois da expansão da exibição, a consulta não será elegível para a correspondência da exibição indexada.
Se uma dica de tabela na forma de INDEX (index_val[ ,...n] ) fizer referência a uma exibição em uma consulta, e você não especificar a dica NOEXPAND, a dica de índice será ignorada. Para especificar o uso de um determinado índice, use NOEXPAND.
Geralmente, quando o Otimizador de Consulta corresponde uma exibição indexada a uma consulta, as dicas especificadas nas tabelas ou exibições da consulta são aplicadas diretamente à exibição indexada. Se o otimizador de consulta optar por não usar uma exibição indexada, qualquer dica será propagada diretamente às tabelas referenciadas na exibição. Para saber mais, veja Resolução de exibição. Essa propagação se aplica a dicas de junção. Elas são aplicadas somente em sua posição original na consulta. As dicas de união não são consideradas pelo otimizador de consulta quando há correspondência entre as consultas e as exibições indexadas. Se um plano de consulta usar uma exibição indexada que corresponda a parte de uma consulta que contém uma dica de junção, esta não será usada no plano.
Não são permitidas dicas nas definições de exibições indexadas. No modo de compatibilidade 80 e superior, o SQL Server ignora as dicas em definições de exibição indexada quando as mantêm, ou ao executar consultas que usam exibições indexadas. Embora o uso de dicas em definições de exibição indexada não produza um erro de sintaxe no modo de compatibilidade 80, elas são ignoradas.
Para obter mais informações, confira Dicas de tabela (Transact-SQL).
Resolver exibições particionadas distribuídas
O processador de consultas do SQL Server otimiza o desempenho das exibições particionadas distribuídas. O aspecto mais importante de desempenho de exibição particionada distribuída é minimizar a quantidade de dados transferida entre servidores membro.
O SQL Server cria planos inteligentes e dinâmicos que usam de forma eficaz as consultas distribuídas para acessar dados de tabelas de membro remoto:
- O Processador de Consultas usa o OLE DB primeiro para recuperar as definições de restrição de verificação de cada tabela de membro. Isso permite ao processador de consultas mapear a distribuição de valores da chave entre as tabelas de membro.
- O Processador de consulta compara os principais intervalos especificados em uma cláusula da instrução Transact-SQL
WHEREcom o mapa que mostra como as linhas são distribuídas nas tabelas de membro. O processador de consultas cria um plano de execução de consulta que usa consultas distribuídas para recuperar apenas essas linhas remotas exigidas para completar a instrução Transact-SQL. O plano de execução também é criado de forma que qualquer acesso a tabelas de membro remoto, tanto para dados quanto para metadados, seja adiado até as informações serem exigidas.
Por exemplo, considere um sistema em que uma tabela Customers é particionada entre Server1 (CustomerID de 1 até 3299999), Server2 (CustomerID de 3300000 até 6599999) e Server3 (CustomerID de 6600000 até 9999999).
Considere o plano de execução criado para esta consulta executada em Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
O plano de execução para esta consulta extrai as linhas com valores da chave CustomerID de 3200000 até 3299999 da tabela de membro local, e emite uma consulta distribuída para recuperar as linhas com valores da chave de 3300000 até 3400000 do Server2.
O Processador de Consultas do SQL Server também pode criar lógica dinâmica em planos de execução de consulta para instruções Transact-SQL em que os valores de chave não são conhecidos quando o plano precisa ser criado. Por exemplo, considere este procedimento armazenado:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
O SQL Server não pode prever qual valor de chave será fornecido pelo parâmetro @CustomerIDParameter sempre que o procedimento for executado. Como o valor de chave não pode ser previsto, o processador de consultas também não pode prever qual tabela de membro precisará ser acessada. Para lidar com isso, o SQL Server cria um plano de execução que tem lógica condicional, conhecido como filtros dinâmicos, para controlar qual tabela de membro será acessada, com base no valor de parâmetro de entrada. Supondo que o procedimento armazenado GetCustomer foi executado no Server1, a lógica do plano de execução poderá ser representada como mostrado a seguir:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
Às vezes, o SQL Server cria esses tipos de planos de execução dinâmicos até para consultas que não são parametrizadas. O Otimizador de Consulta pode parametrizar uma consulta para que o plano de execução possa ser reutilizado. Se o Otimizador de Consulta parametrizar uma consulta que referencia uma exibição particionada, ele já não poderá supor que as linhas exigidas serão provenientes de uma tabela base especificada. Ele terá de usar filtros dinâmicos no plano de execução.
Procedimento armazenado e execução de gatilho
O SQL Server armazena apenas a origem de procedimentos armazenados e disparadores. Quando um procedimento armazenado ou disparador é executado primeiro, a origem é compilada em um plano de execução. Se o procedimento armazenado ou o disparador for executado novamente antes de o plano de execução envelhecer na memória, o mecanismo relacional detectará o plano existente e o reutilizará. Se o plano envelhecer fora da memória, um plano novo será criado. Esse processo é semelhante ao processo que o SQL Server segue para todas as instruções Transact-SQL. A vantagem de desempenho principal que os procedimentos armazenados e os disparadores têm no SQL Server, comparada com lotes de Transact-SQL dinâmico, é que suas instruções Transact-SQL são sempre as mesmas. Portanto, o mecanismo relacional as corresponde facilmente com qualquer plano de execução existente. O planos de procedimento armazenado e disparador são reutilizados facilmente.
O plano de execução de procedimentos armazenados e disparadores é executado separadamente do plano de execução do lote que chama o procedimento armazenado ou aciona o disparador. Isso permite uma grande reutilização de planos de execução de procedimento armazenado e disparador.
Cache e reutilização do plano de execução
O SQL Server tem um pool de memória usado para armazenar planos de execução e buffers de dados. A porcentagem do pool alocada a planos de execução ou buffers de dados flutua dinamicamente, dependendo do estado do sistema. A parte do pool de memória usada para armazenar os planos de execução é conhecida como cache de planos.
O cache de planos tem dois repositórios para todos os planos compilados:
- O OBJCP (repositório de cache de Planos de Objeto) usado para os planos relacionados a objetos persistentes (procedimentos armazenados, funções e gatilhos).
- O SQLCP (repositório de cache de Planos do SQL) usado para os planos relacionados a consultas parametrizadas automaticamente, dinâmicas ou preparadas.
A consulta abaixo fornece informações sobre o uso de memória para esses dois repositórios de cache:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Observação
O cache de planos tem dois repositórios adicionais que não são usados para armazenar planos:
- O repositório de cache de Árvores Associadas (PHDR) usado para as estruturas de dados usadas durante a compilação do plano para exibições, restrições e padrões. Essas estruturas são conhecidas como Árvores Associadas ou Árvores Algebristas.
- O repositório de cache de Procedimentos Armazenados Estendidos (XPROC) usado para procedimentos do sistema predefinidos, como
sp_executeSqlouxp_cmdshell, que são definidos com uma DLL, não com instruções Transact-SQL. A estrutura armazenada em cache contém apenas o nome da função e o nome da DLL na qual o procedimento é implementado.
Os planos de execução do SQL Server têm os componentes principais a seguir:
Plano Compilado (ou plano de consulta)
O plano de consulta produzido pelo processo de compilação é basicamente uma estrutura de dados reentrante somente leitura, usada por qualquer número de usuários. Ele armazena informações sobre:Os operadores físicos que implementam a operação descrita pelos operadores lógicos.
A ordem desses operadores, que determina a ordem na qual os dados são acessados, filtrados e agregados.
O número de linhas estimadas que fluem pelos operadores.
Observação
Nas versões mais recentes do Mecanismo de Banco de Dados, as informações sobre os objetos de estatísticas usados para a Estimativa de Cardinalidade também são armazenadas.
Quais objetos de suporte precisam ser criados, como tabelas de trabalho ou arquivos de trabalho no
tempdb. Nenhuma informação de contexto de usuário ou de runtime é armazenada no plano de consulta. Nunca há mais de uma ou duas cópias do plano de consulta na memória: uma cópia para todas as execuções em série e outra para todas as execuções paralelas. A cópia paralela cobre todas as execuções paralelas, independentemente do grau de paralelismo.
Contexto de execução
Cada usuário que está executando a consulta atualmente tem uma estrutura de dados que retém os dados específicos para a sua execução, como valores de parâmetro. Esta estrutura de dados é conhecida como contexto de execução. As estruturas de dados do contexto de execução são reutilizadas, mas seu conteúdo não. Se outro usuário executar a mesma consulta, as estruturas de dados serão reinicializadas com o contexto para o novo usuário.
Quando qualquer instrução Transact-SQL é executada no SQL Server, primeiro, o Mecanismo de Banco de Dados examina o cache de planos para verificar se há um plano de execução existente para a mesma instrução Transact-SQL. A instrução Transact-SQL será qualificada como existente se ela corresponder a uma instrução Transact-SQL executada anteriormente com um plano armazenado em cache, caractere por caractere. O SQL Server reutiliza qualquer plano existente que encontrar, diminuindo as despesas de recompilação da instrução Transact-SQL. Se não há nenhum plano de execução, o SQL Server gera um novo plano de execução para a consulta.
Observação
Os planos de execução de algumas instruções Transact-SQL não são persistentes no cache de planos, como instruções de operação em massa em execução em rowstore ou instruções que contêm literais de cadeia de caracteres maiores que 8 KB. Esses planos só existem enquanto a consulta está sendo executada.
SQL Server tem um algoritmo eficiente para localizar planos de execução existentes para qualquer instrução Transact-SQL específica. Na maioria dos sistemas, os recursos mínimos usados por esta varredura são inferiores aos recursos salvos graças à reutilização de planos existentes em vez da compilação de cada instrução Transact-SQL.
Os algoritmos para fazer a correspondência das novas instruções Transact-SQL aos planos de execução existentes não usados no cache de planos exigem que todas as referências de objeto sejam totalmente qualificadas. Por exemplo, suponha que Person é o esquema padrão do usuário que executa as instruções SELECT abaixo. Embora neste exemplo não seja necessário que a tabela Person seja totalmente qualificada para execução, isso significa que a segunda instrução não corresponde a um plano existente, mas a terceira corresponde:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
A alteração de uma das seguintes opções SET para determinada execução afetará a capacidade de reutilizar planos, pois o Mecanismo de Banco de Dados executa a dobragem constante, e essas opções afetam os resultados dessas expressões:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Armazenar vários planos em cache para a mesma consulta
As consultas e os planos de execução são exclusivamente identificáveis no Mecanismo de Banco de Dados, de maneira semelhante a uma impressão digital:
- O hash do plano de consulta é um valor de hash binário calculado no plano de execução para determinada consulta e usado para identificar exclusivamente os planos de execução semelhantes.
