Tutorial: persistir dados em um aplicativo de contêiner usando volumes no VS Code
Neste tutorial, você aprenderá a persistir dados em um aplicativo de contêiner. Quando você os executa ou atualiza, os dados permanecem disponíveis. Há dois tipos principais de volumes usados para persistir dados. Este tutorial se concentra em volumes nomeados.
Você também aprenderá sobre montagens de associação, que controlam o ponto de montagem exato no host. Você pode usar montagens de associação para persistir dados, mas também pode adicionar mais dados em contêineres. Ao trabalhar em um aplicativo, você pode usar uma montagem de associação para montar o código-fonte no contêiner e permitir que ele veja alterações de código, responda e permita que você veja as alterações imediatamente.
Este tutorial também apresenta as camadas de imagem, o cache de camadas e os builds de vários estágios.
Neste tutorial, você aprenderá como:
- Entender os dados entre contêineres.
- Persistir dados usando volumes nomeados.
- Usar montagens de associação.
- Exibir a camada de imagens.
- Armazenar dependências em cache.
- Entender os builds de vários estágios.
Pré-requisitos
Este tutorial continua o tutorial anterior, Criar e compartilhar um aplicativo do Docker com Visual Studio Code. Comece com ele, que inclui pré-requisitos.
Entender os dados entre contêineres
Nesta seção, você iniciará dois contêineres e criará um arquivo em cada um. Os arquivos criados em um contêiner não ficam disponíveis em outro.
Inicie um contêiner
ubuntuusando este comando:docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Esse comando invoca dois comandos usando
&&. A primeira parte escolhe um número aleatório e o grava em/data.txt. O segundo comando inspeciona um arquivo para manter o contêiner em execução.No VS Code, na área do Docker, clique com o botão direito do mouse no contêiner do Ubuntu e selecione Anexar Shell.
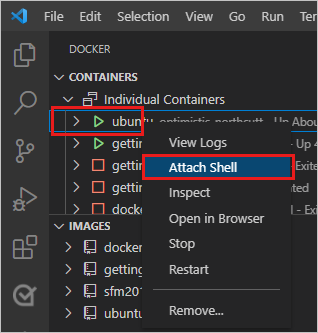
É aberto um terminal que está executando um shell no contêiner do Ubuntu.
Execute o comando a seguir para ver o conteúdo do arquivo
/data.txt.cat /data.txtO terminal mostra um número entre 1 e 10000.
Para usar a linha de comando para ver esse resultado, obtenha a ID do contêiner usando o comando
docker pse execute o comando a seguir.docker exec <container-id> cat /data.txtInicie outro contêiner
ubuntu.docker run -d ubuntu bash -c "shuf -i 1-10000 -n 1 -o /data.txt && tail -f /dev/null"Use este comando para examinar o conteúdo da pasta.
docker run -it ubuntu ls /Não deve haver nenhum arquivo
data.txtlá, pois ele foi gravado no espaço temporário apenas para o primeiro contêiner.Selecione esses dois contêineres do Ubuntu. Clique com o botão direito do mouse e selecione Remover. Na linha de comando, você pode removê-los usando o comando
docker rm -f.
Persistir dados de tarefas pendentes usando volumes nomeados
Por padrão, o aplicativo de tarefas pendentes armazena dados em um Banco de Dados SQLite em /etc/todos/todo.db.
O Banco de Dados SQLite é um banco de dados relacional que armazena dados de um só arquivo.
Essa abordagem funciona para projetos pequenos.
Você pode persistir o arquivo no host. Quando você o disponibiliza para o próximo contêiner, o aplicativo pode continuar de onde parou. Ao criar um volume e anexar, ou montar, na pasta na qual os dados estão armazenados, você pode persistir os dados. O contêiner grava no arquivo todo.db e esses dados persistem no host no volume.
Para esta seção, use um volume nomeado. O Docker mantém o local físico do volume no disco. Consulte o nome do volume e o Docker fornecerá os dados corretos.
Crie um volume usando o comando
docker volume create.docker volume create todo-dbEm CONTÊINERES, selecione getting-started e clique com o botão direito do mouse. Selecione Parar para interromper o contêiner do aplicativo.
