Anti-padrão de Obtenção Externa
Os anti-padrões são falhas de design comuns que podem quebrar o seu software ou aplicações em situações de stress e não devem ser negligenciadas. Em um antipadrão de busca estranho, mais do que os dados necessários são recuperados para uma operação de negócios, muitas vezes resultando em sobrecarga de E/S desnecessária e capacidade de resposta reduzida.
Exemplos de antipadrão de busca estranho
Este anti-padrão pode ocorrer se a aplicação tentar minimizar os pedidos de E/S ao recuperar todos os dados de que pode precisar. Isto costuma ser um resultado de sobrecompensação para o anti-padrão Chatty I/O. Por exemplo, uma aplicação pode obter os detalhes para cada produto numa base de dados. Mas o utilizador pode precisar apenas de um subconjunto dos detalhes (alguns podem não ser relevantes para os clientes) e provavelmente não precisa de ver todos os produtos ao mesmo tempo. Mesmo que o usuário esteja navegando em todo o catálogo, faria sentido paginar os resultados — mostrando 20 de cada vez, por exemplo.
Outra origem deste problema é seguir práticas de programação ou conceção fracas. Por exemplo, o seguinte código utiliza o Entity Framework para obter os detalhes completos para cada produto. Então filtra os resultados para devolver apenas um subconjunto dos campos, descartando o resto. Pode encontrar o exemplo completo aqui.
public async Task<IHttpActionResult> GetAllFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Execute the query. This happens at the database.
var products = await context.Products.ToListAsync();
// Project fields from the query results. This happens in application memory.
var result = products.Select(p => new ProductInfo { Id = p.ProductId, Name = p.Name });
return Ok(result);
}
}
No exemplo seguinte, a aplicação obtém dados para efetuar uma agregação que, como alternativa, pode ser feita pela base de dados. A aplicação calcula as vendas totais ao obter cada registo para todas as encomendas vendidas e calcular a soma desses registos. Pode encontrar o exemplo completo aqui.
public async Task<IHttpActionResult> AggregateOnClientAsync()
{
using (var context = new AdventureWorksContext())
{
// Fetch all order totals from the database.
var orderAmounts = await context.SalesOrderHeaders.Select(soh => soh.TotalDue).ToListAsync();
// Sum the order totals in memory.
var total = orderAmounts.Sum();
return Ok(total);
}
}
O exemplo seguinte mostra um problema subtis causado pela forma como o Entity Framework utiliza o LINQ to Entities.
var query = from p in context.Products.AsEnumerable()
where p.SellStartDate < DateTime.Now.AddDays(-7) // AddDays cannot be mapped by LINQ to Entities
select ...;
List<Product> products = query.ToList();
A aplicação está a tentar localizar os produtos com uma SellStartDate a mais que uma semana. Na maioria dos casos, o LINQ to Entities converte uma cláusula where para uma instrução de SQL que é executada pela base de dados. No entanto, neste caso o LINQ to Entities não pode mapear o método AddDays para SQL. Em vez disso, cada linha da tabela Product é devolvida e os resultados são filtrados na memória.
A chamada para AsEnumerable é uma sugestão que há um problema. Este método converte os resultados para uma interface IEnumerable. Apesar de IEnumerable suportar filtragem, a filtragem é efetuada no lado do cliente, não do lado da base de dados. Por predefinição, o LINQ to Entities utiliza IQueryable, que passa a responsabilidade de filtragem para a origem de dados.
Como corrigir antipadrão de busca estranho
Evite a obtenção de grandes volumes de dados que podem rapidamente tornar-se desatualizados ou podem ser descartados. Obtenha apenas os dados necessários para a operação a realizar.
Em vez de obter cada coluna de uma tabela e então filtrá-las, selecione as colunas que precisa da base de dados.
public async Task<IHttpActionResult> GetRequiredFieldsAsync()
{
using (var context = new AdventureWorksContext())
{
// Project fields as part of the query itself
var result = await context.Products
.Select(p => new ProductInfo {Id = p.ProductId, Name = p.Name})
.ToListAsync();
return Ok(result);
}
}
Da mesma forma, realize a agregação na base de dados e não na memória da aplicação.
public async Task<IHttpActionResult> AggregateOnDatabaseAsync()
{
using (var context = new AdventureWorksContext())
{
// Sum the order totals as part of the database query.
var total = await context.SalesOrderHeaders.SumAsync(soh => soh.TotalDue);
return Ok(total);
}
}
Ao usar o Entity Framework, certifique-se de que as consultas LINQ sejam resolvidas usando a interface e não IEnumerableo IQueryable . Pode precisar de ajustar a consulta para apenas utilizar funções que possam ser mapeadas para a origem de dados. O exemplo anterior pode ser refatorizado para remover o método AddDays da consulta, permitindo que a filtragem possa ser feita pela base de dados.
DateTime dateSince = DateTime.Now.AddDays(-7); // AddDays has been factored out.
var query = from p in context.Products
where p.SellStartDate < dateSince // This criterion can be passed to the database by LINQ to Entities
select ...;
List<Product> products = query.ToList();
Considerações
Em alguns casos, pode melhorar o desempenho ao particionar os dados horizontalmente. Se diferentes operações acederem a atributos diferentes dos dados, a partição horizontal pode reduzir a contenção. Muitas vezes, a maior parte das operações são executadas em relação a um pequeno subconjunto de dados, pelo que propagar esta carga pode melhorar o desempenho. Veja Partição de dados.
Para operações que têm de suportar consultas sem limites, implemente a paginação e obtenha apenas um número limitado de entidades de cada vez. Por exemplo, se um cliente estiver a navegar num catálogo de produtos, pode msotrar uma página de resultados de cada vez.
Quando possível, tire partido das funcionalidades integradas no arquivo de dados. Por exemplo, as bases de dados SQL costumam fornecer funções de agregação.
Se estiver a utilizar um arquivo de dados que não suporta uma função específica, como a agregação, pode armazenar o resultado calculado noutro local ao atualizar o valor como registos adicionados ou atualizados, pelo que a aplicação não tem que recalcular o valor sempre que é preciso.
Se vir que os pedidos estão a devolver um número grande de campos, examine o código-fonte para determinar se todos esses campos são necessários. Por vezes esses pedidos resultam de uma consulta de
SELECT *mal concebida.Da mesma forma, os pedidos que obtêm um grande número de entidades podem ser um sinal que a aplicação não está a filtrar corretamente os dados. Certifique-se de que todas essas entidades são necessárias. Utilize a filtragem do lado da base de dados se possível, por exemplo ao utilizar cláusulas
WHEREem SQL.O processamento de descarga para a base de dados nem sempre é a melhor opção. Utilize esta estratégia apenas quando a base de dados está concebida ou otimizada para tal. A maior parte dos sistemas de bases de dados estão otimizados para determinadas funções, mas não estão concebidas para funcionar como motores de aplicações para efeitos gerais. Para obter mais informações, veja Anti-padrão de Base de Dados Ocupada.
Como detetar antipadrão de busca estranho
Os sintomas de obtenção externa incluem elevada latência e baixo débito. Se os dados forem obtidos de um arquivo de dados, é possível que haja um aumento na contenção. É provável que os usuários finais relatem tempos de resposta estendidos ou falhas causadas pelo tempo limite dos serviços. Essas falhas podem retornar erros HTTP 500 (Servidor Interno) ou HTTP 503 (Serviço Indisponível). Analise os registos de eventos do servidor Web, os quais contêm provavelmente informações mais detalhadas sobre as causas e as circunstâncias dos erros.
Os sintomas deste anti-padrão e alguns da telemetria obtida podem ser muito semelhantes aos do Anti-padrão de Persistência Monolítica.
Pode realizar os passos seguintes para ajudar a identificar a causa:
- Identifique as cargas de trabalho ou transações lentas ao realizar um teste de carga, monitorização de processos ou outros métodos de captura de dados de instrumentação.
- Observe quaisquer padrões comportamentais apresentados pelo sistema. Existem limites particulares em termos de transações por segundo ou volume de utilizadores?
- Faça a correlação das instâncias de cargas de trabalho lentas com os padrões comportamentais.
- Identifique os arquivos de dados a utilizar. Para cada origem de dados, execute uma telemetria de nível inferior para observar o comportamento das operações.
- Identifique quaisquer consultas de execução lenta que referenciem estas origens de dados.
- Realize uma análise específica em recursos das consultas lentas e determine como os dados são utilizados e consumidos.
Procure por qualquer um destes sintomas:
- São feitos pedidos grandes e frequentes de E/S ao mesmo recurso ou arquivo de dados.
- Contenção num recurso partilhado ou arquivo de dados.
- Uma operação que recebe frequentemente grandes volumes de dados através da rede.
- As aplicações e serviços que passem um tempo significativo à espera de E/S para concluir.
Diagnóstico de exemplo
As seguintes secções aplicam estes passos aos exemplos anteriores.
Identificar cargas de trabalho lentas
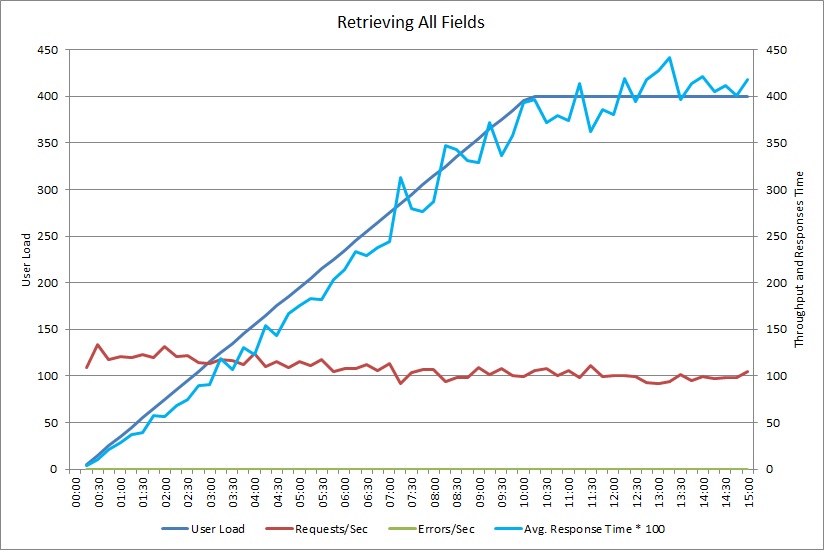
Este gráfico mostra os resultados de desempenho de um teste de carga com simulação de até 400 utilizadores em simultâneo com o método GetAllFieldsAsync apresentado anteriormente. O débito diminui lentamente conforme a carga aumenta. O tempo de resposta médio sobe à medida que a carga de trabalho aumenta.
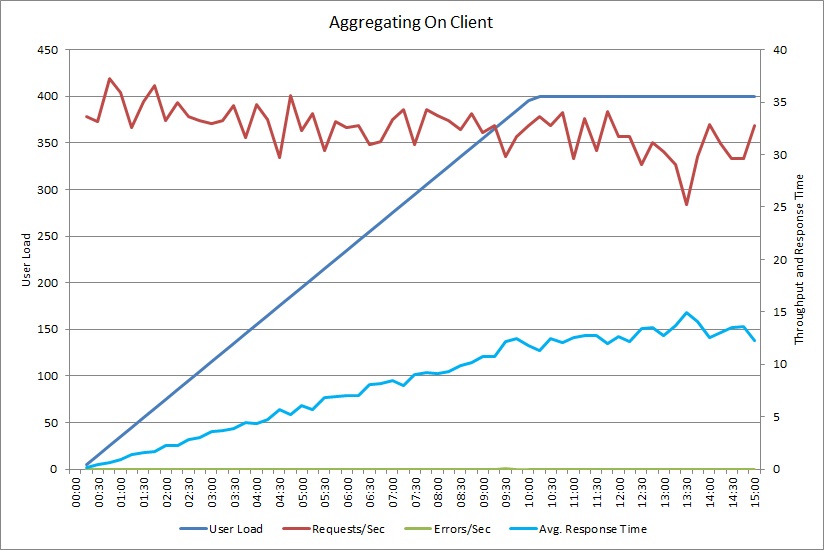
Um teste de carga para a operação AggregateOnClientAsync mostra um padrão semelhante. O volume de pedidos está razoavelmente estável. O tempo médio de resposta aumenta com a carga de trabalho, embora mais lentamente que no gráfico anterior.
