Decomponha uma tarefa que realiza processamento complexo numa série de elementos separados que podem ser reutilizados. Isso pode melhorar o desempenho, a escalabilidade e a reutilização, permitindo que os elementos da tarefa que executam o processamento sejam implantados e dimensionados de forma independente.
Contexto e problema
Você tem um pipeline de tarefas sequenciais que precisa processar. Uma abordagem simples, mas inflexível, para implementar este aplicativo é executar esse processamento em um módulo monolítico. No entanto, essa abordagem provavelmente reduzirá as oportunidades de refatoração do código, otimizando-o ou reutilizando-o se partes do mesmo processamento forem necessárias em outro lugar do aplicativo.
O diagrama a seguir ilustra um dos problemas com o processamento de dados usando uma abordagem monolítica, a incapacidade de reutilizar o código em vários pipelines. Neste exemplo, um aplicativo recebe e processa dados de duas fontes. Um módulo separado processa os dados de cada fonte executando uma série de tarefas para transformar os dados antes de passar o resultado para a lógica de negócios do aplicativo.
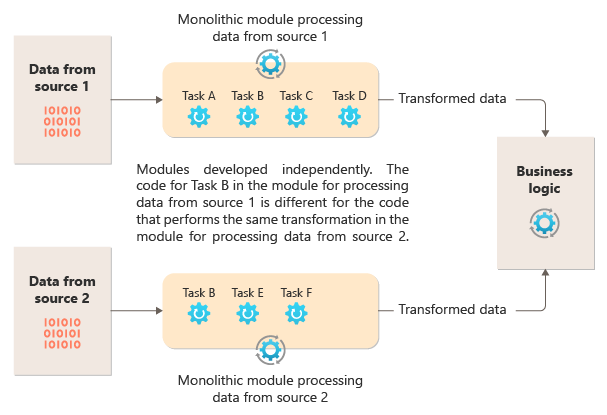
Algumas das tarefas que os módulos monolíticos executam são funcionalmente semelhantes, mas o código tem que ser repetido em ambos os módulos e provavelmente está firmemente acoplado dentro de seu módulo. Além da incapacidade de reutilizar a lógica, esta abordagem introduz um risco quando os requisitos mudam. Você deve se lembrar de atualizar o código em ambos os lugares.
Existem outros desafios com uma implementação monolítica não relacionada a vários pipelines ou reutilização. Com um monólito, você não tem a capacidade de executar tarefas específicas em diferentes ambientes ou dimensioná-las de forma independente. Algumas tarefas podem ser de computação intensiva e se beneficiariam da execução em hardware poderoso ou da execução de várias instâncias em paralelo. Outras tarefas podem não ter os mesmos requisitos. Além disso, com monólitos, é um desafio reordenar tarefas ou injetar novas tarefas no pipeline. Essas alterações exigem um novo teste de todo o pipeline.
Solução
Divida o processamento necessário para cada fluxo para um conjunto de componentes (ou filtros) separados, cada um a executar uma única tarefa. Os filtros são compostos em tubulações, conectando os filtros com tubos. Os filtros recebem mensagens de um pipe de entrada e publicam mensagens em um pipe de saída diferente. Os tubos não executam roteamento ou qualquer outra lógica. Eles apenas conectam filtros, passando a mensagem de saída de um filtro como a entrada para o próximo.
Os filtros agem de forma independente e não têm conhecimento de outros filtros. Eles só estão cientes de seus esquemas de entrada e saída. Como tal, os filtros podem ser organizados em qualquer ordem, desde que o esquema de entrada para qualquer filtro corresponda ao esquema de saída para o filtro anterior. O uso de um esquema padronizado para todos os filtros aumenta a capacidade de reordenar os filtros.
O acoplamento solto dos filtros torna mais fácil:
- Criar novos pipelines compostos por filtros existentes
- Atualizar ou substituir lógica em filtros individuais
- Reordenar filtros, quando necessário
- Execute filtros em hardware diferente, quando necessário
- Executar filtros em paralelo
Este diagrama mostra uma solução implementada com tubos e filtros:
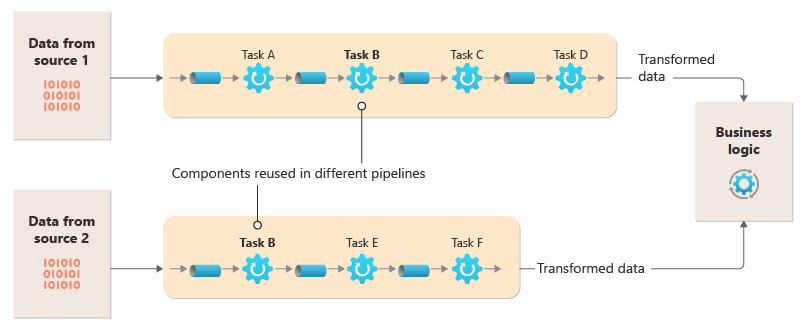
O tempo necessário para processar uma única solicitação depende da velocidade dos filtros mais lentos no pipeline. Um ou mais filtros podem ser gargalos, especialmente se um grande número de solicitações aparecer em um fluxo de uma fonte de dados específica. A capacidade de executar instâncias paralelas de filtros lentos permite que o sistema espalhe a carga e melhore a taxa de transferência.
A capacidade de executar filtros em diferentes instâncias de computação permite que eles sejam dimensionados de forma independente e aproveitem a elasticidade que muitos ambientes de nuvem oferecem. Um filtro que é computacionalmente intensivo pode ser executado em hardware de alto desempenho, enquanto outros filtros menos exigentes podem ser hospedados em hardware de mercadoria menos caro. Os filtros nem precisam estar no mesmo datacenter ou localização geográfica, permitindo que cada elemento de um pipeline seja executado em um ambiente próximo aos recursos necessários. Este diagrama mostra um exemplo aplicado ao pipeline para os dados da Fonte 1:
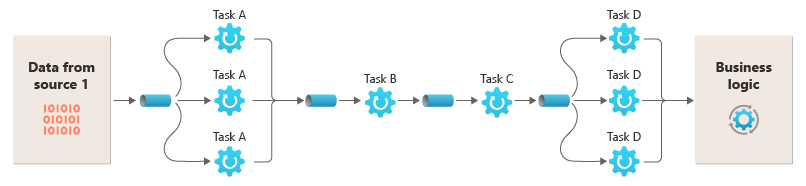
Se a entrada e a saída de um filtro forem estruturadas como um fluxo, você poderá executar o processamento de cada filtro em paralelo. O primeiro filtro no pipeline pode iniciar seu trabalho e produzir seus resultados, que são passados diretamente para o próximo filtro na sequência antes que o primeiro filtro conclua seu trabalho.
Usar o padrão Pipes and Filters juntamente com o padrão Compensating Transaction é uma abordagem alternativa para implementar transações distribuídas. Você pode dividir uma transação distribuída em tarefas separadas e compensáveis, cada uma das quais pode ser implementada por meio de um filtro que também implementa o padrão de Transação de Compensação. Você pode implementar os filtros em um pipeline como tarefas hospedadas separadas que são executadas perto dos dados que eles mantêm.
Problemas e considerações
Considere os seguintes pontos ao decidir como implementar esse padrão:
Complexidade. O aumento da flexibilidade que este padrão fornece também pode fornecer complexidade, especialmente se os filtros num pipeline forem distribuídos por servidores diferentes.
Fiabilidade. Use uma infraestrutura que garanta que os dados que fluem entre filtros em um pipe não sejam perdidos.
Idempotência. Se um filtro em um pipeline falhar depois de receber uma mensagem e o trabalho for reagendado para outra instância do filtro, parte do trabalho pode já estar concluída. Se o trabalho atualizar algum aspeto do estado global (como informações armazenadas em um banco de dados), uma única atualização poderá ser repetida. Um problema semelhante pode ocorrer se um filtro falhar depois de publicar seus resultados no próximo filtro, mas antes de indicar que concluiu seu trabalho com êxito. Nesses casos, outra instância do filtro pode repetir esse trabalho, fazendo com que os mesmos resultados sejam postados duas vezes. Esse cenário pode resultar em filtros subsequentes no pipeline processando os mesmos dados duas vezes. Portanto, os filtros em um pipeline devem ser projetados para serem idempotentes. Para obter mais informações, consulte Padrões de idempotência no blog de Jonathan Oliver.
Mensagens repetidas. Se um filtro em um pipeline falhar depois de postar uma mensagem para o próximo estágio do pipeline, outra instância do filtro poderá ser executada e ele postará uma cópia da mesma mensagem no pipeline. Esse cenário pode fazer com que duas instâncias da mesma mensagem sejam passadas para o próximo filtro. Para evitar esse problema, o pipeline deve detetar e eliminar mensagens duplicadas.
Nota
Se você implementar o pipeline usando filas de mensagens (como filas do Barramento de Serviço do Azure), a infraestrutura de enfileiramento de mensagens poderá fornecer deteção e remoção automática de mensagens duplicadas.
Contexto e estado. Num pipeline, cada filtro é executado essencialmente em isolamento e não deve criar qualquer pressuposto sobre a forma como foi invocado, Portanto, cada filtro deve ser fornecido com contexto suficiente para executar seu trabalho. Este contexto poderia incluir uma quantidade significativa de informações estatais. Se os filtros usarem estado externo, como dados em um banco de dados ou armazenamento externo, você deverá considerar o impacto no desempenho. Cada filtro tem que carregar, operar e persistir esse estado, o que adiciona sobrecarga sobre soluções que carregam o estado externo uma única vez.
Tolerância de mensagens. Os filtros devem ser tolerantes com os dados na mensagem recebida contra os quais não operam. Eles operam com base nos dados pertinentes a eles e ignoram outros dados e os transmitem inalterados na mensagem de saída.
Tratamento de erros - Cada filtro deve determinar o que fazer no caso de um erro de quebra. O filtro deve determinar se ele falha no pipeline ou propaga a exceção.
Quando utilizar este padrão
Utilize este padrão quando:
O processamento exigido a uma aplicação puder ser facilmente dividido num conjunto de passos independentes.
Os passos do processamento realizados por uma aplicação tiverem requisitos de escalabilidade diferentes.
Nota
Você pode agrupar filtros que devem ser dimensionados juntos no mesmo processo. Para obter mais informações, veja o Padrão de Consolidação de Recursos de Computação.
Você precisa de flexibilidade para permitir a reordenação das etapas de processamento que o aplicativo executa ou para permitir a capacidade de adicionar e remover etapas.
O sistema puder beneficiar da distribuição dos passos de processamento por servidores diferentes.
Você precisa de uma solução confiável que minimize os efeitos da falha em uma etapa enquanto os dados estão sendo processados.
Este padrão poderá não ser prático quando:
O aplicativo segue um padrão de solicitação-resposta.
O processamento da tarefa deve ser concluído como parte de uma solicitação inicial, como um cenário de solicitação/resposta.
As etapas de processamento executadas por um aplicativo não são independentes ou precisam ser executadas juntas como parte de uma única transação.
A quantidade de contexto ou informações de estado que uma etapa requer torna essa abordagem ineficiente. Talvez seja possível persistir as informações de estado em um banco de dados, mas não use essa estratégia se a carga extra no banco de dados causar contenção excessiva.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão Pipes and Filters pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | A responsabilidade única de cada etapa permite uma atenção focada e evita a distração do processamento de dados combinados. - RE:01 Simplicidade - RE:07 Trabalhos em segundo plano |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
Pode utilizar uma sequência de filas de mensagens para fornecer a infraestrutura necessária para implementar um pipeline. Uma fila de mensagens inicial recebe mensagens não processadas que se tornam o início da implementação do padrão de pipes e filtros. Um componente implementado como uma tarefa de filtro escuta uma mensagem nessa fila, executa seu trabalho e, em seguida, posta uma mensagem nova ou transformada na próxima fila na sequência. Outra tarefa de filtro pode ouvir mensagens nessa fila, processá-las, postar os resultados em outra fila e assim por diante, até a etapa final que termina o processo de pipes e filtros. Este diagrama ilustra um pipeline que usa filas de mensagens:

Um pipeline de processamento de imagem pode ser implementado usando esse padrão. Se a sua carga de trabalho tiver uma imagem, a imagem poderá passar por uma série de filtros amplamente independentes e reordenáveis para executar ações como:
- moderação de conteúdo
- redimensionar
- marca d'água
- reorientação
- Remoção de metadados Exif
- Publicação da rede de distribuição de conteúdos (CDN)
Neste exemplo, os filtros podem ser implementados como Azure Functions implantados individualmente ou até mesmo um único aplicativo Azure Function que contenha cada filtro como uma implantação isolada. O uso de gatilhos do Azure Function, associações de entrada e associações de saída pode simplificar o código de filtro e trabalhar automaticamente com um pipe baseado em fila usando uma verificação de declaração para a imagem a ser processada.

Aqui está um exemplo de como um filtro, implementado como uma Função do Azure, acionado a partir de um pipe de Armazenamento de Fila com uma verificação de declaração na imagem e escrever uma nova verificação de declaração em outro pipe de Armazenamento de Fila pode parecer. Substituímos a implementação por pseudocódigo nos comentários para maior brevidade. Mais código como este pode ser encontrado na demonstração do padrão Pipes and Filters disponível no GitHub.
// This is the "Resize" filter. It handles claim checks from input pipe, performs the
// resize work, and places a claim check in the next pipe for anther filter to handle.
[Function(nameof(ResizeFilter))]
[QueueOutput("pipe-fjur", Connection = "pipe")] // Destination pipe claim check
public async Task<string> RunAsync(
[QueueTrigger("pipe-xfty", Connection = "pipe")] string imageFilePath, // Source pipe claim check
[BlobInput("{QueueTrigger}", Connection = "pipe")] BlockBlobClient imageBlob) // Image to process
{
_logger.LogInformation("Processing image {uri} for resizing.", imageBlob.Uri);
// Idempotency checks
// ...
// Download image based on claim check in queue message body
// ...
// Resize the image
// ...
// Write resized image back to storage
// ...
// Create claim check for image and place in the next pipe
// ...
_logger.LogInformation("Image resizing done or not needed. Adding image {filePath} into the next pipe.", imageFilePath);
return imageFilePath;
}
Nota
O Spring Integration Framework tem uma implementação do padrão de tubos e filtros.
Próximos passos
Você pode achar os seguintes recursos úteis ao implementar esse padrão:
- Uma demonstração do padrão de tubos e filtros usando o cenário de processamento de imagem está disponível no GitHub.
- Padrões de idempotência, no blog de Jonathan Oliver.
Recursos relacionados
Os padrões a seguir também podem ser relevantes quando você implementa esse padrão:
- Padrão Claim-Check. Um pipeline implementado usando uma fila pode não conter o item real que está sendo enviado através dos filtros, mas sim um ponteiro para os dados que precisam ser processados. O exemplo usa uma verificação de declaração no Armazenamento de Filas do Azure para imagens armazenadas no Armazenamento de Blobs do Azure.
- Padrão de Consumidores Concorrentes. Um pipeline pode conter várias instâncias de um ou mais filtros. Essa abordagem é útil para executar instâncias paralelas de filtros lentos. Ele permite que o sistema espalhe a carga e melhore o rendimento. Cada instância de um filtro compete pela entrada com as outras instâncias, mas duas instâncias de um filtro não devem ser capazes de processar os mesmos dados. Este artigo explica a abordagem.
- Padrão de Consolidação de Recursos de Computação. Talvez seja possível agrupar filtros que devem ser dimensionados em um único processo. Este artigo fornece mais informações sobre os benefícios e compensações dessa estratégia.
- Padrão Transação de Compensação. Você pode implementar um filtro como uma operação que pode ser revertida ou que tem uma operação de compensação que restaura o estado para uma versão anterior se houver uma falha. Este artigo explica como você pode implementar esse padrão para manter ou alcançar uma eventual consistência.
- Tubos e Filtros - Padrões de Integração Empresarial.