Cenários de uso da tabela temporal
Aplica-se a:![]() SQL Server
SQL Server
As tabelas temporais são úteis em cenários que exigem o acompanhamento do histórico de alterações de dados. Recomendamos que você considere as tabelas temporais nos seguintes casos de uso visando mais benefícios de produtividade.
Auditoria de dados
Use controle temporal da versão do sistema em tabelas que armazenam informações críticas para as quais você precisa acompanhar o que foi alterado, quando o foi e para executar análise forense dados em qualquer ponto no tempo.
Tabelas com controle temporal da versão do sistema permitem que você planeje os cenários de auditoria de dados nos primeiros estágios do ciclo de desenvolvimento ou adicione dados de auditoria aos aplicativos ou soluções existentes, quando necessário.
O diagrama a seguir mostra um cenário com uma tabela Funcionário com a amostra de dados, incluindo as versões de linha atual (marcada com a cor azul) e de histórico (marcada com cor cinza). A parte direita do diagrama visualiza as versões de linha no eixo de tempo e quais são as linhas que você seleciona com diferentes tipos de consulta na tabela temporal, com ou sem a cláusula SYSTEM_TIME.

Habilitação do controle da versão do sistema em uma nova tabela para auditoria de dados
Se você tiver identificado informações que requerem auditoria de dados, crie tabelas de banco de dados com controle temporal da versão do sistema. O exemplo simples a seguir ilustra um cenário com informações de Funcionário em um banco de dados de RH hipotético:
CREATE TABLE Employee
(
[EmployeeID] int NOT NULL PRIMARY KEY CLUSTERED
, [Name] nvarchar(100) NOT NULL
, [Position] varchar(100) NOT NULL
, [Department] varchar(100) NOT NULL
, [Address] nvarchar(1024) NOT NULL
, [AnnualSalary] decimal (10,2) NOT NULL
, [ValidFrom] datetime2 (2) GENERATED ALWAYS AS ROW START
, [ValidTo] datetime2 (2) GENERATED ALWAYS AS ROW END
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo)
)
WITH (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.EmployeeHistory));
Várias opções para criar a tabela com controle temporal da versão do sistema são descritas em Creating a System-Versioned Temporal Table(Criando uma tabela temporal com controle da versão do sistema).
Habilitação do controle da versão de sistema em uma tabela existente para auditoria de dados
Se você precisar realizar auditoria de dados em bancos de dados existentes, use ALTER TABLE para estender as tabelas não temporais, fazendo com que passem a oferecer controle da versão do sistema. Para evitar alterações interruptivas em seu aplicativo, adicione colunas de período como HIDDEN, conforme explicado em Alterar a tabela não temporal para ser uma tabela temporal com controle da versão do sistema. O exemplo a seguir ilustra a habilitação do controle da versão do sistema em uma tabela Funcionário existente em um banco de dados de RH hipotético:
/*
Turn ON system versioning in Employee table in two steps
(1) add new period columns (HIDDEN)
(2) create default history table
*/
ALTER TABLE Employee
ADD
ValidFrom datetime2 (2) GENERATED ALWAYS AS ROW START HIDDEN
constraint DF_ValidFrom DEFAULT DATEADD(second, -1, SYSUTCDATETIME())
, ValidTo datetime2 (2) GENERATED ALWAYS AS ROW END HIDDEN
constraint DF_ValidTo DEFAULT '9999.12.31 23:59:59.99'
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo);
ALTER TABLE Employee
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.Employee_History));
Importante
A precisão do tipo de dados datetime2 é a mesma na tabela de origem e na tabela histórica com controle de versão do sistema.
Depois de executar o script acima, todas as alterações de dados serão coletadas transparentemente na tabela de histórico. Em um cenário típico de auditoria de dados, você consultaria todas as alterações de dados que foram aplicadas a uma linha individual durante um período de tempo de interesse. A tabela de histórico padrão é criada com a árvore B de repositório de linha clusterizado para atender com eficiência esse caso de uso.
