Aquisição de dados e estágio de compreensão do ciclo de vida do Processo de Ciência de Dados da Equipe
Este artigo descreve as metas, tarefas e resultados finais associados ao estágio de aquisição e compreensão de dados do Processo de Ciência de Dados da Equipe (TDSP). Esse processo fornece um ciclo de vida recomendado que sua equipe pode usar para estruturar seus projetos de ciência de dados. O ciclo de vida descreve os principais estágios que sua equipe executa, geralmente iterativamente:
- Compreensão do negócio
- Aquisição e compreensão de dados
- Modelação
- Implementação
- Aceitação do cliente
Aqui está uma representação visual do ciclo de vida do TDSP:
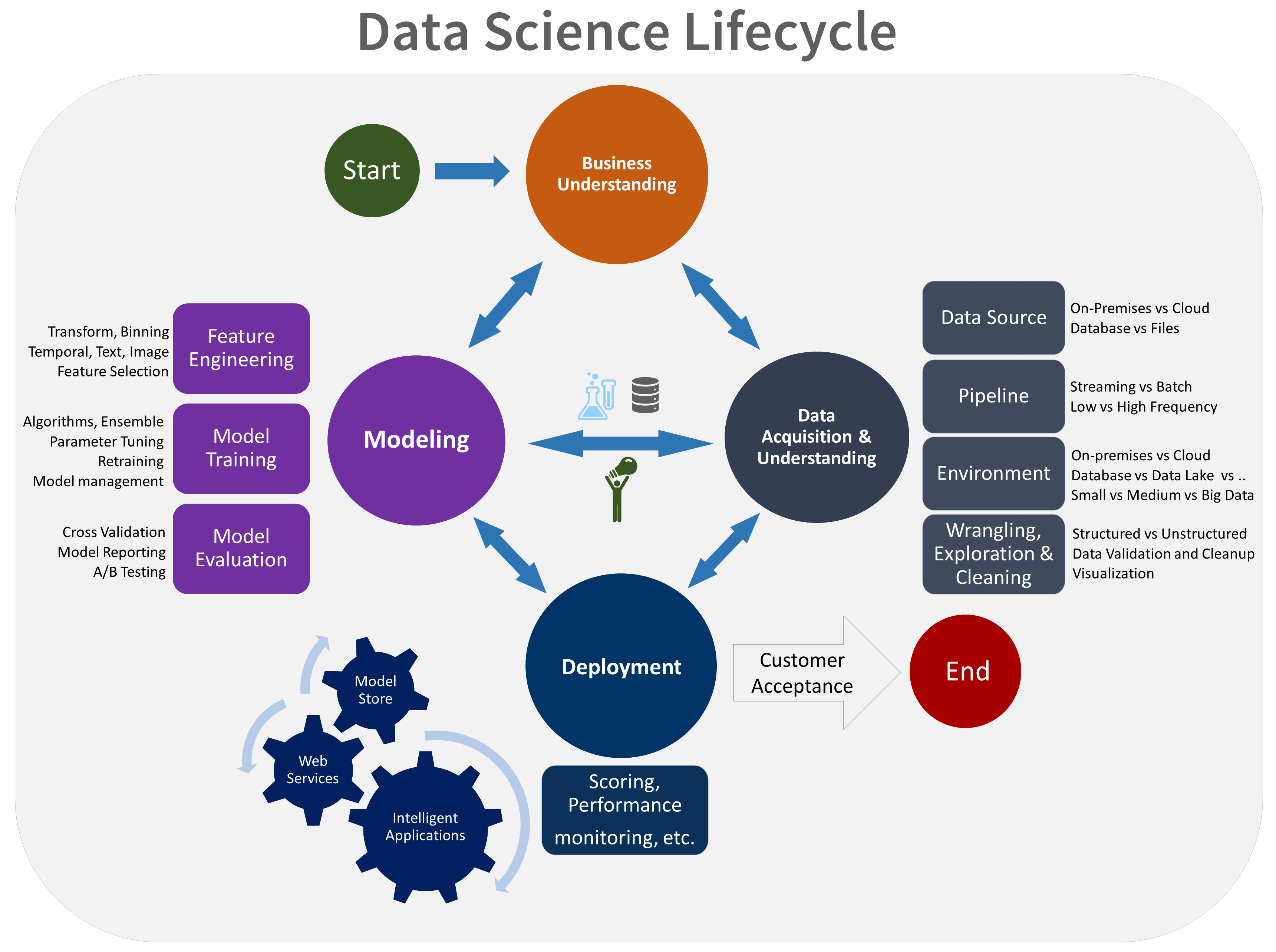
Objetivos
Os objetivos da etapa de aquisição e compreensão de dados são:
Produza um conjunto de dados limpo e de alta qualidade que se relacione claramente com as variáveis-alvo. Localize o conjunto de dados no ambiente de análise apropriado para que sua equipe esteja pronta para o estágio de modelagem.
