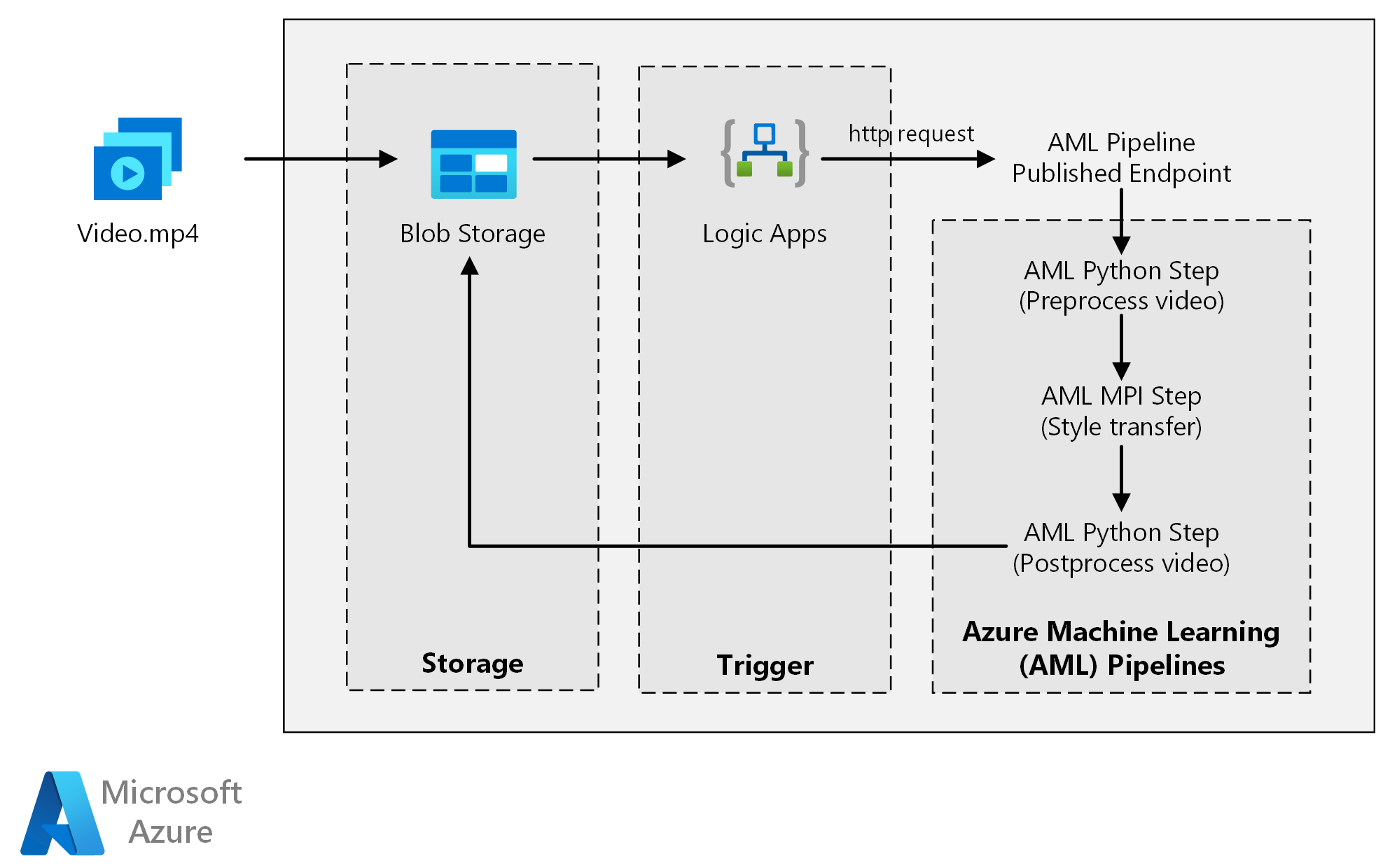
Esta arquitetura de referência mostra como aplicar a transferência de estilo neural a um vídeo, usando o Azure Machine Learning. A transferência de estilo é uma técnica de aprendizagem profunda que compõe uma imagem existente no estilo de outra imagem. Você pode generalizar essa arquitetura para qualquer cenário que use pontuação em lote com aprendizado profundo.