Executando análise de dados
Depois de habilitar o controle de versão de sistema usando uma das abordagens acima, você está a apenas uma consulta da auditoria de dados. A seguinte consulta procura por versões de linha para o registro de funcionário com EmployeeID = 1000 que estavam ativas por pelo menos parte do período entre 1º de janeiro de 2021 e 1º de janeiro de 2022 (incluindo o limite superior):
SELECT * FROM Employee
FOR SYSTEM_TIME
BETWEEN '2021-01-01 00:00:00.0000000' AND '2022-01-01 00:00:00.0000000'
WHERE EmployeeID = 1000 ORDER BY ValidFrom;
Substitua FOR SYSTEM_TIME BETWEEN...AND por FOR SYSTEM_TIME ALL para analisar todo o histórico de alterações de dados desse funcionário específico:
SELECT * FROM Employee
FOR SYSTEM_TIME ALL WHERE
EmployeeID = 1000 ORDER BY ValidFrom;
Para pesquisar pelas versões de linha que estavam ativas somente dentro de um período (e não fora dele), use CONTAINED IN. Essa consulta é eficiente porque consulta apenas a tabela de histórico:
SELECT * FROM Employee FOR SYSTEM_TIME
CONTAINED IN ('2021-01-01 00:00:00.0000000', '2022-01-01 00:00:00.0000000')
WHERE EmployeeID = 1000 ORDER BY ValidFrom;
Por fim, em alguns cenários de auditoria, talvez você deseje ver a aparência da tabela inteira em qualquer ponto no tempo no passado:
SELECT * FROM Employee FOR SYSTEM_TIME AS OF '2021-01-01 00:00:00.0000000';
As tabelas temporais com controle da versão do sistema armazenam valores de colunas de período no fuso horário UTC, mas pode ser mais conveniente trabalhar com o fuso horário local para filtragem de dados e exibição dos resultados. O seguinte exemplo de código mostra como aplicar a condição de filtragem que é especificada no fuso horário local e, depois, convertida em UTC usando AT TIME ZONE, introduzido no SQL Server 2016 (13.x):
/*Add offset of the local time zone to current time*/
DECLARE @asOf DATETIMEOFFSET = GETDATE() AT TIME ZONE 'Pacific Standard Time'
/*Convert AS OF filter to UTC*/
SET @asOf = DATEADD (HOUR, -9, @asOf) AT TIME ZONE 'UTC';
SELECT
EmployeeID
, Name
, Position
, Department
, [Address]
, [AnnualSalary]
, ValidFrom AT TIME ZONE 'Pacific Standard Time' AS ValidFromPT
, ValidTo AT TIME ZONE 'Pacific Standard Time' AS ValidToPT
FROM Employee
FOR SYSTEM_TIME AS OF @asOf where EmployeeId = 1000;
Usar AT TIME ZONE é útil em todos os outros cenários em que tabelas com controle de versão do sistema são usadas.
Dica
As condições de filtragem especificadas em cláusulas temporais com FOR SYSTEM_TIME são SARGable. (A capacidade de usar o SARG significa que o SQL Server pode utilizar o índice clusterizado subjacente para executar uma busca em vez de uma operação de verificação. Para obter mais informações, confira Guia de Arquitetura e Design de Índice do SQL Server.) Se você consultar a tabela de histórico diretamente, verifique se a sua condição de filtragem também tem a capacidade de usar o SARG especificando os filtros no formato \<period column> {< | > | =, ...} date_condition AT TIME ZONE 'UTC'.
Se você aplicar AT TIME ZONE a colunas de período, o SQL Server executará uma verificação de tabela/índice, o que pode ser muito caro. Evite esse tipo de condição em suas consultas: \<period column> AT TIME ZONE '\<your time zone>' > {< | > | =, ...} date_condition.
Consulte também: Consultar dados em uma tabela temporal com controle da versão do sistema.
Análise pontual (viagem no tempo)
Ao contrário da auditoria de dados, em que o foco normalmente é sobre as alterações que ocorreram em registros individuais, em cenários de viagem no tempo os usuários querem ver como conjuntos de dados inteiros sofreram alterações ao longo do tempo. Às vezes, viajar nos tempos inclui várias tabelas temporais relacionadas, cada uma sofrendo alterações em um ritmo independente, para as quais você deseja analisar:
- Tendências dos indicadores importantes nos dados atuais e históricos
- Instantâneo exato de todos os dados "começando em" qualquer ponto no tempo no passado (ontem, um mês atrás, etc.)
- As diferenças entre dois pontos no tempo de interesse (por exemplo, um mês atrás versus três meses atrás)
Há muitos cenários do mundo real que exigem a análise de viagem no tempo. Para ilustrar esse cenário de uso, observemos OLTP com histórico gerado automaticamente.
OLTP com histórico de dados gerada automaticamente
Em sistemas de processamento de transações, é possível analisar como métricas importantes sofrem alterações ao longo do tempo. Idealmente, analisar o histórico não deve comprometer o desempenho do aplicativo OLTP em que o acesso ao estado mais recente dos dados deve ocorrer com latência mínima e o mínimo de bloqueio de dados. É possível usar tabelas temporais com controle da versão do sistema para manter o histórico completo de alterações para análise posterior, transparentemente e separadamente de dados atuais, com o mínimo de impacto sobre a carga de trabalho de OLTP principal.
Para cargas de trabalho elevadas de processamento de transações, recomendamos que você use Tabelas temporais com controle da versão do sistema com tabelas com otimização de memória, que permitem que você armazene dados atuais in-memory e o histórico completo das alterações em disco, de maneira econômica.
Para a tabela de histórico, recomendamos que você use um índice columnstore clusterizado pelos seguintes motivos:
- A análise de tendência típica se beneficia do desempenho de consulta fornecido por um índice columnstore clusterizado.
- A tarefa de liberação de dados com tabelas com otimização de memória, sob carga de trabalho OLTP pesada, é melhor executada quando a tabela de histórico tem um índice columnstore clusterizado.
