Este artigo descreve algumas estratégias para particionar dados em vários armazenamentos de dados do Azure. Para obter orientações gerais sobre quando particionar dados e práticas recomendadas, consulte Particionamento de dados.
Particionando o Banco de Dados SQL do Azure
Uma única base de dados SQL tem um limite para o volume de dados que pode conter. O débito é limitado por fatores de arquitetura e pelo número de ligações simultâneas que suporta.
Os pools elásticos oferecem suporte ao dimensionamento horizontal para um banco de dados SQL. Usando pools elásticos, você pode particionar seus dados em fragmentos espalhados por vários bancos de dados SQL. Também pode adicionar ou remover partições horizontais à medida que o volume de dados que precisa de processar cresce e diminui. Os pools elásticos também podem ajudar a reduzir a contenção distribuindo a carga entre bancos de dados.
Cada partição horizontal é implementada como uma base de dados SQL. Um fragmento pode conter mais de um conjunto de dados (chamado de shardlet). Cada base de dados mantém metadados que descrevem os shardlets nela contidos. Um shardlet pode ser um único item de dados ou um grupo de itens que compartilham a mesma chave de shardlet. Por exemplo, em um aplicativo multilocatário, a chave do shardlet pode ser a ID do locatário e todos os dados de um locatário podem ser mantidos no mesmo shardlet.
Os aplicativos cliente são responsáveis por associar um conjunto de dados a uma chave shardlet. Uma base de dados SQL separada atua como um gestor global dos mapas das partições horizontais. Esta base de dados tem uma lista de todos os fragmentos e shardlets no sistema. O aplicativo se conecta ao banco de dados do gerenciador de mapas de estilhaços para obter uma cópia do mapa de estilhaços. Ele armazena em cache o mapa de estilhaços localmente e usa o mapa para rotear solicitações de dados para o fragmento apropriado. Essa funcionalidade está oculta atrás de uma série de APIs contidas na biblioteca de cliente do Elastic Database, que está disponível para Java e .NET.
Para obter mais informações sobre pools elásticos, consulte Dimensionamento com o Banco de Dados SQL do Azure.
Para reduzir a latência e melhorar a disponibilidade, você pode replicar o banco de dados global do gerenciador de mapas de estilhaços. Com os níveis de preços Premium, você pode configurar a replicação geográfica ativa para copiar dados continuamente para bancos de dados em diferentes regiões.
Como alternativa, use o Azure SQL Data Sync ou o Azure Data Factory para replicar o banco de dados do gerenciador de mapas de estilhaços entre regiões. Essa forma de replicação é executada periodicamente e é mais adequada se o mapa de estilhaços mudar com pouca frequência e não exigir a camada Premium.
A Base de Dados Elástica fornece dois esquemas de mapeamento de dados para shardlets e o respetivo armazenamento nas partições horizontais:
Um mapa de estilhaços de lista associa uma única chave a um shardlet. Por exemplo, num sistema multi-inquilino, os dados de cada inquilino podem ser associados a uma chave exclusiva e armazenados no seu próprio shardlet. Para garantir o isolamento, cada fragmento pode ser mantido dentro do seu próprio fragmento.

Baixe um arquivo do Visio deste diagrama.
Um mapa de estilhaços de intervalo associa um conjunto de valores-chave contíguos a um shardlet. Por exemplo, você pode agrupar os dados de um conjunto de locatários (cada um com sua própria chave) dentro do mesmo shardlet. Este esquema é menos dispendioso do que o primeiro, porque os inquilinos partilham armazenamento de dados, mas tem menos isolamento.

Baixar um arquivo do Visio deste diagrama
Um único fragmento pode conter os dados de vários fragmentos. Por exemplo, pode utilizar shardlets de lista para armazenar dados de diferentes inquilinos não contínuos na mesma partição horizontal. Você também pode misturar shardlets de alcance e shardlets de lista no mesmo fragmento, embora eles sejam abordados através de mapas diferentes. O diagrama a seguir mostra essa abordagem:

Baixe um arquivo do Visio deste diagrama.
Os pools elásticos possibilitam adicionar e remover fragmentos à medida que o volume de dados diminui e cresce. Os aplicativos cliente podem criar e excluir fragmentos dinamicamente e atualizar de forma transparente o gerenciador de mapas de estilhaços. No entanto, a remoção de uma partição horizontal é uma operação destrutiva que também requer a eliminação de todos os dados nessa partição horizontal.
Se um aplicativo precisar dividir um fragmento em dois fragmentos separados ou combinar fragmentos, use a ferramenta de mesclagem dividida. Essa ferramenta é executada como um serviço Web do Azure e migra dados com segurança entre fragmentos.
O esquema de particionamento pode afetar significativamente o desempenho do seu sistema. Também pode afetar a taxa na qual os fragmentos devem ser adicionados ou removidos, ou que os dados devem ser reparticionados entre fragmentos. Considere os pontos seguintes:
Agrupe dados usados juntos no mesmo fragmento e evite operações que acessam dados de vários fragmentos. Um fragmento é um banco de dados SQL por si só, e as junções entre bancos de dados devem ser executadas no lado do cliente.
Embora o Banco de dados SQL não ofereça suporte a junções entre bancos de dados, você pode usar as ferramentas do Banco de Dados Elástico para executar consultas de vários estilhaços. Uma consulta com vários estilhaços envia consultas individuais para cada banco de dados e mescla os resultados.
Não projete um sistema que tenha dependências entre fragmentos. Restrições de integridade referencial, gatilhos e procedimentos armazenados em um banco de dados não podem fazer referência a objetos em outro.
Se você tiver dados de referência usados com freqüência por consultas, considere replicar esses dados entre fragmentos. Essa abordagem pode eliminar a necessidade de unir dados entre bancos de dados. Idealmente, esses dados devem ser estáticos ou lentos, para minimizar o esforço de replicação e reduzir as chances de se tornarem obsoletos.