Para interromper o contêiner da linha de comando, use o comando
docker stop.Inicie o contêiner getting-started usando o comando a seguir.
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedO parâmetro de volume especifica o volume a ser montado e o local,
/etc/todos.Atualize o navegador para recarregar o aplicativo. Se você fechou a janela do navegador, vá para
http://localhost:3000/. Adicione alguns itens à lista de tarefas pendentes.
Remova o contêiner getting-start do aplicativo de lista de tarefas. Clique com o botão direito do mouse no contêiner na área do Docker e selecione Remover ou use os comandos
docker stopedocker rm.Inicie um novo contêiner usando o mesmo comando:
docker run -dp 3000:3000 -v todo-db:/etc/todos getting-startedEsse comando monta a mesma unidade de antes. Atualize seu navegador. Os itens que você adicionou ainda estão na lista.
Remova o contêiner getting-started novamente.
Volumes nomeados e montagens de associação, abordados abaixo, são os principais tipos de volumes compatíveis com uma instalação padrão do mecanismo do Docker.
| Propriedade | Volumes nomeados | Montagens por associação |
|---|---|---|
| Local do host | O Docker escolhe | Você controla |
Exemplo de montagem (usando -v) |
my-volume:/usr/local/data | /path/to/data:/usr/local/data |
| Popula o novo volume com o conteúdo do contêiner | Sim | No |
| Dá suporte a drivers de volume | Yes | No |
Muitos plug-ins de driver de volume estão disponíveis para dar suporte a NFS, SFTP, NetApp e muito mais. Esses plug-ins são especialmente importantes para executar contêineres em vários hosts em um ambiente clusterizado, como Swarm ou Kubernetes.
Se você se pergunta onde o Docker realmente armazena seus dados, execute o comando a seguir.
docker volume inspect todo-db
Examine a saída, semelhante a este resultado.
[
{
"CreatedAt": "2019-09-26T02:18:36Z",
"Driver": "local",
"Labels": {},
"Mountpoint": "/var/lib/docker/volumes/todo-db/_data",
"Name": "todo-db",
"Options": {},
"Scope": "local"
}
]
O Mountpoint é o local real em que os dados são armazenados.
Na maioria dos computadores, você precisa de acesso à raiz para acessar esse diretório do host.
Usar montagens de associação
Com as montagens de associação, você controla o ponto de montagem exato no host. Essa abordagem persiste dados, mas geralmente é usada para fornecer mais dados para contêineres. Você pode usar uma montagem de associação para montar o código-fonte no contêiner e permitir que ele veja alterações de código, responda e permita que você veja as alterações imediatamente.
Para executar o contêiner para dar suporte a um fluxo de trabalho de desenvolvimento, você executará as seguintes etapas:
Remova todos os contêineres
getting-started.Na pasta
app, execute o comando a seguir.docker run -dp 3000:3000 -w /app -v ${PWD}:/app node:20-alpine sh -c "yarn install && yarn run dev"Esse comando contém os parâmetros a seguir.
-dp 3000:3000O mesmo que antes. Execute no modo desanexado e crie um mapeamento de portas.-w /appDiretório de trabalho dentro do contêiner.-v ${PWD}:/app"Montar com associação do diretório atual do host no contêiner ao diretório/app.node:20-alpineA imagem a ser usada. Essa é a imagem base do aplicativo do Dockerfile.sh -c "yarn install && yarn run dev"Um comando. Ele inicia um shell usandoshe executayarn installpara instalar todas as dependências. Em seguida, ele executayarn run dev. Se você olhar nopackage.json, o scriptdevestá iniciandonodemon.
Você pode inspecionar os logs usando
docker logs.docker logs -f <container-id>$ nodemon src/index.js [nodemon] 2.0.20 [nodemon] to restart at any time, enter `rs` [nodemon] watching path(s): *.* [nodemon] watching extensions: js,mjs,json [nodemon] starting `node src/index.js` Using sqlite database at /etc/todos/todo.db Listening on port 3000Quando você vê a entrada final nesta lista, o aplicativo está em execução.