- Um índice columnstore clusterizado fornece excelente compactação, especialmente em situações em que nem todas as colunas são alteradas simultaneamente.
Usando tabelas de tempo com OLTP in-memory reduz a necessidade de manter todo o conjunto de dados na memória e permite distinguir facilmente entre dados quentes e frios.
Exemplos dos cenários reais que se enquadram bem nesta categoria são o gerenciamento de estoque e o câmbio de moedas, entre outros.
O diagrama a seguir mostra um modelo de dados simplificado usado para gerenciamento de estoque:

O exemplo de código a seguir cria ProductInventory como uma tabela temporal com controle da versão do sistema in-memory com um índice columnstore clusterizado na tabela de histórico (que, na verdade, substitui o índice de repositório de linha criado por padrão):
Observação
Verifique se seu banco de dados permite a criação de tabelas com otimização de memória. Consulte Criando uma tabela com otimização de memória e um procedimento armazenado compilado nativamente.
USE TemporalProductInventory
GO
BEGIN
--If table is system-versioned, SYSTEM_VERSIONING must be set to OFF first
IF ((SELECT temporal_type FROM SYS.TABLES WHERE object_id = OBJECT_ID('dbo.ProductInventory', 'U')) = 2)
BEGIN
ALTER TABLE [dbo].[ProductInventory] SET (SYSTEM_VERSIONING = OFF)
END
DROP TABLE IF EXISTS [dbo].[ProductInventory];
DROP TABLE IF EXISTS [dbo].[ProductInventoryHistory];
END
GO
CREATE TABLE [dbo].[ProductInventory]
(
ProductId int NOT NULL,
LocationID INT NOT NULL,
Quantity int NOT NULL CHECK (Quantity >=0),
ValidFrom datetime2 GENERATED ALWAYS AS ROW START NOT NULL ,
ValidTo datetime2 GENERATED ALWAYS AS ROW END NOT NULL ,
PERIOD FOR SYSTEM_TIME(ValidFrom, ValidTo),
--Primary key definition
CONSTRAINT PK_ProductInventory PRIMARY KEY NONCLUSTERED (ProductId, LocationId)
)
WITH
(
MEMORY_OPTIMIZED=ON,
SYSTEM_VERSIONING = ON
(
HISTORY_TABLE = [dbo].[ProductInventoryHistory],
DATA_CONSISTENCY_CHECK = ON
)
)
CREATE CLUSTERED COLUMNSTORE INDEX IX_ProductInventoryHistory ON [ProductInventoryHistory]
WITH (DROP_EXISTING = ON);
Para o modelo acima, veja como poderia ser o procedimento de manutenção de estoque:
CREATE PROCEDURE [dbo].[spUpdateInventory]
@productId int,
@locationId int,
@quantityIncrement int
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL=SNAPSHOT, LANGUAGE=N'English')
UPDATE dbo.ProductInventory
SET Quantity = Quantity + @quantityIncrement
WHERE ProductId = @productId AND LocationId = @locationId
/*If zero rows were updated than this is insert of the new product for a given location*/
IF @@rowcount = 0
BEGIN
IF @quantityIncrement < 0
SET @quantityIncrement = 0
INSERT INTO [dbo].[ProductInventory]
(
[ProductId]
,[LocationID]
,[Quantity]
)
VALUES
(
@productId
,@locationId
,@quantityIncrement
)
END
END;
O procedimento armazenado spUpdateInventory insere um novo produto no estoque ou atualiza a quantidade de produtos para a localização específica. A lógica de negócios é muito simples e voltada para manter o estado mais recente preciso sempre, incrementando/decrementando o campo Quantidade por meio de atualização da tabela, enquanto tabelas com controle da versão do sistema adicionam transparentemente dimensão de histórico aos dados, conforme ilustrado no diagrama abaixo.

Agora, a consulta do estado mais recente pode ser executada com eficiência do módulo compilado nativamente:
CREATE PROCEDURE [dbo].[spQueryInventoryLatestState]
WITH NATIVE_COMPILATION, SCHEMABINDING
AS
BEGIN ATOMIC WITH (TRANSACTION ISOLATION LEVEL=SNAPSHOT, LANGUAGE=N'English')
SELECT ProductId, LocationID, Quantity, ValidFrom
FROM dbo.ProductInventory
ORDER BY ProductId, LocationId
END;
GO
EXEC [dbo].[spQueryInventoryLatestState];
A análise de alterações de dados ao longo do tempo torna-se extremamente fácil com a cláusula FOR SYSTEM_TIME ALL, conforme mostrado no seguinte exemplo:
DROP VIEW IF EXISTS vw_GetProductInventoryHistory;
GO
CREATE VIEW vw_GetProductInventoryHistory
AS
SELECT ProductId, LocationId, Quantity, ValidFrom, ValidTo
FROM [dbo].[ProductInventory]
FOR SYSTEM_TIME ALL;
GO
SELECT * FROM vw_GetProductInventoryHistory
WHERE ProductId = 2;
O seguinte diagrama mostra o histórico de dados para um produto que pode ser renderizado facilmente importar a exibição acima no Power Query, Power BI ou ferramenta de business intelligence semelhante:

Tabelas temporais podem ser usadas neste cenário para executar outros tipos de análise de viagem nos tempos, como reconstruir o estado do inventário de qualquer ponto no tempo no passado ou comparar instantâneos pertencentes a diferentes momentos no tempo.