Os shardlets que pertencem ao mesmo mapa de estilhaços devem ter o mesmo esquema. Essa regra não é imposta pelo Banco de dados SQL, mas o gerenciamento e a consulta de dados se tornam muito complexos se cada shardlet tiver um esquema diferente. Em vez disso, crie mapas de estilhaços separados para cada esquema. Lembre-se de que os dados pertencentes a diferentes shardlets podem ser armazenados no mesmo fragmento.
As operações transacionais são suportadas apenas para dados dentro de um fragmento, e não entre fragmentos. As transações podem abranger shardlets, desde que façam parte da mesma partição horizontal. Portanto, se sua lógica de negócios precisa realizar transações, armazene os dados no mesmo fragmento ou implemente uma eventual consistência.
Coloque fragmentos perto dos usuários que acessam os dados nesses fragmentos. Esta estratégia ajuda a reduzir a latência.
Evite ter uma mistura de fragmentos altamente ativos e relativamente inativos. Tente distribuir a carga uniformemente por partições horizontais. Para tal, poderá ser necessário o hashing das chaves de fragmentação. Se estiver a realizar a localização geográfica de shards, verifique se as chaves de hash mapeiam para shardlets mantidos em shards armazenados próximo dos utilizadores que acedem a esses dados.
Particionando o armazenamento de tabela do Azure
O Armazenamento de Tabela do Azure é um armazenamento de chave-valor projetado em torno do particionamento. Todas as entidades são armazenadas em uma partição e as partições são gerenciadas internamente pelo armazenamento de Tabela do Azure. Cada entidade armazenada em uma tabela deve fornecer uma chave de duas partes que inclui:
A chave de partição. Este é um valor de cadeia de caracteres que determina a partição onde o armazenamento de Tabela do Azure colocará a entidade. Todas as entidades com a mesma chave de partição são armazenadas na mesma partição.
A chave de linha. Este é um valor de cadeia de caracteres que identifica a entidade dentro da partição. Todas as entidades dentro de uma partição são ordenadas lexicalmente, por ordem ascendente por esta chave. A combinação de chave de partição/chave de linha tem de ser exclusiva para cada entidade e não pode exceder 1 KB de comprimento.
Se uma entidade for adicionada a uma tabela com uma chave de partição não utilizada anteriormente, o Armazenamento de Tabela do Azure criará uma nova partição para essa entidade. Outras entidades com a mesma chave de partição serão armazenadas na mesma partição.
Este mecanismo implementa de forma eficaz uma estratégia de escalamento horizontal automática. Cada partição é armazenada no mesmo servidor em um datacenter do Azure para ajudar a garantir que as consultas que recuperam dados de uma única partição sejam executadas rapidamente.
A Microsoft publicou metas de escalabilidade para o Armazenamento do Azure. Se for provável que o seu sistema exceda esses limites, considere dividir as entidades em várias tabelas. Utilize a criação de partições verticais para dividir os campos em grupos com maior probabilidade de serem acedidos em conjunto.
O diagrama a seguir mostra a estrutura lógica de uma conta de armazenamento de exemplo. A conta de armazenamento contém três tabelas: Informações de Clientes, Informações de Produtos e Informações de Encomendas.
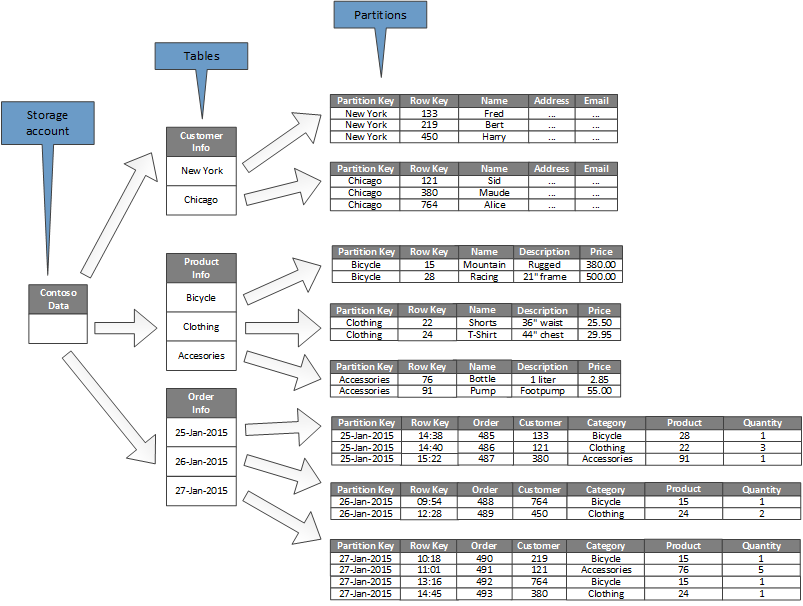
Cada tabela tem várias partições.
- Na tabela Informações do cliente, os dados são particionados de acordo com a cidade onde o cliente está localizado. A chave de linha contém o ID do cliente.
- Na tabela Informações do produto, os produtos são particionados por categoria de produto e a chave de linha contém o número do produto.
- Na tabela Informações do pedido, os pedidos são particionados por data do pedido, e a chave de linha especifica a hora em que o pedido foi recebido. Todos os dados são ordenados pela chave de linha em cada partição.
Considere os seguintes pontos ao projetar suas entidades para o armazenamento de tabela do Azure:
Selecione uma chave de partição e uma chave de linha de acordo com a forma como os dados são acessados. Escolha uma combinação de chave de partição/chave de linha que suporte a maioria das suas consultas. As consultas mais eficientes obtêm dados ao especificar a chave de partição e a chave de linha. As consultas que especificam uma chave de partição e um intervalo de chaves de linha podem ser concluídas através da análise de uma única partição. Isto é relativamente rápido porque os dados são mantidos por ordem de chave de linha. Se as consultas não especificarem qual partição examinar, todas as partições deverão ser verificadas.