Desenvolva uma arquitetura de solução do pipeline de dados que atualize e classifique os dados regularmente.
Como concluir as tarefas
A etapa de aquisição e compreensão de dados tem três tarefas principais:
Ingerir dados no ambiente analítico de destino.
Explore os dados para determinar se os dados podem responder à pergunta.
Configure um pipeline de dados para pontuar dados novos ou atualizados regularmente.
Ingerir dados
Configure um processo para mover dados dos locais de origem para os locais de destino onde você executa operações de análise, como treinamento e previsões.
Explorar dados
Antes de treinar seus modelos, você precisa desenvolver uma compreensão sólida dos dados. Os conjuntos de dados do mundo real são frequentemente barulhentos, não têm valores ou têm uma série de outras discrepâncias. Você pode usar o resumo e a visualização de dados para auditar a qualidade dos dados e coletar informações para processar os dados antes que estejam prontos para a modelagem. Este processo é muitas vezes iterativo. Para obter orientação sobre como limpar os dados, consulte Tarefas para preparar dados para aprendizado de máquina aprimorado.
Depois de estar satisfeito com a qualidade dos dados limpos, a próxima etapa é entender melhor os padrões nos dados. Esta análise de dados ajuda-o a escolher e desenvolver um modelo preditivo adequado para o seu alvo. Determine o quanto os dados correspondem ao destino. Em seguida, decida se sua equipe tem dados suficientes para avançar com as próximas etapas de modelagem. Mais uma vez, este processo é muitas vezes iterativo. Talvez seja necessário encontrar novas fontes de dados com dados mais precisos ou mais relevantes para ajustar o conjunto de dados inicialmente identificado na etapa anterior.
Configurar um pipeline de dados
Além de ingerir e limpar dados, você normalmente precisa configurar um processo para pontuar novos dados ou atualizá-los regularmente como parte de um processo de aprendizado contínuo. Você pode usar um pipeline de dados ou fluxo de trabalho para pontuar dados. Recomendamos um pipeline que use o Azure Data Factory.
Nesta etapa, você desenvolve uma arquitetura de solução do pipeline de dados. Você cria o pipeline em paralelo com a próxima etapa do projeto de ciência de dados. Dependendo das necessidades do seu negócio e das restrições dos seus sistemas existentes nos quais esta solução está a ser integrada, o pipeline pode ser:
- Baseado em lote
- Streaming ou em tempo real
- Híbrido
Integração com MLflow
Durante a fase de compreensão de dados, você pode usar o rastreamento de experimentos do MLflow para rastrear e documentar várias estratégias de pré-processamento de dados e análise exploratória de dados.
Artefactos
Nesta etapa, sua equipe entrega:
Um relatório de qualidade de dados que inclui resumos de dados, as relações entre cada atributo e destino, a classificação variável e muito mais.
Uma arquitetura de solução, como um diagrama ou uma descrição do pipeline de dados que sua equipe usa para executar previsões em novos dados. Este diagrama também contém o pipeline para treinar novamente seu modelo com base em novos dados. Quando você usa o modelo de estrutura de diretório TDSP, armazene o documento no diretório do projeto.
Uma decisão de ponto de verificação. Antes de começar a engenharia completa e a construção de modelos, você pode reavaliar o projeto para determinar se o valor esperado é suficiente para continuar a persegui-lo. Você pode, por exemplo, estar pronto para prosseguir, precisar coletar mais dados ou abandonar o projeto se não conseguir encontrar dados que respondam às perguntas.
Literatura revista por pares
Os pesquisadores publicam estudos sobre o TDSP na literatura revisada por pares. As citações oferecem uma oportunidade para investigar outras aplicações ou ideias semelhantes ao TDSP, incluindo a aquisição de dados e a compreensão do estágio do ciclo de vida.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Mark Tabladillo - Brasil | Arquiteto de Soluções Cloud Sênior
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Recursos relacionados
Estes artigos descrevem os outros estágios do ciclo de vida do TDSP:
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários