CQRS significa Command and Query Responsibility Segregation, um padrão que separa operações de leitura e atualização para um armazenamento de dados. A implementação do CQRS em seu aplicativo pode maximizar seu desempenho, escalabilidade e segurança. A flexibilidade criada pela migração para o CQRS permite que um sistema evolua melhor ao longo do tempo e evita que os comandos de atualização causem conflitos de mesclagem no nível do domínio.
Contexto e problema
Nas arquiteturas tradicionais, o mesmo modelo de dados é utilizado para consultar e atualizar uma base de dados. É simples e funciona bem para operações CRUD básicas. Nas aplicações mais complexas, no entanto, esta abordagem pode tornar-se difícil. Por exemplo, no lado de leitura, a aplicação pode efetuar várias consultas diferentes, devolvendo objetos de transferência de dados (DTOs) com formas diferentes. O mapeamento de objetos pode tornar-se complicado. No lado de escrita, o modelo pode implementar validação complexa e lógica de negócio. Como resultado, pode acabar por ficar com um modelo demasiado complexo, que faz demasiado.
As cargas de trabalho de leitura e gravação geralmente são assimétricas, com requisitos de desempenho e escala muito diferentes.
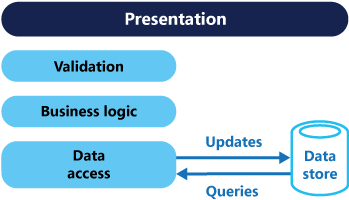
Muitas vezes, há uma incompatibilidade entre as representações de leitura e gravação dos dados, como colunas adicionais ou propriedades que devem ser atualizadas corretamente, mesmo que não sejam necessárias como parte de uma operação.
A contenção de dados pode ocorrer quando as operações são executadas em paralelo no mesmo conjunto de dados.
A abordagem tradicional pode ter um efeito negativo no desempenho devido à carga no armazenamento de dados e na camada de acesso a dados, e à complexidade das consultas necessárias para recuperar informações.
O gerenciamento de segurança e permissões pode se tornar complexo, porque cada entidade está sujeita a operações de leitura e gravação, que podem expor dados no contexto errado.
Solução
O CQRS separa leituras e gravações em modelos diferentes, usando comandos para atualizar dados e consultas para ler dados.
- Os comandos devem ser baseados em tarefas, em vez de centrados em dados. ("Reservar quarto de hotel", não "definir ReservationStatus como Reservado"). Isso pode exigir algumas alterações correspondentes no estilo de interação do usuário. A outra parte disso é analisar a modificação da lógica de negócios que processa esses comandos para serem bem-sucedidos com mais frequência. Uma técnica que suporta isso é executar algumas regras de validação no cliente antes mesmo de enviar o comando, possivelmente desativando botões, explicando por que na interface do usuário ("não há salas restantes"). Dessa forma, a causa das falhas de comando do lado do servidor pode ser reduzida às condições de corrida (dois usuários tentando reservar a última sala), e até mesmo essas às vezes podem ser resolvidas com mais alguns dados e lógica (colocando um convidado em uma lista de espera).
- Os comandos podem ser colocados em uma fila para processamento assíncrono, em vez de serem processados de forma síncrona.
- As consultas nunca modificam a base de dados. Uma consulta devolve um DTO que não encapsula qualquer conhecimento de domínio.
Os modelos podem então ser isolados, como mostrado no diagrama a seguir, embora isso não seja um requisito absoluto.
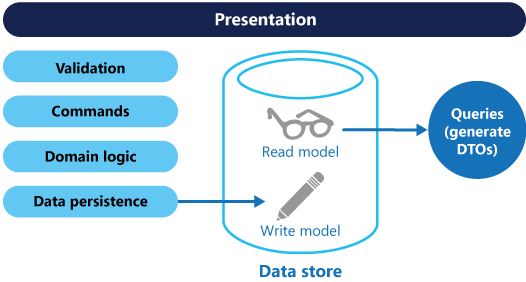
Ter modelos de consulta e atualização separados simplifica o design e a implementação. No entanto, uma desvantagem é que o código CQRS não pode ser gerado automaticamente a partir de um esquema de banco de dados usando mecanismos de andaime, como ferramentas O/RM (No entanto, você poderá construir sua personalização em cima do código gerado).
Para maior isolamento, pode separar fisicamente os dados de leitura dos dados de escrita. Nesse caso, a base de dados de leitura pode utilizar o seu próprio esquema de dados que está otimizado para consultas. Por exemplo, pode armazenar uma vista materializada dos dados, para evitar associações complexas ou mapeamentos de O/RM complexos. Poderá até utilizar um tipo diferente do arquivo de dados. Por exemplo, a base de dados de escrita pode ser relacional, enquanto a base de dados de leitura é uma base de dados de documentos.
Se forem usados bancos de dados de leitura e gravação separados, eles deverão ser mantidos sincronizados. Normalmente, isso é feito fazendo com que o modelo de gravação publique um evento sempre que atualizar o banco de dados. Para obter mais informações sobre como usar eventos, consulte Estilo de arquitetura orientada a eventos. Como os agentes de mensagens e bancos de dados geralmente não podem ser incluídos em uma única transação distribuída, pode haver desafios para garantir a consistência ao atualizar o banco de dados e publicar eventos. Para obter mais informações, consulte as orientações sobre processamento idempotente de mensagens.
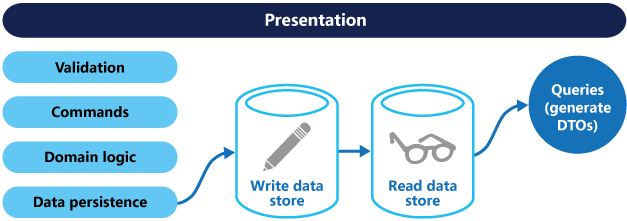
O arquivo de leitura pode ser uma réplica só de leitura do arquivo de escrita ou os arquivos de leitura e escrita podem ter uma estrutura completamente diferente. O uso de várias réplicas somente leitura pode aumentar o desempenho da consulta, especialmente em cenários distribuídos em que as réplicas somente leitura estão localizadas perto das instâncias do aplicativo.
A separação dos arquivos de leitura e escrita também permitem que cada um seja dimensionado adequadamente para corresponder à carga. Por exemplo, os arquivos de leitura encontram normalmente uma carga muito superior à dos arquivos de escrita.
Algumas implementações de CQRS utilizam o Padrão de Aprovisionamento de Eventos. Com este padrão, o estado da aplicação é armazenado como uma sequência de eventos. Cada evento representa um conjunto de alterações aos dados. O estado atual é construído ao reproduzir os eventos. Em um contexto CQRS, um benefício do Event Sourcing é que os mesmos eventos podem ser usados para notificar outros componentes — em particular, para notificar o modelo de leitura. O modelo de leitura utiliza os eventos para criar um instantâneo do estado atual, o que é mais eficiente para consultas. No entanto, o Aprovisionamento de Eventos adiciona complexidade à estrutura.
Os benefícios do CQRS incluem:
- Escalonamento independente. O CQRS permite que as cargas de trabalho de leitura e escrita sejam dimensionadas de forma independente, e poderá resultar em menos contenções de bloqueio.
- Esquemas de dados otimizados. O lado de leitura pode utilizar um esquema que está otimizado para consultas, enquanto o lado de escrita utiliza um esquema que está otimizado para atualizações.
- Segurança. É mais fácil garantir que apenas as entidades de domínio corretas estão a efetuar operações de escrita nos dados.
- Separação das preocupações. A separação dos lados de leitura e escrita pode resultar na criação de modelos que são mais flexíveis e sustentáveis. A maioria da lógica de negócio complexa vai para no modelo de escrita. O modelo de leitura pode ser relativamente simples.
- Consultas mais simples. Ao armazenar uma vista materializada na base de dados de leitura, a aplicação pode evitar associações complexas durante as consultas.
Questões e considerações relativas à aplicação
Alguns desafios da implementação desse padrão incluem:
Complexidade. A ideia básica do CQRS é simples. Mas pode levar a uma estrutura de aplicação mais complexa, especialmente se incluir o padrão de Aprovisionamento de Eventos.
Mensagens. Embora o CQRS não requeira mensagens, é comum utilizar mensagens para processar comandos e publicar eventos de atualização. Nesse caso, a aplicação deve processar falhas de mensagens ou mensagens duplicadas. Consulte as orientações sobre Filas de prioridade para lidar com comandos com prioridades diferentes.
Consistência eventual. Se separar as bases de dados de leitura e escrita, os dados de leitura poderão ficar obsoletos. O repositório de modelos de leitura deve ser atualizado para refletir as alterações no repositório de modelos de gravação e pode ser difícil detetar quando um usuário emitiu uma solicitação com base em dados de leitura obsoletos.
Quando usar o padrão CQRS
Considere o CQRS para os seguintes cenários:
Domínios colaborativos onde muitos utilizadores acedem aos mesmos dados em paralelo. O CQRS permite definir comandos com granularidade suficiente para minimizar conflitos de mesclagem no nível do domínio, e os conflitos que surgem podem ser mesclados pelo comando.
Interfaces de utilizador baseadas em tarefas nas quais os utilizadores são orientados através de um processo complexo como uma série de passos ou com modelos de domínio complexos. O modelo de gravação tem uma pilha completa de processamento de comandos com lógica de negócios, validação de entrada e validação de negócios. O modelo de gravação pode tratar um conjunto de objetos associados como uma única unidade para alterações de dados (um agregado, na terminologia DDD) e garantir que esses objetos estejam sempre em um estado consistente. O modelo de leitura não tem lógica de negócios ou pilha de validação e apenas retorna um DTO para uso em um modelo de exibição. O modelo de leitura é eventualmente consistente com o modelo de escrita.
Cenários em que o desempenho de leituras de dados deve ser ajustado separadamente do desempenho de gravações de dados, especialmente quando o número de leituras é muito maior do que o número de gravações. Nesse cenário, você pode expandir o modelo de leitura, mas executar o modelo de gravação em apenas algumas instâncias. Um pequeno número de instâncias do modelo de escrita também ajuda a minimizar a ocorrência de conflitos de intercalação.
Cenários onde uma equipa de programadores pode concentrar-se no modelo de domínio complexo que faz parte do modelo de escrita e outra equipa pode concentrar-se no modelo de leitura e nas interfaces de utilizador.
Cenários onde se espera que o sistema evolua ao longo do tempo e possa conter várias versões do modelo ou onde as regras de negócio são alteradas regularmente.
Integração com outros sistemas, especialmente em conjunto com a origem do evento, onde a falha temporária de um subsistema não deve afetar a disponibilidade dos outros.
Este padrão não é recomendado quando:
O domínio ou as regras de negócio são simples.
Uma interface de usuário simples no estilo CRUD e operações de acesso a dados são suficientes.
Considere aplicar o CQRS em secções limitadas do sistema onde será mais valioso.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão CQRS pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | A separação de operações de leitura e gravação em altas cargas de trabalho de leitura para gravação permite otimizações direcionadas de desempenho e dimensionamento para a finalidade específica de cada operação. - PE:05 Dimensionamento e particionamento - PE:08 Desempenho dos dados |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Fornecimento de eventos e padrão CQRS
O padrão CQRS é frequentemente utilizado juntamente com o padrão de Origem do Evento. Os sistemas baseados no CQRS utilizam modelos de leitura e escrita separados, cada um personalizado para tarefas relevantes e, muitas vezes, localizados em arquivos fisicamente separados. Quando utilizado com o padrão Origem do Evento, o arquivo de eventos é o modelo de escrita e a origem de informações oficial. O modelo de leitura de um sistema baseado no CQRS fornece vistas materializadas dos dados, normalmente, como vistas altamente desnormalizadas. Estas vistas são personalizadas para as interfaces e apresentam os requisitos da aplicação, o que ajuda a maximizar o desempenho da apresentação e da consulta.
Com o fluxo de eventos como arquivo de escrita, em vez dos dados reais num ponto no tempo, evita conflitos de atualização numa agregação única e maximiza o desempenho e a escalabilidade. Os eventos podem ser utilizados para gerar de forma assíncrona vistas materializadas dos dados utilizados para preencher o arquivo de leitura.
Uma vez que o arquivo de eventos é a origem de informações oficial, é possível eliminar as vistas materializadas e repetir todos os eventos anteriores para criar uma nova representação do estado atual quando o sistema evolui ou quando o modelo de leitura tem de ser alterado. As vistas materializadas estão em vigor numa cache só de leitura durável dos dados.
Quando utilizar o CQRS combinado com o padrão de Origem do Evento, considere o seguinte:
À semelhança de qualquer sistema onde os arquivos de escrita e leitura estão separados, os sistemas com base neste padrão são apenas eventualmente consistentes. Haverá algum atraso entre a geração do evento e a atualização do arquivo de dados.
O padrão adiciona complexidade pois o código tem de ser criado para iniciar e processar eventos e montar ou atualizar as vistas ou os objetos adequados necessários para as consultas ou um modelo de leitura. A complexidade do padrão CQRS quando utilizado com o padrão de Origem do Evento pode tornar mais difícil uma implementação bem-sucedida e precisa de uma abordagem diferente para a criação de sistemas. No entanto, a origem do evento pode tornar mais fácil modelar o domínio e reconstruir as vistas, ou criar novas, uma vez o objetivo das alterações nos dados é preservado.
Gerar vistas materializadas para utilizar no modelo de leitura ou nas projeções de dados ao reproduzir e processar os eventos para entidades ou coleções de entidades específicas pode exigir um tempo de processamento e uma utilização de recursos significativos. Tal é particularmente verdade se for necessário um resumo da análise dos valores durante longos períodos, porque todos os eventos associados podem ter de ser examinados. Resolva isso implementando instantâneos dos dados em intervalos agendados, como uma contagem total do número de uma ação específica que ocorreu ou o estado atual de uma entidade.
Exemplo de padrão CQRS
O código seguinte mostra alguns extratos de um exemplo de uma implementação do CQRS que utiliza definições diferentes para os modelos de leitura e escrita. As interfaces do modelo não ditam quaisquer funcionalidades dos arquivos de dados subjacentes e podem evoluir e ser otimizadas de forma independente, uma vez que são interfaces separadas.
O código seguinte mostra a definição do modelo de leitura.
// Query interface
namespace ReadModel
{
public interface ProductsDao
{
ProductDisplay FindById(int productId);
ICollection<ProductDisplay> FindByName(string name);
ICollection<ProductInventory> FindOutOfStockProducts();
ICollection<ProductDisplay> FindRelatedProducts(int productId);
}
public class ProductDisplay
{
public int Id { get; set; }
public string Name { get; set; }
public string Description { get; set; }
public decimal UnitPrice { get; set; }
public bool IsOutOfStock { get; set; }
public double UserRating { get; set; }
}
public class ProductInventory
{
public int Id { get; set; }
public string Name { get; set; }
public int CurrentStock { get; set; }
}
}
O sistema permite aos utilizadores classificar os produtos. O código de aplicação realiza esta operação com o comando RateProduct mostrado no código seguinte.
public interface ICommand
{
Guid Id { get; }
}
public class RateProduct : ICommand
{
public RateProduct()
{
this.Id = Guid.NewGuid();
}
public Guid Id { get; set; }
public int ProductId { get; set; }
public int Rating { get; set; }
public int UserId {get; set; }
}
O sistema utiliza a classe ProductsCommandHandler para processar os comandos enviados pela aplicação. Por norma, os clientes enviam comandos para o domínio através de um sistema de mensagens, tal como uma fila. O processador de comandos aceita estes comandos e invoca métodos da interface de domínio. A granularidade de cada comando é concebida para reduzir a possibilidade de pedidos em conflito. O código seguinte mostra uma descrição da classe ProductsCommandHandler.
public class ProductsCommandHandler :
ICommandHandler<AddNewProduct>,
ICommandHandler<RateProduct>,
ICommandHandler<AddToInventory>,
ICommandHandler<ConfirmItemShipped>,
ICommandHandler<UpdateStockFromInventoryRecount>
{
private readonly IRepository<Product> repository;
public ProductsCommandHandler (IRepository<Product> repository)
{
this.repository = repository;
}
void Handle (AddNewProduct command)
{
...
}
void Handle (RateProduct command)
{
var product = repository.Find(command.ProductId);
if (product != null)
{
product.RateProduct(command.UserId, command.Rating);
repository.Save(product);
}
}
void Handle (AddToInventory command)
{
...
}
void Handle (ConfirmItemsShipped command)
{
...
}
void Handle (UpdateStockFromInventoryRecount command)
{
...
}
}
Próximos passos
Os padrões e as orientações que se seguem são úteis ao implementar este padrão:
Manual Básico de Consistência de Dados. Explica os problemas que são normalmente encontrados devido a uma consistência eventual entre os arquivos de dados de leitura e escrita ao utilizar o padrão CQRS e a forma como estes problemas podem ser resolvidos.
Particionamento de dados horizontal, vertical e funcional. Descreve as práticas recomendadas para dividir dados em partições que podem ser gerenciadas e acessadas separadamente para melhorar a escalabilidade, reduzir a contenção e otimizar o desempenho.
O guia de padrões e práticas CQRS Journey (Percurso CQRS). Em particular, Introducing the Command Query Responsibility Segregation pattern explora o padrão e quando ele é útil, e Epilogue: Lessons Learned ajuda você a entender alguns dos problemas que surgem ao usar esse padrão.
Posts do blog de Martin Fowler:
Recursos relacionados
Padrão de Origem do Evento. Descreve em maior detalhe como a Origem do Evento pode ser utilizada com o padrão CQRS para simplificar as tarefas em domínios complexos ao melhorar o desempenho, a escalabilidade e a capacidade de resposta. Bem como o fornecimento de consistência para os dados transacionais enquanto mantém registos de auditoria completos e um histórico que pode permitir ações de compensação.
Padrão de Vista Materializada. O modelo de leitura de uma implementação do CQRS pode conter vistas materializadas dos dados do modelo de escrita. Em alternativa, utilize o modelo de leitura para gerar vistas materializadas.
Apresentação sobre melhores CQRS através de padrões assíncronos de interação do usuário