Faça a correlação das cargas de trabalho lentas com os padrões comportamentais
Qualquer correlação entre os períodos de elevada utilização e um desempenho mais lento pode indicar áreas de preocupação. Examine rigorosamente o perfil de desempenho da funcionalidade que se suspeita estar em execução lenta, para poder determinar se corresponde ao teste de carga realizado antes.
Faça o teste de carga à mesma funcionalidade com carregamentos de utilizadores com base em passos, para descobrir o ponto em que o desempenho cai significativamente ou falha completamente. Se esse ponto calhar dentro dos limites da sua utilização de mundo real esperada, examine como está implementada a funcionalidade.
Uma operação lenta não é necessariamente um problema, se não estiver a ser realizada quando o sistema está em esforço, sem ser crítico em termos de tempo e não afetar negativamente o desempenho de outras operações importantes. Por exemplo, gerar estatísticas operacionais mensais pode ser uma operação a longo prazo, mas pode ser realizada como um processo em lote e baixa prioridade. Por outro lado, os clientes a consultar o catálogo de produtos é uma operação crítica para o negócio. Foque-se na telemetria gerada por essas operações críticas para ver como o desempenho varia durante os períodos de utilização elevada.
Identifique as origens de dados em cargas de trabalho lentas
Se suspeitar que um serviço está a ser executado de forma insuficiente devido à forma como obtém dados, investigue como é que a aplicação interage com os repositórios que utiliza. Monitorize o sistema ao vivo para ver que origens são acendidas durante os períodos de fraco desempenho.
Para cada origem de dados, instrumente o sistema para capturar o seguinte:
- A frequência com que cada arquivo de dados é acedido.
- O volume de dados a entrar e sair do arquivo de dados.
- A temporização destas operações, em particular, a latência dos pedidos.
- A natureza e a taxa de quaisquer erros que ocorram ao aceder cada arquivo de dados sob uma carga típica.
Compare estas informações com o volume de dados devolvidos pela aplicação para o cliente. Controle a proporção entre o volume de dados devolvidos pelo arquivo de dados com o volume de dados devolvidos para o cliente. Se não houver uma grande disparidade, investigue para determinar se a aplicação está a obter dados de que não precisa.
Pode capturar estes dados ao observar o sistema ao vivo e rastrear o ciclo de vida de cada utilizador, ou pode modelar uma série de cargas de trabalho sintéticas e executá-las num sistema de teste.
Os gráficos seguintes mostram a telemetria capturada com o New Relic APM durante um teste de carga do método GetAllFieldsAsync. Tenha em atenção a diferença entre os volumes de dados recebidos da base de dados e as respostas HTTP correspondentes.
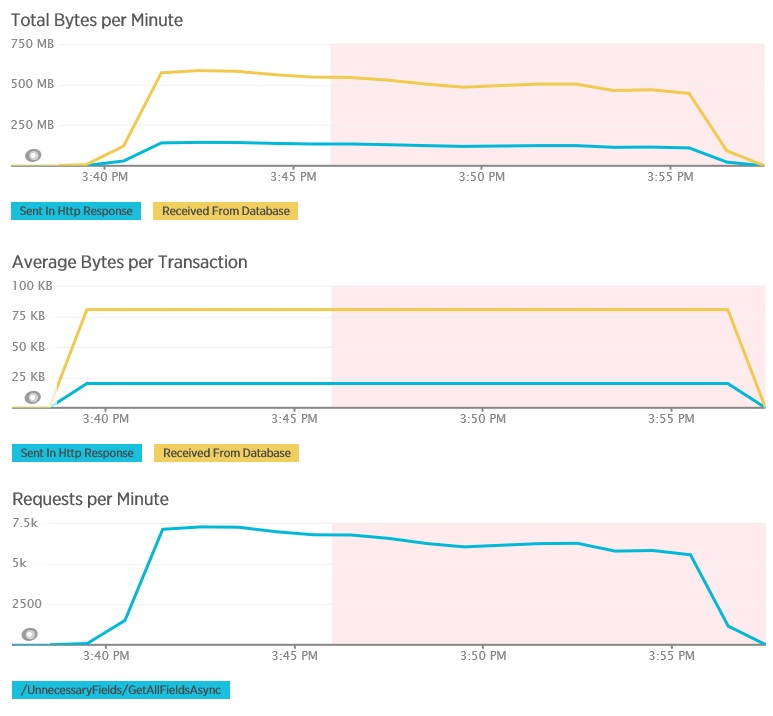
Para cada pedido, a base de dados devolveu 80.503 bytes, mas a resposta para o cliente apenas continha 19.855 bytes, ou seja, cerca de 25% do tamanho da resposta da base de dados. O tamanho dos dados devolvidos ao cliente podem variar dependendo do formato. Para este teste de carga, o cliente pediu dados JSON. Os testes em separado com XML (não mostrado) tiveram um tamanho de resposta de 35.655 bytes, ou seja, 44% do tamanho da resposta da base de dados.