Se uma entidade tiver uma chave natural, utilize-a como a chave de partição e especifique uma cadeia vazia como a chave de linha. Se uma entidade tiver uma chave composta que consiste em duas propriedades, selecione a propriedade de alteração mais lenta como a chave de partição e a outra como a chave de linha. Se uma entidade tiver mais de duas propriedades de chave, utilize uma concatenação das propriedades para fornecer as chaves de partição e de linha.
Se você executar regularmente consultas que pesquisam dados usando campos diferentes das chaves de partição e linha, considere implementar o padrão Tabela de Índice ou considere usar um armazenamento de dados diferente que ofereça suporte à indexação, como o Azure Cosmos DB.
Se você gerar chaves de partição usando uma sequência monotônica (como "0001", "0002", "0003") e cada partição contiver apenas uma quantidade limitada de dados, o armazenamento de Tabela do Azure poderá agrupar fisicamente essas partições no mesmo servidor. O Armazenamento do Azure pressupõe que o aplicativo tem maior probabilidade de executar consultas em um intervalo contíguo de partições (consultas de intervalo) e é otimizado para esse caso. No entanto, esta abordagem pode conduzir a centros de registo, uma vez que é provável que todas as inserções de novas entidades se concentrem num extremo da gama contígua. Também pode reduzir a escalabilidade. Para distribuir a carga de forma mais uniforme, considere realizar o hashing da chave de partição.
O Armazenamento de Tabela do Azure dá suporte a operações transacionais para entidades que pertencem à mesma partição. Um aplicativo pode executar várias operações de inserção, atualização, exclusão, substituição ou mesclagem como uma unidade atômica, desde que a transação não inclua mais de 100 entidades e a carga útil da solicitação não exceda 4 MB. As operações que abrangem várias partições não são transacionais e podem exigir que você implemente uma eventual consistência. Para obter mais informações sobre armazenamento de tabelas e transações, consulte Executando transações de grupo de entidades.
Considere a granularidade da chave de partição:
Usar a mesma chave de partição para cada entidade resulta em uma única partição mantida em um servidor. Isso impede que a partição seja dimensionada e concentra a carga em um único servidor. Como resultado, essa abordagem só é adequada para armazenar um pequeno número de entidades. No entanto, garante que todas as entidades possam participar em transações de grupos de entidades.
O uso de uma chave de partição exclusiva para cada entidade faz com que o serviço de armazenamento de tabelas crie uma partição separada para cada entidade, possivelmente resultando em um grande número de partições pequenas. Esta abordagem é mais dimensionável do que utilizar uma chave de partição única, mas as transações do grupo de entidades não são possíveis. Além disso, as consultas que obtêm mais do que uma entidade poderão envolver a leitura de mais do que um servidor. No entanto, se o aplicativo executar consultas de intervalo, usar uma sequência monotônica para as chaves de partição pode ajudar a otimizar essas consultas.
O compartilhamento da chave de partição em um subconjunto de entidades torna possível agrupar entidades relacionadas na mesma partição. As operações que envolvem entidades relacionadas podem ser efetuadas através da utilização de transações do grupo de entidades e as consultas que obtêm um conjunto de entidades relacionadas podem ser concluídas ao aceder a um único servidor.
Para obter mais informações, consulte Guia de design da tabela de armazenamento do Azure e Estratégia de particionamento escalável.
Particionando o Armazenamento de Blobs do Azure
O Armazenamento de Blobs do Azure torna possível armazenar grandes objetos binários. Use blobs de bloco em cenários em que você precisa carregar ou baixar grandes volumes de dados rapidamente. Utilize blobs de páginas para aplicações que requerem acesso aleatório, em vez de acesso de série a partes dos dados.
Cada blob (de blocos ou de páginas) é mantido num contentor numa conta de armazenamento do Azure. Pode utilizar contentores para agrupar blobs relacionados que têm os mesmos requisitos de segurança. Este agrupamento é lógico, em vez de físico. Dentro de um contentor, cada blob tem um nome exclusivo.
A chave de partição para um blob é o nome da conta + nome do contentor + nome do blob. A chave de partição é usada para particionar dados em intervalos e esses intervalos são balanceados de carga em todo o sistema. Os blobs podem ser distribuídos por vários servidores para aumentar horizontalmente o acesso aos mesmos, mas um blob individual só pode ser servido por um único servidor.
Se o seu esquema de nomenclatura usa carimbos de data/hora ou identificadores numéricos, isso pode levar a um tráfego excessivo indo para uma partição, limitando o sistema de balanceamento de carga eficaz. Por exemplo, se você tiver operações diárias que usam um objeto blob com um carimbo de data/hora, como aaaa-mm-dd, todo o tráfego dessa operação irá para um único servidor de partição. Em vez disso, considere adicionar um hash de três dígitos como prefixo ao nome. Para obter mais informações, consulte Convenção de nomenclatura de partição.
As ações de escrever um único bloco ou página são atômicas, mas as operações que abrangem blocos, páginas ou blobs não são. Se precisar de assegurar a consistência ao executar operações de escrita em blocos, páginas e blobs, remova um bloqueio de escrita, utilizando uma concessão de blob.
Criação de partições de filas de armazenamento do Azure
As filas de armazenamento do Azure permitem-lhe implementar mensagens assíncronas entre processos. Uma conta de armazenamento do Azure pode conter qualquer número de filas, e cada fila pode conter qualquer número de mensagens. A única limitação é o espaço disponível na conta de armazenamento. O tamanho máximo de uma mensagem individual é de 64 KB. Se necessitar de mensagens maiores, considere utilizar filas do Azure Service Bus em alternativa.
Cada fila de armazenamento tem um nome exclusivo dentro da conta de armazenamento que a contém. O Azure cria partições de filas baseadas no nome. Todas as mensagens para a mesma fila são armazenadas na mesma partição, que é controlada por um único servidor. Filas diferentes podem ser geridas por diferentes servidores, para o ajudar a equilibrar a carga. A alocação de filas a servidores é transparente para as aplicações e os utilizadores.