Para esse cenário de uso, você também pode estender as tabelas Produto e Local para se tornarem tabelas temporais para habilitar a análise posterior do histórico de alterações de UnitPrice e NumberOfEmployee.
ALTER TABLE Product
ADD
ValidFrom datetime2 GENERATED ALWAYS AS ROW START HIDDEN
constraint DF_ValidFrom DEFAULT DATEADD(second, -1, SYSUTCDATETIME())
, ValidTo datetime2 GENERATED ALWAYS AS ROW END HIDDEN
constraint DF_ValidTo DEFAULT '9999.12.31 23:59:59.99'
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo);
ALTER TABLE Product
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.ProductHistory));
ALTER TABLE [Location]
ADD
ValidFrom datetime2 GENERATED ALWAYS AS ROW START HIDDEN
constraint DFValidFrom DEFAULT DATEADD(second, -1, SYSUTCDATETIME())
, ValidTo datetime2 GENERATED ALWAYS AS ROW END HIDDEN
constraint DFValidTo DEFAULT '9999.12.31 23:59:59.99'
, PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo);
ALTER TABLE [Location]
SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.LocationHistory));
Como o modelo de dados agora envolve várias tabelas temporais, a melhor prática para análise AS OF é criar uma exibição que extraia os dados necessários das tabelas relacionadas e aplicar FOR SYSTEM_TIME AS OF à exibição, já que isso simplificará imensamente a reconstrução do estado do modelo de dados inteiro:
DROP VIEW IF EXISTS vw_ProductInventoryDetails;
GO
CREATE VIEW vw_ProductInventoryDetails
AS
SELECT PrInv.ProductId ,PrInv.LocationId, P.ProductName, L.LocationName, PrInv.Quantity
, P.UnitPrice, L.NumberOfEmployees
, P.ValidFrom AS ProductStartTime, P.ValidTo AS ProductEndTime
, L.ValidFrom AS LocationStartTime, L.ValidTo AS LocationEndTime
, PrInv.ValidFrom AS InventoryStartTime, PrInv.ValidTo AS InventoryEndTime
FROM dbo.ProductInventory as PrInv
JOIN dbo.Product AS P ON PrInv.ProductId = P.ProductID
JOIN dbo.Location AS L ON PrInv.LocationId = L.LocationID;
GO
SELECT * FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF '2022-01-01';
A captura de tela a seguir mostra o plano de execução gerado para a consulta SELECT. Isso ilustra que o mecanismo do SQL Server dá conta de toda a complexidade envolvida em lidar com relações temporais:
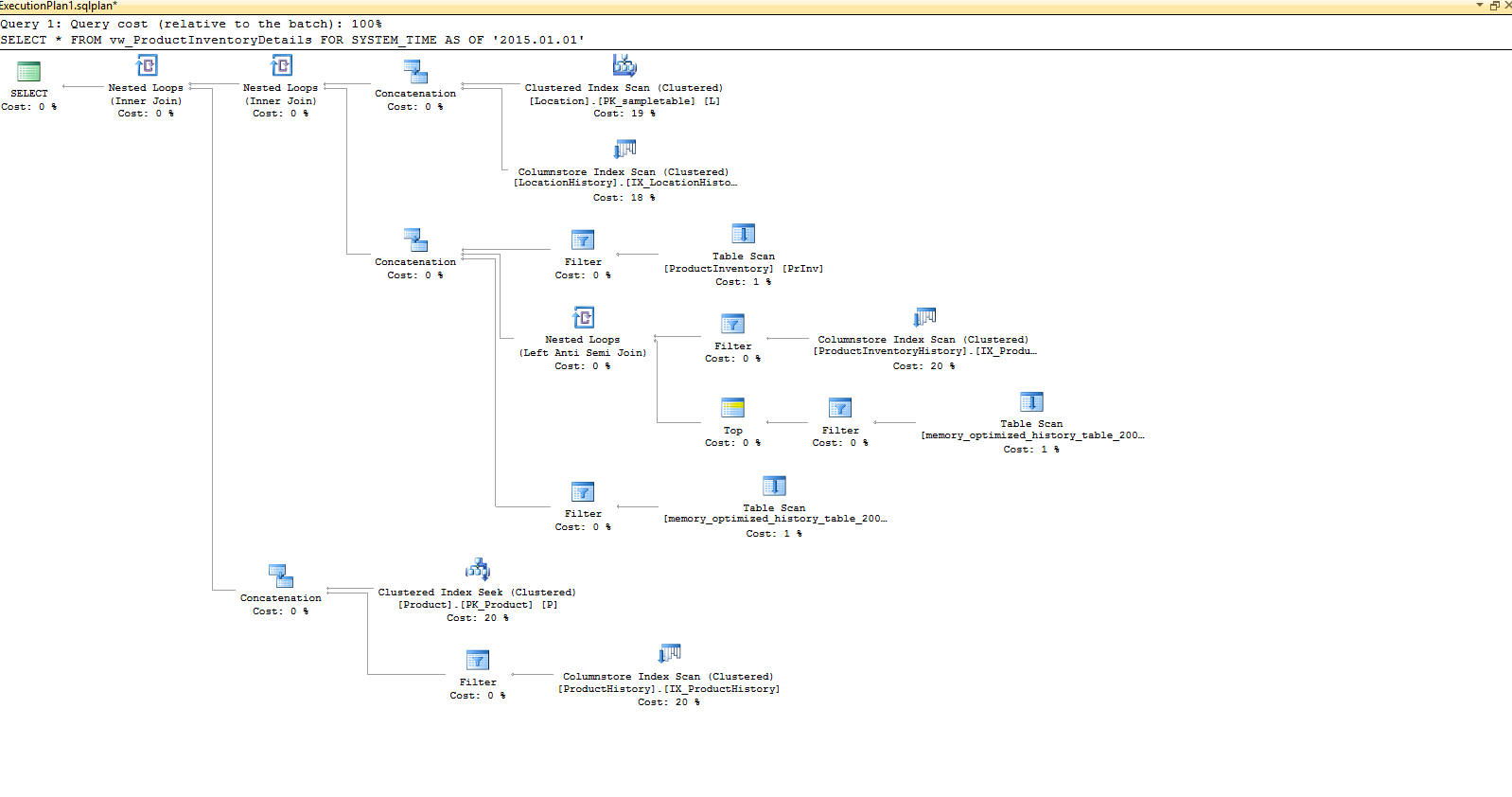
Use o código a seguir para comparar o estado do estoque de produtos entre dois pontos no tempo (há um dia e um mês atrás):
DECLARE @dayAgo datetime2 = DATEADD (day, -1, SYSUTCDATETIME());
DECLARE @monthAgo datetime2 = DATEADD (month, -1, SYSUTCDATETIME());
SELECT
inventoryDayAgo.ProductId
, inventoryDayAgo.ProductName
, inventoryDayAgo.LocationName
, inventoryDayAgo.Quantity AS QuantityDayAgo,inventoryMonthAgo.Quantity AS QuantityMonthAgo
, inventoryDayAgo.UnitPrice AS UnitPriceDayAgo, inventoryMonthAgo.UnitPrice AS UnitPriceMonthAgo
FROM vw_ProductInventoryDetails
FOR SYSTEM_TIME AS OF @dayAgo AS inventoryDayAgo
JOIN vw_ProductInventoryDetails FOR SYSTEM_TIME AS OF @monthAgo AS inventoryMonthAgo