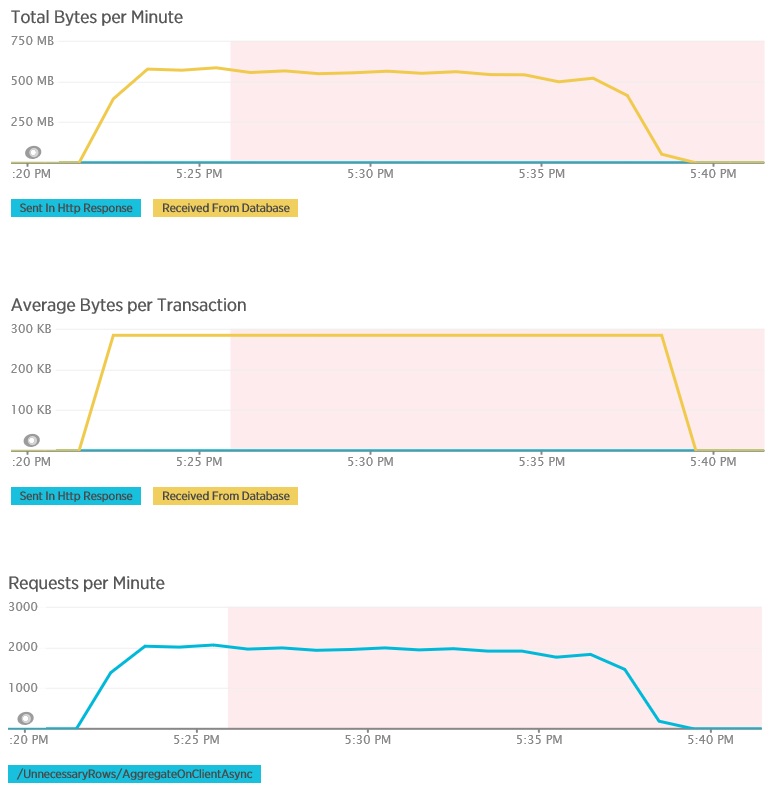
O teste de carga para o método AggregateOnClientAsync mostra resultados mais extremos. Neste caso, cada teste realizou uma consulta que desenvolveu mais de 280 Kb de dados da base de dados, mas a resposta JSON uns meros 14 bytes. A grande disparidade deve-se ao método calcular um resultado agregado a partir de um grande volume de dados.
Identificar e analisar consultas lentas
Procure por consultas de base de dados que consumam mais recursos e tire o maior tempo para executar. Pode adicionar a instrumentação para descobrir as horas de início e conclusão de várias operações da base de dados. Vários arquivos de dados também fornecem informação aprofundada sobre como as consultas são otimizadas e desempenhadas. Por exemplo, o painel Desempenho de Consulta no portal de gestão da Base de Dados SQL do Azure permite-lhe selecionar uma consultar e ver informações de desempenho de runtime detalhadas. Aqui está a consulta gerada pela operação GetAllFieldsAsync:

Implementar a solução e verificar o resultado
Em seguida a alterar o método GetRequiredFieldsAsync para utilizar a instrução SELECT no lado da base de dados, o teste de carga mostrou os seguintes resultados.