Em um aplicativo de grande escala, não use a mesma fila de armazenamento para todas as instâncias do aplicativo porque essa abordagem pode fazer com que o servidor que está hospedando a fila se torne um ponto de acesso. Em vez disso, utilize filas diferentes para diferentes áreas funcionais da aplicação. As filas de armazenamento do Azure não dão suporte a transações, portanto, direcionar mensagens para filas diferentes deve ter pouco efeito na consistência das mensagens.
Uma fila de armazenamento do Azure pode processar até 2000 mensagens por segundo. Se precisar de processar mensagens a uma taxa superior, considere criar várias filas. Por exemplo, numa aplicação global, crie filas de armazenamento separadas em contas de armazenamento separadas para processar instâncias de aplicações que estejam a ser executadas em cada região.
Particionando o Barramento de Serviço do Azure
O Azure Service Bus utiliza um mediador de mensagens para processar mensagens que são enviadas para uma fila ou tópico do Service Bus. Por predefinição, todas as mensagens que são enviadas para uma fila ou um tópico são processadas pelo mesmo processo de mediador de mensagens. Esta arquitetura pode colocar uma limitação ao débito global da fila de mensagens. No entanto, também pode particionar uma fila ou um tópico quando é criado. Para tal, defina a propriedade EnablePartitioning da descrição da fila ou do tópico para true.
Uma fila ou um tópico particionado está dividido em vários fragmentos, cada um dos quais tem por base um armazenamento de mensagens e um mediador de mensagens separados. O Service Bus assume a responsabilidade por criar e gerir estes fragmentos. Quando uma aplicação publica uma mensagem numa fila ou num tópico particionado, o Service Bus atribui a mensagem a um fragmento para essa fila ou tópico. Quando uma aplicação recebe uma mensagem de uma fila ou subscrição, o Service Bus verifica cada fragmento para obter a mensagem seguinte disponível e, em seguida, passa-a à aplicação para processamento.
Esta estrutura ajuda a distribuir a carga por mediadores de mensagens e arquivos de mensagens, aumentando a escalabilidade e melhorando a disponibilidade. Se o mediador de mensagens ou o arquivo de mensagens para um fragmento estiver temporariamente indisponível, o Service Bus pode obter as mensagens de um dos restantes fragmentos disponíveis.
O Service Bus atribui uma mensagem a um fragmento da seguinte forma:
Se a mensagem pertencer a uma sessão, todas as mensagens com o mesmo valor para a propriedade SessionId serão enviadas para o mesmo fragmento.
Se a mensagem não pertencer a uma sessão, mas o remetente tiver especificado um valor para a propriedade PartitionKey, então todas as mensagens com o mesmo valor PartitionKey são enviadas para o mesmo fragmento.
Nota
Se as propriedades SessionId e PartitionKey estiverem ambas especificadas, têm de ser definidas para o mesmo valor ou a mensagem será rejeitada.
Se as propriedades SessionId e PartitionKey de uma mensagem não forem especificadas, mas a deteção de duplicados estiver ativada, a propriedade MessageId irá ser utilizada. Todas as mensagens com o mesmo MessageId serão direcionadas para o mesmo fragmento.
Se as mensagens não incluírem uma propriedade SessionId, PartitionKey ou MessageId, o Service Bus atribui mensagens a fragmentos sequencialmente. Se um fragmento não estiver disponível, o Service Bus irá avançar para o seguinte. Isto significa que uma falha temporária na infraestrutura de mensagens não irá causar a falha da operação de envio de mensagens.
Considere os seguintes pontos ao decidir se ou como particionar uma fila ou um tópico de mensagens do Service Bus:
As filas e os tópicos do Service Bus são criados no âmbito de um espaço de nomes do Service Bus. Atualmente, o Service Bus permite até 100 filas ou tópicos particionados por espaço de nomes.
Cada espaço de nomes do Service Bus impõe quotas dos recursos disponíveis, como o número de subscrições por tópico, o número de pedidos simultâneos de envio e receção por segundo, e o número máximo de ligações simultâneas que podem ser estabelecidas. Essas cotas são documentadas em cotas do Service Bus. Se prevê exceder estes valores, crie espaços de nomes adicionais com as suas próprias filas e tópicos, e distribua o trabalho por estes espaços de nomes. Por exemplo, numa aplicação global, crie espaços de nomes separados em cada região e configure as instâncias da aplicação para que utilizem as filas e os tópicos no espaço de nomes mais próximo.
As mensagens que são enviadas como parte de uma transação têm de especificar uma chave de partição. Pode ser uma propriedade SessionId, PartitionKey ou MessageId. Todas as mensagens que são enviadas como parte da mesma transação têm de especificar a mesma chave de partição porque têm de ser processadas pelo mesmo processo de mediador de mensagens. Não é possível enviar mensagens para filas ou tópicos diferentes na mesma transação.
As filas e os tópicos particionados não podem ser configurados para serem eliminados automaticamente quando ficam inativos.
Atualmente, as filas e os tópicos particionados não podem ser utilizados com o Advance Message Queueing Protocol (AMQP) se estiver a criar soluções entre plataformas ou híbridas.
Particionando o Azure Cosmos DB
O Azure Cosmos DB para NoSQL é um banco de dados NoSQL para armazenar documentos JSON. Um documento em um banco de dados do Azure Cosmos DB é uma representação serializada em JSON de um objeto ou outra parte dos dados. Não são impostos esquemas fixos, exceto que cada documento tem de conter um ID exclusivo.
Os documentos são organizados em coleções. Pode agrupar documentos relacionados numa coleção. Por exemplo, num sistema de que mantém publicações de blogue, pode armazenar o conteúdo de cada mensagem de blogue como um documento numa coleção. Também pode criar coleções para cada tipo de assunto. Em alternativa, numa aplicação multi-inquilino, como num sistema onde autores diferentes controlam e gerem as suas próprias publicações no blogue, pode particionar blogues por autor e criar coleções separadas para cada autor. O espaço de armazenamento que é atribuído às coleções é elástico e pode aumentar ou diminuir conforme necessário.