Arquitetura
Transfira um ficheiro do Visio desta arquitetura.
Fluxo de Trabalho
Esta arquitetura é composta pelos seguintes componentes.
Computação
O Azure Machine Learning usa pipelines para criar sequências de computação reproduzíveis e fáceis de gerenciar. Ele também oferece um destino de computação gerenciado (no qual uma computação de pipeline pode ser executada) chamado Azure Machine Learning Compute para treinamento, implantação e pontuação de modelos de aprendizado de máquina.
Armazenamento
O Armazenamento de Blobs do Azure armazena todas as imagens (imagens de entrada, imagens de estilo e imagens de saída). O Azure Machine Learning integra-se com o Armazenamento de Blobs para que os utilizadores não tenham de mover manualmente dados entre plataformas de computação e armazenamentos de blobs. O armazenamento de Blob também é econômico para o desempenho que essa carga de trabalho exige.
Acionador
Os Aplicativos Lógicos do Azure acionam o fluxo de trabalho. Quando o aplicativo lógico deteta que um blob foi adicionado ao contêiner, ele aciona o pipeline do Azure Machine Learning. O Logic Apps é uma boa opção para essa arquitetura de referência porque é uma maneira fácil de detetar alterações no armazenamento de blobs, com um processo fácil para alterar o gatilho.
Pré-processar e pós-processar os dados
Esta arquitetura de referência usa imagens de vídeo de um orangotango em uma árvore.
- Use FFmpeg para extrair o arquivo de áudio das imagens de vídeo, para que o arquivo de áudio possa ser costurado novamente no vídeo de saída mais tarde.
- Use FFmpeg para dividir o vídeo em quadros individuais. Os quadros são processados de forma independente, em paralelo.
- Neste ponto, você pode aplicar a transferência de estilo neural a cada quadro individual em paralelo.
- Depois que cada quadro tiver sido processado, use FFmpeg para recompor os quadros.
- Finalmente, reanexe o arquivo de áudio às imagens restitched.
Componentes
Detalhes da solução
Essa arquitetura de referência foi projetada para cargas de trabalho acionadas pela presença de novas mídias no Armazenamento do Azure.
O processamento envolve as seguintes etapas:
- Carregue um arquivo de vídeo no Armazenamento de Blobs do Azure.
- O arquivo de vídeo aciona os Aplicativos Lógicos do Azure para enviar uma solicitação ao ponto de extremidade publicado do pipeline do Azure Machine Learning.
- O pipeline processa o vídeo, aplica a transferência de estilo com MPI e pósprocessa o vídeo.
- A saída é salva de volta no Armazenamento de Blob assim que o pipeline é concluído.
Potenciais casos de utilização
Uma organização de mídia tem um vídeo cujo estilo eles querem mudar para se parecer com uma pintura específica. A organização quer aplicar este estilo a todos os frames do vídeo de forma atempada e automatizada. Para obter mais informações sobre algoritmos de transferência de estilo neural, consulte Transferência de estilo de imagem usando redes neurais convolucionais (PDF).
Considerações
Essas considerações implementam os pilares do Azure Well-Architected Framework, que é um conjunto de princípios orientadores que podem ser usados para melhorar a qualidade de uma carga de trabalho. Para obter mais informações, consulte Microsoft Azure Well-Architected Framework.
Eficiência de desempenho
Eficiência de desempenho é a capacidade da sua carga de trabalho para dimensionar para satisfazer as exigências que os utilizadores lhe colocam de forma eficiente. Para obter mais informações, consulte Visão geral do pilar de eficiência de desempenho.
GPU versus CPU
Para cargas de trabalho de aprendizagem profunda, as GPUs geralmente superam as CPUs em uma quantidade considerável, na medida em que um cluster considerável de CPUs é normalmente necessário para obter um desempenho comparável. Embora você possa usar apenas CPUs nessa arquitetura, as GPUs fornecem um perfil de custo/desempenho muito melhor. Recomendamos o uso da mais recente série NCv3 de VMs otimizadas para GPU.
