Anti-padrão de Persistência Monolítica
Colocar todos os dados de uma aplicação num arquivo de dados único pode prejudicar o desempenho, porque este leva à contenção de recursos ou porque o arquivo de dados não é uma boa opção para alguns dos dados.
Descrição do problema
Historicamente, as aplicações utilizaram frequentemente um único arquivo de dados, independentemente dos diferentes tipos de dados que a aplicação possa ter de armazenar. Normalmente, isto é feito para simplificar a estrutura da aplicação ou para corresponder ao conjunto de competências existente da equipa de desenvolvimento.
Muitas vezes, sistemas baseados em cloud modernos têm requisitos adicionais funcionais e não funcionais e têm de armazenar muitos tipos de dados heterogéneos, como documentos, imagens, dados em cache, mensagens em fila, registos de aplicações e telemetria. Seguir a abordagem tradicional e colocar todas estas informações no mesmo arquivo de dados pode prejudicar o desempenho, por duas razões principais:
- Armazenar e obter grandes quantidades de dados não relacionados no mesmo arquivo de dados pode provocar a contenção, que por sua vez origina tempos de resposta mais lentos e falhas de ligação.
- Independentemente do arquivo de dados escolhido, poderá não ser a melhor opção para todos os diferentes tipos de dados ou pode não ser otimizado para as operações que a aplicação executa.
O exemplo seguinte mostra um controlador de API Web do ASP.NET que adiciona um novo registo a uma base de dados e também regista o resultado num registo. O registo está retido na mesma base de dados que os dados empresariais. Pode encontrar o exemplo completo aqui.
public class MonoController : ApiController
{
private static readonly string ProductionDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
await DataAccess.LogAsync(ProductionDb, LogTableName);
return Ok();
}
}
A velocidade em que os registos são gerados provavelmente irá afetar o desempenho das operações empresariais. E, se outro componente, por exemplo, um monitor do processo de aplicação, regularmente lê e processa dados de registo, isso também pode afetar as operações empresariais.
Como resolver o problema
Separe os dados de acordo com a sua utilização. Para cada conjunto de dados, selecione um arquivo de dados que melhor corresponda à forma como esse conjunto de dados será utilizado. No exemplo anterior, a aplicação deve registar um arquivo separado da base de dados que contém dados de empresariais:
public class PolyController : ApiController
{
private static readonly string ProductionDb = ...;
private static readonly string LogDb = ...;
public async Task<IHttpActionResult> PostAsync([FromBody]string value)
{
await DataAccess.InsertPurchaseOrderHeaderAsync(ProductionDb);
// Log to a different data store.
await DataAccess.LogAsync(LogDb, LogTableName);
return Ok();
}
}
Considerações
Separe os dados pela forma como são utilizados e acedidos. Por exemplo, não armazene dados empresariais e informações de registo no mesmo arquivo de dados. Estes tipos de dados têm requisitos significativamente diferentes e padrões de acesso. Os registos de registo são inerentemente sequenciais, enquanto os dados empresariais são mais prováveis de requererem acesso aleatório e, muitas vezes, são relacionais.
Considere o padrão de acesso de dados para cada tipo de dados. Por exemplo, armazene relatórios e documentos formatados em um banco de dados de documentos, como o Azure Cosmos DB, mas use o Cache Redis do Azure para armazenar em cache dados temporários.
Se seguir esta documentação de orientação, mas ainda atingir os limites da base de dados, poderá ter de aumentar verticalmente a base de dados. Considere também dimensionar horizontalmente e criar partições de carga entre servidores de base de dados. No entanto, a criação de partições pode exigir a reestruturação da aplicação. Para obter mais informações, veja Criação de partições de dados.
Como detetar o problema
O sistema irá provavelmente ficar muito mais lento e, eventualmente, falhar, uma vez que o sistema fica sem recursos, como ligações de base de dados.
Pode realizar os passos seguintes para ajudar a identificar a causa.
- Instrumente o sistema para gravar as estatísticas do desempenho chave. Capture informações de tempo para cada operação, bem como os pontos de onde a aplicação lê e escreve dados.
- Se puder, monitorize o sistema em execução durante alguns dias num ambiente de produção para obter uma vista do mundo real de como o sistema é utilizado. Se não puder, execute os testes de carga com script com um volume realista de utilizadores virtuais a realizar uma série típica de operações.
- Utilize os dados telemétricos para identificar períodos de fraco desempenho.
- Identifique quais os arquivos de dados que foram acedidos durante esses períodos.
- Identifique os recursos de armazenamento de dados que podem apresentar contenção.
Diagnóstico de exemplo
As secções seguintes aplicam estes passos para o exemplo de aplicação descrito anteriormente.
Instrumente e monitorize o sistema
O gráfico seguinte mostra os resultados do teste de carga da aplicação de exemplo descrito anteriormente. O teste utilizou uma carga de até 1000 utilizadores em simultâneo.
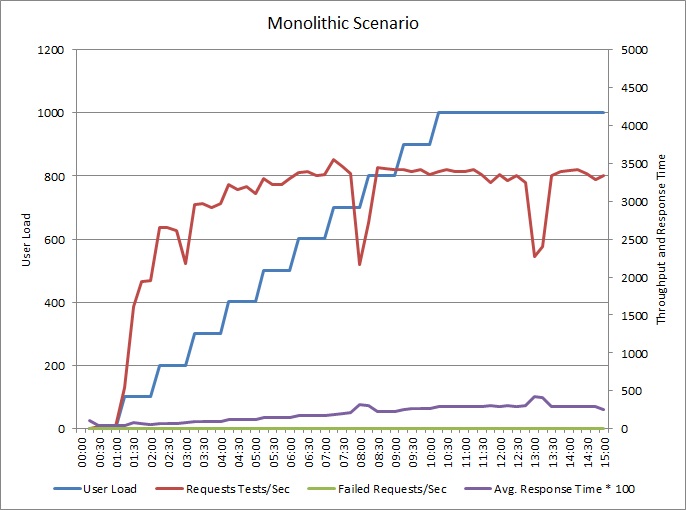
À medida que a carga aumenta para 700 utilizadores, o débito também aumenta. Mas nessa altura, os níveis de débito e o sistema parecem estar em execução na capacidade máxima. A resposta média aumenta gradualmente com a carga do utilizador, mostrando que o sistema não consegue acompanhar a procura.
Identificar períodos de fraco desempenho
Se estiver a monitorizar o sistema de produção, pode ser que repare em padrões. Por exemplo, os tempos de resposta poderão baixar significativamente em simultâneo todos os dias. Isto pode ser causado por uma carga de trabalho regular ou tarefa de lote agendada, ou apenas porque o sistema tem mais utilizadores em determinadas alturas. Deve focar-se nos dados telemétricos para estes eventos.
Procure correlações entre os tempos de resposta aumentados e a atividade de base de dados aumentada ou E/S para recursos partilhados. Se existirem correlações, significa que a base de dados poderá ter sofrido um estrangulamento.
Identifique quais os arquivos de dados que são acedidos durante esses períodos
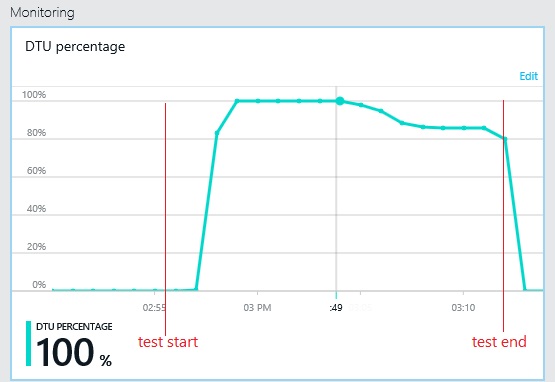
O gráfico seguinte mostra a utilização das unidades de débito de base de dados (DTU) durante o teste de carga. (Uma DTU é uma medida de capacidade disponível e é uma combinação de utilização da CPU, alocação de memória, taxa de E/S.) A utilização de DTUs rapidamente atingiu 100%. Este é aproximadamente o ponto em que o débito atingiu o pico no gráfico anterior. A utilização da base de dados permaneceu muito elevada até o teste estar concluído. Existe uma ligeira redução em direção ao final, que pode ser causada pela limitação, pela concorrência das ligações de base de dados ou por outros fatores.
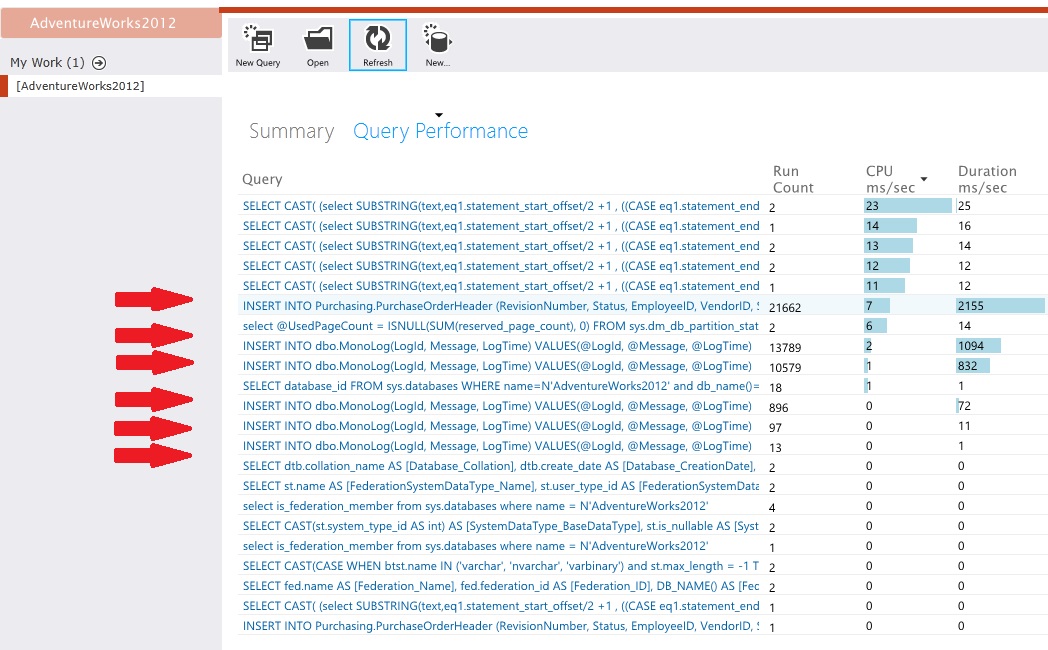
Examinar a telemetria dos arquivos de dados
Instrumente os arquivos de dados para capturar os detalhes de baixo nível da atividade. No exemplo de aplicação, as estatísticas do acesso aos dados mostraram um grande volume de operações de inserção executadas na tabela PurchaseOrderHeader e na tabela MonoLog.
Identificar a contenção de recursos
Neste momento, pode rever o código de origem, com foco nos pontos em que os recursos disponíveis são acedidos pela aplicação. Procure situações, como:
- Os dados que estão logicamente separados escritos no mesmo arquivo. Dados, como registos, relatórios e mensagens em fila não devem ser mantidos na mesma base de dados como informações empresariais.
- Um erro de correspondência entre a escolha do arquivo de dados e o tipo de dados, como blobs grandes ou documentos XML numa base de dados relacional.
- Dados com padrões de utilização significativamente diferentes que partilham o mesmo arquivo, como dados de alta-escrita/baixa-leitura a ser armazenados com dados de baixa escrita/alta leitura.
Implementar a solução e verificar o resultado
A aplicação foi alterada para registos de escrita para um arquivo de dados separado. Seguem-se os resultados do teste de carga:
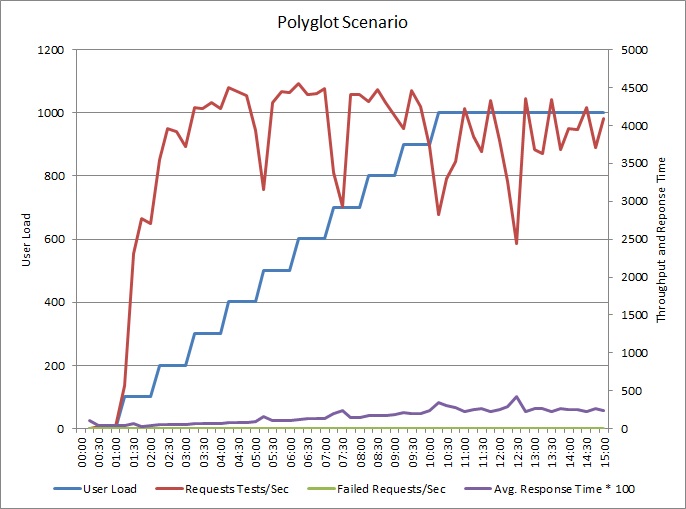
O padrão de débito é semelhante ao gráfico anterior, mas o ponto no qual os picos de desempenho é de aproximadamente 500 pedidos por segundo mais alto. O tempo de resposta médio é ligeiramente inferior. No entanto, estas estatísticas não mostram tudo. A telemetria para a base de dados empresarial mostra que os picos de utilização da DTU estão em cerca de 75%, em vez de 100%.
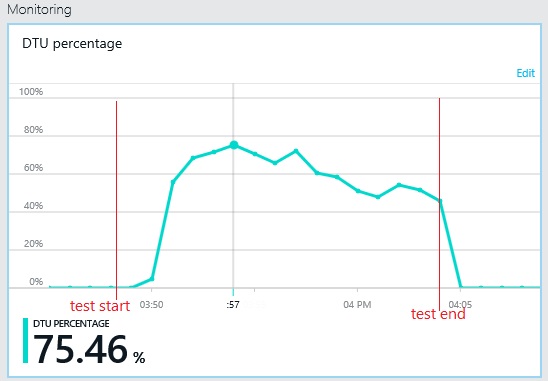
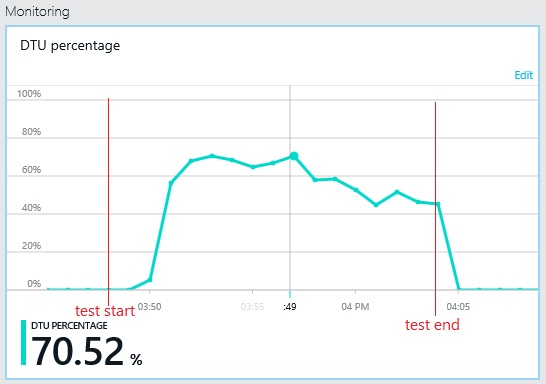
Da mesma forma, a utilização de DTU máxima de base de dados do registo atinge apenas cerca de 70%. As bases de dados já não são o fator restritivo no desempenho do sistema.
Recursos relacionados
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários