Esta arquitetura de referência mostra como executar a pontuação em lote com modelos R usando o Lote do Azure. O Azure Batch funciona bem com cargas de trabalho intrinsecamente paralelas e inclui agendamento de tarefas e gerenciamento de computação. A inferência de lote (pontuação) é amplamente utilizada para segmentar clientes, prever vendas, prever comportamentos de clientes, prever manutenção ou melhorar a segurança cibernética.
Transfira um ficheiro do Visio desta arquitetura.
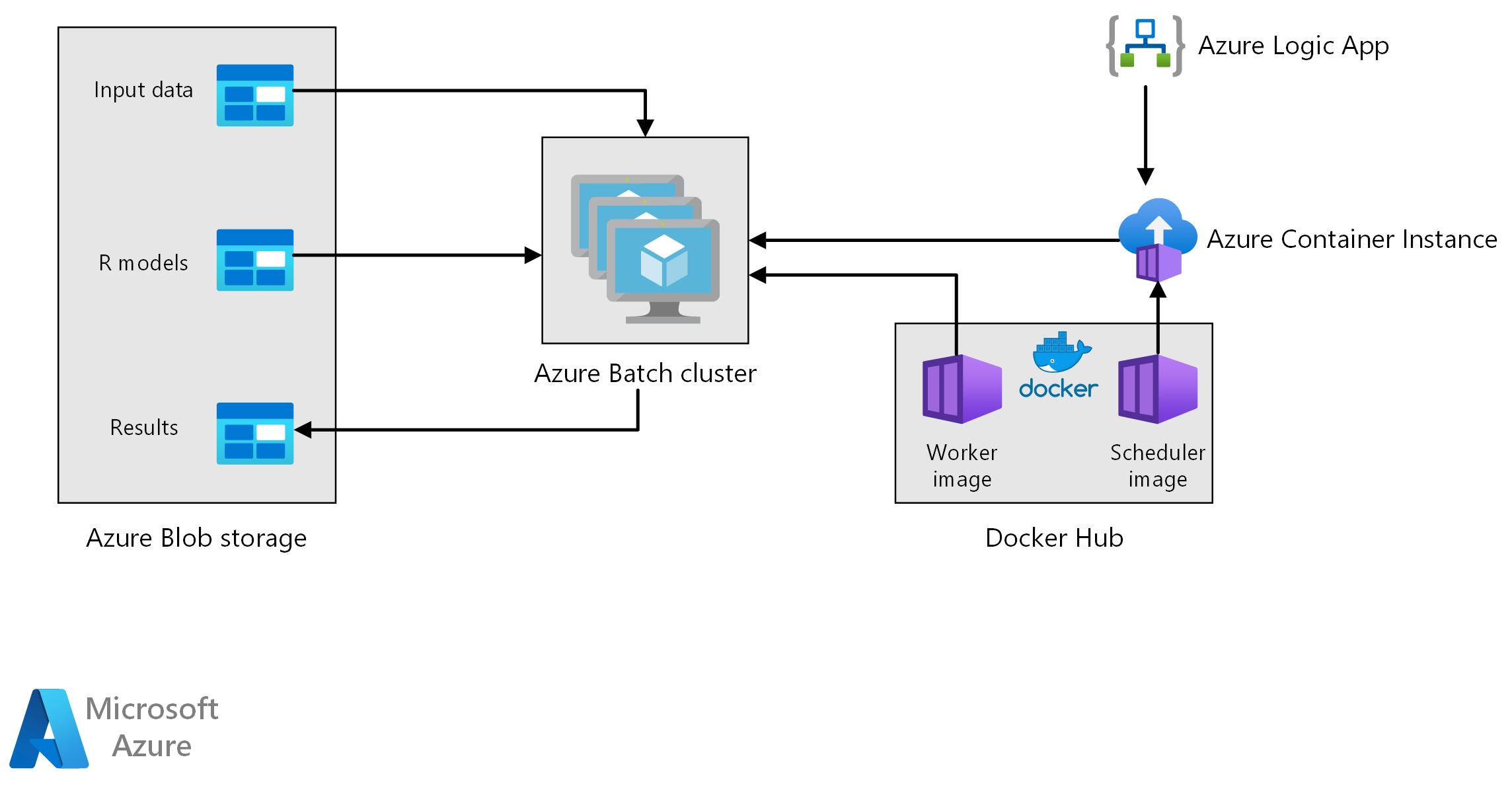
Fluxo de Trabalho
Esta arquitetura é composta pelos seguintes componentes.