- O hash de consulta é um valor de hash binário calculado no texto do Transact-SQL de uma consulta e é usado para identificar exclusivamente as consultas.
Um plano compilado pode ser recuperado do cache de planos usando um identificador de plano, que é um identificador transitório que permanece constante apenas enquanto o plano permanece no cache. O identificador do plano é um valor de hash derivado do plano compilado do lote inteiro. O identificador do plano de um plano compilado permanece o mesmo, mesmo se uma ou mais instruções no lote são recompiladas.
Observação
Se um plano foi compilado para um lote em vez de uma só instrução, o plano de instruções individuais no lote pode ser recuperado usando o identificador de plano e os deslocamentos de instrução.
A DMV sys.dm_exec_requests contém as colunas statement_start_offset e statement_end_offset para cada registro, que se referem à instrução atualmente em execução de um lote ou um objeto persistente em execução no momento. Para obter mais informações, confira sys.dm_exec_requests (Transact-SQL).
A DMV sys.dm_exec_query_stats também contém essas colunas para cada registro, que se referem à posição de uma instrução em um lote ou um objeto persistente. Para obter mais informações, confira sys.dm_exec_query_stats (Transact-SQL).
O texto real do Transact-SQL de um lote é armazenado em um espaço de memória separado do cache de planos, chamado o cache do SQLMGR (SQL Manager). O texto do Transact-SQL de um plano compilado pode ser recuperado do cache do SQL Manager com um Identificador SQL, que é um identificador transitório que permanece constante apenas enquanto, pelo menos, um plano que o referencie permanece no cache de planos. O identificador SQL é um valor de hash derivado do texto do lote inteiro e tem a garantia de ser exclusivo em cada lote.
Observação
Como um plano compilado, o texto do Transact-SQL é armazenado por lote, incluindo os comentários. O identificador SQL contém o hash MD5 do texto do lote inteiro e tem a garantia de ser exclusivo em cada lote.
A consulta abaixo fornece informações sobre o uso de memória para o cache do SQL Manager:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Há uma relação 1:N entre um identificador SQL e os identificadores de plano. Essa condição ocorre quando a chave de cache dos planos compilados é diferente. Isso pode ocorrer devido a uma alteração nas opções SET entre duas execuções do mesmo lote.
Considere o seguinte procedimento armazenado:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Verifique o que pode ser encontrado no cache de planos usando a consulta abaixo:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Este é o conjunto de resultados.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Agora execute o procedimento armazenado com outro parâmetro, mas nenhuma outra alteração no contexto de execução:
EXEC usp_SalesByCustomer 8
GO
Verifique novamente o que pode ser encontrado no cache de planos. Este é o conjunto de resultados.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Observe que as usecounts aumentaram para 2, o que significa que o mesmo plano armazenado em cache foi reutilizado no estado em que se encontra, pois as estruturas de dados do contexto de execução foram reutilizadas. Agora altere a opção SET ANSI_DEFAULTS e execute o procedimento armazenado usando o mesmo parâmetro.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Verifique novamente o que pode ser encontrado no cache de planos. Este é o conjunto de resultados.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Observe que agora há duas entradas na saída da DMV sys.dm_exec_cached_plans:
- A coluna
usecountsmostra o valor1no primeiro registro, que é o plano executado uma vez comSET ANSI_DEFAULTS OFF. - A coluna
usecountsmostra o valor2no segundo registro, que é o plano executado comSET ANSI_DEFAULTS ON, pois foi executado duas vezes. - Os
memory_object_addressdiferentes referem-se a uma entrada diferente de plano de execução no cache de planos. No entanto, o valor desql_handleé o mesmo para as duas entradas, porque elas se referem ao mesmo lote.- A execução com
ANSI_DEFAULTSdefinido como OFF tem um novoplan_handlee está disponível para reutilização em chamadas que tenham o mesmo conjunto de opções SET. O novo identificador de plano é necessário porque o contexto de execução foi reinicializado devido a opções SET alteradas. Mas isso não dispara uma recompilação: ambas as entradas se referem ao mesmo plano e à mesma consulta, conforme evidenciado pelos mesmos valores dequery_plan_hashequery_hash.
- A execução com
O que isso significa efetivamente é que temos duas entradas de plano no cache correspondentes ao mesmo lote e ela destaca a importância de garantir que o cache de planos que afeta as opções SET seja o mesmo quando as mesmas consultas são executadas repetidamente, a fim de otimizar a reutilização do plano e manter o tamanho mínimo necessário do cache de planos.
Dica
Uma armadilha comum é que diferentes clientes podem ter valores padrão diferentes para as opções SET. Por exemplo, uma conexão feita por meio do SQL Server Management Studio automaticamente define QUOTED_IDENTIFIER como ON, enquanto o SQLCMD define QUOTED_IDENTIFIER como OFF. A execução das mesmas consultas nesses dois clientes resultará em vários planos (conforme descrito no exemplo acima).
Remover planos de execução do cache de planos
Os planos de execução permanecem no cache de planos enquanto houver memória suficiente para armazená-los. Quando há demanda de memória, o Mecanismo de Banco de Dados do SQL Server usa uma abordagem baseada em custo para determinar quais planos de execução remover do cache de planos. Para tomar uma decisão baseada em custo, o Mecanismo de Banco de Dados do SQL Server aumenta e reduz uma variável de custo atual para cada plano de execução de acordo com os fatores a seguir.
Quando um processo de usuário insere um plano de execução no cache, esse processo de usuário define o custo atual igual ao custo de compilação da consulta original. Para planos de execução ad hoc, o processo de usuário define o custo atual como zero. Depois disso, cada vez que um processo de usuário faz referência a um plano de execução, ele restaura o custo atual como igual ao custo de compilação original. Para planos de execução ad hoc, o processo de usuário aumenta o custo atual. Para todos os planos, o valor máximo do custo atual é o custo de compilação original.
Quando há demanda de memória, o Mecanismo de Banco de Dados do SQL Server responde removendo planos de execução do cache de planos. Para determinar quais planos remover, o Mecanismo de Banco de Dados do SQL Server examina repetidamente o estado de cada plano de execução e remove planos quando o custo atual for igual a zero. Um plano de execução com custo atual igual a zero não é removido automaticamente quando há demanda de memória. Ele é removido apenas quando o Mecanismo de Banco de Dados do SQL Server examinar o plano, e o custo atual for igual a zero. Ao examinar um plano de execução, o Mecanismo de Banco de Dados do SQL Server impulsiona o custo atual em direção a zero ao reduzir o custo atual se uma consulta não estiver usando o plano no momento.
O Mecanismo de Banco de Dados do SQL Server examina repetidamente os planos de execução até que o suficiente tenha sido removido para atender aos requisitos de memória. Embora haja pressão de memória, o custo de um plano de execução pode ser aumentado e reduzido mais de uma vez. Quando não houver mais demanda de memória, o Mecanismo de Banco de Dados do SQL Server vai parar de reduzir o custo atual de planos de execução não utilizados e todos os planos de execução permanecerão no cache de planos, mesmo que seu custo seja igual a zero.
O Mecanismo de Banco de Dados do SQL Server usa o monitor de recursos e os threads de trabalho do usuário para liberar memória do cache de planos em resposta à demanda de memória. O monitor de recursos e os threads de trabalho do usuário podem examinar planos em execução simultânea para diminuir o custo de cada plano de execução não utilizado. O monitor de recursos remove planos de execução do cache de planos quando há pressão de memória global. Ele libera memória para aplicar políticas para a memória do sistema, a memória do processo, a memória do pool de recursos e o tamanho máximo de todos os caches.
O tamanho máximo de todos os caches é uma função do tamanho do pool de buffers que não pode exceder a memória máxima do servidor. Para saber mais sobre como configurar a memória máxima do servidor, veja a definição de max server memory em sp_configure.
Os threads de trabalho do usuário removem planos de execução do cache de planos quando há pressão de memória de cache único. Eles aplicam políticas de tamanho máximo de cache único e do número máximo de entradas do cache único.
Os exemplos a seguir ilustram quais planos de execução são removidos do cache de planos:
- Um plano de execução é referenciado frequentemente para que seu custo nunca seja zerado. O plano permanece no cache de planos e não é removido a menos que haja demanda de memória e o custo atual seja zero.
- Um plano de execução ad hoc é inserido e não é referenciado novamente até que haja demanda de memória. Como os planos ad hoc são inicializados com um custo atual igual a zero, quando o Mecanismo de Banco de Dados do SQL Server examina o plano de execução, ele vê o custo atual igual a zero e remove o plano do cache de planos. O plano de execução ad hoc permanece no cache de planos com um custo atual igual a zero quando não há demanda de memória.
Para remover manualmente um único plano ou todos os planos do cache, use DBCC FREEPROCCACHE. DBCC FREESYSTEMCACHE também pode ser usado para limpar qualquer cache, incluindo o cache de planos. A partir do SQL Server 2016 (13.x), o ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE para limpar o cache (plano) de procedimento para o banco de dados no escopo.
Uma alteração em algumas definições de configuração por meio de sp_configure e reconfigure também fará com que os planos sejam removidos do cache de planos. Encontre a lista dessas definições de configuração na seção Comentários do artigo DBCC FREEPROCCACHE. Uma alteração de configuração como essa registrará a seguinte mensagem informativa no log de erros:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Recompilar planos de execução
Certas alterações em um banco de dados podem fazer com que a execução de um plano seja ineficaz ou inválida, com base no novo estado do banco de dados. O SQL Server detecta as alterações que invalidam um plano de execução e marca o plano como inválido. Um plano novo deve ser recompilado para a próxima conexão que executar a consulta. As condições que invalidam um plano incluem o seguinte:
- Alterações feitas em uma tabela ou exibição referenciadas pela consulta (
ALTER TABLEeALTER VIEW). - As alterações feitas em um único procedimento, o que descartaria todos os planos para esse procedimento do cache (
ALTER PROCEDURE). - Alterações em quaisquer índices usadas pelo plano de execução.
- Atualizações em estatísticas usadas pelo plano de execução, geradas explicitamente de uma instrução, como
UPDATE STATISTICSou geradas automaticamente. - Cancelando um índice usado pelo plano de execução.
- Uma chamada explícita para
sp_recompile. - Números grandes de alterações para chaves (gerados por instruções
INSERTouDELETEde outros usuários que modificam a tabela referenciada pela consulta). - Para tabelas com disparadores, se o número de linhas nas tabelas inseridas ou excluídas aumentar consideravelmente.
- Executar um procedimento armazenado usando a opção
WITH RECOMPILE.
A maioria das recompilações é necessária para exatidão da instrução ou para obter planos de execução de consulta potencialmente mais rápidos.