O Azure Cosmos DB dá suporte ao particionamento automático de dados com base em uma chave de partição definida pelo aplicativo. Uma partição lógica é uma partição que armazena todos os dados para um valor de chave de partição única. Todos os documentos que partilham o mesmo valor da chave de partição são colocados na mesma partição lógica. O Azure Cosmos DB distribui valores de acordo com o hash da chave de partição. Uma partição lógica tem um tamanho máximo de 20 GB. Por conseguinte, a escolha da chave de partição é uma decisão importante no momento da conceção. Escolha uma propriedade com uma vasta gama de valores e padrões de acesso uniformes. Para obter mais informações, veja Particionar e dimensionar no Azure Cosmos DB.
Nota
Cada banco de dados do Azure Cosmos DB tem um nível de desempenho que determina a quantidade de recursos que recebe. Um nível de desempenho está associado a um limite de taxa de unidade de pedido (RU). O limite de taxa de RU especifica o volume dos recursos que estão reservados e disponíveis para utilização exclusiva por essa coleção. O custo de uma coleção depende do nível de desempenho que está selecionado para essa coleção. Quanto maior for o nível de desempenho (e o limite de taxa de RU), maior será o encargo. Pode ajustar o nível de desempenho de uma coleção com o portal do Azure. Para obter mais informações, veja Unidades de Pedido no Azure Cosmos DB.
Se o mecanismo de particionamento que o Azure Cosmos DB fornece não for suficiente, talvez seja necessário fragmentar os dados no nível do aplicativo. As coleções de documentos fornecem um mecanismo natural para criação de partições de dados dentro de uma base de dados. A forma mais simples de implementar a divisão consiste em criar uma coleção para cada partição horizontal. Os contentores são recursos lógicos e podem abranger um ou mais servidores. Os contêineres de tamanho fixo têm um limite máximo de 20 GB e taxa de transferência de 10.000 RU/s. Os contêineres ilimitados não têm um tamanho máximo de armazenamento, mas devem especificar uma chave de partição. Com a fragmentação da aplicação, a aplicação cliente tem de direcionar os pedidos para a partição horizontal adequada, normalmente, implementando o seu próprio mecanismo de mapeamento, com base em alguns atributos dos dados que definem a chave de partição horizontal.
Todos os bancos de dados são criados no contexto de uma conta de banco de dados do Azure Cosmos DB. Uma única conta pode conter várias bases de dados e especifica em que regiões são criadas as bases de dados. Cada conta também impõe o seu próprio controlo de acesso. Você pode usar contas do Azure Cosmos DB para localizar geograficamente fragmentos (coleções em bancos de dados) perto dos usuários que precisam acessá-los e impor restrições para que apenas esses usuários possam se conectar a eles.
Considere os seguintes pontos ao decidir como particionar dados com o Azure Cosmos DB para NoSQL:
Os recursos disponíveis para um banco de dados do Azure Cosmos DB estão sujeitos às limitações de cota da conta. Cada base de dados pode conter várias coleções, e cada coleção está associada a um nível de desempenho que regula o limite de taxa de RU (débito reservado) para essa coleção. Para obter mais informações, veja Subscrição do Azure e limites, quotas e restrições do serviço.
Cada documento tem de ter um atributo que possa ser utilizado para identificar exclusivamente esse documento dentro da coleção em que é mantido. Este atributo é diferente da chave de partição horizontal, que define qual coleção contém o documento. Uma coleção pode conter um grande número de documentos. Em teoria, está limitada apenas pelo comprimento máximo do ID do documento. O ID do documento pode ter até 255 carateres.
Todas as operações em relação a um documento são executadas no contexto de uma transação. As transações estão confinadas à coleção na qual o documento está contido. Se uma operação falhar, o trabalho que foi efetuado é revertido. Enquanto um documento está sujeito a uma operação, quaisquer alterações efetuadas estão sujeitas ao isolamento a nível de instantâneo. Este mecanismo garante que se, por exemplo, um pedido para criar um novo documento falhar, outro utilizador que esteja a consultar a base de dados em simultâneo não irá ver um documento parcial que é então removido.
As consultas de base de dados também estão confinadas ao nível da coleção. Uma consulta única só pode obter dados de uma coleção. Se precisar de obter dados de várias coleções, tem de consultar individualmente cada coleção e unir os resultados no código da aplicação.
O Azure Cosmos DB dá suporte a itens programáveis que podem ser armazenados em uma coleção ao lado de documentos. Estes incluem os procedimentos armazenados, as funções definidas pelo utilizador e os acionadores (escritos em JavaScript). Estes itens podem aceder a qualquer documento dentro da mesma coleção. Além disso, estes itens são executados no âmbito da transação de ambiente (no caso de um acionador que é acionado em resultado de uma operação de criação, eliminação ou substituição efetuada num documento) ou ao iniciar uma nova transação (no caso de um procedimento armazenado que é executado em resultado de um pedido explícito de um cliente). Se o código de um item programável emitir uma exceção, a transação é revertida. Pode utilizar os procedimentos armazenados e os acionadores para manter a integridade e consistência entre documentos, mas estes documentos têm todos de constar da mesma coleção.
As coleções que pretende manter nas bases de dados não devem exceder os limites de débito definidos pelos níveis de desempenho das coleções. Para obter mais informações, veja Unidades de Pedido no Azure Cosmos DB. Se prevê atingir estes limites, considere a divisão das coleções entre bases de dados em contas diferentes para reduzir a carga por coleção.