O Azure Batch executa trabalhos de geração de previsão em paralelo em um cluster de máquinas virtuais. As previsões são feitas usando modelos de aprendizado de máquina pré-treinados implementados no R. O Azure Batch pode dimensionar automaticamente o número de VMs com base no número de trabalhos enviados ao cluster. Em cada nó, um script R é executado dentro de um contêiner do Docker para pontuar dados e gerar previsões.
O Armazenamento de Blobs do Azure armazena os dados de entrada, os modelos de aprendizado de máquina pré-treinados e os resultados de previsão. Ele oferece armazenamento econômico para o desempenho que essa carga de trabalho exige.
As Instâncias de Contêiner do Azure fornecem computação sem servidor sob demanda. Nesse caso, uma instância de contêiner é implantada em um cronograma para disparar os trabalhos em lote que geram as previsões. Os trabalhos em lote são acionados a partir de um script R usando o pacote doAzureParallel . A instância do contêiner é desligada automaticamente assim que os trabalhos são concluídos.
Os Aplicativos Lógicos do Azure acionam todo o fluxo de trabalho implantando as instâncias de contêiner em uma agenda. Um conector de Instâncias de Contêiner do Azure em Aplicativos Lógicos permite que uma instância seja implantada em uma variedade de eventos de gatilho.
Componentes
Detalhes da solução
Embora o cenário a seguir seja baseado na previsão de vendas em lojas de varejo, sua arquitetura pode ser generalizada para qualquer cenário que exija a geração de previsões em maior escala usando modelos R. Uma implementação de referência para essa arquitetura está disponível no GitHub.
Potenciais casos de utilização
Uma rede de supermercados precisa prever as vendas de produtos para o próximo trimestre. A previsão permite que a empresa gerencie melhor sua cadeia de suprimentos e garanta que possa atender à demanda por produtos em cada uma de suas lojas. A empresa atualiza suas previsões todas as semanas, à medida que novos dados de vendas da semana anterior ficam disponíveis e a estratégia de marketing de produto para o próximo trimestre é definida. As previsões quantitativas são geradas para estimar a incerteza das previsões de vendas individuais.
O processamento envolve as seguintes etapas:
Um aplicativo lógico do Azure dispara o processo de geração de previsão uma vez por semana.
O aplicativo lógico inicia uma Instância de Contêiner do Azure executando o contêiner do Docker do agendador, que dispara os trabalhos de pontuação no cluster em lote.
Os trabalhos de pontuação são executados em paralelo nos nós do cluster em lote. Cada nó:
Puxa a imagem do Docker do trabalhador e inicia um contêiner.
Lê dados de entrada e modelos R pré-treinados do armazenamento de Blob do Azure.
Pontua os dados para produzir previsões.
Grava os resultados da previsão no armazenamento de blobs.
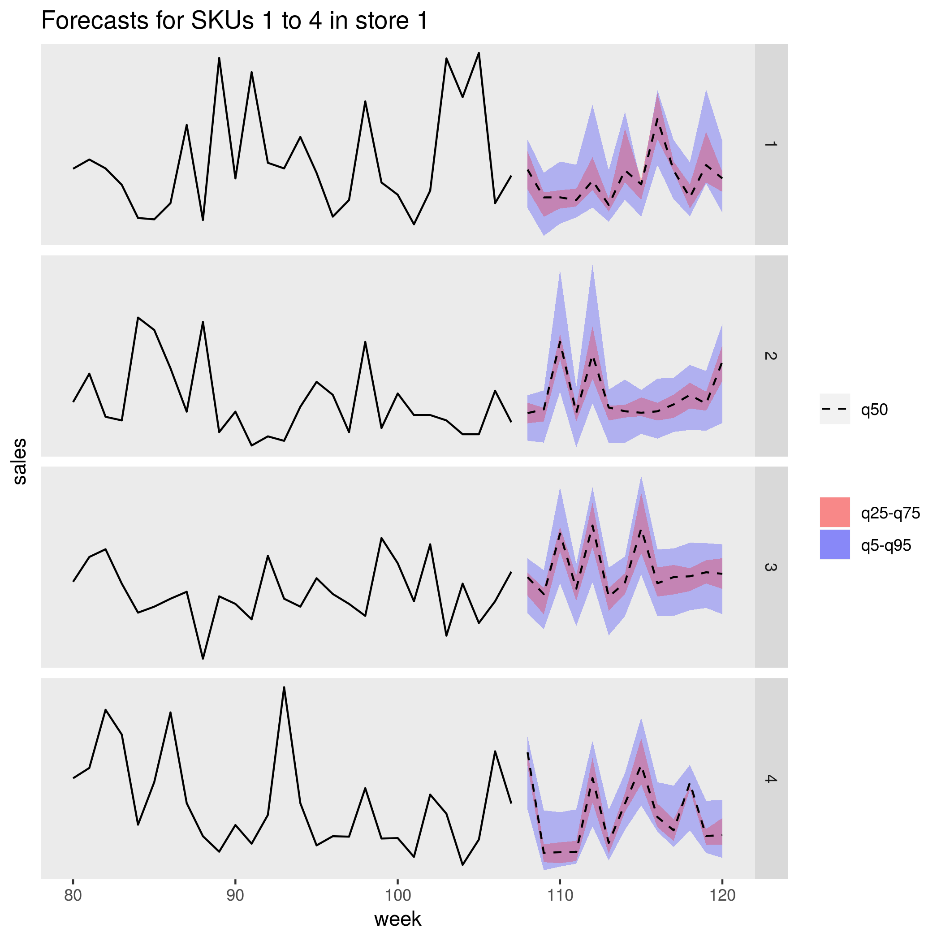
A figura a seguir mostra as vendas previstas para quatro produtos (SKUs) em uma loja. A linha preta é o histórico de vendas, a linha tracejada é a previsão mediana (q50), a faixa rosa representa os percentis 25 e 75 e a faixa azul representa os percentis 50 e 95.
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Desempenho
Implementação em contentores
Com essa arquitetura, todos os scripts R são executados em contêineres do Docker . O uso de contêineres garante que os scripts sejam executados sempre em um ambiente consistente, com a mesma versão R e versões de pacotes. Imagens separadas do Docker são usadas para os contêineres do agendador e do trabalhador, porque cada um tem um conjunto diferente de dependências do pacote R.
As Instâncias de Contêiner do Azure fornecem um ambiente sem servidor para executar o contêiner do agendador. O contêiner do agendador executa um script R que aciona os trabalhos de pontuação individuais em execução em um cluster do Lote do Azure.
Cada nó do cluster Batch executa o contêiner de trabalho, que executa o script de pontuação.
Paralelizar a carga de trabalho
Ao pontuar dados em lote com modelos R, considere como paralelizar a carga de trabalho. Os dados de entrada devem ser particionados para que a operação de pontuação possa ser distribuída entre os nós do cluster. Experimente diferentes abordagens para descobrir a melhor escolha para distribuir sua carga de trabalho. Numa base casuística, considere:
- Quantos dados podem ser carregados e processados na memória de um único nó.
- A sobrecarga de iniciar cada trabalho em lote.
- A sobrecarga de carregamento dos modelos R.
No cenário usado para este exemplo, os objetos de modelo são grandes e leva apenas alguns segundos para gerar uma previsão para produtos individuais. Por esse motivo, você pode agrupar os produtos e executar um único trabalho em lote por nó. Um loop dentro de cada trabalho gera previsões para os produtos sequencialmente. Esse método é a maneira mais eficiente de paralelizar essa carga de trabalho específica. Ele evita a sobrecarga de iniciar muitos trabalhos em lote menores e carregar repetidamente os modelos R.
Uma abordagem alternativa é acionar um trabalho em lote por produto. O Lote do Azure forma automaticamente uma fila de trabalhos e envia-os para serem executados no cluster à medida que os nós ficam disponíveis. Use o dimensionamento automático para ajustar o número de nós no cluster, dependendo do número de trabalhos. Essa abordagem é útil se levar um tempo relativamente longo para concluir cada operação de pontuação, o que justifica a sobrecarga de iniciar os trabalhos e recarregar os objetos do modelo. Essa abordagem também é mais simples de implementar e oferece a flexibilidade de usar o dimensionamento automático, uma consideração importante se o tamanho da carga de trabalho total não for conhecido com antecedência.
Monitorar trabalhos do Lote do Azure
Monitore e encerre trabalhos em Lote no painel Trabalhos da conta Lote no portal do Azure. Monitore o cluster em lotes, incluindo o estado de nós individuais, no painel Pools .
Fazer log com doAzureParallel
O pacote doAzureParallel coleta automaticamente logs de todos os stdout/stderr para cada trabalho enviado no Lote do Azure. Esses logs podem ser encontrados na conta de armazenamento criada na instalação. Para exibi-los, use uma ferramenta de navegação de armazenamento, como o Gerenciador de Armazenamento do Azure ou o portal do Azure.
Para depurar rapidamente trabalhos em lote durante o desenvolvimento, exiba os logs em sua sessão R local. Para obter mais informações, consulte Usando as execuções de treinamento Configurar e enviar.
Otimização de custos
A otimização de custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Os recursos de computação usados nessa arquitetura de referência são os componentes mais caros. Para esse cenário, um cluster de tamanho fixo é criado sempre que o trabalho é acionado e, em seguida, desligado após a conclusão do trabalho. O custo é incorrido apenas enquanto os nós do cluster estão iniciando, executando ou desligando. Essa abordagem é adequada para um cenário em que os recursos de computação necessários para gerar as previsões permanecem relativamente constantes de trabalho para trabalho.
Em cenários em que a quantidade de computação necessária para concluir o trabalho não é conhecida com antecedência, pode ser mais adequado usar o dimensionamento automático. Com essa abordagem, o tamanho do cluster é dimensionado para cima ou para baixo, dependendo do tamanho do trabalho. O Lote do Azure dá suporte a uma variedade de fórmulas de dimensionamento automático, que você pode definir ao definir o cluster usando a API doAzureParallel .
Para alguns cenários, o tempo entre os trabalhos pode ser muito curto para desligar e iniciar o cluster. Nesses casos, mantenha o cluster em execução entre os trabalhos, se apropriado.
O Azure Batch e o doAzureParallel dão suporte ao uso de VMs de baixa prioridade. Essas VMs vêm com um desconto significativo, mas correm o risco de serem apropriadas por outras cargas de trabalho de prioridade mais alta. Portanto, o uso de VMs de baixa prioridade não é recomendado para cargas de trabalho críticas de produção. No entanto, eles são úteis para cargas de trabalho experimentais ou de desenvolvimento.
Implementar este cenário
Para implantar essa arquitetura de referência, siga as etapas descritas no repositório GitHub .
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Angus Taylor - Brasil | Cientista de Dados Sênior
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.