Lendo Páginas
Aplica-se a:![]() SQL Server
SQL Server
A E/S de uma instância do Mecanismo de Banco de Dados do SQL Server inclui leituras lógicas e físicas. As leituras lógicas ocorrem sempre que o Mecanismo de Banco de Dados solicita uma página do cache do buffer. Se a página não estiver atualmente no cache do buffer, a leitura física copiará primeiramente a página de disco no cache.
As solicitações de leitura geradas por uma instância do Mecanismo de Banco de Dados são controladas pelo mecanismo relacional e otimizadas pelo mecanismo de armazenamento. O mecanismo relacional determina o método de acesso (como um exame de tabela, um exame de índice ou uma leitura de chave) mais efetivo; os métodos de acesso e os componentes do gerenciador de buffer do mecanismo de armazenamento determinam o padrão geral de leituras a serem executadas e otimizam as leituras exigidas para implementar o método de acesso. O thread que executa o lote agenda as leituras.
Read-Ahead
O Mecanismo de Banco de Dados é compatível com um mecanismo de otimização de desempenho chamado read-ahead. O read-ahead antecipa os dados e as páginas de índice necessários para atender a um plano de execução de consulta e traz as páginas ao cache do buffer antes de elas serem realmente usadas pela consulta. Isso permite a sobreposição da computação e da E/S, aproveitando ao máximo a CPU e o disco.
O mecanismo read-ahead permite que o Mecanismo de Banco de Dados leia até 64 páginas contíguas (512 KB) de um arquivo. A leitura é executada como uma única leitura de dispersão e coleta para o número apropriado (provavelmente não contíguo) de buffers no cache do buffer. Se alguma página do intervalo já estiver presente no cache do buffer, a página correspondente da leitura será descartada quando ela for concluída. O intervalo de páginas também pode ser “cortado” em qualquer ponto se as páginas correspondentes já estiverem presentes no cache.
Há dois tipos de read-ahead: um para páginas de dados e um para páginas de índice.
Lendo Páginas de dados
As verificações de tabela usadas para ler páginas de dados são muito eficientes no Mecanismo de Banco de Dados. As páginas IAM (Index Allocation Map) em um banco de dados do SQL Server listam as extensões usadas por uma tabela ou um índice. O mecanismo de armazenamento pode ler a página IAM para criar uma lista ordenada de endereços de disco que deve ser lida. Isso permite ao mecanismo de armazenamento otimizar suas E/S como grandes leituras sequenciais, executadas em sequência, com base em seu local no disco. Para saber mais sobre as páginas IAM, veja Gerenciando espaço usado por objetos.
Lendo páginas de índice
O mecanismo de armazenamento lê páginas de índice em série na ordem de chave. Por exemplo, essa ilustração mostra uma representação simplificada de um conjunto de páginas folha que contém um conjunto de chaves e o nó de índice intermediário que mapeia as páginas folha. Para saber mais sobre a estrutura de páginas em um índice, veja Estruturas de índice clusterizado.
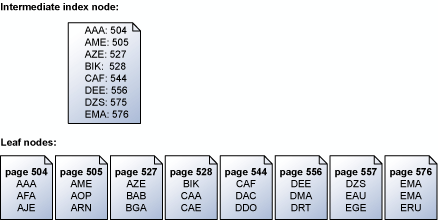
O mecanismo de armazenamento usa as informações na página de índice intermediário acima do nível folha para agendar read-aheads consecutivos para as páginas que contêm as chaves. Se uma solicitação for feita para todas as chaves de ABC para DEF, o mecanismo de armazenamento primeiro lerá a página de índice acima da página folha. No entanto, ele não lê cada página de dados em sequência da página 504 a 556 (a última página com chaves no intervalo especificado). Em vez disso, o mecanismo de armazenamento examina a página de índice intermediário e cria uma lista de páginas folha que deve ser lida. O mecanismo de armazenamento agenda todas as leituras em ordem de chave. O mecanismo de armazenamento também reconhece que as páginas 504/505 e 527/528 são contíguas e executa uma única leitura de dispersão para recuperar as páginas adjacentes em uma única operação. Quando há muitas páginas a serem recuperadas em uma operação consecutiva, o mecanismo de armazenamento agenda um bloco de leituras por vez. Quando um subconjunto dessas leituras é concluído, o mecanismo de armazenamento agenda um número igual de leituras novas até que todas as leituras exigidas sejam agendadas.
O mecanismo de armazenamento usa a pré-busca para acelerar as pesquisas de tabela base de índices não cluster. As linhas de folha de um índice não clusterizado contêm ponteiros para as linhas de dados que contém cada valor de chave específico. Como o mecanismo de armazenamento lê as páginas de folha do índice não clusterizado, também inicia o agendamento de leituras assíncronas das linhas de dados cujos ponteiros já foram recuperados. Isso permite ao mecanismo de armazenamento recuperar linhas de dados da tabela subjacente antes de concluir o exame do índice não clusterizado. A pré-busca é usada independentemente de a tabela ter um índice clusterizado. O SQL Server Enterprise usa mais pré-buscas do que as outras edições do SQL Server, permitindo que a leitura read-ahead seja feita em um número maior de páginas. O nível de pré-busca não é configurável em nenhuma edição. Para saber mais sobre índices não clusterizados, veja Estruturas de índice não clusterizado.
Exame avançado
No SQL Server Enterprise, o recurso de verificação avançada permite que diversas tarefas compartilhem verificações de tabelas completas. Caso o plano de execução de uma instrução Transact-SQL exija uma verificação das páginas de dados em uma tabela e o Mecanismo de Banco de Dados detecte que a tabela já está sendo verificada para outro plano de execução, o Mecanismo de Banco de Dados associará a segunda verificação à primeira, no local atual da segunda verificação. O Mecanismo de Banco de Dados lê cada página uma vez e passa as linhas de cada página para ambos os planos de execução. Isso continua até o término da tabela ser alcançado.
Nesse ponto, o primeiro plano de execução tem os resultados completos de um exame, mas o segundo plano de execução ainda precisa recuperar as páginas de dados que eram lidas antes de serem associadas ao exame em andamento. O exame do segundo plano de execução volta para a primeira página de dados da tabela e examina mais adiante o local em que ele foi associado ao primeiro exame. Qualquer número de exames pode ser combinado dessa forma. O Mecanismo de Banco de Dados continuará executando um loop pelas páginas de dados até que todas as verificações sejam concluídas. Esse mecanismo também é conhecido como “exame carrossel” e demonstra o motivo pelo qual a ordem dos resultados retornada de uma instrução SELECT não pode ser garantida sem uma cláusula ORDER BY.
Por exemplo, suponha que você tenha uma tabela com 500.000 páginas. O UserA executa uma instrução Transact-SQL que exige um exame da tabela. Quando esse exame tiver processado 100.000 páginas, o UserB executará outra instrução Transact-SQL que examinará a mesma tabela. O Mecanismo de Banco de Dados agenda um conjunto de solicitações de leitura para as páginas após 100.001 e passa as linhas de cada página de volta para ambas as verificações. Quando o exame alcançar 200.000 páginas, o UserC executará outra instrução Transact-SQL que examinará a mesma tabela. Após a página 200.001, o Mecanismo de Banco de Dados passa as linhas de cada página lida de volta para todas as três verificações. Depois de ler a linha 500.000, o exame do UserA será concluído, e os exames do UserB e UserC voltarão para o início e começarão a ler as páginas começando com a página 1. Quando o Mecanismo de Banco de Dados alcançar a página 100.000, a verificação de UserB estará concluída. O exame do UserC continuará sendo executado sozinho até alcançar a página 200.000. Nesse ponto, todos os exames estarão concluídos.
Sem o exame avançado, cada usuário teria de competir pelo espaço do buffer e isso causaria a contenção do braço do disco. As mesmas páginas seriam lidas uma vez para cada usuário, em vez de serem lidas uma vez e compartilhadas por vários usuários, reduzindo a velocidade do desempenho e sobrecarregando os recursos.
Confira também
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de