O padrão de estrutura saga é uma forma de gerir a consistência de dados em microsserviços em cenários de transação distribuída. Uma saga é uma sequência de transações que atualiza cada serviço e publica uma mensagem ou evento para acionar o próximo passo de transação. Se um passo falhar, a saga executa transações de compensação que contrapõem as transações anteriores.
Contexto e problema
Uma transação é uma única unidade de lógica ou trabalho, por vezes composta por múltiplas operações. Numa transação, um evento é uma alteração de estado que ocorre numa entidade e um comando encapsula todas as informações necessárias para realizar uma ação ou acionar um evento posterior.
As transações têm de ser atómicas, consistentes, isoladas e duráveis (ACID). As transações num único serviço são ACID, mas a consistência de dados entre serviços requer uma estratégia de gestão de transações entre serviços.
Em arquiteturas de vários serviços:
- A atomicidade é um conjunto de operações indivisível e irredutível que tem de ocorrer ou não ocorrer.
- Consistência significa que a transação leva os dados apenas de um estado válido para outro estado válido.
- O isolamento garante que as transações simultâneas produzem o mesmo estado de dados que as transações executadas sequencialmente teriam produzido.
- A durabilidade garante que as transações consolidadas permanecem consolidadas mesmo em caso de falha de sistema ou falha de energia.
Um modelo de base de dados por microsserviço proporciona muitas vantagens para arquiteturas de microsserviços. Encapsular dados de domínio permite que cada serviço utilize o seu melhor tipo e esquema de arquivo de dados, dimensione o seu próprio arquivo de dados conforme necessário e seja isolado das falhas de outros serviços. No entanto, garantir a consistência dos dados em bases de dados específicas do serviço coloca desafios.
As transações distribuídas, como o protocolo de consolidação de duas fases (2PC), exigem que todos os participantes numa transação consolidem ou revertam antes de a transação poder continuar. No entanto, algumas implementações de participantes, como bases de dados NoSQL e mediação de mensagens, não suportam este modelo.
Outra limitação de transação distribuída é a sincronização e a disponibilidade da comunicação entre processos (IPC ). O IPC fornecido pelo sistema operativo permite que processos separados partilhem dados. Para que as transações distribuídas sejam consolidadas, todos os serviços participantes têm de estar disponíveis, o que pode reduzir a disponibilidade geral do sistema. As implementações de arquitetura com limitações de IPC ou transações são candidatas ao padrão Saga.
Solução
O padrão Saga fornece gestão de transações com uma sequência de transações locais. Uma transação local é o esforço de trabalho atómico realizado por um participante da saga. Cada transação local atualiza a base de dados e publica uma mensagem ou evento para acionar a próxima transação local na saga. Se uma transação local falhar, a saga executa uma série de transações compensatórias que anulam as alterações efetuadas pelas transações locais anteriores.
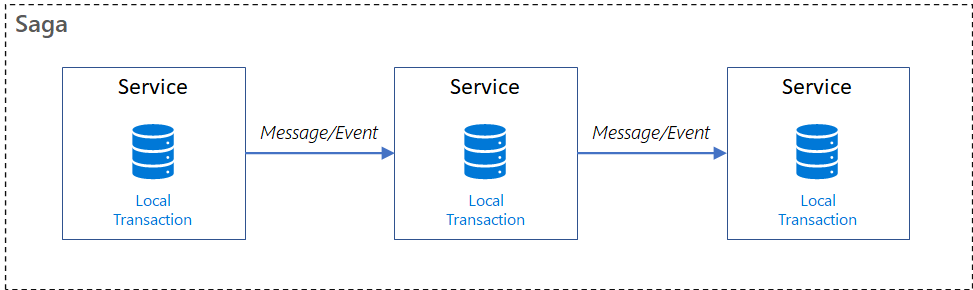
Nos padrões da Saga:
- As transações compensatórias são transações que podem potencialmente ser invertidas ao processar outra transação com o efeito oposto.
- Uma transação dinâmica é o ponto go/no-go numa saga. Se a transação dinâmica for consolidada, a saga será executada até à conclusão. Uma transação dinâmica pode ser uma transação que não é compensavel nem replicável, ou pode ser a última transação compensatória ou a primeira transação replicável na saga.
- As transações retráveis são transações que seguem a transação dinâmica e têm a garantia de sucesso.
Existem duas abordagens comuns de implementação de sagas, coreografia e orquestração. Cada abordagem tem o seu próprio conjunto de desafios e tecnologias para coordenar o fluxo de trabalho.
Coreografia
A coreografia é uma forma de coordenar sagas onde os participantes trocam eventos sem um ponto de controlo centralizado. Com a coreografia, cada transação local publica eventos de domínio que acionam transações locais noutros serviços.
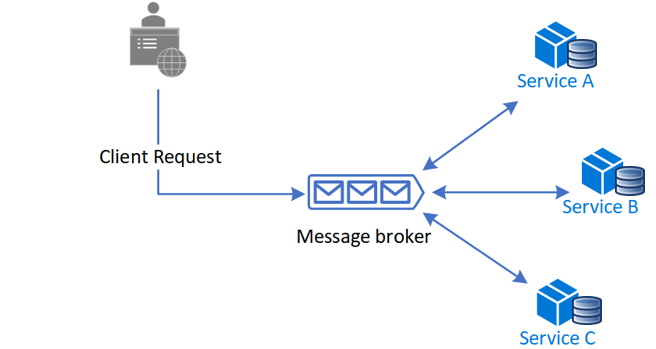
Benefícios
- Bom para fluxos de trabalho simples que requerem poucos participantes e não precisam de uma lógica de coordenação.
- Não requer implementação e manutenção de serviços adicionais.
- Não introduz um único ponto de falha, uma vez que as responsabilidades são distribuídas pelos participantes da saga.
Desvantagens
- O fluxo de trabalho pode tornar-se confuso ao adicionar novos passos, uma vez que é difícil controlar que participantes da saga ouvem os comandos.
- Existe o risco de dependência cíclica entre os participantes da saga porque têm de consumir os comandos uns dos outros.
- Os testes de integração são difíceis porque todos os serviços têm de estar em execução para simular uma transação.
Orquestração
A orquestração é uma forma de coordenar sagas onde um controlador centralizado diz aos participantes da saga quais as transações locais a executar. O orquestrador de saga processa todas as transações e indica aos participantes que operação executar com base em eventos. O orquestrador executa pedidos de saga, armazena e interpreta os estados de cada tarefa e processa a recuperação de falhas com transações compensatórias.
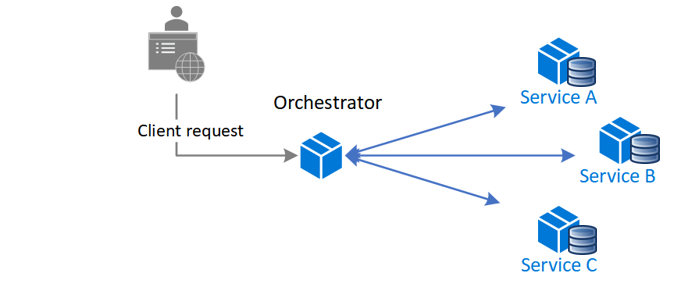
Benefícios
- Bom para fluxos de trabalho complexos que envolvem muitos participantes ou novos participantes adicionados ao longo do tempo.
- Adequado quando existe controlo sobre todos os participantes no processo e controlo sobre o fluxo de atividades.
- Não introduz dependências cíclicas, porque o orquestrador depende unilateralmente dos participantes da saga.
- Os participantes da Saga não precisam de saber mais sobre comandos para outros participantes. A separação clara das preocupações simplifica a lógica de negócio.
Desvantagens
- A complexidade de design adicional requer uma implementação de uma lógica de coordenação.
- Existe um ponto adicional de falha, porque o orquestrador gere o fluxo de trabalho completo.
Problemas e considerações
Considere os seguintes pontos ao implementar o padrão saga:
- O padrão saga pode ser inicialmente desafiante, uma vez que requer uma nova forma de pensar em como coordenar uma transação e manter a consistência de dados para um processo de negócio que abrange vários microsserviços.
- O padrão saga é particularmente difícil de depurar e a complexidade aumenta à medida que os participantes aumentam.
- Não é possível reverter os dados porque os participantes da saga consolidam alterações nas respetivas bases de dados locais.
