Solucionar problemas de desempenho lento SQL Server causados por problemas de E/S
Aplica-se ao: SQL Server
Este artigo fornece diretrizes sobre quais problemas de E/S causam desempenho lento SQL Server e como solucionar problemas.
Definir o desempenho lento de E/S
Contadores de monitor de desempenho são usados para determinar o desempenho lento de E/S. Esses contadores medem a rapidez com que o subsistema de E/S atende a cada solicitação de E/S em média em termos de tempo de relógio. Os contadores de monitor de desempenho específicos que medem a latência de E/S no Windows são Avg Disk sec/ Read, Avg. Disk sec/Writee Avg. Disk sec/Transfer (cumulativos de leituras e gravações).
Em SQL Server, as coisas funcionam da mesma maneira. Normalmente, você analisa se SQL Server relata possíveis gargalos de E/S medidos no tempo do relógio (milissegundos). SQL Server faz solicitações de E/S para o sistema operacional chamando as funções Win32, como WriteFile(), ReadFile(), WriteFileGather()e ReadFileScatter(). Quando ele posta uma solicitação de E/S, SQL Server vezes a solicitação e relata a duração da solicitação usando tipos de espera. SQL Server usa tipos de espera para indicar esperas de E/S em diferentes locais do produto. As esperas relacionadas à E/S são:
- / PAGEIOLATCH_SHPAGEIOLATCH_EX
- WRITELOG
- IO_COMPLETION
- ASYNC_IO_COMPLETION
- BACKUPIO
Se essas esperas excederem de 10 a 15 milissegundos consistentemente, a E/S será considerada um gargalo.
Observação