Quando terminar de inspecionar os logs, selecione qualquer tecla na janela do terminal ou selecione Ctrl+C em uma janela externa.
No VS Code, abra src/static/js/app.js. Altere o texto do botão Adicionar Item na linha 109.
- {submitting ? 'Adding...' : 'Add Item'} + {submitting ? 'Adding...' : 'Add'}Salve sua alteração.
Atualize seu navegador. Você deverá ver a alteração.

Exibir camadas de imagens
Você pode examinar as camadas que compõem uma imagem.
Execute o comando docker image history para ver o comando usado para criar cada camada dentro de uma imagem.
Use
docker image historypara ver as camadas na imagem getting-started que você criou anteriormente no tutorial.docker image history getting-startedO resultado deve ser semelhante a essa saída.
IMAGE CREATED CREATED BY SIZE COMMENT a78a40cbf866 18 seconds ago /bin/sh -c #(nop) CMD ["node" "/app/src/ind… 0B f1d1808565d6 19 seconds ago /bin/sh -c yarn install --production 85.4MB a2c054d14948 36 seconds ago /bin/sh -c #(nop) COPY dir:5dc710ad87c789593… 198kB 9577ae713121 37 seconds ago /bin/sh -c #(nop) WORKDIR /app 0B b95baba1cfdb 13 days ago /bin/sh -c #(nop) CMD ["node"] 0B <missing> 13 days ago /bin/sh -c #(nop) ENTRYPOINT ["docker-entry… 0B <missing> 13 days ago /bin/sh -c #(nop) COPY file:238737301d473041… 116B <missing> 13 days ago /bin/sh -c apk add --no-cache --virtual .bui… 5.35MB <missing> 13 days ago /bin/sh -c #(nop) ENV YARN_VERSION=1.21.1 0B <missing> 13 days ago /bin/sh -c addgroup -g 1000 node && addu… 74.3MB <missing> 13 days ago /bin/sh -c #(nop) ENV NODE_VERSION=12.14.1 0B <missing> 13 days ago /bin/sh -c #(nop) CMD ["/bin/sh"] 0B <missing> 13 days ago /bin/sh -c #(nop) ADD file:e69d441d729412d24… 5.59MBCada uma das linhas representa uma camada na imagem. A saída mostra a base na parte inferior, com a camada mais recente na parte superior. Usando essas informações, você pode ver o tamanho de cada camada, ajudando a diagnosticar imagens grandes.
Várias das linhas estão truncadas. Se você adicionar o parâmetro
--no-trunc, receberá a saída completa.docker image history --no-trunc getting-started
Armazenar dependências em cache
Depois que uma camada é alterada, todas as camadas downstream também precisam ser recriadas. Aqui está o Dockerfile novamente:
FROM node:20-alpine
WORKDIR /app
COPY . .
RUN yarn install --production
CMD ["node", "/app/src/index.js"]
Cada comando no Dockerfile se torna uma nova camada na imagem.
Para minimizar o número de camadas, você pode reestruturar o Dockerfile para dar suporte ao cache de dependências.
Para aplicativos baseados em Node, essas dependências são definidas no arquivo package.json.
A abordagem é copiar somente esse arquivo primeiro, instalar as dependências e, depois, copiar todo o resto.
O processo só recriará as dependências do yarn se houver uma alteração no package.json.
Atualize o Dockerfile para copiar no primeiro
package.json, instale as dependências e copie todo o resto. Este é o novo arquivo:FROM node:20-alpine WORKDIR /app COPY package.json yarn.lock ./ RUN yarn install --production COPY . . CMD ["node", "/app/src/index.js"]Compile uma nova imagem usando
docker build.docker build -t getting-started .Você verá uma saída semelhante aos seguintes resultados:
Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:12-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Running in d53a06c9e4c2 yarn install v1.17.3 [1/4] Resolving packages... [2/4] Fetching packages... info fsevents@1.2.9: The platform "linux" is incompatible with this module. info "fsevents@1.2.9" is an optional dependency and failed compatibility check. Excluding it from installation. [3/4] Linking dependencies... [4/4] Building fresh packages... Done in 10.89s. Removing intermediate container d53a06c9e4c2 ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> a239a11f68d8 Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 49999f68df8f Removing intermediate container 49999f68df8f ---> e709c03bc597 Successfully built e709c03bc597 Successfully tagged getting-started:latestTodas as camadas foram recompiladas. Esse resultado é esperado porque você alterou o Dockerfile.