Em versões do SQL Server anteriores à 2005, sempre que uma instrução em um lote causava a recompilação, todo o lote, fosse enviado por meio de um procedimento armazenado, gatilho, lote ad hoc ou instrução preparada, era recompilado. A partir do SQL Server 2005 (9.x), apenas a instrução dentro do lote que aciona a recompilação é recompilada. Além disso, há tipos adicionais de recompilações no SQL Server 2005 (9.x) e versões posteriores devido ao seu conjunto de recursos expandido.
A recompilação em nível de instrução beneficia o desempenho porque, na maioria dos casos, um número pequeno de instruções provoca recompilações e as penalidades associadas, em termos de bloqueios e tempo de CPU. Portanto, essas penalidades são evitadas nas outras instruções do lote que não precisam ser recompiladas.
O evento estendido do sql_statement_recompile (xEvent) relata recompilações no nível da instrução. Esse xEvent ocorre quando uma recompilação no nível de instrução é exigida por qualquer tipo de lote. Isso inclui procedimentos armazenados, disparadores, lotes ad hoc e consultas. Os lotes podem ser enviados por meio de diversas interfaces, incluindo sp_executesql, SQL dinâmico e os métodos Prepare ou Execute.
A coluna recompile_cause do xEvent sql_statement_recompile contém um código de inteiro que indica o motivo da recompilação. A tabela a seguir contém os possíveis motivos:
Esquema alterado
Estatísticas alteradas
Compilação adiada
Alteração da opção SET
Alteração da tabela temporária
Conjunto de linhas remoto alterado
Alteração da permissão FOR BROWSE
Ambiente de notificação de consulta alterado
Alteração da exibição particionada
Opções de cursor alteradas
OPTION (RECOMPILE) solicitado
Liberação do plano parametrizado
Alteração do plano que afeta a versão do banco de dados
Alteração da política de imposição do plano do Repositório de Consultas
Falha da imposição do plano do Repositório de Consultas
Plano do Repositório de Consultas ausente
Observação
Em versões do SQL Server em que o xEvents não está disponível, o evento de rastreamento SQL Server Profiler SP:Recompile pode ser usado para a mesma finalidade do relatório de recompilações no nível de instrução.
O evento de rastreamento SQL:StmtRecompile também relata recompilações no nível de instrução e pode ser usado para acompanhar e depurar recompilações.
Enquanto SP:Recompile gera apenas para procedimentos armazenados e acionadores, SQL:StmtRecompile gera para procedimentos armazenados, acionadores, lotes ad hoc, lotes que são executados usando sp_executesql, consultas preparadas e SQL dinâmico.
A coluna EventSubClass de SP:Recompile e SQL:StmtRecompile contém um código inteiro que indica o motivo da recompilação. Os códigos descritos aqui.
Observação
Quando a opção do banco de dados AUTO_UPDATE_STATISTICS for definida como ON, as consultas serão recompiladas quando destinadas a tabelas ou exibições indexadas cujas estatísticas foram atualizadas ou cujas cardinalidades foram alteradas significativamente desde a última execução.
Esse comportamento se aplica a tabelas padrão definidas pelo usuário, tabelas temporárias e tabelas inseridas e excluídas criadas por disparadores de DML. Se o desempenho de consulta for afetado por recompilações excessivas, considere a alteração dessa configuração para OFF. Quando a opção do banco de dados AUTO_UPDATE_STATISTICS for definida como OFF, não ocorrerá nenhuma recompilação com base em estatísticas ou alterações de cardinalidade, com exceção das tabelas inseridas e excluídas criadas por disparadores de DML INSTEAD OF. Como essas tabelas são criadas em tempdb, a recompilação de consultas que as acessam depende da configuração de AUTO_UPDATE_STATISTICS em tempdb.
No SQL Server anterior a 2005, as consultas continuam a ser recompiladas com base nas alterações de cardinalidade nas tabelas inseridas e excluídas do gatilho DML, mesmo quando essa configuração é OFF.
Reutilização de parâmetros e plano de execução
O uso de parâmetros, inclusive de marcadores de parâmetro em aplicativos ADO, OLE DB e ODBC, pode aumentar a reutilização de planos de execução.
Aviso
O uso de parâmetros ou marcadores de parâmetro para manter valores digitados pelo usuário final é mais seguro que a concatenação dos valores em uma cadeia de caracteres executada posteriormente usando um método API de acesso a dados, a instrução EXECUTE ou o procedimento armazenado sp_executesql .
A única diferença entre as duas instruções SELECT a seguir são os valores comparados na cláusula WHERE :
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
A única diferença entre os planos de execução dessas consultas é o valor armazenado para a comparação com a coluna ProductSubcategoryID . Embora o objetivo seja que o SQL Server sempre reconheça que as instruções geram essencialmente o mesmo plano e reutilize os planos, às vezes o SQL Server não detecta isso em instruções Transact-SQL complexas.
A separação de constantes da instrução Transact-SQL usando parâmetros ajuda o mecanismo relacional a reconhecer planos duplicados. Você pode usar parâmetros dos seguintes modos:
No Transact-SQL, use
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmEsse método é recomendado para scripts de Transact-SQL, procedimentos armazenados ou gatilhos que geram instruções SQL dinamicamente.
ADO, OLE DB e ODBC usam marcadores de parâmetro. Marcadores de parâmetro são marcas de interrogação (?) que substituem uma constante em uma instrução SQL e são associados a uma variável de programa. Por exemplo, você faria o seguinte em um aplicativo de ODBC:
Use o
SQLBindParameterpara associar uma variável de inteiro ao primeiro marcador de parâmetro em uma instrução SQL.Coloque o valor inteiro na variável.
Execute a instrução, especificando o marcador de parâmetro (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
O SQL Server Native Client OLE DB Provider e o driver SQL Server Native Client ODBC incluídos com o SQL Server usam
sp_executesqlpara enviar instruções ao SQL Server quando os marcadores de parâmetro são usados em aplicativos.Para criar procedimentos armazenados que usam parâmetros por design.
Se você não criar parâmetros explicitamente no design de seus aplicativos, também poderá contar com o Otimizador de Consulta do SQL Server para parametrizar automaticamente determinadas consultas usando o comportamento padrão de parametrização simples. Outra opção é forçar o Otimizador de Consulta a considerar a parametrização de todas as consultas no banco de dados, configuração a opção PARAMETERIZATION da instrução ALTER DATABASE como FORCED.
Quando a parametrização forçada estiver habilitada, a parametrização simples ainda poderá acontecer. Por exemplo, a consulta a seguir não pode ser parametrizada de acordo com as regras de parametrização forçada:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Porém, ela pode ser parametrizada de acordo com as regras de parametrização simples. Quando se tenta usar a parametrização forçada, mas ela falha, há uma tentativa subsequente de parametrização simples.
Parametrização simples
No SQL Server, o uso de parâmetros ou marcadores de parâmetro em instruções Transact-SQL aumenta a capacidade do mecanismo relacional de corresponder novas instruções Transact-SQL com planos de execução existentes compilados anteriormente.
Aviso
O uso de parâmetros ou marcadores de parâmetro para manter valores digitados pelo usuário final é mais seguro que a concatenação dos valores em uma cadeia de caracteres executada posteriormente usando um método API de acesso a dados, a instrução EXECUTE ou o procedimento armazenado sp_executesql .
Se uma instrução Transact-SQL for executada sem parâmetros, o SQL Server parametrizará a instrução internamente para aumentar a possibilidade de correspondência com um plano de execução existente. Esse processo é chamado de parametrização simples. Em versões do SQL Server anteriores a 2005, o processo era conhecido como parametrização automática.
Considere esta instrução:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
O valor 1 ao final da instrução pode ser especificado como um parâmetro. O mecanismo relacional cria o plano de execução para este lote como se um parâmetro tivesse sido especificado no lugar do valor 1. Devido a essa parametrização simples, o SQL Server reconhece que as duas instruções a seguir geram essencialmente o mesmo plano de execução e reutilizam o primeiro plano para a segunda instrução:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Ao processar instruções Transact-SQL complexas, o mecanismo relacional pode ter dificuldade em determinar quais expressões podem ser parametrizadas. Para aumentar a capacidade do mecanismo relacional de corresponder instruções Transact-SQL complexas a planos de execução existentes e não utilizados, especifique explicitamente os parâmetros usando marcadores sp_executesql ou de parâmetro.
Observação
Quando os operadores aritméticos +, -, *, / ou % são usados para executar conversão implícita ou explícita de valores constantes int, smallint, tinyint ou bigint para os tipos de dados float, real, decimal ou numérico, o SQL Server aplica regras específicas para calcular o tipo e a precisão dos resultados da expressão. Porém, essas regras diferem, dependendo se a consulta for parametrizada ou não. Portanto, as expressões semelhantes em consultas podem, em alguns casos, produzir resultados diferentes.
No comportamento padrão de parametrização simples, o SQL Server parametriza uma classe relativamente pequena de consultas. No entanto, você pode especificar que todas as consultas de um banco de dados sejam parametrizadas, sujeitas a determinadas limitações, configurando a opção PARAMETERIZATION do comando ALTER DATABASE para FORCED. Isso pode melhorar o desempenho dos bancos de dados que suportam grandes volumes de consultas simultâneas, reduzindo a frequência de compilações de consultas.
Alternativamente, você pode especificar que, uma consulta única e quaisquer outras que sejam sintaticamente equivalentes e apenas diferem nos valores de parâmetro, sejam parametrizadas.
Dica
Ao usar uma solução de ORM (mapeamento de objeto relacional), como EF (Entity Framework), as consultas de aplicativo como árvores manuais de consulta do LINQ ou determinadas consultas brutas de SQL podem não ser parametrizadas, o que afeta o reuso do plano e a capacidade de controlar consultas no Repositório de Consultas. Para saber mais, confira Parametrização e cache de consultas do EF e Consultas de SQL bruto do EF.
Parametrização forçada
É possível substituir o comportamento padrão da parametrização simples do SQL Server especificando que todas as instruções SELECT, INSERT, UPDATEe DELETE em um banco de dados tenham parâmetros e sejam sujeitas a determinadas limitações. A parametrização forçada é habilitada pela configuração da opção PARAMETERIZATION como FORCED na instrução ALTER DATABASE . A parametrização forçada pode melhorar o desempenho de alguns bancos de dados reduzindo a frequência de compilações e recompilações de consulta. Os bancos de dados que podem se beneficiar da parametrização forçada geralmente são aqueles em que há suporte a grandes volumes de consultas simultâneas de origens tais como aplicativos de ponto-de-venda.
Quando a opção PARAMETERIZATION é definida como FORCED, qualquer valor literal exibido em uma instrução SELECT, INSERT, UPDATEou DELETE , enviado de qualquer forma, é convertido em um parâmetro durante a compilação de consulta. As exceções são literais exibidos nas seguintes construções de consulta:
- Instruções
INSERT...EXECUTE. - Instruções nos corpos de procedimentos armazenados, gatilhos ou funções definidas pelo usuário. O SQL Server já reutiliza os planos de consulta para essas rotinas.
- Instruções preparadas que já foram parametrizadas no aplicativo cliente.
- Instruções que contêm chamadas do método XQuery, onde o método é exibido em um contexto em que seus argumentos normalmente seriam parametrizados, como uma cláusula
WHERE. Se o método for exibido em um contexto em que seus argumentos não serão parametrizados, o restante da instrução será parametrizado. - Instruções dentro de um cursor do Transact-SQL. (As instruções
SELECTsão parametrizadas em cursores de API.) - Construções da consulta preterida.
- Qualquer instrução executada no contexto de
ANSI_PADDINGouANSI_NULLSdefinida comoOFF. - Instruções que contêm mais de 2.097 literais elegíveis para parametrização.
- Instruções que fazem referência a variáveis, como
WHERE T.col2 >= @bb. - Instruções que contêm a dica de consulta
RECOMPILE. - Instruções que contêm uma cláusula
COMPUTE. - Instruções que contêm uma cláusula
WHERE CURRENT OF.
Além disso, as cláusulas de consulta a seguir não são parametrizadas. Nesses casos, somente as cláusulas não são parametrizadas. Outras cláusulas dentro da mesma consulta podem ser elegíveis para parametrização forçada.
- A <select_list> de qualquer instrução
SELECT. Isso inclui as listasSELECTde subconsultas e listasSELECTdentro de instruçõesINSERT. - Instruções
SELECTde subconsulta exibidas dentro de uma instruçãoIF. - As cláusulas
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOouFOR XMLde uma consulta. - Argumentos, diretos ou como subexpressões, para
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLou qualquer operadorFULLTEXT. - Os argumentos pattern e escape_character de uma cláusula
LIKE. - O argumento style de uma cláusula
CONVERT. - As constantes de número inteiro dentro de uma cláusula
IDENTITY. - Constantes especificadas usando a sintaxe da extensão ODBC.
- Expressões de constantes desdobráveis que são argumentos dos operadores
+,-,*,/e%. Ao considerar a elegibilidade para parametrização forçada, o SQL Server considera uma expressão como dobrável constante quando uma das seguintes condições for verdadeira:- Nenhuma coluna, variável ou subconsulta é exibida na expressão.
- A expressão contém uma cláusula
CASE.
- Argumentos para cláusulas de dica de consulta. Incluem o argumento number_of_rows da dica de consulta
FAST, o argumento number_of_processors da dica de consultaMAXDOPe o argumento number da dica de consultaMAXRECURSION.
A parametrização ocorre no nível das instruções Transact-SQL individuais. Em outras palavras, são parametrizadas instruções individuais em lote. Após a compilação, uma consulta parametrizada é executada no contexto do lote em que foi enviado originalmente. Se um plano de execução de uma consulta for armazenado em cache, você poderá determinar se a consulta foi parametrizada referenciando a coluna sql da exibição de gerenciamento dinâmico sys.syscacheobjects. Se uma consulta for parametrizada, os nomes e tipos de dados de parâmetros serão exibidos antes do texto do lote enviado nessa coluna, como (@1 tinyint).
Observação
Os nomes de parâmetro são arbitrários. Os usuários ou os aplicativos não devem confiar em uma ordem de nomenclatura específica. Além disso, os seguintes itens podem ser alterados entre as versões do SQL Server e as atualizações do Service Pack: nomes de parâmetros, a escolha de literais parametrizados e o espaçamento no texto parametrizado.
Tipos de dados de parâmetros
Quando o SQL Server parametriza literais, os parâmetros são convertidos nos seguintes tipos de dados:
- Literais inteiros cujo tamanho pode ser ajustado no tipo de dados int parametrizados como int. Literais inteiros grandes que fazem parte de predicados que envolvem um operador de comparação (incluindo
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENeIN) são parametrizados como numeric(38,0). Os literais grandes que não fazem parte de predicados que envolvem operadores de comparação parametrizados em numeric, cuja precisão é grande o suficiente para oferecer suporte ao seu tamanho e cuja escala é 0. - Literais numéricos de ponto fixo que não fazem parte de predicados que envolvem operadores de comparação parametrizados em numeric, cuja precisão é 38 e cuja escala é grande o suficiente para oferecer suporte ao seu tamanho. Literais numéricos de ponto fixo que não fazem parte de predicados que envolvem operadores de comparação parametrizados em numeric, cuja precisão e escala são grandes o suficiente para oferecer suporte ao seu tamanho.
- Literais numéricos de ponto de flutuação parametrizados em float(53).
- Literais de cadeia de caracteres não Unicode parametrizados em varchar(8000), caso o literal caiba em 8000 caracteres, e em varchar(max), se ele for maior do que 8000 caracteres.
- Literais de cadeia de caracteres Unicode parametrizados em nvarchar(4000), caso o literal caiba em 4000 caracteres, e em nvarchar(max), se ele for maior do que 4000 caracteres.
- Literais binários parametrizados em varbinary(8000), caso o literal caiba em 8000 bytes. Se for maior do que 8000 bytes, será convertido em varbinary(max).
- Literais de moeda parametrizados em money.
Diretrizes para uso da parametrização forçada
Considere as seguintes diretrizes ao definir a opção PARAMETERIZATION como FORCED:
- A parametrização forçada altera as constantes literais em uma consulta para parâmetros ao compilar uma consulta. Portanto, o otimizador de consulta poderia escolher planos com qualidade inferior para consultas. Em particular, é menos provável que o otimizador de consulta efetue uma correspondência entre uma consulta uma exibição indexada ou um índice em uma coluna computada. Além disso, ele pode escolher planos com qualidade inferior para consultas inseridas em tabelas particionadas e exibições particionadas distribuídas. A parametrização forçada não deve ser usada em ambientes que dependem excessivamente de exibições indexadas e índices em colunas computadas. Via de regra, a opção
PARAMETERIZATION FORCEDsó deve ser usada por administradores de banco de dados experientes depois de determinarem que isso não afeta o desempenho de forma negativa. - As consultas distribuídas que referenciam mais de um banco de dados são elegíveis para parametrização forçada, contanto que a opção
PARAMETERIZATIONseja definida comoFORCEDno banco de dados cujo contexto está sendo executado pela consulta. - A definição da opção
PARAMETERIZATIONcomoFORCEDlibera todos os planos de consulta do cache de plano de um banco de dados, menos os que estão sendo compilados, recompilados ou em execução. Os planos de consultas que estiverem sendo compilados ou em execução durante a mudança de configuração serão parametrizados da próxima vez que a consulta for executada. - A definição da opção
PARAMETERIZATIONé uma operação online que não exige nenhum bloqueio exclusivo no nível de banco de dados. - A configuração atual da opção
PARAMETERIZATIONé preservada ao anexar novamente ou restaurar um banco de dados.
É possível substituir o comportamento da parametrização forçada especificando a tentativa da parametrização simples em uma única consulta, e em quaisquer outras que sejam sintaticamente equivalentes, mas diferem apenas nos valores de parâmetro. Reciprocamente, pode-se especificar a tentativa da parametrização forçada em apenas um conjunto de consultas sintaticamente equivalentes, mesmo se a parametrização forçada estiver desabilitada no banco de dados. Guias de plano são usados para essa finalidade.
Observação
Quando a opção PARAMETERIZATION é definida como FORCED, o relatório de mensagens de erro pode ser diferente de quando a opção PARAMETERIZATION está configurada para SIMPLE: podem ser relatadas várias mensagens de erro na parametrização forçada, em que poucas mensagens seriam informadas na parametrização simples, e o número de linhas nas quais ocorrem erros pode ser relatado incorretamente.
Preparar instruções SQL
O mecanismo relacional SQL Server apresenta suporte completo na preparação de instruções Transact-SQL antes de elas serem executadas. Se um aplicativo tiver que executar uma instrução Transact-SQL várias vezes, poderá usar a API do banco de dados para fazer o seguinte:
- Preparar a instrução uma vez. Esse procedimento compila a instrução Transact-SQL em um plano de execução.
- Executar o plano de execução pré-compilado sempre que tiver de executar a instrução. Isso evita a necessidade de recompilar a instrução Transact-SQL em cada execução depois da primeira vez. A preparação e a execução de instruções são controladas por funções e métodos de API. Isso não faz parte da linguagem Transact-SQL. O modelo de preparação/execução para executar instruções Transact-SQL é compatível com o SQL Server Native Client OLE DB Provider e o driver SQL Server Native Client ODBC. Em uma solicitação de preparação, o provedor ou o driver envia a instrução ao SQL Server com uma solicitação para preparar a instrução. O SQL Server compila um plano de execução e retorna um identificador desse plano para o provedor ou driver. Em uma solicitação de execução, o provedor ou o driver envia ao servidor uma solicitação para executar o plano associado ao identificador.
As instruções preparadas não podem ser usadas para criar objetos temporários no SQL Server. As instruções preparadas não podem fazer referência aos procedimentos armazenados do sistema que criam objetos temporários, como tabelas temporárias. Esses procedimentos devem ser executados diretamente.
O uso excessivo do modelo de preparação/execução pode diminuir o desempenho. Se uma instrução for executada apenas uma vez, uma execução direta exigirá apenas uma viagem de ida e volta da rede para o servidor. A preparação e a execução de uma instrução Transact-SQL executadas apenas uma vez exigem uma viagem de ida e volta adicional da rede; uma viagem para preparar a instrução e uma viagem para executá-la.
A preparação de uma instrução é mais eficaz se forem utilizados marcadores de parâmetro. Por exemplo, supondo que a um aplicativo seja pedido ocasionalmente a recuperação de informações de produto do banco de dados de exemplo AdventureWorks . Há dois modos para o aplicativo fazer isso.
Usando o primeiro modo, o aplicativo pode executar uma consulta separada para cada produto solicitado:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Usando o segundo modo, o aplicativo faz o seguinte:
Prepara uma instrução contendo um marcador de parâmetro (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Associa uma variável de programa ao marcador de parâmetro.
Sempre que as informações de produto são necessárias, preenche a variável de associação com o valor da chave e executa a instrução.
O segundo modo é mais eficiente quando a instrução é executada mais de três vezes.
No SQL Server, o modelo de preparação/execução não tem uma vantagem de desempenho considerável sobre a execução direta, devido ao modo como o SQL Server reutiliza os planos de execução. O SQL Server tem algoritmos eficientes para corresponder as instruções Transact-SQL atuais aos planos de execução, que são gerados para execuções anteriores da mesma instrução Transact-SQL. Se um aplicativo executar uma instrução Transact-SQL com marcadores de parâmetro várias vezes, o SQL Server reutilizará o plano de execução da primeira execução para a segunda e as execuções subsequentes (a menos que o plano fique mais antigo que o cache de planos). O modelo de preparação/execução ainda possui estes benefícios:
- A localização de um plano de execução por um identificador é mais eficiente que os algoritmos usados para corresponder uma instrução Transact-SQL aos planos de execução existentes.