Para fornecer contexto e perspectiva, no mundo da solução de problemas SQL Server, o Microsoft CSS observou casos em que uma solicitação de E/S levou mais de um segundo e até 15 segundos por sistemas de E/S de transferência precisam de otimização. Por outro lado, o Microsoft CSS viu sistemas em que a taxa de transferência está abaixo de um milissegundo/transferência. Com a tecnologia SSD/NVMe de hoje, as taxas de taxa de transferência anunciadas variam em dezenas de microssegundos por transferência. Portanto, o valor de 10 a 15 milissegundos/transferência é um limite muito aproximado que selecionamos com base na experiência coletiva entre o Windows e engenheiros SQL Server ao longo dos anos. Normalmente, quando os números ultrapassam esse limite aproximado, SQL Server usuários começam a ver latência em suas cargas de trabalho e os relatam. Em última análise, a taxa de transferência esperada de um subsistema de E/S é definida pelo fabricante, modelo, configuração, carga de trabalho e potencialmente vários outros fatores.
Metodologia
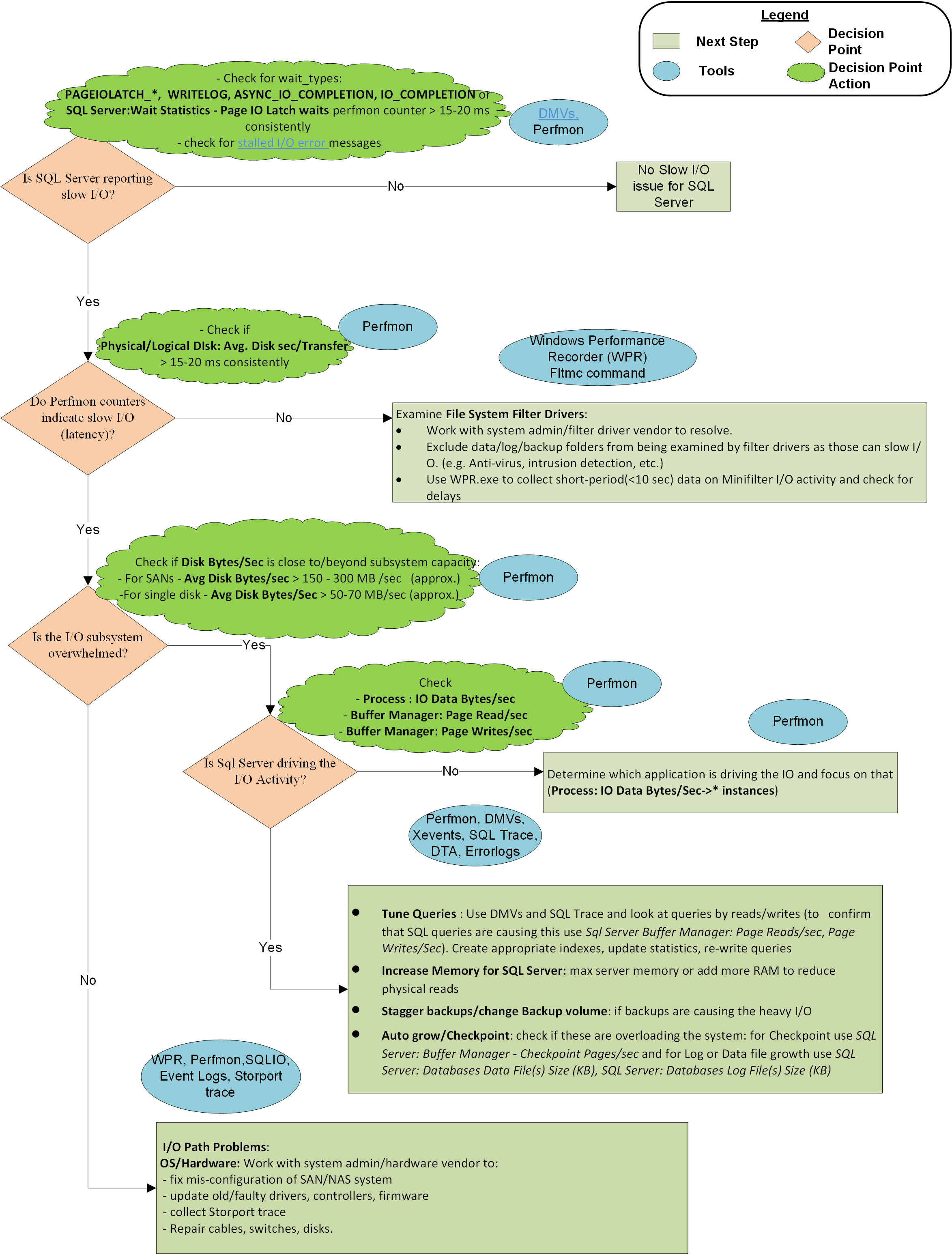
Um fluxograma no final deste artigo descreve a metodologia que o Microsoft CSS usa para abordar problemas lentos de E/S com SQL Server. Não é uma abordagem exaustiva ou exclusiva, mas tem se mostrado útil para isolar o problema e resolvê-lo.
Você pode escolher uma das duas opções a seguir para resolve o problema:
Opção 1: executar as etapas diretamente em um notebook por meio do Azure Data Studio
Observação
Antes de tentar abrir este notebook, verifique se o Azure Data Studio está instalado no computador local. Para instalá-lo, acesse Saiba como instalar o Azure Data Studio.
Opção 2: siga as etapas manualmente
A metodologia é descrita nestas etapas:
Etapa 1: SQL Server está relatando E/S lenta?
SQL Server pode relatar latência de E/S de várias maneiras:
- Tipos de espera de E/S
- DMV
sys.dm_io_virtual_file_stats - Log de erros ou log de eventos de aplicativo
Tipos de espera de E/S
Determine se há latência de E/S relatada por SQL Server tipos de espera. Os valores PAGEIOLATCH_*, WRITELOGe ASYNC_IO_COMPLETION os valores de vários outros tipos de espera menos comuns geralmente devem ficar abaixo de 10 a 15 milissegundos por solicitação de E/S. Se esses valores forem maiores consistentemente, um problema de desempenho de E/S existirá e exigirá uma investigação mais aprofundada. A consulta a seguir pode ajudá-lo a coletar essas informações de diagnóstico em seu sistema:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
for ([int]$i = 0; $i -lt 100; $i++)
{
sqlcmd -E -S $sqlserver_instance -Q "SELECT r.session_id, r.wait_type, r.wait_time as wait_time_ms`
FROM sys.dm_exec_requests r JOIN sys.dm_exec_sessions s `
ON r.session_id = s.session_id `
WHERE wait_type in ('PAGEIOLATCH_SH', 'PAGEIOLATCH_EX', 'WRITELOG', `
'IO_COMPLETION', 'ASYNC_IO_COMPLETION', 'BACKUPIO')`
AND is_user_process = 1"
Start-Sleep -s 2
}
Estatísticas de arquivo em sys.dm_io_virtual_file_stats
Para exibir a latência no nível do arquivo do banco de dados conforme relatado em SQL Server, execute a seguinte consulta:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT LEFT(mf.physical_name,100), `
ReadLatency = CASE WHEN num_of_reads = 0 THEN 0 ELSE (io_stall_read_ms / num_of_reads) END, `
WriteLatency = CASE WHEN num_of_writes = 0 THEN 0 ELSE (io_stall_write_ms / num_of_writes) END, `
AvgLatency = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE (io_stall / (num_of_reads + num_of_writes)) END,`
LatencyAssessment = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 'No data' ELSE `
CASE WHEN (io_stall / (num_of_reads + num_of_writes)) < 2 THEN 'Excellent' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 2 AND 5 THEN 'Very good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 6 AND 15 THEN 'Good' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 16 AND 100 THEN 'Poor' `
WHEN (io_stall / (num_of_reads + num_of_writes)) BETWEEN 100 AND 500 THEN 'Bad' `
ELSE 'Deplorable' END END, `
[Avg KBs/Transfer] = CASE WHEN (num_of_reads = 0 AND num_of_writes = 0) THEN 0 `
ELSE ((([num_of_bytes_read] + [num_of_bytes_written]) / (num_of_reads + num_of_writes)) / 1024) END, `
LEFT (mf.physical_name, 2) AS Volume, `
LEFT(DB_NAME (vfs.database_id),32) AS [Database Name]`
FROM sys.dm_io_virtual_file_stats (NULL,NULL) AS vfs `
JOIN sys.master_files AS mf ON vfs.database_id = mf.database_id `
AND vfs.file_id = mf.file_id `
ORDER BY AvgLatency DESC"
Examine as AvgLatency colunas e LatencyAssessment para entender os detalhes da latência.
Erro 833 relatado em Errorlog ou log de eventos de aplicativo
Em alguns casos, você pode observar o erro 833 SQL Server has encountered %d occurrence(s) of I/O requests taking longer than %d seconds to complete on file [%ls] in database [%ls] (%d) no log de erros. Você pode marcar SQL Server logs de erro em seu sistema executando o seguinte comando do PowerShell:
Get-ChildItem -Path "c:\program files\microsoft sql server\mssql*" -Recurse -Include Errorlog |
Select-String "occurrence(s) of I/O requests taking longer than Longer than 15 secs"
Além disso, para obter mais informações sobre esse erro, consulte a seção MSSQLSERVER_833 .
Etapa 2: Contadores perfmon indicam latência de E/S?