ON inventoryDayAgo.ProductId = inventoryMonthAgo.ProductId AND inventoryDayAgo.LocationId = inventoryMonthAgo.LocationID;
Detecção de anomalias
Detecção de anomalias (ou detecção de exceções) é a identificação de itens que não estão em conformidade com um padrão esperado ou com outros itens em um conjunto de dados. Você pode usar tabelas temporais com controle da versão do sistema para detectar anomalias que ocorrem periodicamente ou de modo irregular, você pode utilizar a consulta temporal para localizar padrões específicos rapidamente. O que é uma anomalia depende do tipo de dados que você coleta e da sua lógica de negócios.
O exemplo a seguir mostra a lógica simplificada para detectar "picos" em números de vendas. Vamos supor que você trabalhe com uma tabela de tempo que coleta o histórico dos produtos comprados:
CREATE TABLE [dbo].[Product]
(
[ProdID] [int] NOT NULL PRIMARY KEY CLUSTERED
, [ProductName] [varchar](100) NOT NULL
, [DailySales] INT NOT NULL
, [ValidFrom] [datetime2] GENERATED ALWAYS AS ROW START NOT NULL
, [ValidTo] [datetime2] GENERATED ALWAYS AS ROW END NOT NULL
, PERIOD FOR SYSTEM_TIME ([ValidFrom], [ValidTo])
)
WITH( SYSTEM_VERSIONING = ON (HISTORY_TABLE = [dbo].[ProductHistory]
, DATA_CONSISTENCY_CHECK = ON ))
O diagrama a seguir mostra as compras ao longo do tempo:

Supondo que durante os dias regulares o número de produtos comprados tenha variância pequena, a seguinte consulta identifica as exceções singleton: exemplos cuja diferença, em comparação com seus vizinhos imediatos, é significativa (x2), enquanto os exemplos adjacentes não diferem significativamente (menos de 20%):
WITH CTE (ProdId, PrevValue, CurrentValue, NextValue, ValidFrom, ValidTo)
AS
(
SELECT
ProdId, LAG (DailySales, 1, 1) over (partition by ProdId order by ValidFrom) as PrevValue
, DailySales, LEAD (DailySales, 1, 1) over (partition by ProdId order by ValidFrom) as NextValue
, ValidFrom, ValidTo from Product
FOR SYSTEM_TIME ALL
)
SELECT
ProdId
, PrevValue
, CurrentValue
, NextValue
, ValidFrom
, ValidTo
, ABS (PrevValue - NextValue) / convert (float, (CASE WHEN NextValue > PrevValue THEN PrevValue ELSE NextValue END)) as PrevToNextDiff
, ABS (CurrentValue - PrevValue) / convert (float, (CASE WHEN CurrentValue > PrevValue THEN PrevValue ELSE CurrentValue END)) as CurrentToPrevDiff
, ABS (CurrentValue - NextValue) / convert (float, (CASE WHEN CurrentValue > NextValue THEN NextValue ELSE CurrentValue END)) as CurrentToNextDiff
FROM CTE
WHERE
ABS (PrevValue - NextValue) / (CASE WHEN NextValue > PrevValue THEN PrevValue ELSE NextValue END) < 0.2
AND ABS (CurrentValue - PrevValue) / (CASE WHEN CurrentValue > PrevValue THEN PrevValue ELSE CurrentValue END) > 2
AND ABS (CurrentValue - NextValue) / (CASE WHEN CurrentValue > NextValue THEN NextValue ELSE CurrentValue END) > 2;
Observação
Este exemplo é intencionalmente simplificado. Nos cenários de produção, você provavelmente usaria métodos estatísticos avançados para identificar exemplos que não seguem o padrão comum.
