Este artigo descreve considerações para gerenciar dados em uma arquitetura de microsserviços. Como cada microsserviço gerencia seus próprios dados, a integridade e a consistência dos dados são desafios críticos.
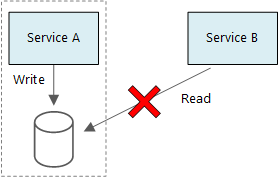
Um princípio básico dos microsserviços é o facto de cada serviço gerir os seus próprios dados. Dois serviços não devem compartilhar um armazenamento de dados. Em vez disso, cada serviço é responsável por seu próprio armazenamento de dados privado, que outros serviços não podem acessar diretamente.
A razão para esta regra é evitar o acoplamento não intencional entre serviços, o que pode resultar se os serviços partilharem os mesmos esquemas de dados subjacentes. Se houver uma alteração no esquema de dados, a alteração deverá ser coordenada em todos os serviços que dependem desse banco de dados. Ao isolar o armazenamento de dados de cada serviço, podemos limitar o escopo da alteração e preservar a agilidade de implantações verdadeiramente independentes. Outra razão é que cada microsserviço pode ter seus próprios modelos de dados, consultas ou padrões de leitura/gravação. O uso de um armazenamento de dados compartilhado limita a capacidade de cada equipe de otimizar o armazenamento de dados para seu serviço específico.
Essa abordagem leva naturalmente à persistência poliglota — o uso de várias tecnologias de armazenamento de dados em um único aplicativo. Um serviço pode exigir os recursos de esquema em leitura de um banco de dados de documentos. Outro pode precisar da integridade referencial fornecida por um RDBMS. Cada equipa é livre de fazer a melhor escolha para o seu serviço.
Nota
Não há problema em os serviços compartilharem o mesmo servidor de banco de dados físico. O problema ocorre quando os serviços compartilham o mesmo esquema ou ler e gravar no mesmo conjunto de tabelas de banco de dados.
Desafios
Alguns desafios surgem dessa abordagem distribuída para gerenciar dados. Primeiro, pode haver redundância nos armazenamentos de dados, com o mesmo item de dados aparecendo em vários locais. Por exemplo, os dados podem ser armazenados como parte de uma transação e, em seguida, armazenados em outro lugar para análise, relatórios ou arquivamento. Dados duplicados ou particionados podem levar a problemas de integridade e consistência dos dados. Quando as relações de dados abrangem vários serviços, você não pode usar técnicas tradicionais de gerenciamento de dados para impor as relações.
A modelagem de dados tradicional usa a regra de "um fato em um só lugar". Cada entidade aparece exatamente uma vez no esquema. Outras entidades podem ter referências a ele, mas não duplicá-lo. A vantagem óbvia da abordagem tradicional é que as atualizações são feitas em um único lugar, o que evita problemas com a consistência dos dados. Em uma arquitetura de microsserviços, você precisa considerar como as atualizações são propagadas entre serviços e como gerenciar a eventual consistência quando os dados aparecem em vários locais sem consistência forte.
Abordagens para gerenciar dados
Não há uma abordagem única que seja correta em todos os casos, mas aqui estão algumas diretrizes gerais para gerenciar dados em uma arquitetura de microsserviços.
Adote a consistência eventual sempre que possível. Entenda os lugares no sistema onde você precisa de consistência forte ou transações ACID, e os lugares onde uma eventual consistência é aceitável.
Quando você precisa de fortes garantias de consistência, um serviço pode representar a fonte da verdade para uma determinada entidade, que é exposta por meio de uma API. Outros serviços podem ter sua própria cópia dos dados, ou um subconjunto dos dados, que seja eventualmente consistente com os dados mestres, mas não seja considerado a fonte da verdade. Por exemplo, imagine um sistema de e-commerce com um serviço de pedido do cliente e um serviço de recomendação. O serviço de recomendação pode ouvir eventos do serviço de pedidos, mas se um cliente solicitar um reembolso, é o serviço de pedidos, não o serviço de recomendação, que tem o histórico completo de transações.