- A implementação tem de ser capaz de lidar com um conjunto de potenciais falhas transitórias e fornecer idempotência para reduzir os efeitos colaterais e garantir a consistência dos dados. Idempotência significa que a mesma operação pode ser repetida várias vezes sem alterar o resultado inicial. Para obter mais informações, veja a documentação de orientação sobre como garantir a idempotência ao processar mensagens e atualizar o estado em conjunto.
- É melhor implementar a observabilidade para monitorizar e controlar o fluxo de trabalho da saga.
- A falta de isolamento de dados dos participantes impõe desafios de durabilidade. A implementação da saga tem de incluir contramedidas para reduzir anomalias.
As seguintes anomalias podem ocorrer sem medidas adequadas:
- Atualizações perdidas, quando uma saga escreve sem ler as alterações feitas por outra saga.
- Leituras sujas, quando uma transação ou uma saga lê as atualizações feitas por uma saga que ainda não concluiu essas atualizações.
- Leituras difusas/não repetíveis, quando diferentes passos de saga leem dados diferentes porque ocorre uma atualização de dados entre as leituras.
As contramedidas sugeridas para reduzir ou evitar anomalias incluem:
- Bloqueio semântico, um bloqueio ao nível da aplicação em que a transação compensavel de uma saga utiliza um semáforo para indicar que está em curso uma atualização.
- Atualizações comutativas que podem ser executadas por qualquer ordem e produzem o mesmo resultado.
- Vista pessimista: É possível que uma saga leia dados sujos, enquanto outra saga está a executar uma transação compensatória para reverter a operação. A vista pessimista reordena a saga para que os dados subjacentes sejam atualizados numa transação retráctil, o que elimina a possibilidade de uma leitura suja.
- O valor reread verifica se os dados são inalterados e, em seguida, atualiza o registo. Se o registo tiver sido alterado, os passos abortam e a saga poderá ser reiniciada.
- Um ficheiro de versão regista as operações num registo à medida que chegam e, em seguida, executa-as pela ordem correta.
- Por valor , utiliza o risco comercial de cada pedido para selecionar dinamicamente o mecanismo de simultaneidade. Os pedidos de baixo risco favorecem sagas, enquanto os pedidos de alto risco favorecem as transações distribuídas.
Quando utilizar este padrão
Utilize o padrão saga quando precisar de:
- Confirme a consistência dos dados num sistema distribuído sem acoplamento apertado.
- Reverter ou compensar se uma das operações na sequência falhar.
O padrão Saga é menos adequado para:
- Transações bem acopladas.
- Compensação de transações que ocorrem em participantes anteriores.
- Dependências cíclicas.
Exemplo
A Saga baseada em orquestração em Sem Servidor é uma referência de implementação de saga com a abordagem de orquestração que simula um cenário de transferência de dinheiro com fluxos de trabalho bem-sucedidos e falhados.
Passos seguintes
- Dados distribuídos
- Richardson, Chris. 2018: Padrões de Microsserviços. Manning Publications.
Recursos relacionados
Os padrões seguintes podem também ser úteis ao implementar este padrão:
- A coreografia tem cada componente do sistema que participa no processo de tomada de decisão sobre o fluxo de trabalho de uma transação empresarial, em vez de depender de um ponto central de controlo.
- As transações de compensação anulam o trabalho realizado por uma série de passos e, eventualmente, definem uma operação consistente se um ou mais passos falharem. As aplicações alojadas na cloud que implementam processos de negócio e fluxos de trabalho complexos seguem frequentemente este modelo de consistência eventual.
- A repetição permite que uma aplicação processe falhas transitórias quando tenta ligar a um serviço ou recurso de rede, repetindo de forma transparente a operação falhada. A repetição pode melhorar a estabilidade da aplicação.
- O disjuntor automático processa falhas que demoram um período de tempo variável a recuperar ao ligar a um serviço ou recurso remoto. O disjuntor automático pode melhorar a estabilidade e resiliência de uma aplicação.
- A monitorização do ponto final de estado de funcionamento implementa verificações funcionais numa aplicação à qual as ferramentas externas podem aceder através de pontos finais expostos em intervalos regulares. A monitorização do ponto final de estado de funcionamento pode ajudar a verificar se as aplicações e os serviços estão a funcionar corretamente.