Dimensões de alteração lenta
Dimensões em data warehouse normalmente contêm dados relativamente estáticos sobre entidades como produtos, clientes ou locais geográficos. No entanto, alguns cenários exigem que você acompanhe as alterações de dados também nas tabelas de dimensões. Considerando que as modificações em dimensões ocorrem com muito menos frequência, de maneira imprevisível e fora do agendamento de atualização regular que se aplica a tabelas de fatos, esses tipos de tabelas de dimensões são chamados de SCD (dimensões de alteração lenta).
Há várias categorias de dimensões de alteração lenta com base em como o histórico de alterações é preservado:
- Tipo 0: o histórico não é preservado. Os atributos de dimensão refletem os valores originais.
- Tipo 1: os atributos de dimensão refletem os valores mais recentes (os valores anteriores são substituídos)
- Tipo 2: toda versão do membro da dimensão representado com uma linha separada na tabela, normalmente com colunas que representam o período de validade
- Tipo 3: manutenção de um histórico limitado para atributos selecionados usando colunas adicionais na mesma linha
- Tipo 4: manutenção do histórico na tabela separada, enquanto a tabela de dimensões original mantém as versões de membro da dimensão mais recentes (atuais)
Quando você escolhe uma estratégia SCD, é responsabilidade da camada de ETL (extração, transformação e carregamento) manter as tabelas de dimensões precisas, o que geralmente exige muito código e manutenção complexa.
As tabelas temporais com controle da versão do sistema podem ser usadas para reduzir drasticamente a complexidade do seu código, já que o histórico de dados é preservado automaticamente. Considerando sua implementação usando duas tabelas, as tabelas temporais estão mais próximas do SCD Tipo 4. No entanto, como consultas temporais permitem que você referencie apenas a tabela atual, você também pode considerar o uso de tabelas temporais em ambientes nos quais você planeja usar o SCD Tipo 2.
Para converter sua tabela de dimensões regular para SCD, crie uma ou altere uma já existente, tornando-a uma tabela temporal com controle da versão do sistema. Se sua tabela de dimensões existente contiver dados históricos, crie uma tabela separada, mova dados históricos para lá e mantenha as versões atuais de dimensão (real) em sua tabela de dimensões original. Em seguida, use sintaxe ALTER TABLE para converter sua tabela de dimensões em uma tabela temporal com controle da versão do sistema com uma tabela de histórico predefinida.
O seguinte exemplo ilustra o processo e pressupõe que a tabela de dimensões DimLocation já tenha ValidFrom e ValidTo como colunas não anuláveis datetime2, que são populadas pelo processo de ETL:
/*Move "closed" row versions into newly created history table*/
SELECT * INTO DimLocationHistory
FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
GO
/*Create clustered columnstore index which is a very good choice in DW scenarios*/
CREATE CLUSTERED COLUMNSTORE INDEX IX_DimLocationHistory ON DimLocationHistory
/*Delete previous versions from DimLocation which will become current table in temporal-system-versioning configuration*/
DELETE FROM DimLocation
WHERE ValidTo < '9999-12-31 23:59:59.99';
/*Add period definition*/
ALTER TABLE DimLocation ADD PERIOD FOR SYSTEM_TIME (ValidFrom, ValidTo);
/*Enable system-versioning and bind history table to the DimLocation*/
ALTER TABLE DimLocation SET (SYSTEM_VERSIONING = ON (HISTORY_TABLE = dbo.DimLocationHistory));
Nenhum código adicional é necessário para manter o SCD durante o processo de carregamento do data warehouse depois que você o tiver criado.