Se SQL Server relatar latência de E/S, consulte contadores de sistema operacional. Você pode determinar se há um problema de E/S examinando o contador Avg Disk Sec/Transferde latência . O snippet de código a seguir indica uma maneira de coletar essas informações por meio do PowerShell. Ele reúne contadores em todos os volumes de disco: "_total". Altere para um volume de unidade específico (por exemplo, "D:"). Para localizar quais volumes hospedam seus arquivos de banco de dados, execute a seguinte consulta em seu SQL Server:
#replace with server\instance or server for default instance
$sqlserver_instance = "server\instance"
sqlcmd -E -S $sqlserver_instance -Q "SELECT DISTINCT LEFT(volume_mount_point, 32) AS volume_mount_point `
FROM sys.master_files f `
CROSS APPLY sys.dm_os_volume_stats(f.database_id, f.file_id) vs"
Reúna Avg Disk Sec/Transfer métricas em seu volume de opções:
clear
$cntr = 0
# replace with your server name, unless local computer
$serverName = $env:COMPUTERNAME
# replace with your volume name - C: , D:, etc
$volumeName = "_total"
$Counters = @(("\\$serverName" +"\LogicalDisk($volumeName)\Avg. disk sec/transfer"))
$disksectransfer = Get-Counter -Counter $Counters -MaxSamples 1
$avg = $($disksectransfer.CounterSamples | Select-Object CookedValue).CookedValue
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 30 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 5))
turn = $cntr = $cntr +1
running_avg = [Math]::Round(($avg = (($_.CookedValue + $avg) / 2)), 5)
} | Format-Table
}
}
write-host "Final_Running_Average: $([Math]::Round( $avg, 5)) sec/transfer`n"
if ($avg -gt 0.01)
{
Write-Host "There ARE indications of slow I/O performance on your system"
}
else
{
Write-Host "There is NO indication of slow I/O performance on your system"
}
Se os valores desse contador estiverem consistentemente acima de 10 a 15 milissegundos, você precisará examinar ainda mais o problema. Picos ocasionais não contam na maioria dos casos, mas certifique-se de marcar a duração de um pico. Se o pico durou um minuto ou mais, é mais um planalto do que um pico.
Se os contadores do Monitor de Desempenho não relatarem latência, mas SQL Server o fizerem, o problema será entre SQL Server e o Gerenciador de Partições, ou seja, filtrar drivers. O Gerenciador de Partições é uma camada de E/S em que o sistema operacional coleta contadores Perfmon . Para resolver a latência, verifique as exclusões adequadas de drivers de filtro e resolve filtrar problemas do driver. Os drivers de filtro são usados por programas como software antivírus, soluções de backup, criptografia, compactação e assim por diante. Você pode usar esse comando para listar drivers de filtro nos sistemas e nos volumes aos quais eles se anexam. Em seguida, você pode pesquisar os nomes do driver e os fornecedores de software no artigo Altitudes de filtro alocadas .
fltmc instances
Para obter mais informações, confira Como escolher o software antivírus para ser executado em computadores que estão executando SQL Server.
Evite usar o EFS (Encrypting File System) e a compactação do sistema de arquivos porque eles fazem com que a E/S assíncrona se torne síncrona e, portanto, mais lenta. Para obter mais informações, confira O E/S do disco assíncrono é exibido como síncrono no artigo do Windows .
Etapa 3: o subsistema de E/S está sobrecarregado além da capacidade?
Se SQL Server e o sistema operacional indicarem que o subsistema de E/S é lento, marcar se a causa for o sistema sendo sobrecarregado além da capacidade. Você pode marcar capacidade olhando para contadores Disk Bytes/Secde E/S , Disk Read Bytes/Secou Disk Write Bytes/Sec. Certifique-se de marcar com o administrador do sistema ou o fornecedor de hardware para as especificações de taxa de transferência esperadas para seu SAN (ou outro subsistema de E/S). Por exemplo, você não pode enviar mais de 200 MB/s de E/S por meio de um cartão HBA de 2 GB/s ou uma porta dedicada de 2 GB/s em um comutador SAN. A capacidade de taxa de transferência esperada definida por um fabricante de hardware define como você procede daqui.
clear
$serverName = $env:COMPUTERNAME
$Counters = @(
("\\$serverName" +"\PhysicalDisk(*)\Disk Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Read Bytes/sec"),
("\\$serverName" +"\PhysicalDisk(*)\Disk Write Bytes/sec")
)
Get-Counter -Counter $Counters -SampleInterval 2 -MaxSamples 20 | ForEach-Object {
$_.CounterSamples | ForEach-Object {
[pscustomobject]@{
TimeStamp = $_.TimeStamp
Path = $_.Path
Value = ([Math]::Round($_.CookedValue, 3)) }
}
}
Etapa 4: SQL Server está conduzindo a atividade de E/S pesada?