Faça uma alteração em src/static/index.html. Por exemplo, altere o título para "O maravilhoso aplicativo de lista de tarefas".
Compile a imagem do Docker usando
docker buildnovamente. Desta vez, a saída deve ser um pouco diferente.Sending build context to Docker daemon 219.1kB Step 1/6 : FROM node:12-alpine ---> b0dc3a5e5e9e Step 2/6 : WORKDIR /app ---> Using cache ---> 9577ae713121 Step 3/6 : COPY package* yarn.lock ./ ---> Using cache ---> bd5306f49fc8 Step 4/6 : RUN yarn install --production ---> Using cache ---> 4e68fbc2d704 Step 5/6 : COPY . . ---> cccde25a3d9a Step 6/6 : CMD ["node", "/app/src/index.js"] ---> Running in 2be75662c150 Removing intermediate container 2be75662c150 ---> 458e5c6f080c Successfully built 458e5c6f080c Successfully tagged getting-started:latestComo você está usando o cache de build, ele deve ser muito mais rápido.
Builds de várias fases
Builds de várias fases são uma ferramenta incrivelmente poderosa para ajudar a usar várias fases para criar uma imagem. Eles têm várias vantagens:
- Separar dependências de tempo de build de dependências de runtime
- Reduzir o tamanho geral da imagem enviando apenas o que seu aplicativo precisa executar
Esta seção fornece exemplos breves.
Exemplo de Maven/Tomcat
Quando você compila aplicativos baseados em Java, um JDK é necessário para compilar o código-fonte em código de bytes Java. Esse JDK não é necessário na produção. Talvez você esteja usando ferramentas como Maven ou Gradle para ajudar a compilar o aplicativo. Essas ferramentas também não são necessárias na imagem final.
FROM maven AS build
WORKDIR /app
COPY . .
RUN mvn package
FROM tomcat
COPY --from=build /app/target/file.war /usr/local/tomcat/webapps
Este exemplo usa uma fase, build, para executar o build de Java real usando o Maven.
A segunda fase, começando em "FROM tomcat", copia arquivos da fase build.
A imagem final é apenas a última fase que está sendo criada, que pode ser substituída usando o parâmetro --target.
Exemplo do React
Ao compilar aplicativos React, você precisa de um ambiente Node para compilar o código JavaScript, folhas de estilos SASS e muito mais em HTML estático, JavaScript e CSS. Se você não estiver fazendo a renderização do lado do servidor, não precisará de um ambiente Node para o build de produção.
FROM node:20-alpine AS build
WORKDIR /app
COPY package* yarn.lock ./
RUN yarn install
COPY public ./public
COPY src ./src
RUN yarn run build
FROM nginx:alpine
COPY --from=build /app/build /usr/share/nginx/html
Este exemplo usa uma imagem node:20 para executar o build, o que maximiza o cache de camadas e copia a saída em um contêiner nginx.
Limpar os recursos
Mantenha tudo o que você fez até agora para continuar esta série de tutoriais.
Próximas etapas
Você aprendeu sobre as opções para persistir dados para aplicativos de contêiner.
O que você deseja fazer em seguida?
Trabalhar com vários contêineres usando o Docker Compose:
Criar aplicativos de vários contêineres com o MySQL e o Docker Compose
Implantar nos Aplicativos de Contêiner do Azure:
Implantar no Serviço de Aplicativo do Azure
Comentários
Em breve: Ao longo de 2024, eliminaremos os problemas do GitHub como o mecanismo de comentários para conteúdo e o substituiremos por um novo sistema de comentários. Para obter mais informações, consulte https://aka.ms/ContentUserFeedback.
Enviar e exibir comentários de