As GPUs não estão habilitadas por padrão em todas as regiões. Certifique-se de selecionar uma região com GPUs habilitadas. Além disso, as assinaturas têm uma cota padrão de zero núcleos para VMs otimizadas para GPU. Você pode aumentar essa cota abrindo uma solicitação de suporte. Certifique-se de que a sua subscrição tem quota suficiente para executar a sua carga de trabalho.
Paralelizar entre VMs versus núcleos
Quando você executa um processo de transferência de estilo como um trabalho em lote, os trabalhos executados principalmente em GPUs precisam ser paralelizados entre VMs. Duas abordagens são possíveis: você pode criar um cluster maior usando VMs que tenham uma única GPU ou criar um cluster menor usando VMs com muitas GPUs.
Para essa carga de trabalho, essas duas opções têm desempenho comparável. Usar menos VMs com mais GPUs por VM pode ajudar a reduzir a movimentação de dados. No entanto, o volume de dados por trabalho para essa carga de trabalho não é grande, portanto, você não observará muita limitação pelo Armazenamento de Blob.
Passo MPI
Ao criar o pipeline do Azure Machine Learning, uma das etapas usadas para executar a computação paralela é a etapa MPI (interface de processamento de mensagens). A etapa MPI ajuda a dividir os dados uniformemente entre os nós disponíveis. A etapa MPI não é executada até que todos os nós solicitados estejam prontos. Se um nó falhar ou for antecipado (se for uma máquina virtual de baixa prioridade), a etapa MPI terá que ser executada novamente.
Segurança
A segurança oferece garantias contra ataques deliberados e o abuso de seus valiosos dados e sistemas. Para obter mais informações, consulte Visão geral do pilar de segurança. Esta seção contém considerações para a criação de soluções seguras.
Restringir o acesso ao Armazenamento de Blobs do Azure
Nesta arquitetura de referência, o Armazenamento de Blobs do Azure é o principal componente de armazenamento que precisa ser protegido. A implantação de linha de base mostrada no repositório GitHub usa chaves de conta de armazenamento para acessar o armazenamento de blob. Para maior controle e proteção, considere o uso de uma Assinatura de Acesso Compartilhado (SAS). Isso concede acesso limitado a objetos no armazenamento, sem a necessidade de codificar as chaves da conta ou salvá-las em texto sem formatação. Essa abordagem é especialmente útil porque as chaves de conta são visíveis em texto sem formatação dentro da interface de designer do aplicativo lógico. O uso de um SAS também ajuda a garantir que a conta de armazenamento tenha governança adequada e que o acesso seja concedido apenas às pessoas que pretendem tê-lo.
Para cenários com dados mais confidenciais, certifique-se de que todas as chaves de armazenamento estão protegidas, pois essas chaves concedem acesso total a todos os dados de entrada e saída da carga de trabalho.
Encriptação e movimentação de dados
Esta arquitetura de referência usa a transferência de estilo como um exemplo de um processo de pontuação em lote. Para cenários mais sensíveis a dados, os dados armazenados devem ser criptografados em repouso. Sempre que os dados forem movidos de um local para outro, use o Transport Layer Security (TSL) para proteger a transferência de dados. Para obter mais informações, consulte o guia de segurança do Armazenamento do Azure.
Proteja a sua computação numa rede virtual
Ao implantar seu cluster de computação de Aprendizado de Máquina, você pode configurar seu cluster para ser provisionado dentro de uma sub-rede de uma rede virtual. Essa sub-rede permite que os nós de computação no cluster se comuniquem com segurança com outras máquinas virtuais.
Proteja-se contra atividades maliciosas
Em cenários em que há vários usuários, certifique-se de que os dados confidenciais estejam protegidos contra atividades maliciosas. Se outros usuários tiverem acesso a essa implantação para personalizar os dados de entrada, observe as seguintes precauções e considerações:
- Use o RBAC (controle de acesso baseado em função) do Azure para limitar o acesso dos usuários apenas aos recursos de que eles precisam.
- Provisione duas contas de armazenamento separadas. Armazene dados de entrada e saída na primeira conta. Os utilizadores externos podem ter acesso a esta conta. Armazene scripts executáveis e arquivos de log de saída na outra conta. Os utilizadores externos não devem ter acesso a esta conta. Essa separação garante que os usuários externos não possam modificar nenhum arquivo executável (para injetar código mal-intencionado) e não tenham acesso a arquivos de log, que podem conter informações confidenciais.
- Usuários mal-intencionados podem executar um ataque DDoS na fila de tarefas ou injetar mensagens suspeitas malformadas na fila de tarefas, fazendo com que o sistema trave ou causando erros de enfileiramento.
Otimização de custos
A otimização de custos consiste em procurar formas de reduzir despesas desnecessárias e melhorar a eficiência operacional. Para obter mais informações, consulte Visão geral do pilar de otimização de custos.
Em comparação com os componentes de armazenamento e agendamento, os recursos de computação usados nessa arquitetura de referência dominam de longe em termos de custos. Um dos principais desafios é paralelizar efetivamente o trabalho em um cluster de máquinas habilitadas para GPU.
O tamanho do cluster de Computação do Azure Machine Learning pode ser dimensionado automaticamente para cima e para baixo, dependendo dos trabalhos na fila. Você pode habilitar o dimensionamento automático programaticamente definindo os nós mínimo e máximo.
Para trabalhos que não exigem processamento imediato, configure o dimensionamento automático para que o estado padrão (mínimo) seja um cluster de nós zero. Com essa configuração, o cluster começa com zero nós e só aumenta quando deteta trabalhos na fila. Se o processo de pontuação em lote acontecer apenas algumas vezes por dia ou menos, essa configuração resultará em economias de custos significativas.
O dimensionamento automático pode não ser apropriado para trabalhos em lote que acontecem muito próximos uns dos outros. O tempo que leva para um cluster girar para cima e para baixo também incorre em um custo, portanto, se uma carga de trabalho em lote começar apenas alguns minutos após o término do trabalho anterior, pode ser mais econômico manter o cluster em execução entre trabalhos.
O Azure Machine Learning Compute também dá suporte a máquinas virtuais de baixa prioridade, o que permite executar sua computação em máquinas virtuais com desconto, com a ressalva de que elas podem ser antecipadas a qualquer momento. As máquinas virtuais de baixa prioridade são ideais para cargas de trabalho de pontuação em lote não críticas.
Monitorar trabalhos em lote
Durante a execução do seu trabalho, é importante monitorar o progresso e certificar-se de que o trabalho está funcionando conforme o esperado. No entanto, pode ser um desafio monitorar em um cluster de nós ativos.
Para verificar o estado geral do cluster, vá para o serviço de Aprendizado de Máquina no portal do Azure para verificar o estado dos nós no cluster. Se um nó estiver inativo ou um trabalho tiver falhado, os logs de erro serão salvos no Armazenamento de Blobs e também poderão ser acessados no portal do Azure.
O monitoramento pode ser ainda mais enriquecido conectando logs ao Application Insights ou executando processos separados para pesquisar o estado do cluster e seus trabalhos.
Iniciar sessão com o Azure Machine Learning
O Aprendizado de Máquina do Azure registrará automaticamente todos os stdout/stderr na conta de Armazenamento de Blob associada. A menos que especificado de outra forma, seu espaço de trabalho do Azure Machine Learning provisionará automaticamente uma conta de armazenamento e despejará seus logs nela. Você também pode usar uma ferramenta de navegação de armazenamento, como o Gerenciador de Armazenamento do Azure, que é uma maneira mais fácil de navegar pelos arquivos de log.
Implementar este cenário
Para implantar essa arquitetura de referência, siga as etapas descritas no repositório GitHub.
Você também pode implantar uma arquitetura de pontuação em lote para modelos de aprendizado profundo usando o Serviço Kubernetes do Azure. Siga as etapas descritas neste repositório GitHub.
Contribuidores
Este artigo é mantido pela Microsoft. Foi originalmente escrito pelos seguintes contribuidores.
Autor principal:
- Jian Tang - Brasil | Gestor de Programas II
Para ver perfis não públicos do LinkedIn, inicie sessão no LinkedIn.
Próximos passos
- Pontuação em lote de modelos do Spark no Azure Databricks
- Pontuação em lote de modelos Python no Azure
- Pontuação em lote com modelos R para prever vendas