Particionando a Pesquisa do Azure
A capacidade de pesquisar dados é, muitas vezes, o método principal de navegação e exploração que é fornecido por muitas aplicações Web. Ajuda os utilizadores a localizar recursos rapidamente (por exemplo, os produtos numa aplicação de comércio eletrónico) com base nas combinações de critérios de pesquisa. O serviço Azure Search fornece capacidades de pesquisa em texto completo relativamente a conteúdo Web e inclui funcionalidades como escrita antecipada, consultas sugeridas com base em correspondências próximas e navegação por facetas. Para obter mais informações, consulte O que é a Pesquisa do Azure?.
O Azure Search armazena conteúdo pesquisável como documentos JSON numa base de dados. Pode definir índices que especificam os campos pesquisáveis nestes documentos e fornecem estas definições ao Azure Search. Quando um utilizador submete um pedido de pesquisa, o Azure Search utiliza os índices adequados para localizar itens correspondentes.
Para reduzir a contenção, o armazenamento que é utilizado pelo Azure Search pode ser dividido em 1, 2, 3, 4, 6 ou 12 partições, e cada partição pode ser replicada até 6 vezes. O resultado do número de partições, multiplicado pelo número de réplicas é denominado a unidade de pesquisa (SU). Uma única instância do Azure Search pode conter um máximo de 36 SUs (uma base de dados com 12 partições só suporta, no máximo, 3 réplicas).
É-lhe faturada cada SU atribuída ao seu serviço. À medida que o volume pesquisável cresce ou que a taxa de pedidos de pesquisa aumenta, pode adicionar SUs a uma instância existente do Azure Search para processar a carga adicional. O próprio Azure Search distribui equitativamente os documentos pelas partições. Atualmente, não são suportadas estratégias manuais de criação de partições.
Cada partição pode conter, no máximo, 15 milhões de documentos ou ocupar 300 GB de espaço de armazenamento (o que for mais pequeno). Pode criar até 50 índices. O desempenho do serviço varia e depende da complexidade dos documentos, dos índices disponíveis e dos efeitos da latência de rede. Em média, uma única réplica (1 SU) deve ser capaz de lidar com 15 consultas por segundo (QPS), embora seja recomendável efetuar testes de referência com os seus dados para obter uma medida de débito mais precisa. Para obter mais informações, consulte Limites de serviço na Pesquisa do Azure.
Nota
Pode armazenar um conjunto limitado de tipos de dados em documentos pesquisáveis, incluindo cadeias, booleanos, dados numéricos, dados de data e hora e alguns dados geográficos. Para obter mais informações, consulte a página Tipos de dados suportados (Azure Search) no site da Microsoft.
Tem controlo limitado sobre a forma como o Azure Search particiona os dados para cada instância do serviço. No entanto, num ambiente global, poderá melhorar o desempenho e reduzir ainda mais a latência e a contenção através da criação de partições do próprio serviço, com qualquer uma das seguintes estratégias:
Crie uma instância do Azure Search em cada região geográfica e certifique-se de que os aplicativos cliente sejam direcionados para a instância disponível mais próxima. Esta estratégia requer que todas as atualizações ao conteúdo pesquisável sejam replicadas atempadamente em todas as instâncias do serviço.
Crie duas camadas do Azure Search:
- Um serviço local em cada região que contém os dados que são acedidos mais frequentemente por utilizadores nessa região. Os utilizadores podem direcionar os pedidos aqui para obterem resultados rápidos, embora limitados.
- Um serviço global que abrange todos os dados. Os utilizadores podem direcionar os pedidos aqui para obterem resultados mais lentos mas mais completos.
Esta abordagem é mais adequada quando há uma variação regional significativa dos dados que estão a ser pesquisados.
Particionando o Cache do Azure para Redis
O Cache Redis do Azure fornece um serviço de cache compartilhado na nuvem baseado no armazenamento de dados chave-valor do Redis. Como o próprio nome indica, o Cache Redis do Azure destina-se a ser uma solução de cache. Utilize-a apenas para conter dados transitórios e não como um arquivo de dados permanente. Os aplicativos que usam o Cache Redis do Azure devem poder continuar funcionando se o cache não estiver disponível. O Cache Redis do Azure dá suporte à replicação primária/secundária para fornecer alta disponibilidade, mas atualmente limita o tamanho máximo do cache a 53 GB. Se precisar de mais espaço, tem de criar caches adicionais. Para obter mais informações, veja Azure Cache for Redis (Cache do Azure para Redis).
A criação de partições de um arquivo de dados de Redis envolve a divisão os dados entre instâncias do serviço de Redis. Cada instância constitui uma única partição. O Cache do Azure para Redis abstrai os serviços do Redis por trás de uma fachada e não os expõe diretamente. A maneira mais simples de implementar o particionamento é criar várias instâncias do Cache do Azure para Redis e distribuir os dados entre elas.
Pode associar cada item de dados a um identificador (uma chave de partição) que especifica qual cache armazena o item de dados. A lógica de aplicação de cliente pode então utilizar este identificador para encaminhar pedidos para a partição adequada. Esse esquema é muito simples, mas se o esquema de particionamento for alterado (por exemplo, se instâncias adicionais do Cache do Azure para Redis forem criadas), os aplicativos cliente talvez precisem ser reconfigurados.
O Redis nativo (não o Cache do Azure para Redis) dá suporte ao particionamento do lado do servidor com base no cluster Redis. Nesta abordagem, pode dividir os dados uniformemente pelos servidores através de um mecanismo de hashing. Cada servidor Redis armazena os metadados que descrevem o intervalo de chaves hash que a partição contém e também inclui informações sobre as chaves hash localizadas em partições noutros servidores.
As aplicações cliente simplesmente enviam pedidos para qualquer um dos servidores de Redis participantes (provavelmente o mais próximo). O servidor Redis examina o pedido de cliente. Se puder ser resolvido localmente, efetua a operação pedida. Caso contrário, reencaminha o pedido para o servidor adequado.