A ilustração a seguir mostra como você pode usar tabelas temporais em um cenário simples envolvendo 2 SCDs (DimLocation e DimProduct) e uma tabela de fatos.

Para usar os SCDs acima em relatórios, você precisa ajustar a consulta de modo eficaz. Por exemplo, você talvez queira calcular o total de vendas e o número médio de produtos vendidos per capita nos últimos seis meses. Ambas as métricas requerem a correlação de dados da tabela de fatos e dimensões cujos atributos importantes para a análise (DimLocation.NumOfCustomers, DimProduct.UnitPrice) podem ter sofrido alterações. A consulta a seguir calcula corretamente as métricas necessárias:
DECLARE @now datetime2 = SYSUTCDATETIME()
DECLARE @sixMonthsAgo datetime2 SET
@sixMonthsAgo = DATEADD (month, -12, SYSUTCDATETIME())
SELECT DimProduct_History.ProductId
, DimLocation_History.LocationId
, SUM(F.Quantity * DimProduct_History.UnitPrice) AS TotalAmount
, AVG (F.Quantity/DimLocation_History.NumOfCustomers) AS AverageProductsPerCapita
FROM FactProductSales F
/* find corresponding record in SCD history in last 6 months, based on matching fact */
JOIN DimLocation FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimLocation_History
ON DimLocation_History.LocationId = F.LocationId
AND F.FactDate BETWEEN DimLocation_History.ValidFrom AND DimLocation_History.ValidTo
/* find corresponding record in SCD history in last 6 months, based on matching fact */
JOIN DimProduct FOR SYSTEM_TIME BETWEEN @sixMonthsAgo AND @now AS DimProduct_History
ON DimProduct_History.ProductId = F.ProductId
AND F.FactDate BETWEEN DimProduct_History.ValidFrom AND DimProduct_History.ValidTo
WHERE F.FactDate BETWEEN @sixMonthsAgo AND @now
GROUP BY DimProduct_History.ProductId, DimLocation_History.LocationId ;
Considerações:
- Usar tabelas temporais com controle da versão do sistema para SCD será aceitável se o período de validade calculado com base no tempo de transação de banco de dados for compatível com sua lógica de negócios. Se você carregar dados com um atraso significativo, o tempo de transação poderá não ser aceitável.
- Por padrão, tabelas temporais com controle da versão do sistema não permitem a alteração de dados históricos após o carregamento (você pode modificar o histórico depois de definir SYSTEM_VERSIONING como OFF). Isso pode ser uma limitação em casos em que a alteração de dados históricos ocorre regularmente.
- Tabelas com controle temporal da versão do sistema geram a versão de linha em caso de qualquer alteração de coluna. Se desejar suprimir novas versões em determinadas alterações de coluna, você precisará incorporar essa limitação na lógica do ETL.
- Se você espera um número significativo de linhas de histórico nas tabelas SCD, considere usar um índice columnstore clusterizado como a opção de armazenamento principal para a tabela de histórico. Isso reduzirá o volume da tabela de histórico e acelerará suas consultas analíticas.
Como reparar dados corrompidos em nível de linha
Você pode confiar em dados históricos nas tabelas temporais com controle da versão do sistema para reparar rapidamente linhas individuais, retornando-as a qualquer um dos estados capturados anteriormente. Essa propriedade das tabelas temporais é útil quando você é capaz de localizar linhas afetadas e/ou quando você sabe a hora da alteração de dados indesejada, de modo que você pode executar o reparo de maneira muito eficiente sem lidar com backups.
Essa abordagem apresenta várias vantagens:
- É possível controlar o escopo do reparo com muita precisão. Os registros que não são afetados precisam permanecer no estado mais recente, o que é normalmente um requisito crítico.
- A operação é eficiente e o banco de dados permanece online para todas as cargas de trabalho usando os dados.
- A operação de reparo em si é com controle de versão. Você tem a trilha de auditoria para a operação de reparo em si, de modo que você pode analisar posteriormente o que aconteceu, se necessário.
A ação de reparo pode ser automatizada com relativa facilidade. O exemplo de código abaixo mostra o procedimento armazenado que executa o reparo de dados para a tabela Employee usada em um cenário de auditoria de dados.
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecord;
GO
CREATE PROCEDURE sp_RepairEmployeeRecord
@EmployeeID INT,
@versionNumber INT = 1
AS
;WITH History
AS
(
/* Order historical rows by their age in DESC order*/
SELECT ROW_NUMBER () OVER (PARTITION BY EmployeeID ORDER BY [ValidTo] DESC) AS RN, *
FROM Employee FOR SYSTEM_TIME ALL WHERE YEAR (ValidTo) < 9999 AND Employee.EmployeeID = @EmployeeID
)
/*Update current row by using N-th row version from history (default is 1 - i.e. last version)*/
UPDATE Employee
SET [Position] = H.[Position], [Department] = H.Department, [Address] = H.[Address], AnnualSalary = H.AnnualSalary
FROM Employee E JOIN History H ON E.EmployeeID = H.EmployeeID AND RN = @versionNumber
WHERE E.EmployeeID = @EmployeeID
Este procedimento armazenado usa @EmployeeID e @versionNumber como parâmetros de entrada. Esse procedimento restaura, por padrão, o estado de linha para a última versão do histórico (@versionNumber = 1).
A figura a seguir mostra o estado da linha antes e depois da invocação de procedimento. O retângulo vermelho marca a versão de linha atual que está incorreta, enquanto o retângulo verde marca a versão correta do histórico.

EXEC sp_RepairEmployeeRecord @EmployeeID = 1, @versionNumber = 1

Esse procedimento armazenado de reparo pode ser definido para aceitar um carimbo de data/hora exato, em vez da versão de linha. Ele restaurará a linha para qualquer versão que estava ativa para o ponto no tempo fornecido (ou seja, ponto no tempo AS OF).
DROP PROCEDURE IF EXISTS sp_RepairEmployeeRecordAsOf;
GO
CREATE PROCEDURE sp_RepairEmployeeRecordAsOf
@EmployeeID INT,
@asOf datetime2
AS
/*Update current row to the state that was actual AS OF provided date*/
UPDATE Employee
SET [Position] = History.[Position], [Department] = History.Department, [Address] = History.[Address], AnnualSalary = History.AnnualSalary
FROM Employee AS E JOIN Employee FOR SYSTEM_TIME AS OF @asOf AS History ON E.EmployeeID = History.EmployeeID
WHERE E.EmployeeID = @EmployeeID
Para a mesma amostra de dados, a imagem a seguir ilustra o cenário de reparo com a condição de tempo. Estão realçados o parâmetro @asOf, a linha selecionada no histórico que era real no ponto no tempo fornecido e, por fim, a nova versão de linha na tabela atual após a operação de reparo:
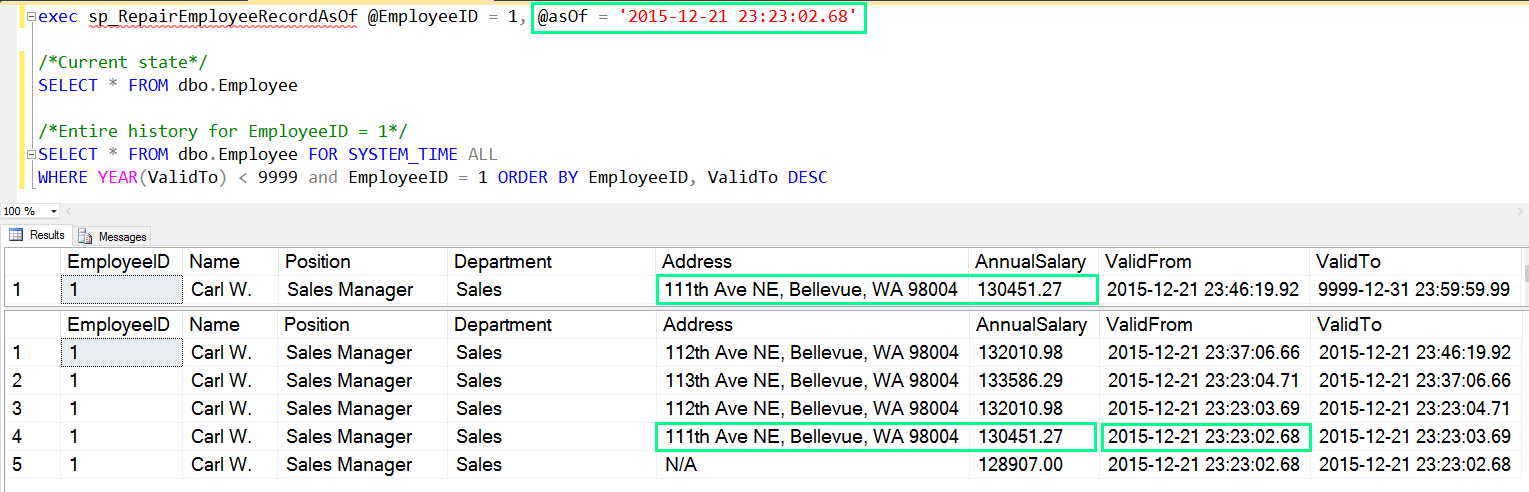
A correção de dados pode tornar-se parte do carregamento de dados em sistemas de data warehouse e de relatórios. Se um valor atualizado recentemente não estiver correto, em muitos cenários, restaurar a versão anterior do histórico será mitigação suficiente. O diagrama a seguir mostra como esse processo pode ser automatizado:

Próximas etapas
- Tabelas temporais
- Introdução a tabelas temporais com controle da versão do sistema
- Verificações de consistência do sistema de tabela temporal
- Particionamento com tabelas temporais
- Considerações e limitações da tabela temporal
- Segurança da tabela temporal
- Tabelas temporais com controle da versão do sistema com tabelas com otimização de memória
- Funções e exibições de metadados de tabela temporal
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de