- O aplicativo pode controlar quando o plano de execução é criado e quando é reutilizado.
- O modelo de preparação/execução é portátil para outros bancos de dados, inclusive para versões anteriores do SQL Server.
Sensibilidade de parâmetros
A sensibilidade de parâmetros, também conhecida como "detecção de parâmetros", refere-se a um processo pelo qual o SQL Server "detecta" os valores atuais dos parâmetros durante a compilação ou recompilação e os transmite ao Otimizador de Consulta para que possam ser usados para gerar planos de execução de consultas potencialmente mais eficientes.
Valores de parâmetro são detectados durante a compilação ou recompilação para os seguintes tipos de lotes:
- Procedimentos armazenados
- Consultas enviadas por meio de
sp_executesql - Consultas preparadas
Para obter mais informações sobre como solucionar problemas de detecção de parâmetros incorretos, consulte:
- Investigue e resolva problemas de sensibilidade de parâmetros
- Reutilização de Parâmetros e Plano de Execução
- Otimização do plano sensível de parâmetro
- Solucionar problemas de consultas com problemas de plano de execução de consulta sensível a parâmetros no Banco de Dados SQL do Azure
- Solucionar problemas de consultas com problemas de plano de execução de consulta sensível a parâmetros na Instância Gerenciada de SQL do Azure
Observação
Para consultas que utilizam a dica RECOMPILE, tanto os valores de parâmetros quanto os valores atuais das variáveis locais são detectados. Os valores detectados (de parâmetros e de variáveis locais) são aqueles que existem no local no lote antes da instrução com a dica RECOMPILE. Especificamente para parâmetros, os valores que acompanha a chamada de invocação de lote não são detectados.
Processamento paralelo de consultas
O SQL Server fornece consultas paralelas para otimizar a execução de consultas e operações de índice para computadores que têm mais de um microprocessador (CPU). Como o SQL Server pode executar uma consulta ou operação de índice em paralelo usando vários threads de trabalho do sistema operacional, a operação pode ser concluída de forma rápida e eficiente.
Durante a otimização da consulta, o SQL Server procura consultas ou operações de índice que poderiam se beneficiar da execução paralela. Para essas consultas, o SQL Server insere operadores de troca no plano de execução de consulta para preparar a consulta para a execução paralela. Um operador de troca é um operador em um plano de execução de consulta que fornece gerenciamento de processo, redistribuição de dados e controle de fluxo. O operador de troca inclui como subtipos os operadores lógicos Distribute Streams, Repartition Streamse Gather Streams dos quais um ou mais podem aparecer na saída do Plano de Execução de um plano de consulta para uma consulta paralela.
Importante
Certos constructos inibem a capacidade do SQL Server de usar paralelismo em todo o plano de execução, ou em partes ou no plano de execução.
Os constructos que inibem o paralelismo incluem:
UDFs escalares
Para obter mais informações sobre funções escalares definidas pelo usuário, confira Create User-defined Functions (Criar funções definidas pelo usuário). A partir do SQL Server 2019 (15.x), o Mecanismo de Banco de Dados do SQL Server tem a capacidade de incorporar essas funções e desbloquear o uso do paralelismo durante o processamento de consultas. Para obter mais informações sobre o inlining do UDF escalar, confira Processamento inteligente de consultas em bancos de dados SQL.Consulta remota
Para obter mais informações sobre Consulta Remota, confira Referência de operadores lógicos e físicos de plano de execução.Cursores dinâmicos
Para saber mais sobre cursores, confira DECLARE CURSOR.Consultas recursivas
Para saber mais sobre recursão, confira Guidelines for Defining and Using Recursive Common Table Expressions (Diretrizes para definir e usar Expressões de Tabela Comum Recursivas) e Recursion in T-SQL (Recursão em T-SQL).MSTVFs (Funções com valor de tabela de várias instruções)
Para obter mais informações sobre MSTVFs, confira Criar funções definidas pelo usuário (Mecanismo de Banco de Dados).Palavra-chave TOP
Para saber mais, confira TOP (Transact-SQL).
Um plano de execução de consulta pode conter o atributo NonParallelPlanReason no elemento QueryPlan, que descreve por que o paralelismo não foi usado. Os valores para esse atributo incluem:
| NonParallelPlanReason Value | Descrição |
|---|---|
| MaxDOPSetToOne | Grau máximo de paralelismo definido como 1. |
| EstimatedDOPIsOne | O grau estimado de paralelismo é 1. |
| NoParallelWithRemoteQuery | O paralelismo não é compatível com consultas remotas. |
| NoParallelDynamicCursor | Não há suporte para planos paralelos em cursores dinâmicos. |
| NoParallelFastForwardCursor | Não há suporte para planos paralelos em cursores de avanço rápido. |
| NoParallelCursorFetchByBookmark | Não há suporte para planos paralelos em cursores que buscam por indicador. |
| NoParallelCreateIndexInNonEnterpriseEdition | Não há suporte para criação de índice paralelo na edição não empresarial. |
| NoParallelPlansInDesktopOrExpressEdition | Não há suporte para planos paralelos nas edições Desktop e Express. |
| NonParallelizableIntrinsicFunction | A consulta está fazendo referência a uma função intrínseca não paralelizável. |
| CLRUserDefinedFunctionRequiresDataAccess | Não há suporte para paralelismo em uma UDF CLR que requer acesso a dados. |
| TSQLUserDefinedFunctionsNotParallelizable | A consulta está fazendo referência a uma função definida pelo usuário T-SQL que não era paralelizável. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | As transações de variáveis de tabela não são compatíveis com as transações aninhadas paralelas. |
| DMLQueryReturnsOutputToClient | A consulta DML retorna a saída ao cliente e não é paralelizável. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | A combinação de planos serial e paralelo sem suporte para um único build de índice online. |
| CouldNotGenerateValidParallelPlan | Falha ao verificar o plano paralelo; realizando failback para serial. |
| NoParallelForMemoryOptimizedTables | Não há suporte para paralelismo em tabelas OLTP in-memory referenciadas. |
| NoParallelForDmlOnMemoryOptimizedTable | Não há suporte para paralelismo em DML em uma tabela OLTP in-memory. |
| NoParallelForNativelyCompiledModule | Não há suporte para paralelismo em módulos compilados nativamente referenciados. |
| NoRangesResumableCreate | Falha na geração de intervalo para uma operação de criação retomável. |
Depois que os operadores de troca são inseridos, o resultado é um plano de execução da consulta paralela. Um plano de execução de consulta paralela pode usar mais de um thread de trabalho. Um plano de execução em série, usado por uma consulta não paralela (em série), usa só um thread de trabalho para sua execução. O número real de threads de trabalho usado por uma consulta paralela é determinado na inicialização da execução do plano de consulta e pela complexidade do plano e seu grau de paralelismo.
O DOP (Grau de Paralelismo) determina o número máximo de CPUs que estão sendo usadas; isso não significa o número de threads de trabalho que estão sendo usados. O limite de DOP é definido por tarefa. Não é um limite por solicitação ou por consulta. Isso significa que, durante uma execução de consulta paralela, uma solicitação única pode gerar várias tarefas que são atribuídas a um agendador. Mais processadores do que o especificado pelo MAXDOP podem ser usados simultaneamente em qualquer ponto de execução de consulta específico, quando diferentes tarefas são executadas simultaneamente. Para saber mais, confira o Guia de arquitetura de threads e tarefas.
O Otimizador de Consulta do SQL Server não usa um plano de execução paralela para uma consulta se alguma das condições a seguir for verdadeira:
- O plano de execução serial é trivial ou não excede o limite de custo para a configuração de paralelismo.
- O plano de execução serial tem um custo total estimado de subárvore menor do que qualquer plano paralelo de execução explorado pelo otimizador.
- A consulta contém operadores escalares ou relacionais que não podem ser executados em paralelo. Certos operadores podem fazer com que uma seção do plano de consulta seja executada no modo em série ou que todo o plano seja executado no modo em série.
Observação
O custo total estimado da subárvore de um plano paralelo pode ser menor do que o limite de custo para a configuração de paralelismo. Isso indica que o custo total estimado da subárvore do plano serial o excedeu, e o plano de consulta com o menor custo total estimado da subárvore foi escolhido.
Grau de Paralelismo (DOP)
O SQL Server detecta automaticamente o melhor grau de paralelismo para cada instância de uma execução de consulta paralela ou operação DDL (linguagem de definição de dados) do índice. Isso é feito baseado nos seguintes critérios:
Se o SQL Server estiver sendo executado em um computador que tenha mais de um microprocessador ou mais de uma CPU, como um computador SMP (multiprocessamento simétrico). Apenas computadores que têm mais de uma CPU podem usar consultas paralelas.
Se há threads de trabalho suficientes disponíveis. Cada operação de consulta ou índice exige um determinado número de threads de trabalho para execução. A execução de um plano paralelo exige mais threads de trabalho que um plano serial e o número de threads de trabalho exigidos aumenta conforme o grau de paralelismo. Quando o requisito de thread de trabalho do plano paralelo para um grau específico de paralelismo não pode ser satisfeito, o Mecanismo de Banco de Dados do SQL Server diminui o grau de paralelismo automaticamente ou abandona completamente o plano paralelo no contexto de carga de trabalho especificado. Depois, ele executará o plano consecutivo (um thread de trabalho).
O tipo de operação de consulta ou de índice executada. As operações de índice que criam ou reconstroem um índice, ou descartam um índice cluster e as consultas que usam ciclos de CPU frequentemente são as melhores opções para um plano paralelo. Por exemplo, junções de tabelas grandes, agregações grandes e classificação de conjuntos de resultados grandes são boas alternativas. As consultas simples, frequentemente encontradas em aplicativos de processamento de transações, localizam a coordenação adicional exigida para executar uma consulta em paralelo que supera o aumento de desempenho potencial. Para distinguir entre consultas que se beneficiam do paralelismo e aquelas que não se beneficiam, o Mecanismo de Banco de Dados do SQL Server compara o custo estimado de execução da consulta ou operação de índice com o limite de custo do valor de paralelismo. Os usuários podem alterar o valor padrão 5 usando sp_configure se os testes adequados descobriram que um valor diferente é mais adequado para a carga de trabalho em execução.
Se houver um número suficiente de linhas para processar. Se o Otimizador de Consulta determinar que o número de linhas for muito baixo, ele não introduzirá operadores de troca para distribuir as linhas. Assim, os operadores serão executados em série. A execução dos operadores em um plano consecutivo evita cenários quando os custos de inicialização, distribuição e coordenação excedem os ganhos alcançados pela execução de operador paralela.