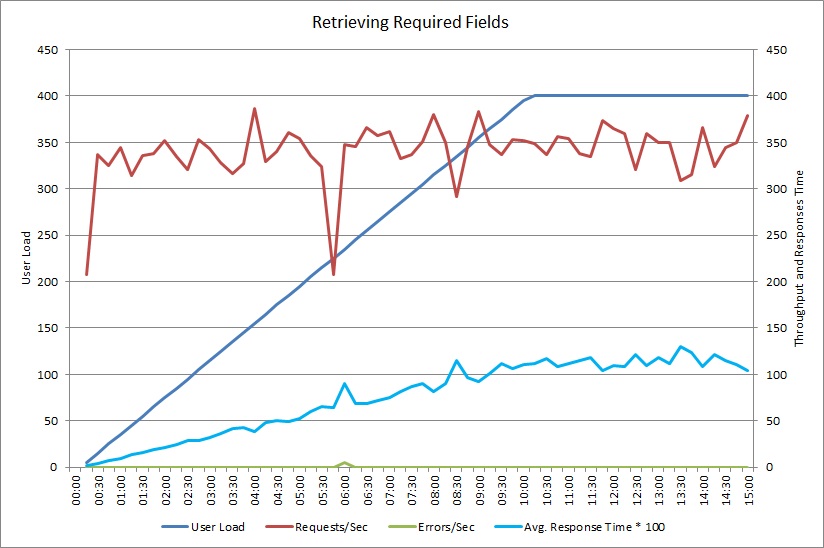
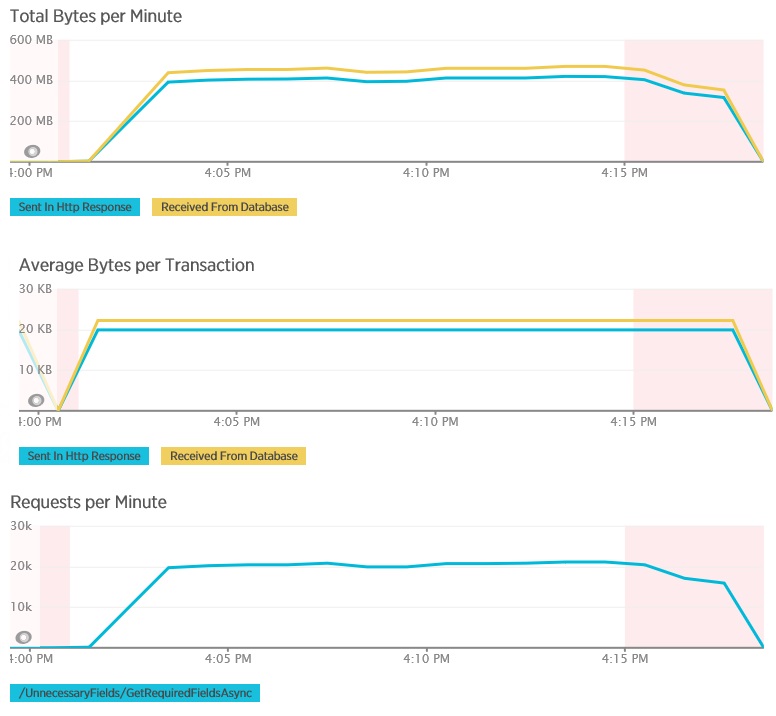
Este teste de carga utilizou a mesma implementação e a mesma carga de trabalho simulada com os 400 utilizadores em simultâneo, como antes. O gráfico mostra uma latência muito menor. O tempo de resposta sobe com a carga para aproximadamente 1,3 segundos, em comparação com os 4 segundos no caso anterior. O débito também é superior, em 350 pedidos por segundo em comparação com os 100 antes. O volume de dados obtidos da base de dados agora aproxima-se do tamanho das mensagens de resposta HTTP.