Este modelo é implementado com o clustering de Redis e está descrito com maior detalhe na página Tutorial do cluster Redis no site do Redis. O clustering de Redis é transparente para as aplicações cliente. Servidores Redis adicionais podem ser adicionados ao cluster (e os dados podem ser reparticionados) sem exigir que você reconfigure os clientes.
Importante
Atualmente, o Cache do Azure para Redis dá suporte ao clustering Redis somente na camada premium.
A página Criação de partições: como dividir dados entre várias instâncias de Redis no site do Redis fornece mais informações sobre a implementação da criação de partições com o Redis. O resto desta secção parte do princípio que está a implementar a criação de partições do lado do cliente ou assistida por proxy.
Considere os seguintes pontos ao decidir como particionar dados com o Cache do Azure para Redis:
O Cache Redis do Azure não se destina a atuar como um armazenamento de dados permanente, portanto, seja qual for o esquema de particionamento implementado, o código do aplicativo deve ser capaz de recuperar dados de um local que não seja o cache.
Os dados que são frequentemente acedidos em conjunto devem ser mantidos na mesma partição. O Redis é um arquivo de chave-valor poderoso que fornece vários mecanismos altamente otimizados para estruturar dados. Estes mecanismos podem ser um dos seguintes:
- Cadeias simples (dados binários com comprimento até 512 MB)
- Tipos agregados, como listas (que podem atuar como filas e pilhas)
- Conjuntos (ordenados e não ordenados)
- Hashes (que podem agrupar os campos relacionados, como os itens que representam os campos num objeto)
Os tipos de agregados permitem associar muitos valores relacionados à mesma chave. Uma chave de Redis identifica uma lista, conjunto, ou hash, em vez dos itens de dados nela contidos. Esses tipos estão todos disponíveis com o Cache Redis do Azure e são descritos pela página Tipos de dados no site do Redis. Por exemplo, numa parte de um sistema de comércio eletrónico que controla as encomendas feitas pelos clientes, os detalhes de cada cliente podem ser armazenados num hash de Redis que é codificado com o ID de cliente. Cada hash pode conter uma coleção de IDs de encomendas do cliente. Um conjunto Redis separado pode conter as encomendas, novamente estruturadas como hashes e codificadas com o ID de encomenda. A Figura 8 mostra esta estrutura. Tenha em atenção que o Redis não implementa qualquer outra forma de integridade referencial, pelo que é responsabilidade do programador manter as relações entre os clientes e as encomendas.
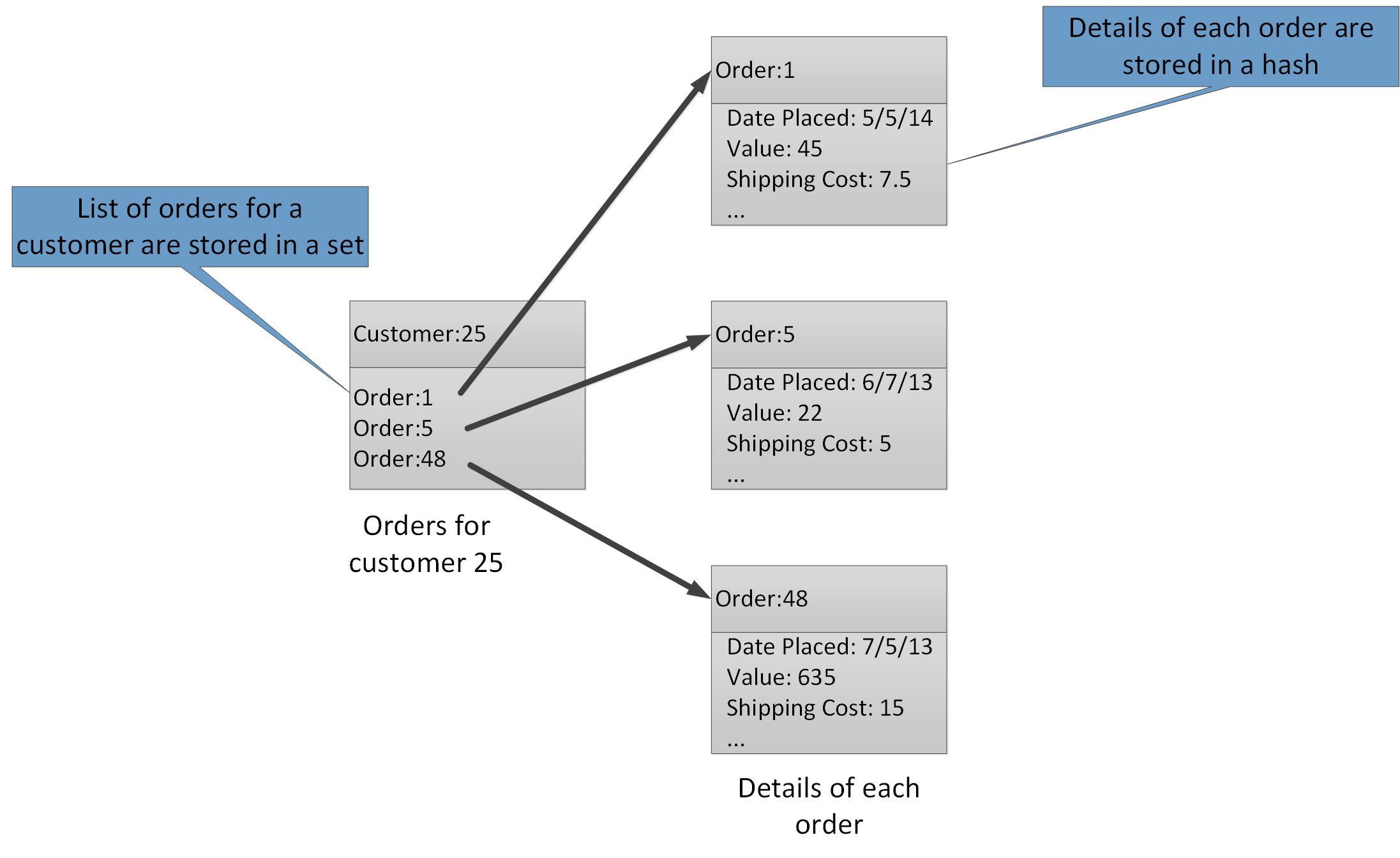
Figura 8. Estrutura sugerida no armazenamento Redis para registro de pedidos de clientes e seus detalhes.