Se as estatísticas de distribuição atuais estiverem disponíveis. Se o maior grau de paralelismo não for possível, os graus mais baixos serão considerados antes que o plano paralelo seja abandonado. Por exemplo, quando você cria um índice clusterizado em uma exibição, as estatísticas de distribuição não poderão ser avaliadas porque o índice clusterizado ainda não existirá. Nesse caso, o Mecanismo de Banco de Dados do SQL Server não poderá fornecer o mais alto grau de paralelismo para a operação de índice. Porém, alguns operadores, como de classificação e verificação, ainda poderão se beneficiar da execução paralela.
Observação
As operações de índice paralelas somente estão disponíveis nas edições Enterprise, Developer e Evaluation do SQL Server.
No tempo de execução, o Mecanismo de Banco de Dados do SQL Server determina se a carga de trabalho do sistema atual e as informações de configuração descritas anteriormente permitem a execução paralela. Se a execução paralela for garantida, o Mecanismo de Banco de Dados do SQL Server determinará o número ideal de threads de trabalho e distribuirá a execução do plano paralelo entre esses threads de trabalho. Quando uma operação de consulta ou índice for iniciada executando em threads de trabalho múltiplos para execução paralela, o mesmo número de threads de trabalho será usado até que a operação seja concluída. O Mecanismo de Banco de Dados do SQL Server reexamina o número ideal de decisões de thread de trabalho sempre que um plano de execução é recuperado do cache de planos. Por exemplo, uma execução de uma consulta pode resultar no uso de um plano consecutivo, uma execução posterior da mesma consulta pode resultar em um plano paralelo que usa três threads de trabalho e uma terceira execução pode resultar em um plano paralelo que usa quatro threads de trabalho.
Os operadores Update e Delete em um plano de execução de consulta paralela são executados em série, mas a cláusula WHERE de uma instrução UPDATE ou DELETE pode ser executada em paralelo. As alterações de dados reais são, depois, aplicadas em série ao banco de dados.
Até o SQL Server 2012 (11.x), o operador insert também é executado serialmente. No entanto, a parte SELECT de uma instrução INSERT pode ser executada em paralelo. As alterações de dados reais são, depois, aplicadas em série ao banco de dados.
A partir do SQL Server 2014 (12.x) e do nível de compatibilidade do banco de dados 110, a instrução SELECT ... INTO pode ser executada em paralelo. Outras formas de operadores de inserção funcionam da mesma maneira descrita para SQL Server 2012 (11.x).
A partir do SQL Server 2016 (13.x) e do nível de compatibilidade do banco de dados 130, a instrução INSERT ... SELECT pode ser executada em paralelo ao inserir em heaps ou índices columnstore clusterizados (CCI) e usando a dica TABLOCK. Inserções em tabelas temporárias locais (identificadas pelo prefixo #) e em tabelas temporárias globais (identificadas por prefixos ##) também estão habilitadas para paralelismo usando a dica TABLOCK. Para saber mais, confira INSERT (Transact-SQL).
Cursores estáticos e controlados por conjunto de chaves podem ser populados por planos de execução paralelos. Porém, o comportamento dos cursores dinâmicos só pode ser fornecido por meio da execução consecutiva. O otimizador de consulta sempre gera um plano de execução consecutivo para uma consulta que faz parte de um cursor dinâmico.
Substituir graus de paralelismo
O grau de paralelismo define o número de processadores a serem usados na execução do plano paralelo. Essa configuração pode ser definida em vários níveis:
Nível do servidor, usando a opção de grau máximo de paralelismo (MAXDOP)na opção de configuração do servidor.
Aplica-se a: SQL ServerObservação
O SQL Server 2019 (15.x) apresenta recomendações automáticas para definir a opção de configuração do servidor MAXDOP durante o processo de instalação. A interface do usuário de configuração permite que você aceite as configurações recomendadas ou insira um valor próprio. Para saber mais, veja a página Configuração do Mecanismo de Banco de Dados – MaxDOP.
Nível da carga de trabalho, usando a opção de configuração de grupo de carga de trabalho do Resource GovernorMAX_DOP.
Aplica-se a: SQL ServerNível de banco de dados, usando a configuração com escopo do banco de dados MAXDOP.
Aplica-se a: SQL Server e Banco de Dados SQL do AzureNível de instrução de consulta ou índice, usando MAXDOPdica de consulta ou MAXDOP opção de índice. Por exemplo, você pode usar a opção MAXDOP para controlar, aumentando ou reduzindo, o número de processadores dedicado a uma operação de índice online. Desse modo, você pode equilibrar os recursos usados por uma operação de índice com aquele dos usuários simultâneos.
Aplica-se a: SQL Server e Banco de dados SQL do Azure
Configurar a opção de grau máximo de paralelismo como 0 (padrão) permite que o SQL Server use todos os processadores disponíveis até um máximo de 64 processadores em uma execução de plano paralelo. Embora o SQL Server defina um destino de tempo de execução de 64 processadores lógicos quando a opção MAXDOP estiver definida como 0, um valor diferente poderá ser definido manualmente, se necessário. A definição de MAXDOP como 0 para consultas e índices permite ao SQL Server usar todos os processadores disponíveis até um máximo de 64 processadores para as consultas ou índices específicos em uma execução de plano paralelo. O MAXDOP não é um valor imposto para todas as consultas paralelas, mas sim uma meta provisória para todas as consultas elegíveis para paralelismo. Isso significa que, se não houver threads de trabalho disponíveis suficientes no runtime, uma consulta poderá ser executada com um grau menor de paralelismo que a opção da configuração de servidor MAXDOP.
Dica
Para obter mais informações, confira Recomendações do MAXDOP para obter diretrizes sobre como configurar o MAXDOP no nível de servidor, banco de dados, consulta ou dica.
Exemplo de consulta paralela
A consulta a seguir conta o número de ordens emitidas em um trimestre específico, iniciando no dia 1º de abril de 2000, e no qual pelo menos um item de linha da ordem foi recebido pelo cliente depois da data confirmada. Essa consulta lista a contagem de tais ordens agrupadas por cada prioridade de ordem e classificada em ordem de prioridade crescente.
Esse exemplo usa nomes teóricos de tabela e de coluna.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Suponha que os índices a seguir estão definidos nas tabelas lineitem e orders:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Aqui há um possível plano paralelo gerado para a consulta mostrada anteriormente:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
A ilustração abaixo mostra um plano de consulta executado com um grau de paralelismo igual a 4 e envolvendo uma junção de duas tabelas.
O plano paralelo contém três operadores de paralelismo. O operador Index Seek do índice o_datkey_ptr e o operador Index Scan do índice l_order_dates_idx são executados em paralelo. Isso produz vários fluxos exclusivos. Isso pode ser determinado com base nos operadores Parallelism mais próximos acima dos operadores Index Scan e Index Seek, respectivamente. Ambos estão reparticionando o tipo de troca. Ou seja, eles estão apenas embaralhando novamente os dados entre os fluxos e produzindo na saída o mesmo número de fluxos existente na entrada. Esse número de fluxos é igual ao grau de paralelismo.
O operador de paralelismo acima do operador l_order_dates_idx Index Seek está reparticionando seus fluxos de entrada usando o valor de L_ORDERKEY como chave. Desse modo, os mesmos valores de L_ORDERKEY terminam no mesmo fluxo de saída. Ao mesmo tempo, os fluxos de saída mantêm a ordem na coluna L_ORDERKEY para atender o requisito de entrada do operador Merge Join.
O operador de paralelismo acima do operador Index Seek está reparticionando seus fluxos de entrada usando o valor de O_ORDERKEY. Como sua entrada não é classificada nos valores da coluna O_ORDERKEY e esta é a coluna de junção no operador Merge Join, o operador Sort entre os operadores de paralelismo e Merge Join garantem que a entrada seja classificada para o operador Merge Join nas colunas de junção. O operador Sort, assim como o operador Merge Join, é executado em paralelo.
O operador de paralelismo superior reúne resultados de vários fluxos em um único fluxo. As agregações parciais executadas pelo operador Stream Aggregate abaixo do operador de paralelismo são acumuladas em um único valor SUM de cada valor diferente de O_ORDERPRIORITY no operador Stream Aggregate acima do operador de paralelismo. Como esse plano tem dois segmentos de troca com grau de paralelismo igual a 4, ele usa oito threads de trabalho.
Para obter mais informações sobre os operadores usados neste exemplo, consulte a Referência de Operadores Físicos e Lógicos do Plano de Execução.
Operações de índice paralelo
Os planos de consulta criados para as operações de índice que criam ou recompilar um índice, ou removem um índice clusterizado, permitem operações multi-threaded de trabalho paralelas em computadores que tenham vários microprocessadores.
Observação
As operações de índice paralelo estão disponíveis apenas na Edição Enterprise, a partir do SQL Server 2008 (10.0.x).
O SQL Server usa os mesmos algoritmos para determinar o grau de paralelismo (o número total de threads de trabalho separados a serem executados) para operações de índice e para outras consultas. O grau máximo de paralelismo para uma operação de índice está sujeito à opção de configuração de servidor grau máximo de paralelismo . É possível substituir o valor do grau máximo de paralelismo para operações de índice individuais definindo a opção de índice MAXDOP nas instruções CREATE INDEX, ALTER INDEX, DROP INDEX e ALTER TABLE.
Quando o Mecanismo de Banco de Dados do SQL Server cria um plano de execução de índice, o número de operações paralelas é definido como o valor mais baixo dentre os seguintes:
- O número de microprocessadores ou CPUs no computador.
- O número especificado na opção de configuração de servidor grau máximo de paralelismo.
- O número de CPUs que ainda não ultrapassou o limite de trabalho executado para threads de trabalho do SQL Server.
Por exemplo, em um computador que tem oito CPUs, mas que o grau máximo de paralelismo está definido como 6, não são gerados mais do que seis threads de trabalho paralelos para uma operação de índice. Se cinco das CPUs no computador excederem o limite de trabalho do SQL Server quando um plano de execução de índice for criado, o plano de execução especificará somente três threads de trabalho paralelos.
As fases principais de uma operação de índice paralela incluem o seguinte:
- Um thread de trabalho coordenador que examina a tabela de forma rápida e aleatória para calcular a distribuição das chaves do índice. O thread de trabalho coordenador estabelece os limites de chave que criarão um número de intervalos de chave igual ao grau de operações paralelas, em que cada intervalo de chave é calculado para cobrir números semelhantes de linhas. Por exemplo, se houver quatro milhões de linhas na tabela e o grau de paralelismo for 4, o thread de trabalho coordenador determinará os valores de chave que delimitam quatro conjuntos de linhas com 1 milhão de linhas em cada conjunto. Se não for possível estabelecer intervalos de chaves suficientes para usar todas as CPUs, o grau de paralelismo será reduzido de acordo.
- O thread de trabalho coordenador despacha um número de threads de trabalho igual para o grau de operações paralelas e espera que esses threads de trabalho concluam o trabalho deles. Cada thread de trabalho examina a tabela base usando um filtro que recupera apenas as linhas com valores de chave dentro do intervalo atribuído ao thread de trabalho. Cada thread de trabalho cria uma estrutura de índice para as linhas em seu intervalo de chave. No caso de um índice particionado, cada thread de trabalho cria um número especificado de partições. Não são compartilhadas partições entre threads de trabalho.
- Após a conclusão de todos os threads de trabalho paralelos, o thread de trabalho coordenador conecta as subunidades de índice em um único índice. Essa fase só se aplica a operações de índice offline.
As instruções CREATE TABLE ou ALTER TABLE individuais podem ter várias restrições que exigem a criação de um índice. Essas operações de criação de vários índices são executadas em série, embora cada operação de criação de índice individual possa ser uma operação paralela em um computador com várias CPUs.
Arquitetura de consulta distribuída
O Microsoft SQL Server oferece suporte a dois métodos para referenciar fontes de dados OLE DB heterogêneas em instruções Transact-SQL:
Nomes de servidor vinculado
Os procedimentos armazenados do sistemasp_addlinkedserveresp_addlinkedsrvloginsão usados para fornecer um nome de servidor a uma fonte de dados OLE DB. Os objetos desses servidores vinculados podem ser referenciados nas instruções Transact-SQL que usam nomes de quatro partes. Por exemplo, se um nome de servidor vinculado doDeptSQLSrvrfor definido em relação a outra instância do SQL Server, as seguintes referências de instrução farão referência a uma tabela naquele servidor:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;O nome de servidor vinculado também pode ser especificado em uma instrução
OPENQUERYpara abrir um conjunto de linhas da fonte de dados OLE DB. Esse conjunto de linhas pode ser referenciado como uma tabela nas instruções Transact-SQL.Nomes de conector ad hoc
Para referências de pouca frequência a uma fonte de dados, são especificadas as funçõesOPENROWSETouOPENDATASOURCEcom as informações necessárias para a conexão com o servidor vinculado. O conjunto de linhas pode ser referenciado do mesmo modo que uma tabela é referenciada nas instruções Transact-SQL:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
O SQL Server usa o OLE DB para se comunicar entre o mecanismo relacional e o mecanismo de armazenamento. O mecanismo relacional divide cada instrução Transact-SQL em uma série de operações nos conjuntos de linhas OLE DB simples abertos pelo mecanismo de armazenamento das tabelas base. Isso significa que o mecanismo relacional também pode abrir os conjuntos de linhas OLE DB simples em qualquer fonte de dados OLE DB.

O mecanismo relacional usa a API (interface de programação de aplicativo) do OLE DB para abrir os conjuntos de linhas em servidores vinculados, buscar as linhas e gerenciar as transações.
Para cada fonte de dados OLE DB acessada como um servidor vinculado, é necessário que um provedor OLE DB esteja presente no servidor que executa o SQL Server. O conjunto de operações Transact-SQL que pode ser usado com uma fonte de dados OLE DB específica depende dos recursos do provedor OLE DB.
Para cada instância do SQL Server, os membros da função de servidor fixa sysadmin podem habilitar ou desabilitar o uso de nomes de conectores ad hoc para um provedor OLE DB usando a propriedade DisallowAdhocAccess do SQL Server. Quando o acesso ad hoc está habilitado, qualquer usuário com logon naquela instância pode executar instruções Transact-SQL contendo nomes de conectores ad hoc, referenciando qualquer fonte de dados na rede que possa ser acessada usando esse provedor OLE DB. Para controlar o acesso a fontes de dados, os membros da função sysadmin podem desabilitar o acesso ad hoc ao provedor OLE DB, limitando os usuários às fontes de dados referenciadas pelos nomes de servidores vinculados definidos pelos administradores. Por padrão, o acesso ad hoc é habilitado para o provedor OLE DB do SQL Server e desabilitado para todos os outros provedores OLE DB.
As consultas distribuídas podem permitir que os usuários acessem outra fonte de dados (por exemplo, arquivos, fontes de dados não relacionais como Active Directory, e assim por diante) que usa o contexto de segurança da conta do Microsoft Windows no qual o serviço do SQL Server está sendo executado. O SQL Server representa o logon adequadamente para logons do Windows; no entanto, isso não é possível para logons do SQL Server. Isso pode permitir que um usuário de consulta distribuída acesse outra fonte de dados para a qual não tem permissões, mas a conta sob a qual o serviço SQL Server está sendo executado tem permissões. Use sp_addlinkedsrvlogin para definir os logons específicos autorizados para acessar o servidor vinculado correspondente. Esse controle não está disponível para nomes ad hoc, portanto, tenha cuidado ao habilitar um provedor OLE DB para acesso ad hoc.
Quando possível, o SQL Server envia operações relacionais como junções, restrições, projeções, classificações e operações de agrupar por à fonte de dados OLE DB. O SQL Server não tem como padrão verificar a tabela base no SQL Server e executar as próprias operações relacionais. O SQL Server consulta o provedor OLE DB para determinar o nível de gramática SQL ao qual ele oferece suporte e, com base nessas informações, envia o máximo possível de operações relacionais para o provedor.
O SQL Server especifica um mecanismo para um provedor OLE DB retornar estatísticas que indicam como os valores de chave são distribuídos em uma fonte de dados OLE DB. Isso permite ao Otimizador de Consulta do SQL Server analisar melhor o padrão de dados na fonte de dados em relação aos requisitos de cada instrução Transact-SQL, aumentando a capacidade do Otimizador de Consulta de gerar planos de execução otimizados.
Aprimoramentos no processamento de consultas em tabelas e índices particionados
O SQL Server 2008 (10.0.x) melhorou o desempenho do processamento de consultas em tabelas particionadas para muitos planos paralelos, alterou a forma como os planos paralelos e seriais são representados e aprimorou as informações de particionamento fornecidas nos planos de execução em tempo de compilação e em tempo de execução. Este artigo descreve essas melhorias, fornece orientações sobre como interpretar os planos de execução de consultas de tabelas e índices particionados e fornece as melhores práticas para melhorar o desempenho de consultas em objetos particionados.
Observação
Até o SQL Server 2014 (12.x), tabelas e índices particionados são compatíveis apenas com as edições Enterprise, Developer e Evaluation do SQL Server. A partir do SQL Server 2016 (13.x) SP1, tabelas e índices particionados também são compatíveis com a edição Standard do SQL Server.
Nova operação de busca com reconhecimento de partição
No SQL Server, a representação interna de uma tabela particionada é alterada para que a tabela pareça ao processador de consultas um índice de várias colunas com PartitionID como coluna principal. PartitionID é uma coluna computada oculta, usada internamente para representar o ID da partição que contém uma linha específica. Por exemplo, suponha que a tabela T, definida como T(a, b, c), seja particionada na coluna a, e tenha um índice clusterizado na coluna b. No SQL Server, essa tabela particionada é tratada internamente como uma tabela não particionada com o esquema T(PartitionID, a, b, c) e um índice clusterizado na chave composta (PartitionID, b). Isso permite que o Otimizador de Consulta execute operações de busca baseadas em PartitionID em qualquer tabela ou índice particionado.
Agora a eliminação de partição está concluída na operação de busca.
In addition, the Query Optimizer is extended so that a seek or scan operation with one condition can be done on PartitionID (como a coluna lógica principal) e possivelmente em outras colunas de chave de índice e, depois, uma busca de segundo nível, com uma condição diferente, possa ser realizada em uma ou mais colunas adicionais, para cada valor diferente que atenda à qualificação para a operação de busca de primeiro nível. Ou seja, essa operação, chamada de busca seletiva, permite que o otimizador de consulta realize uma operação de busca ou de exame baseada em uma condição para determinar as partições a serem acessadas e uma operação de busca de segundo nível no operador para retornar linhas dessas partições que atendam a uma condição diferente. Por exemplo, considere a consulta abaixo.
SELECT * FROM T WHERE a < 10 and b = 2;
Para esse exemplo, suponha que a tabela T, definida como T(a, b, c), seja particionada na coluna a e tenha um índice clusterizado na coluna b. Os limites de partição da tabela T são definidos pela seguinte função de partição:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Para solucionar a consulta, o processador de consulta realiza uma operação de busca de primeiro nível para encontrar todas as partições que contenham linhas que atendam à condição T.a < 10. Isso identifica as partições a serem acessadas. Em cada partição identificada, o processador realiza uma busca de segundo nível no índice clusterizado na coluna b para encontrar as linhas que atendem à condição T.b = 2 e T.a < 10.
A ilustração a seguir é uma representação lógica da operação de busca seletiva. Ela mostra a tabela T com dados nas colunas a e b. As partições são numeradas de 1 a 4 com os limites de partição mostrados por linhas verticais tracejadas. Uma operação de busca de primeiro nível nas partições (não mostrada na ilustração) determinou que as partições 1, 2 e 3 atendem à condição de busca implícita pelo particionamento definido para a tabela e o predicado na coluna a. Ou seja, T.a < 10. O caminho atravessado pela parte da busca de segundo nível da operação de busca seletiva é ilustrado pela linha curva. Essencialmente, a operação de busca seletiva procura, em cada uma destas partições, por linhas que atendam à condição b = 2. O custo total da operação de busca seletiva é igual ao de três buscas de índice separadas.
Exibir informações sobre particionamento em planos de execução de consultas
Os planos de execução de consultas em tabelas e índices particionados podem ser examinados usando instruções SET de Transact-SQL SET SHOWPLAN_XML ou SET STATISTICS XML, ou usando a saída do plano de execução gráfica no SQL Server Management Studio. Por exemplo, você pode exibir o plano de execução em tempo de compilação selecionando Exibir Plano de Execução Estimado na barra de ferramentas do Editor de Consultas e o plano em tempo de execução selecionando Incluir Plano de Execução Real.
Usando essas ferramentas, você pode averiguar as seguintes informações:
- As operações como
scans,seeks,inserts,updates,mergesedeletesque acessam tabelas ou índices particionados. - As partições acessadas pela consulta. Por exemplo, a contagem total de partições acessadas e os intervalos de partições contíguas que são acessadas estão disponíveis nos planos de execução de tempo de execução.
- Quando a operação de busca seletiva é usada em uma operação de busca ou de exame para recuperar dados de uma ou mais partições.
Aprimoramentos das informações sobre partições
O SQL Server fornece informações aperfeiçoadas de particionamento para planos de execução de tempo de compilação e tempo de execução. Agora, os planos de execução fornecem as seguintes informações:
- Um atributo opcional
Partitionedque indica que um operador, comoseek,scan,insert,update,mergeoudelete, é executado em uma tabela particionada. - Um novo elemento
SeekPredicateNewcom um subelementoSeekKeysque incluiPartitionIDcomo a coluna de chave de índice à esquerda e as condições de filtro que especificam buscas de intervalo emPartitionID. A presença de dois subelementosSeekKeysindica que uma operação de busca seletiva noPartitionIDé usada. - Informações resumidas que fornecem uma contagem total das partições acessadas. Essas informações só estão disponíveis em planos de tempo de execução.
Para demonstrar como essas informações são exibidas tanto na saída do plano de execução gráfica, quanto na saída do Plano de Execução XML, considere a seguinte consulta na tabela particionada fact_sales. Esta consulta atualiza dados em duas partições.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
A ilustração a seguir mostra as propriedades do operador Clustered Index Seek no plano de execução de runtime dessa consulta. Para exibir a definição da tabela fact_sales e a definição de partição, consulte "Exemplo" neste artigo.

Atributo particionado
Quando um operador como Index Seek é executado em uma tabela ou índice particionado, o atributo Partitioned aparece no plano de tempo de compilação e em tempo de execução e é definido como True (1). O atributo não é exibido quando definido como False (0).
O atributo Partitioned pode ser exibido nos seguintes operadores físicos e lógicos:
- Table Scan
- Index Scan
- Index Seek
- Inserir
- Atualizar
- Excluir
- Mesclar
Conforme mostrado na ilustração anterior, esse atributo é exibido nas propriedades do operador no qual ele é definido. Na saída Plano de Execução XML, esse atributo é exibido como Partitioned="1" no nó RelOp do operador no qual é definido.
Novo predicado de busca
Na saída Plano de Execução XML, o elemento SeekPredicateNew aparece no operador no qual está definido. Ele pode conter até duas ocorrências de subelemento SeekKeys. O primeiro item SeekKeys especifica a operação de busca de primeiro nível no nível da ID da partição do índice lógico. Ou seja, essa busca determina as partições que devem ser acessadas para atender as condições da consulta. O segundo item SeekKeys especifica a parte de busca de segundo nível da operação de busca seletiva que ocorre em cada partição identificada na busca de primeiro nível.
Informações resumidas sobre partições
Nos planos de execução de tempo de execução, as informações resumidas sobre partições fornecem uma contagem das partições acessadas e da identidade das partições reais acessadas. É possível usar essas informações para verificar se as partições corretas são acessadas na consulta e se todas as outras partições são eliminadas do exame.
As informações a seguir são fornecidas: Actual Partition Counte Partitions Accessed.
Actual Partition Count é o número total de partições acessadas pela consulta.
Partitions Accessed, na saída Plano de Execução XML, são as informações de resumo da partição que são exibidas no novo elemento RuntimePartitionSummary no nó RelOp do operador no qual ele é definido. O exemplo a seguir demonstra o conteúdo do elemento RuntimePartitionSummary , indicando que é acessado o total de duas partições (partições 2 e 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Exibir informações de partição usando outros métodos de Plano de Execução
Os métodos de Plano de Execução SHOWPLAN_ALL, SHOWPLAN_TEXT e STATISTICS PROFILE não reportam as informações sobre partições descritas neste artigo, com a seguinte exceção. Como parte do predicado SEEK , as partições a serem acessadas são identificadas por um predicado de intervalo na coluna computada representando a ID da partição. A exemplo a seguir mostra o predicado SEEK para um operador Clustered Index Seek . As partições 2 e 3 são acessadas e o operador de busca filtra as linhas que atendem à condição date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpretar planos de execução para heaps particionados
Um heap particionado é tratado como um índice lógico na ID da partição. A eliminação de partição em um heap particionado é representada em um plano de execução como um operador Table Scan com um predicado SEEK na ID da partição. O exemplo a seguir mostra as informações fornecidas sobre o Plano de Execução:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpretar planos de execução para junções colocadas
Uma colocação de junção pode ocorrer quando duas tabelas são particionadas usando a mesma função de particionamento ou função equivalente e as colunas de particionamento de ambos os lados da junção são especificadas na condição de junção da consulta. O otimizador de consulta pode gerar um plano em que as partições de cada uma das tabelas que tenham IDs de partição iguais sejam unidas separadamente. As junções colocadas podem ser mais rápidas que as junções não colocadas porque podem exigir menos memória e tempo de processamento. O Otimizador de Consulta escolhe um plano não colocado ou colocado com base em estimativas de custo.
Em um plano colocado, a junção Nested Loops lê uma ou mais partições de índice e tabela unidas a partir da parte interna. Os números dos operadores Constant Scan representam os números de partições.
Quando planos paralelos para junções colocadas são gerados para tabelas ou índices particionados, um operador Parallelism é exibido entre os operadores de junção Constant Scan e Nested Loops . Nesse caso, cada um dos vários threads de trabalho da parte externa da junção lê e trabalha em uma partição diferente.
A ilustração a seguir demonstra um plano de consulta paralelo para uma junção colocada.
Estratégias de execução de consulta paralela para objetos particionados
O processador de consulta usa uma estratégia de execução paralela para consultas selecionadas a partir de objetos particionados. Como parte da estratégia de execução, o processador de consulta determina as partições de tabela necessárias para a consulta e a proporção de threads de trabalho a serem alocados para cada partição. Na maioria dos casos, o processador de consulta aloca um número igual ou aproximado de threads de trabalho para cada partição e executa a consulta paralelamente por meio das partições. Os parágrafos a seguir explicam a alocação de thread de trabalho com mais detalhes.

Se o número de threads de trabalho é menor que o número de partições, o processador de consulta atribui cada thread de trabalho a uma partição diferente, inicialmente, mantendo uma ou mais partições sem um thread atribuído de trabalho. Quando um thread de trabalho termina a execução em uma partição, o processador de consulta o atribui para a próxima partição até que tenha sido atribuído um único thread de trabalho para cada partição. Esse é o único caso em que o processador de consulta realoca threads de trabalho a outras partições.
Mostra o thread de trabalho reatribuído após a conclusão. Se o número de threads de trabalho é igual ao número de partições, o processador de consulta atribui um thread de trabalho para cada partição. Quando um thread de trabalho é concluído, ele não é realocado para outra partição.

Se o número de threads de trabalho é maior que o número de partições, o processador de consulta aloca um número igual de threads de trabalho para cada partição. Se o número de threads de trabalho não for um múltiplo exato do número de partições, o processador de consultas alocará um thread de trabalho adicional para algumas partições para usar todos os threads de trabalho disponíveis. Se houver apenas uma partição, todos os threads de trabalho serão atribuídos a ela. No diagrama a seguir, há quatro partições e 14 threads de trabalho. Cada partição tem 3 threads de trabalho atribuídos e duas partições têm um thread de trabalho adicional, com um total de 14 threads de trabalho atribuídos. Quando um thread de trabalho é concluído, ele não é reatribuído para outra partição.

Embora o exemplo anterior sugira um modo objetivo para alocar threads de trabalho, a estratégia real é mais complexa e serve para outras variáveis que ocorrem durante a execução da consulta. Por exemplo, se a tabela estiver particionada e tiver um índice clusterizado na coluna A e uma consulta tiver a cláusula de predicado WHERE A IN (13, 17, 25), o processador de consulta alocará um ou mais threads de trabalho a cada um destes três valores de busca (A=13, A=17 e A=25) em vez de cada partição de tabela. Só será necessário executar a consulta nas partições que tiverem esses valores. Se todos esses predicados de busca estiverem na mesma partição de tabela, todos os threads de trabalho serão atribuídos para a mesma partição de tabela.
Vejamos outro exemplo, vamos supor que a tabela possui quatro partições na coluna A com pontos de limite (10, 20, 30), um índice na coluna B e a consulta tem uma cláusula de predicado WHERE B IN (50, 100, 150). Como as partições da tabela têm base nos valores de A, os valores de B podem ocorrer em qualquer uma das partições da tabela. Dessa forma, o processador de consulta buscará cada um dos três valores de B (50, 100, 150) em cada uma das quatro partições de tabela. O processador de consulta atribuirá threads de trabalho proporcionalmente para que possa executar cada um desses 12 exames de consulta em paralelo.
| As partições de tabela baseadas na coluna A | Buscas para coluna B em cada partição de tabela |
|---|---|
| Partição de tabela 1: A < 10 | B=50, B=100, B=150 |
| Partição de tabela 2: A >= 10 E A < 20 | B=50, B=100, B=150 |
| Partição de tabela 3: A >= 20 E A < 30 | B=50, B=100, B=150 |
| Partição de tabela 4: A >= 30 | B=50, B=100, B=150 |
Práticas recomendadas
Para melhorar o desempenho das consultas que acessam uma grande quantidade de dados de grandes tabelas e índices particionados, recomendamos as seguintes práticas:
- Distribuir cada partição em muitos discos. Isso é especialmente relevante ao usar discos de rotação.
- Quando possível, use um servidor com memória principal suficiente para acomodar partições acessadas com frequência, ou todas as partições na memória, para reduzir o custo de E/S.
- Se os dados que você consulta não couberem na memória, compacte as tabelas e os índices. Isso reduzirá o custo de E/S.
- Usar um servidor com processadores rápidos e o máximo possível de núcleos de processador, para se beneficiar da capacidade de processamento de consultas paralelas.
- Verificar se o servidor tem largura de banda suficiente do controlador de E/S.
- Criar um índice clusterizado em todas as tabelas particionadas grandes para beneficiar-se de otimizações de exames da árvore B.
- Seguir as práticas recomendadas no documento The Data Loading Performance Guide(Guia de Desempenho de Carregamento de Dados) quando estiver carregando dados em massa em tabelas particionadas.
Exemplo
O exemplo a seguir cria um banco de dados de teste que contém uma única tabela com sete partições. Use as ferramentas descritas anteriormente quando estiver executando as consultas descritas neste exemplo para exibir informações sobre particionamento para planos de tempo de compilação e de tempo de execução.
Observação
Este exemplo insere mais de 1 milhão de linhas na tabela. A execução deste exemplo pode demorar vários minutos, dependendo de seu hardware. Antes de executar este exemplo, verifique se há mais de 1.5 GB de espaço em disco disponível.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Conteúdo relacionado
- Referência de operadores físicos e lógicos de plano de execução
- Visão geral de eventos estendidos
- Melhores práticas para monitorar cargas de trabalho com o Repositório de Consultas
- Estimativa de cardinalidade (SQL Server)
- Processamento inteligente de consultas em bancos de dados SQL
- Precedência dos operadores (Transact-SQL)
- Visão geral do plano de execução
- Central de desempenho do Mecanismo de Banco de Dados do SQL Server e do Banco de Dados SQL do Azure
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de