Para transações, use padrões como Scheduler Agent Supervisor e Compensating Transaction para manter os dados consistentes em vários serviços. Talvez seja necessário armazenar uma parte adicional de dados que capture o estado de uma unidade de trabalho que abrange vários serviços, para evitar falha parcial entre vários serviços. Por exemplo, mantenha um item de trabalho em uma fila durável enquanto uma transação de várias etapas estiver em andamento.
Armazene apenas os dados de que um serviço precisa. Um serviço pode precisar apenas de um subconjunto de informações sobre uma entidade de domínio. Por exemplo, no contexto de Envio limitado, precisamos saber qual cliente está associado a uma determinada entrega. Mas não precisamos do endereço de cobrança do cliente, que é gerenciado pelo contexto limitado de Contas. Pensar cuidadosamente sobre o domínio, e usar uma abordagem DDD, pode ajudar aqui.
Considere se os seus serviços são coerentes e estão ligados de forma flexível. Se dois serviços estiverem trocando informações continuamente um com o outro, resultando em APIs tagarelas, talvez seja necessário redesenhar os limites do serviço, mesclando dois serviços ou refatorando suas funcionalidades.
Use um estilo de arquitetura orientada a eventos. Nesse estilo de arquitetura, um serviço publica um evento quando há alterações em seus modelos públicos ou entidades. Os serviços interessados podem inscrever-se nestes eventos. Por exemplo, outro serviço poderia usar os eventos para construir uma exibição materializada dos dados que é mais adequada para consulta.
Um serviço proprietário de eventos deve publicar um esquema que possa ser usado para automatizar a serialização e a desserialização dos eventos, para evitar o acoplamento rígido entre editores e assinantes. Considere o esquema JSON ou uma estrutura como Microsoft Bond, Protobuf ou Avro.
Em alta escala, os eventos podem se tornar um gargalo no sistema, portanto, considere usar agregação ou lotes para reduzir a carga total.
Exemplo: Escolher armazenamentos de dados para a aplicação Drone Delivery
Os artigos anteriores desta série discutem um serviço de entrega por drone como um exemplo em execução. Você pode ler mais sobre o cenário e a implementação de referência correspondente aqui. Este exemplo é ideal para as indústrias aeronáutica e aeroespacial.
Para recapitular, esta aplicação define vários microsserviços para agendar entregas por drone. Quando um usuário agenda uma nova entrega, a solicitação do cliente inclui informações sobre a entrega, como locais de retirada e entrega, e sobre o pacote, como tamanho e peso. Esta informação define uma unidade de trabalho.
Os vários serviços de back-end se preocupam com diferentes partes das informações na solicitação, e também têm diferentes perfis de leitura e gravação.
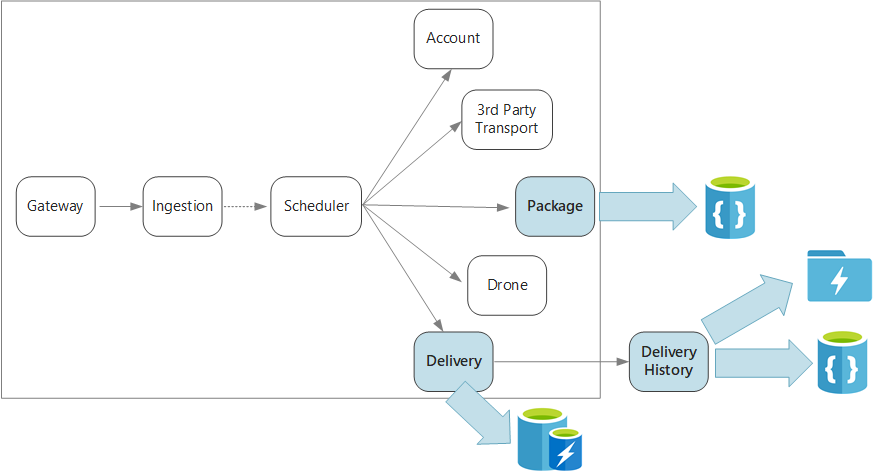
Serviço de entregas
O serviço de Entrega armazena informações sobre todas as entregas atualmente programadas ou em andamento. Ele ouve os eventos dos drones e rastreia o status das entregas que estão em andamento. Ele também envia eventos de domínio com atualizações de status de entrega.
Espera-se que os usuários verifiquem frequentemente o status de uma entrega enquanto aguardam seu pacote. Portanto, o serviço de entrega requer um armazenamento de dados que enfatiza a taxa de transferência (leitura e gravação) sobre o armazenamento de longo prazo. Além disso, o serviço de entrega não realiza consultas ou análises complexas, ele simplesmente busca o status mais recente para uma determinada entrega. A equipe do serviço de Entrega escolheu o Cache Redis do Azure por seu alto desempenho de leitura-gravação. A informação armazenada no Redis é relativamente de curta duração. Quando uma entrega é concluída, o serviço de Histórico de Entregas é o sistema de registro.
Serviço de Histórico de Entregas
O serviço Histórico de Entregas escuta os eventos de status de entrega do serviço de Entrega. Ele armazena esses dados em armazenamento de longo prazo. Há dois casos de uso diferentes para esses dados históricos, que têm requisitos de armazenamento de dados diferentes.
O primeiro cenário é agregar os dados para fins de análise de dados, a fim de otimizar o negócio ou melhorar a qualidade do serviço. Observe que o serviço Histórico de Entregas não executa a análise real dos dados. É apenas responsável pela ingestão e armazenamento. Para esse cenário, o armazenamento deve ser otimizado para análise de dados em um grande conjunto de dados, usando uma abordagem de esquema em leitura para acomodar uma variedade de fontes de dados. O Repositório Azure Data Lake é uma boa opção para esse cenário. O Repositório Data Lake é um sistema de arquivos Apache Hadoop compatível com o Hadoop Distributed File System (HDFS) e é ajustado para desempenho em cenários de análise de dados.
O outro cenário é permitir que os usuários pesquisem o histórico de uma entrega após a conclusão da entrega. O Azure Data Lake não está otimizado para este cenário. Para um desempenho ideal, a Microsoft recomenda armazenar dados de séries cronológicas no Data Lake em pastas particionadas por data. (Ver Ajustando o Repositório Azure Data Lake para desempenho). No entanto, essa estrutura não é ideal para pesquisar registros individuais por ID. A menos que você também conheça o carimbo de data/hora, uma pesquisa por ID requer a verificação de toda a coleção. Portanto, o serviço Histórico de Entrega também armazena um subconjunto dos dados históricos no Azure Cosmos DB para uma pesquisa mais rápida. Os registros não precisam permanecer no Azure Cosmos DB indefinidamente. As entregas mais antigas podem ser arquivadas — por exemplo, após um mês. Isso pode ser feito executando um processo em lote ocasional. O arquivamento de dados mais antigos pode reduzir os custos do Cosmos DB e, ao mesmo tempo, manter os dados disponíveis para relatórios históricos do Data Lake.
Serviço de empacotamento
O serviço de pacote armazena informações sobre todos os pacotes. Os requisitos de armazenamento para o pacote são:
- Armazenamento a longo prazo.
- Capaz de lidar com um grande volume de pacotes, exigindo alta taxa de transferência de gravação.
- Suporta consultas simples por ID de pacote. Sem junções complexas ou requisitos de integridade referencial.
Como os dados do pacote não são relacionais, um banco de dados orientado a documentos é apropriado e o Azure Cosmos DB pode obter alta taxa de transferência usando coleções fragmentadas. A equipe que trabalha no serviço de pacote está familiarizada com a pilha MEAN (MongoDB, Express.js, AngularJS, e Node.js), portanto, eles selecionam a API do MongoDB para o Azure Cosmos DB. Isso permite que eles aproveitem sua experiência existente com o MongoDB, enquanto obtêm os benefícios do Azure Cosmos DB, que é um serviço gerenciado do Azure.
Próximos passos
Saiba mais sobre padrões de design que podem ajudar a mitigar alguns desafios comuns em uma arquitetura de microsserviços.