Nota
No Redis, todas as chaves são valores de dados binários (por exemplo, cadeias de Redis) e podem conter até 512 MB de dados. Em teoria, uma chave pode conter quase quaisquer informações. No entanto, recomendamos que adote uma convenção de nomenclatura consistente de chaves, que seja descritiva do tipo de dados e que identifique a entidade, mas não seja excessivamente longa. Uma abordagem comum é utilizar chaves com o formato “entity_type:ID”. Por exemplo, pode utilizar “customer:99” para indicar a chave de um cliente com o ID 99.
Pode implementar a criação de partições verticais armazenando informações relacionadas em agregações diferentes da mesma base de dados. Por exemplo, numa aplicação de comércio eletrónico, pode armazenar as informações frequentemente acedidas sobre os produtos num hash de Redis e as informações detalhadas utilizadas menos frequentemente noutro. Ambos os hashes podem utilizar o mesmo ID de produto como parte da chave. Por exemplo, você pode usar "product: nn" (onde nn é o ID do produto) para as informações do produto e "product_details: nn" para os dados detalhados. Esta estratégia pode ajudar a reduzir o volume de dados com maior probabilidade de serem obtidos pela maioria das consultas.
Pode criar novas partições de um arquivo de dados de Redis, mas tenha em atenção que se trata de uma tarefa complexa e demorada. O clustering Redis pode reparticionar dados automaticamente, mas esse recurso não está disponível com o Cache do Azure para Redis. Por conseguinte, ao estruturar o esquema de partição, tente deixar espaço livre suficiente em cada partição para permitir o crescimento esperado dos dados ao longo do tempo. No entanto, lembre-se de que o Cache Redis do Azure se destina a armazenar dados em cache temporariamente e que os dados mantidos no cache podem ter um tempo de vida limitado especificado como um valor TTL (time-to-live). Para dados relativamente voláteis, o valor de TTL pode ser pequeno, mas para dados estáticos, o valor de TTL pode ser muito mais longo. Evite armazenar grandes quantidades de dados de longa duração na cache, se houver probabilidade de o volume destes dados encherem a cache. Você pode especificar uma política de remoção que faça com que o Cache Redis do Azure remova dados se o espaço for escasso.
Nota
Ao usar o Cache do Azure para Redis, você especifica o tamanho máximo do cache (de 250 MB a 53 GB) selecionando o nível de preço apropriado. No entanto, depois que um Cache Redis do Azure tiver sido criado, você não poderá aumentar (ou diminuir) seu tamanho.
Os lotes de Redis e as transações não podem abranger várias ligações, pelo que todos os dados que são afetados por um lote ou transação devem ser mantidos na mesma base de dados (partição horizontal).
Nota
Uma sequência de operações numa transação de Redis não é necessariamente atómica. Os comandos que compõem uma transação são verificados e colocados em fila antes de ser executados. Se ocorrer um erro durante esta fase, a fila completa é eliminada. No entanto, depois de a transação ser submetida com êxito, os comandos em fila são executados em sequência. Se um comando falhar, apenas esse comando deixa de ser executado. Todos os comandos anteriores e posteriores na fila são executados. Para obter mais informações, aceda à página Transações no site do Redis.
O Redis suporta um número limitado de operações atómicas. As únicas operações deste tipo que suportam várias chaves e valores são operações MGET e MSET. As operações MGET devolvem uma coleção de valores para uma lista de chaves especificada, e as operações MSET armazenam uma coleção de valores para uma lista de chaves especificada. Se precisar de utilizar estas operações, os pares chave-valor que são referenciados pelos comandos MSET e MGET têm de ser armazenados na mesma base de dados.
Particionando o Azure Service Fabric
O Azure Service Fabric é uma plataforma de microsserviços que fornece um runtime para aplicações distribuídas na cloud. O Service Fabric oferece suporte a executáveis convidados .NET, serviços com e sem monitoração de estado e contêineres. Os serviços com estado fornecem uma coleção fiável para armazenar persistentemente dados de uma coleção de chave-valor dentro do cluster do Service Fabric. Para obter mais informações sobre estratégias para particionar chaves em uma coleção confiável, consulte diretrizes e recomendações para coleções confiáveis no Azure Service Fabric.
Próximos passos
Descrição geral do Azure Service Fabric é uma introdução ao Azure Service Fabric.
Criar partições de serviços fiáveis do Service Fabric fornece mais informações sobre serviços fiáveis no Azure Service Fabric.
Particionando Hubs de Eventos do Azure
Os Hubs de Eventos do Azure foram concebidos para transmissão em fluxo de dados em grande escala e a criação de partições está incorporada no serviço para permitir o dimensionamento horizontal. Cada consumidor só lê uma partição específica do fluxo de mensagens.
O publicador de eventos apenas tem conhecimento da respetiva chave de partição, não da partição onde os eventos são publicados. Este desacoplamento da chave e da partição faz com que o remetente não tenha necessidade de saber muito sobre o processamento a jusante. (Também é possível enviar eventos diretamente para uma determinada partição, mas geralmente tal não é recomendado.)
Considere o dimensionamento a longo prazo ao selecionar a contagem de partições. Depois de um hub de eventos ser criado, não é possível alterar o número de partições.
Próximos passos
Para obter mais informações sobre como utilizar partições em Hubs de Eventos, veja O que são os Hubs de Eventos?.
Para considerações sobre compromissos entre a disponibilidade e a consistência, veja Disponibilidade e consistência em Hubs de Eventos.