O teste de carga com o método AggregateOnDatabaseAsync gera os seguintes resultados:
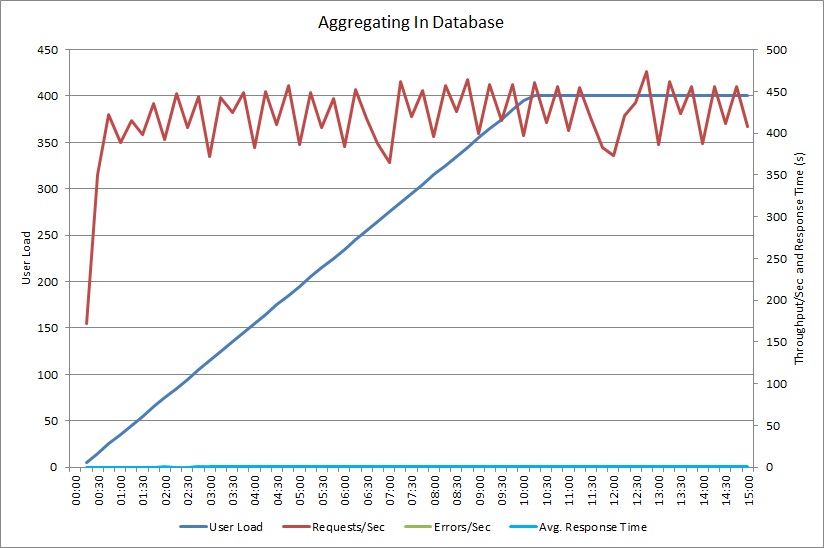
O tempo médio de resposta é mínimo, neste momento. Isto é uma melhoria considerável no desempenho, causada sobretudo pela grande redução na E/S da base de dados.
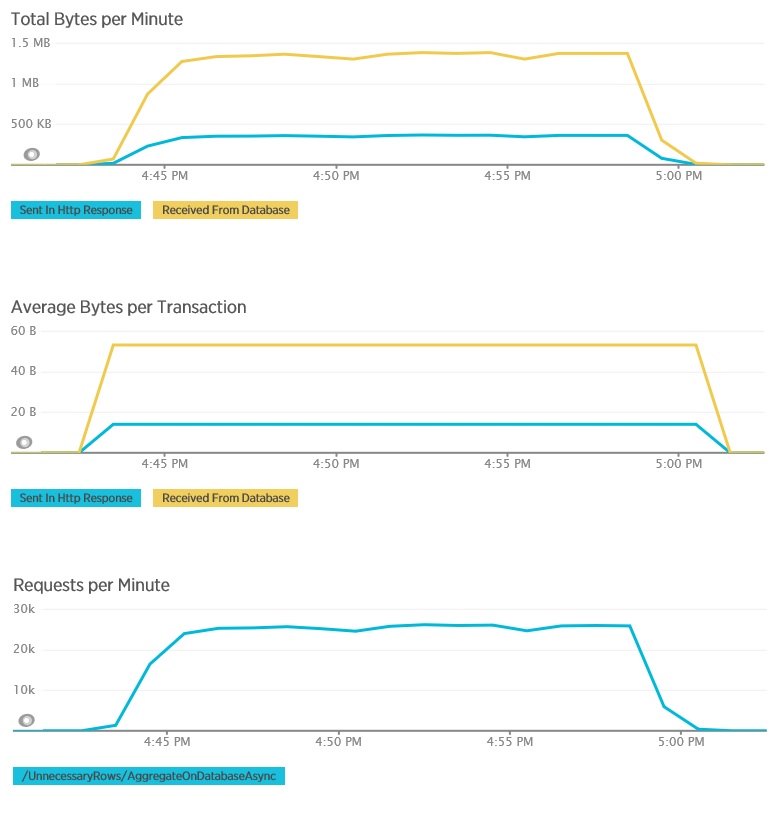
Esta é a telemetria correspondente para o método AggregateOnDatabaseAsync. A quantidade de dados obtidos da base de dados foi bastante reduzida, de mais de 280 Kb por transação para 53 bytes. Como resultado, o número máximo constante de pedidos por minuto subiu de cerca de 2.000 para mais de 25.000.
Recursos relacionados
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários