Controle o consumo dos recursos utilizados por uma instância de uma aplicação, um inquilino individual ou um serviço completo. Deste modo, pode permitir que o sistema continue a funcionar e a cumprir os contratos de nível de serviço, mesmo quando um aumento da procura coloca uma carga extrema sobre os recursos.
Contexto e problema
A carga em um aplicativo na nuvem normalmente varia ao longo do tempo com base no número de usuários ativos ou nos tipos de atividades que eles estão realizando. Por exemplo, é provável que mais utilizadores estejam ativos durante o horário comercial ou o sistema poderá ter de realizar análises computacionalmente dispendiosas no final de cada mês. Também poderá haver bursts repentinos e inesperados na atividade. Se os requisitos de processamento do sistema excederem a capacidade dos recursos que estão disponíveis, este terá um desempenho fraco e até poderá falhar. Se o sistema tiver de satisfazer um nível de serviço acordado, essa falha poderá ser inaceitável.
Há muitas estratégias disponíveis para lidar com cargas variáveis na nuvem, dependendo dos objetivos de negócios para o aplicativo. Uma estratégia é usar o dimensionamento automático para fazer corresponder os recursos provisionados às necessidades do usuário a qualquer momento. Deste modo, tem o potencial satisfazer de forma consistente a procura do utilizador, ao otimizar os custos em execução. No entanto, embora o dimensionamento automático possa acionar o provisionamento de mais recursos, esse provisionamento não é imediato. Se a procura crescer rapidamente, poderá verificar-se deficit de recursos num determinado período de tempo.
Solução
Uma estratégia alternativa ao dimensionamento automático é permitir que as aplicações utilizem recursos apenas até um limite e, em seguida, limitá-los quando este limite for atingido. O sistema deve monitorizar como está a utilizar os recursos para que, quando a utilização exceder o limiar, possa limitar os pedidos de um ou mais utilizadores. Isso permite que o sistema continue funcionando e atenda a quaisquer SLAs (Service Level Agreements, contratos de nível de serviço) em vigor. Para obter mais informações sobre como monitorizar a utilização de recursos, veja Orientações sobre a Instrumentação e a Telemetria.
O sistema pode implementar várias estratégias de limitação, incluindo:
Rejeitar pedidos de um utilizador individual que já acedeu às APIs do sistema mais do que n vezes por segundo ao longo de um determinado período de tempo. Esta ação requer que o sistema meça a utilização dos recursos por parte de cada inquilino ou utilizador a executar uma aplicação. Para obter mais informações, veja Orientações sobre a Medição de Serviço.
Desativar ou degradar a funcionalidade de serviços não essenciais selecionados para que os serviços essenciais possam ser executados sem entraves com recursos suficientes. Por exemplo, se a aplicação estiver a transmitir em fluxo a saída de vídeo, pode mudar para uma resolução inferior.
Utilizar o nivelamento de carga para suavizar o volume de atividade (esta abordagem é descrita de forma mais detalhada pelo Padrão de Nivelamento de Carga Baseado na Fila). Em um ambiente multilocatário, essa abordagem reduzirá o desempenho de cada locatário. Se o sistema tiver de suportar uma mistura de inquilinos com SLAs diferentes, o trabalho dos inquilinos de elevado valor poderá ser executado imediatamente. Os pedidos de outros inquilinos podem ser retidos e processados quando o registo de tarefas pendentes tiver abrandado. O padrão de fila de prioridade pode ser usado para ajudar a implementar essa abordagem, assim como expor diferentes pontos de extremidade para os diferentes níveis/prioridades de serviço.
Diferir operações a executar em nome de inquilinos ou aplicações de prioridade inferior. Estas operações podem ser suspensas ou limitadas, com uma exceção gerada para informar o inquilino de que o sistema está ocupado e que a operação deve ser repetida mais tarde.
Você deve ter cuidado ao integrar com alguns serviços de terceiros que podem ficar indisponíveis ou retornar erros. Reduza o número de solicitações simultâneas sendo processadas para que os logs não se encham desnecessariamente de erros. Você também evita os custos associados à repetição desnecessária do processamento de solicitações que falhariam por causa desse serviço de 3ª parte. Em seguida, quando as solicitações forem processadas com êxito, volte para o processamento regular de solicitações não limitadas. Uma biblioteca que implementa essa funcionalidade é o NServiceBus.
A figura mostra um gráfico de área para a utilização de recursos (combinação de memória, CPU, largura de banda e outros fatores) relativamente ao tempo das aplicações que estão a utilizar as três funcionalidades. Uma funcionalidade é uma área de funcionalidade como um componente que executa um conjunto específico de tarefas, um fragmento de código que realiza um cálculo complexo ou um elemento que proporciona um serviço, como uma cache de memória. Estas funcionalidades têm as etiquetas A, B e C.
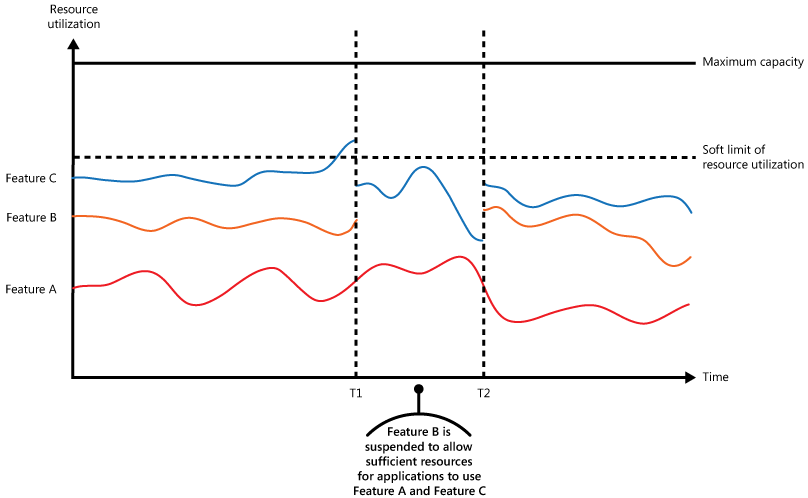
A área imediatamente abaixo da linha d e uma funcionalidade indica os recursos que são utilizados pelas aplicações quando invocam esta funcionalidade. Por exemplo, a área abaixo da linha da Funcionalidade A mostra os recursos utilizados pelas aplicações que estão a utilizar a Funcionalidade A e a área entre as linhas da Funcionalidade A e da Funcionalidade B indica os recursos utilizados pelas aplicações que invocam a Funcionalidade B. Ao agregar as áreas para cada funcionalidade, mostra a utilização total de recursos do sistema.
A figura anterior ilustra os efeitos que surgem depois de diferir as operações. Antes do período de tempo T1, o total de recursos atribuídos a todas as aplicações que utilizam estas funcionalidades atinge um limiar (o limite de utilização de recursos). Neste momento, as aplicações estão em risco de esgotar os recursos disponíveis. Neste sistema, a Funcionalidade B é menos crítica do que a Funcionalidade A ou a Funcionalidade C, pelo que está temporariamente desativada e os recursos que estava a utilizar são libertados. Entre os períodos de tempo T1 e T2, as aplicações que utilizam a Funcionalidade A e a Funcionalidade C continuam a ser executadas normalmente. Eventualmente, a utilização de recursos destas duas funcionalidades diminui até a um ponto que, no período de tempo T2, há capacidade suficiente para ativar a Funcionalidade B novamente.
As abordagens de dimensionamento automático e limitação também podem ser conjugadas para ajudar a manter as aplicações reativas e dentro dos SLAs. Se se espera que a demanda permaneça alta, a limitação fornece uma solução temporária enquanto o sistema se expande. Neste ponto, a funcionalidade completa do sistema pode ser restaurada.
A figura seguinte mostra um gráfico de área da utilização de recursos global por todas as aplicações em execução num sistema relativamente ao tempo e ilustra a forma como a limitação pode ser conjugada com o dimensionamento automático.
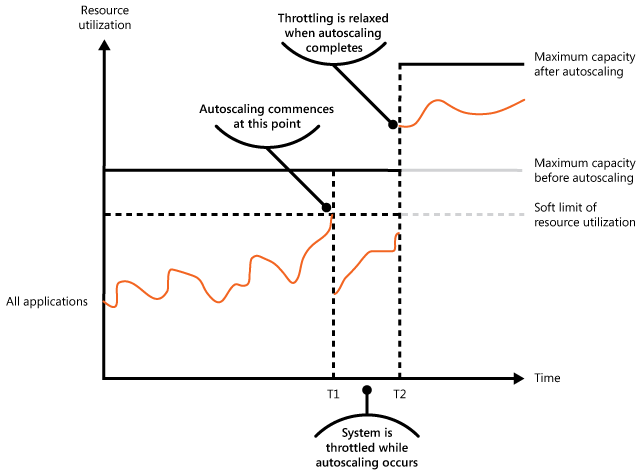
No período de tempo T1, foi atingido o limiar que especifica o limite não restritivo da utilização de recursos. Neste ponto, o sistema pode começar a escalar. No entanto, se os novos recursos não estiverem disponíveis com rapidez suficiente, os recursos existentes poderão esgotar-se e o sistema poderá falhar. Para impedir que tal aconteça, o sistema é temporariamente limitado, conforme descrito anteriormente. Quando o dimensionamento automático for concluído e os recursos extras estiverem disponíveis, a limitação poderá ser relaxada.
Problemas e considerações
Deve considerar os seguintes pontos ao decidir como implementar este padrão:
A limitação de uma aplicação e a definição de uma estratégia a utilizar são uma decisão arquitetural que afeta toda a conceção de um sistema. A limitação deve ser considerada no início do processo de conceção da aplicação, porque não é fácil adicioná-la depois de implementar um sistema.
A limitação tem de ser realizada rapidamente. O sistema tem de ser capaz de detetar um aumento na atividade e reagir em conformidade. O sistema também deve conseguir reverter para o estado original rapidamente depois de a carga ter abrandado. Para tal, é preciso que os dados de desempenho adequados sejam capturados e monitorizados continuamente.
Se um serviço precisar negar uma solicitação de usuário temporariamente, ele deve retornar um código de erro específico, como 429 ("Muitas solicitações") e 503 ("Servidor muito ocupado") para que o aplicativo cliente possa entender que o motivo da recusa em atender uma solicitação é devido à limitação.
- HTTP 429 indica que o aplicativo de chamada enviou muitas solicitações em uma janela de tempo e excedeu um limite predeterminado.
- HTTP 503 indica que o serviço não está pronto para lidar com a solicitação. A causa comum é que o serviço está enfrentando mais picos de carga temporários do que o esperado.
A aplicação cliente pode aguardar por algum tempo antes de repetir o pedido. Um Retry-After cabeçalho HTTP deve ser incluído, para apoiar o cliente na escolha da estratégia de repetição.
A limitação pode servir como uma medida temporária enquanto um sistema é dimensionado automaticamente. Em alguns casos, é melhor simplesmente acelerar, em vez de escalar, se uma explosão de atividade for repentina e não se espera que seja de longa duração, porque o dimensionamento pode aumentar consideravelmente os custos de funcionamento.
Se a limitação estiver sendo usada como uma medida temporária enquanto um sistema é dimensionado automaticamente e se as demandas de recursos crescerem muito rapidamente, o sistema pode não ser capaz de continuar funcionando, mesmo quando estiver operando em um modo limitado. Se tal não for aceitável, considere manter reservas de maior capacidade e configurar um dimensionamento automático mais agressivo.
Normalize os custos de recursos para diferentes operações, pois elas geralmente não têm custos de execução iguais. Por exemplo, os limites de limitação podem ser menores para operações de leitura e mais altos para operações de gravação. Não considerar o custo de uma operação pode resultar em capacidade esgotada e expondo um potencial vetor de ataque.
É desejável alterar a configuração dinâmica do comportamento de limitação em tempo de execução. Se um sistema enfrentar uma carga anormal que a configuração aplicada não pode suportar, os limites de limitação podem precisar aumentar ou diminuir para estabilizar o sistema e acompanhar o tráfego atual. Implantações caras, arriscadas e lentas não são desejáveis neste momento. Usando o padrão de Configuração Externa, a configuração de limitação do Repositório é externalizada e pode ser alterada e aplicada sem implantações.
Quando utilizar este padrão
Utilize este padrão:
Para garantir que um sistema continua a cumprir os contratos de nível de serviço.
Para impedir que um único inquilino monopolize os recursos disponibilizados por uma aplicação.
Para gerir o aumento da atividade.
Para ajudar a otimizar os custos de um sistema ao limitar os níveis de recursos máximos necessários para os manter a funcionar.
Design da carga de trabalho
Um arquiteto deve avaliar como o padrão de Limitação pode ser usado no design de sua carga de trabalho para abordar as metas e os princípios abordados nos pilares do Azure Well-Architected Framework. Por exemplo:
| Pilar | Como esse padrão suporta os objetivos do pilar |
|---|---|
| As decisões de projeto de confiabilidade ajudam sua carga de trabalho a se tornar resiliente ao mau funcionamento e a garantir que ela se recupere para um estado totalmente funcional após a ocorrência de uma falha. | Você projeta os limites para ajudar a evitar o esgotamento de recursos que pode levar a avarias. Você também pode usar esse padrão como um mecanismo de controle em um plano de degradação gracioso. - RE:07 Autopreservação |
| As decisões de design de segurança ajudam a garantir a confidencialidade, integridade e disponibilidade dos dados e sistemas da sua carga de trabalho. | Você pode projetar os limites para ajudar a evitar o esgotamento de recursos que poderia resultar do abuso automatizado do sistema. - SE:06 Controles de rede - SE:08 Recursos de proteção |
| A Otimização de Custos está focada em sustentar e melhorar o retorno do investimento da sua carga de trabalho. | Os limites impostos podem informar a modelagem de custos e podem até mesmo ser diretamente vinculados ao modelo de negócios do seu aplicativo. Eles também colocam limites superiores claros na utilização, que podem ser levados em conta no dimensionamento de recursos. - CO:02 Modelo de custo - CO:12 Custos de escala |
| A Eficiência de Desempenho ajuda sua carga de trabalho a atender às demandas de forma eficiente por meio de otimizações em escala, dados e código. | Quando o sistema está sob alta demanda, esse padrão ajuda a mitigar o congestionamento que pode levar a gargalos de desempenho. Você também pode usá-lo para evitar proativamente cenários vizinhos barulhentos. - PE:02 Planeamento da capacidade - PE:05 Dimensionamento e particionamento |
Como em qualquer decisão de design, considere quaisquer compensações em relação aos objetivos dos outros pilares que possam ser introduzidos com esse padrão.
Exemplo
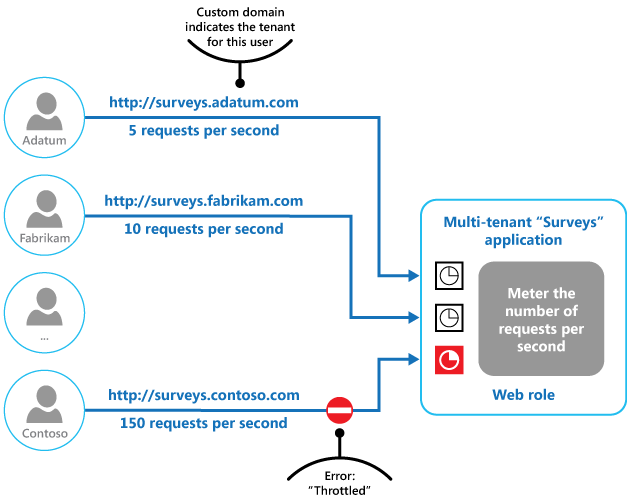
A figura final ilustra como a limitação pode ser implementada em um sistema multilocatário. Os utilizadores de cada organização inquilina acedem a uma aplicação alojada na cloud onde preenchem e submetem inquéritos. A aplicação contém instrumentação que monitoriza a taxa a que estes utilizadores submetem pedidos para a aplicação.
Para impedir que os utilizadores de um inquilino afetem a capacidade de resposta e a disponibilidade da aplicação para todos os outros utilizadores, é aplicado um limite ao número de pedidos por segundo que os utilizadores de qualquer inquilino podem submeter. A aplicação bloqueia os pedidos que excedem este limite.
Próximos passos
As seguintes orientações também podem ser relevantes na implementação deste padrão:
- Orientações sobre a Instrumentação e a Telemetria. A limitação depende da recolha de informações sobre a intensidade de utilização de um serviço. Descreve como gerar e capturar informações de monitorização personalizadas.
- Orientações sobre a Medição de Serviço. Descreve como medir o uso de serviços para obter uma compreensão de como eles são usados. Estas informações podem ser úteis para determinar como limitar um serviço.
- Orientações de Dimensionamento Automático. A limitação pode ser utilizada como uma medida provisória enquanto é realizado o dimensionamento automático de um sistema ou para remover a necessidade de dimensionamento automático de um sistema. Contém informações sobre as estratégias de dimensionamento automático.
Recursos relacionados
Os seguintes padrões também podem ser relevantes ao implementar esse padrão:
- Padrão de Nivelamento de Carga Baseado na Fila. O nivelamento de carga baseado na fila é um mecanismo frequentemente utilizado para implementar a limitação. Uma fila pode atuar como uma memória intermédia que ajuda a nivelar a taxa a que os pedidos enviados por uma aplicação são entregues a um serviço.
- Padrão de Fila de Prioridade. Um sistema pode utilizar a fila de prioridade como parte da sua estratégia de limitação para manter o desempenho das aplicações de valor crítico ou superior, reduzindo o desempenho das aplicações menos importantes.
- Padrão de Repositório de Configuração Externa. Centralizar e externalizar as políticas de limitação fornece a capacidade de alterar a configuração em tempo de execução sem a necessidade de uma reimplantação. Os serviços podem subscrever alterações de configuração, aplicando assim a nova configuração imediatamente, para estabilizar um sistema.