Se o subsistema de E/S estiver sobrecarregado além da capacidade, descubra se SQL Server é o culpado olhando Buffer Manager: Page Reads/Sec para (culpado mais comum) e Page Writes/Sec (muito menos comum) para a instância específica. Se SQL Server for o main o driver de E/S e o volume de E/S estiverem além do que o sistema pode lidar, trabalhe com as equipes de Desenvolvimento de Aplicativos ou o fornecedor de aplicativos para:
- Ajuste consultas, por exemplo: índices melhores, atualizar estatísticas, reescrever consultas e redesenhar o banco de dados.
- Aumente a memória máxima do servidor ou adicione mais RAM no sistema. Mais RAM armazenará em cache mais dados ou páginas de índice sem releitura frequente do disco, o que reduzirá a atividade de E/S.
Causas
Em geral, os seguintes problemas são os motivos de alto nível pelos quais SQL Server consultas sofrem de latência de E/S:
Problemas de hardware:
Uma configuração incorreta de SAN (comutador, cabos, HBA, armazenamento)
Capacidade de E/S excedida (desequilibrada em toda a rede SAN, não apenas no armazenamento de back-end)
Drivers ou problemas de firmware
Os fornecedores de hardware e/ou administradores do sistema precisam ser contratados nesta fase.
Problemas de consulta: SQL Server está saturando volumes de disco com solicitações de E/S e está empurrando o subsistema de E/S para além da capacidade, o que faz com que as taxas de transferência de E/S sejam altas. Nesse caso, a solução é localizar as consultas que estão causando um alto número de leituras lógicas (ou gravações) e ajustar essas consultas para minimizar índices apropriados de E/S de disco é a primeira etapa para fazer isso. Além disso, mantenha as estatísticas atualizadas, pois elas fornecem ao otimizador de consulta informações suficientes para escolher o melhor plano. Além disso, o design incorreto do banco de dados e o design de consulta podem levar a um aumento nos problemas de E/S. Portanto, reprojetar consultas e, às vezes, tabelas podem ajudar com e/S aprimorados.
Drivers de filtro: A resposta de E/S SQL Server pode ser severamente afetada se os drivers de filtro do sistema de arquivos processarem tráfego de E/S pesado. As exclusões de arquivo adequadas da verificação antivírus e do design correto do driver de filtro por fornecedores de software são recomendadas para evitar impacto no desempenho de E/S.
Outros aplicativos: Outro aplicativo no mesmo computador com SQL Server pode saturar o caminho de E/S com solicitações excessivas de leitura ou gravação. Essa situação pode empurrar o subsistema de E/S para além dos limites de capacidade e causar lentidão de E/S para SQL Server. Identifique o aplicativo e ajuste-o ou mova-o para outro lugar para eliminar seu impacto na pilha de E/S.
Representação gráfica da metodologia
Informações sobre tipos de espera relacionados a E/S
Veja a seguir as descrições dos tipos de espera comuns observados em SQL Server quando os problemas de E/S do disco são relatados.
PAGEIOLATCH_EX
Ocorre quando uma tarefa está esperando em uma trava para uma página de dados ou índice (buffer) em uma solicitação de E/S. A solicitação de trava está no modo Exclusivo. Um modo Exclusivo é usado quando o buffer está sendo gravado em disco. Longas esperas podem indicar problemas com o subsistema de disco.
PAGEIOLATCH_SH
Ocorre quando uma tarefa está esperando em uma trava para uma página de dados ou índice (buffer) em uma solicitação de E/S. A solicitação de trava está no modo Compartilhado. O modo compartilhado é usado quando o buffer está sendo lido do disco. Longas esperas podem indicar problemas com o subsistema de disco.
PAGEIOLATCH_UP
Ocorre quando uma tarefa está esperando em uma trava para um buffer em uma solicitação de E/S. A solicitação de trava está no modo Atualização. Longas esperas podem indicar problemas com o subsistema de disco.
WRITELOG
Ocorre quando uma tarefa está aguardando a conclusão de uma liberação de log de transações. Uma liberação ocorre quando o Log Manager grava seu conteúdo temporário em disco. Operações comuns que causam descargas de log são confirmações de transação e pontos de verificação.
As razões comuns para longas esperas WRITELOG são:
Latência do disco de log de transações: essa é a causa mais comum de
WRITELOGesperas. Geralmente, a recomendação é manter os dados e os arquivos de log em volumes separados. As gravações de log de transação são gravações sequenciais durante a leitura ou gravação de dados de um arquivo de dados é aleatória. A combinação de dados e arquivos de log em um volume de unidade (especialmente unidades de disco giratório convencionais) causará movimento excessivo da cabeça de disco.VLFs demais: muitos VLFs (arquivos de log virtual) podem causar
WRITELOGesperas. Muitas VLFs podem causar outros tipos de problemas, como recuperação longa.Muitas transações pequenas: embora transações grandes possam levar ao bloqueio, muitas transações pequenas podem levar a outro conjunto de problemas. Se você não iniciar explicitamente uma transação, qualquer inserção, exclusão ou atualização resultará em uma transação (chamamos essa transação automática). Se você fizer 1.000 inserções em um loop, haverá 1.000 transações geradas. Cada transação neste exemplo precisa ser confirmada, o que resulta em uma liberação de log de transações e 1.000 liberações de transações. Quando possível, agrupar atualização individual, excluir ou inserir em uma transação maior para reduzir as liberações de log de transações e aumentar o desempenho. Essa operação pode levar a menos
WRITELOGesperas.Problemas de agendamento fazem com que os threads do Log Writer não sejam agendados rapidamente o suficiente: antes de SQL Server 2016, um único thread do Log Writer executou todas as gravações de log. Se houvesse problemas com o agendamento de threads (por exemplo, CPU alta), tanto o thread do Log Writer quanto as descargas de log poderiam ficar atrasados. Em SQL Server 2016, até quatro threads do Log Writer foram adicionados para aumentar a taxa de transferência de gravação de log. Confira SQL 2016 – Ele só é executado mais rápido: vários trabalhos de gravador de log. No SQL Server 2019, foram adicionados até oito threads do Log Writer, o que melhora ainda mais a taxa de transferência. Além disso, em SQL Server 2019, cada thread de trabalho regular pode fazer gravações de log diretamente em vez de postar no thread do gravador de log. Com essas melhorias,
WRITELOGas esperas raramente seriam disparadas por problemas de agendamento.
ASYNC_IO_COMPLETION
Ocorre quando algumas das seguintes atividades de E/S acontecem:
- O Provedor de Inserção em Massa ("Inserir Em Massa") usa esse tipo de espera ao executar E/S.
- Lendo Arquivo desfazer no LogShipping e direcionando E/S assíncrona para envio de logs.
- Lendo os dados reais dos arquivos de dados durante um backup de dados.
IO_COMPLETION
Ocorre enquanto aguarda a conclusão das operações de E/S. Esse tipo de espera geralmente envolve E/S não relacionados a páginas de dados (buffers). Os exemplos incluem:
- A leitura e gravação de classificação/hash resulta de/para disco durante um vazamento (marcar desempenho do armazenamento temporário).
- Leitura e gravação de spools ansiosos em disco (marcar armazenamento tempdb).
- Leitura de blocos de log do log de transações (durante qualquer operação que faça com que o log seja lido do disco - por exemplo, recuperação).
- Lendo uma página do disco quando o banco de dados ainda não está configurado.
- Copiar páginas em um banco de dados instantâneo (Copiar em Gravação).
- Fechando o arquivo de banco de dados e a descompressão do arquivo.
BACKUPIO
Ocorre quando uma tarefa de backup aguarda dados ou aguarda um buffer para armazenar dados. Esse tipo não é típico, exceto quando uma tarefa está aguardando uma montagem de fita.
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de