Alta disponibilidade com instância gerenciada SQL habilitada pelo Azure Arc
A Instância Gerenciada SQL habilitada pelo Azure Arc é implantada no Kubernetes como um aplicativo em contêiner. Ele usa construções do Kubernetes, como conjuntos com monitoração de estado e armazenamento persistente, para fornecer built-in:
- Monitorização do estado de funcionamento
- Deteção de falhas
- Failover automático para manter a integridade do serviço.
Para maior confiabilidade, você também pode configurar a Instância Gerenciada SQL habilitada pelo Azure Arc para implantar com réplicas extras em uma configuração de alta disponibilidade. O controlador de dados dos serviços de dados Arc gerencia:
- Monitorização
- Deteção de falhas
- Ativação pós-falha automática
O serviço de dados habilitado para Arc fornece esse serviço sem a intervenção do usuário. O serviço:
- Configura o grupo de disponibilidade
- Configura pontos de extremidade de espelhamento de banco de dados
- Adiciona bancos de dados ao grupo de disponibilidade
- Coordena o failover e a atualização.
Este documento explora ambos os tipos de alta disponibilidade.
A Instância Gerenciada SQL habilitada pelo Azure Arc fornece diferentes níveis de alta disponibilidade, dependendo se a instância gerenciada SQL foi implantada como uma camada de serviço de Propósito Geral ou uma camada de serviço Crítica para os Negócios.
Alta disponibilidade na camada de serviço de uso geral
Na camada de serviço de uso geral, há apenas uma réplica disponível, e a alta disponibilidade é alcançada por meio da orquestração do Kubernetes. Por exemplo, se um pod ou nó que contém a imagem de contêiner de instância gerenciada falhar, o Kubernetes tentará criar outro pod ou nó e anexá-lo ao mesmo armazenamento persistente. Durante esse tempo, a instância gerenciada SQL não está disponível para os aplicativos. Os aplicativos precisam se reconectar e tentar novamente a transação quando o novo pod estiver ativo. Se load balancer for o tipo de serviço usado, os aplicativos poderão se reconectar ao mesmo ponto de extremidade primário e o Kubernetes redirecionará a conexão para o novo primário. Se o tipo de serviço for nodeport , os aplicativos precisarão se reconectar ao novo endereço IP.
Verificar a alta disponibilidade interna
Para verificar a alta disponibilidade incorporada fornecida pelo Kubernetes, você pode:
- Excluir o pod de uma instância gerenciada existente
- Verifique se o Kubernetes se recupera dessa ação
Durante a recuperação, o Kubernetes inicializa outro pod e anexa o armazenamento persistente.
Pré-requisitos
- O cluster Kubernetes requer armazenamento remoto compartilhado
- Uma Instância Gerenciada SQL habilitada pelo Azure Arc implantada com uma réplica (padrão)
Veja os pods.
kubectl get pods -n <namespace of data controller>Exclua o pod de instância gerenciado.
kubectl delete pod <name of managed instance>-0 -n <namespace of data controller>Por exemplo
user@pc:/# kubectl delete pod sql1-0 -n arc pod "sql1-0" deletedExiba os pods para verificar se a instância gerenciada está se recuperando.
kubectl get pods -n <namespace of data controller>Por exemplo:
user@pc:/# kubectl get pods -n arc NAME READY STATUS RESTARTS AGE sql1-0 2/3 Running 0 22s
Depois que todos os contêineres dentro do pod forem recuperados, você poderá se conectar à instância gerenciada.
Alta disponibilidade no nível de serviço Crítico para os Negócios
Na camada de serviço Business Critical, além do que é fornecido nativamente pela orquestração do Kubernetes, a Instância Gerenciada SQL para Azure Arc fornece um grupo de disponibilidade contido. O grupo de disponibilidade contido é criado com base na tecnologia Always On do SQL Server. Proporciona níveis mais elevados de disponibilidade. A Instância Gerenciada SQL habilitada pelo Azure Arc implantada com a camada de serviço Business Critical pode ser implantada com 2 ou 3 réplicas. Essas réplicas são sempre mantidas em sincronia entre si.
Com grupos de disponibilidade contidos, quaisquer falhas de pod ou nó são transparentes para o aplicativo. O grupo de disponibilidade contida fornece pelo menos um outro pod que tem todos os dados do primário e está pronto para assumir conexões.
Grupos de disponibilidade contidos
Um grupo de disponibilidade vincula um ou mais bancos de dados de usuário em um grupo lógico para que, quando houver um failover, todo o grupo de bancos de dados faça failover para a réplica secundária como uma única unidade. Um grupo de disponibilidade replica apenas dados nos bancos de dados de usuários, mas não os dados em bancos de dados do sistema, como logons, permissões ou trabalhos de agente. Um grupo de disponibilidade contida inclui metadados de bancos de dados do sistema, como msdb bancos de dados e bancos master de dados. Quando os logins são criados ou modificados na réplica primária, eles também são criados automaticamente nas réplicas secundárias. Da mesma forma, quando um trabalho de agente é criado ou modificado na réplica primária, as réplicas secundárias também recebem essas alterações.
A Instância Gerenciada SQL habilitada pelo Azure Arc usa esse conceito de grupo de disponibilidade contida e adiciona o operador Kubernetes para que eles possam ser implantados e gerenciados em escala.
Os recursos que continham grupos de disponibilidade permitem:
Quando implantado com várias réplicas, um único grupo de disponibilidade nomeado com o mesmo nome da instância gerenciada SQL habilitada para Arc é criado. Por padrão, o AG contido tem três réplicas, incluindo primárias. Todas as operações CRUD para o grupo de disponibilidade são gerenciadas internamente, incluindo a criação do grupo de disponibilidade ou a associação de réplicas ao grupo de disponibilidade criado. Não é possível criar mais grupos de disponibilidade em uma instância.
Todos os bancos de dados são adicionados automaticamente ao grupo de disponibilidade, incluindo todos os bancos de dados de usuários e sistemas como
masteremsdb. Esse recurso fornece uma visão de sistema único nas réplicas do grupo de disponibilidade. Observe ambos oscontainedag_masterbancos de dados se você secontainedag_msdbconectar diretamente à instância. Oscontainedag_*bancos de dados representam omasteremsdbdentro do grupo de disponibilidade.Um ponto de extremidade externo é automaticamente provisionado para conexão com bancos de dados dentro do grupo de disponibilidade. Esse ponto de extremidade
<managed_instance_name>-external-svcdesempenha a função de ouvinte do grupo de disponibilidade.
Implantar a Instância Gerenciada SQL habilitada pelo Azure Arc com várias réplicas usando o portal do Azure
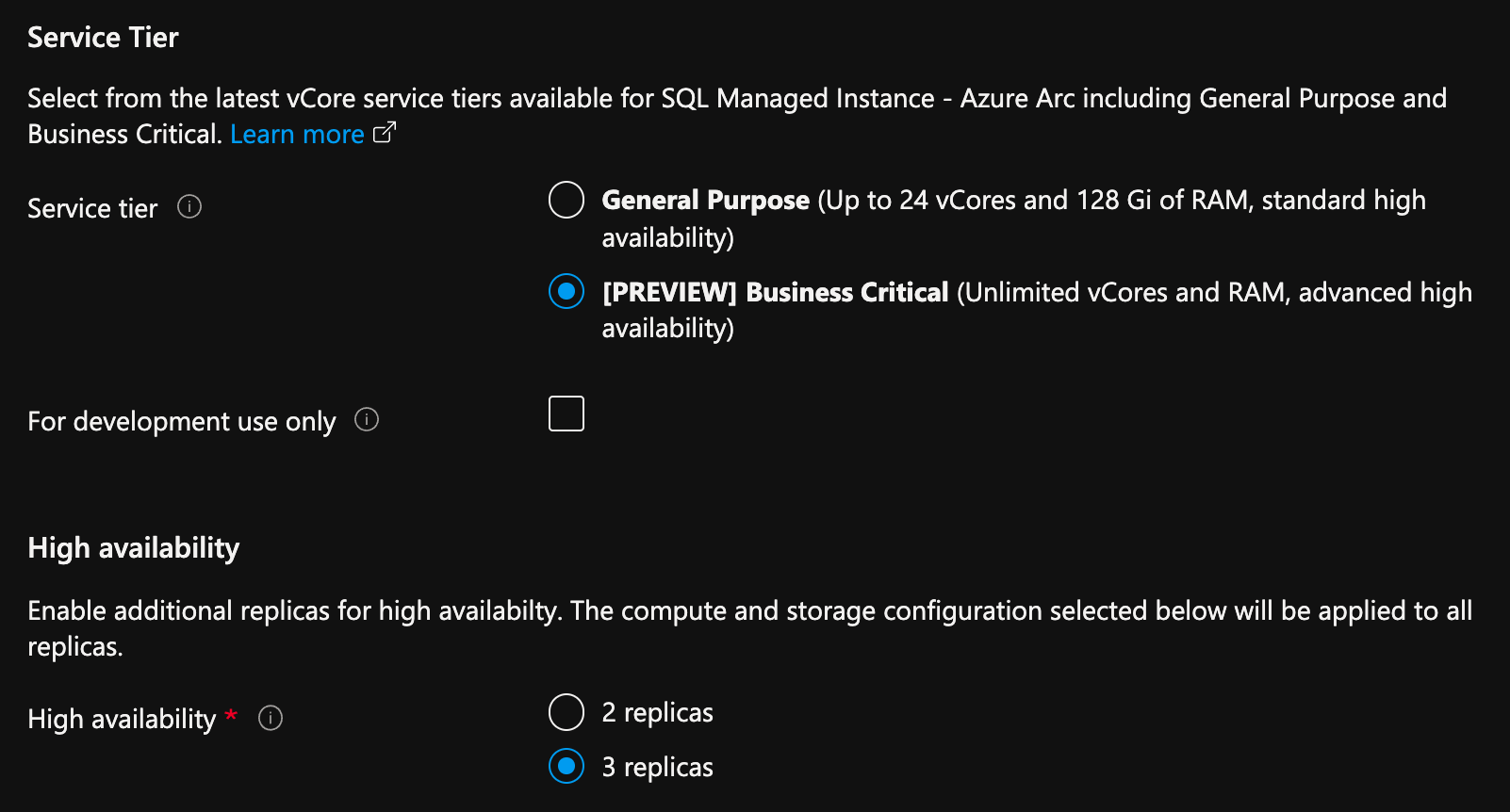
No portal do Azure, na página criar Instância Gerenciada SQL habilitada pelo Azure Arc:
- Selecione Configurar Computação + Armazenamento em Computação + Armazenamento . O portal mostra configurações avançadas.
- Em Camada de serviço, selecione Business Critical.
- Marque a opção "Apenas para uso em desenvolvimento", se estiver usando para fins de desenvolvimento.
- Em Alta disponibilidade, selecione 2 réplicas ou 3 réplicas.
Implantar com várias réplicas usando a CLI do Azure
Quando uma Instância Gerenciada SQL habilitada pelo Azure Arc é implantada na camada de serviço Crítica para Negócios, a implantação cria várias réplicas. A instalação e a configuração de grupos de disponibilidade contidos entre essas instâncias são feitas automaticamente durante o provisionamento.
Por exemplo, o comando a seguir cria uma instância gerenciada com 3 réplicas.
Modo conectado indiretamente:
az sql mi-arc create -n <instanceName> --k8s-namespace <namespace> --use-k8s --tier <tier> --replicas <number of replicas>
Exemplo:
az sql mi-arc create -n sqldemo --k8s-namespace my-namespace --use-k8s --tier BusinessCritical --replicas 3
Modo conectado diretamente:
az sql mi-arc create --name <name> --resource-group <group> --location <Azure location> –subscription <subscription> --custom-location <custom-location> --tier <tier> --replicas <number of replicas>
Exemplo:
az sql mi-arc create --name sqldemo --resource-group rg --location uswest2 –subscription xxxxxxx-xxxx-xxxx-xxxx-xxxxxxxxxxxx --custom-location private-location --tier BusinessCritical --replcias 3
Por padrão, todas as réplicas são configuradas no modo síncrono. Isso significa que todas as atualizações na instância primária são replicadas de forma síncrona para cada uma das instâncias secundárias.
Visualizar e monitorar o status de alta disponibilidade
Quando a implantação estiver concluída, conecte-se ao ponto de extremidade primário do SQL Server Management Studio.
Verifique e recupere o ponto de extremidade da réplica primária e conecte-se a ele a partir do SQL Server Management Studio.
Por exemplo, se a instância SQL foi implantada usando service-type=loadbalancer, execute o comando abaixo para recuperar o ponto de extremidade ao qual se conectar:
az sql mi-arc list --k8s-namespace my-namespace --use-k8s
ou
kubectl get sqlmi -A
Obter os endpoints primários e secundários e o status AG
Use os comandos ou az sql mi-arc show para exibir os kubectl describe sqlmi pontos de extremidade primários e secundários e o status de alta disponibilidade.
Exemplo:
kubectl describe sqlmi sqldemo -n my-namespace
ou
az sql mi-arc show --name sqldemo --k8s-namespace my-namespace --use-k8s
Saída de exemplo:
"status": {
"endpoints": {
"logSearchDashboard": "https://10.120.230.404:5601/app/kibana#/discover?_a=(query:(language:kuery,query:'custom_resource_name:sqldemo'))",
"metricsDashboard": "https://10.120.230.46:3000/d/40q72HnGk/sql-managed-instance-metrics?var-hostname=sqldemo-0",
"mirroring": "10.15.100.150:5022",
"primary": "10.15.100.150,1433",
"secondary": "10.15.100.156,1433"
},
"highAvailability": {
"healthState": "OK",
"mirroringCertificate": "-----BEGIN CERTIFICATE-----\n...\n-----END CERTIFICATE-----"
},
"observedGeneration": 1,
"readyReplicas": "2/2",
"state": "Ready"
}
Você pode se conectar ao ponto de extremidade primário com o SQL Server Management Studio e verificar DMVs como:
SELECT * FROM sys.dm_hadr_availability_replica_states
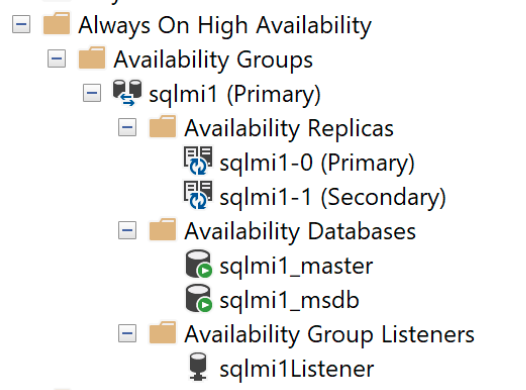
e o painel de disponibilidade contido:
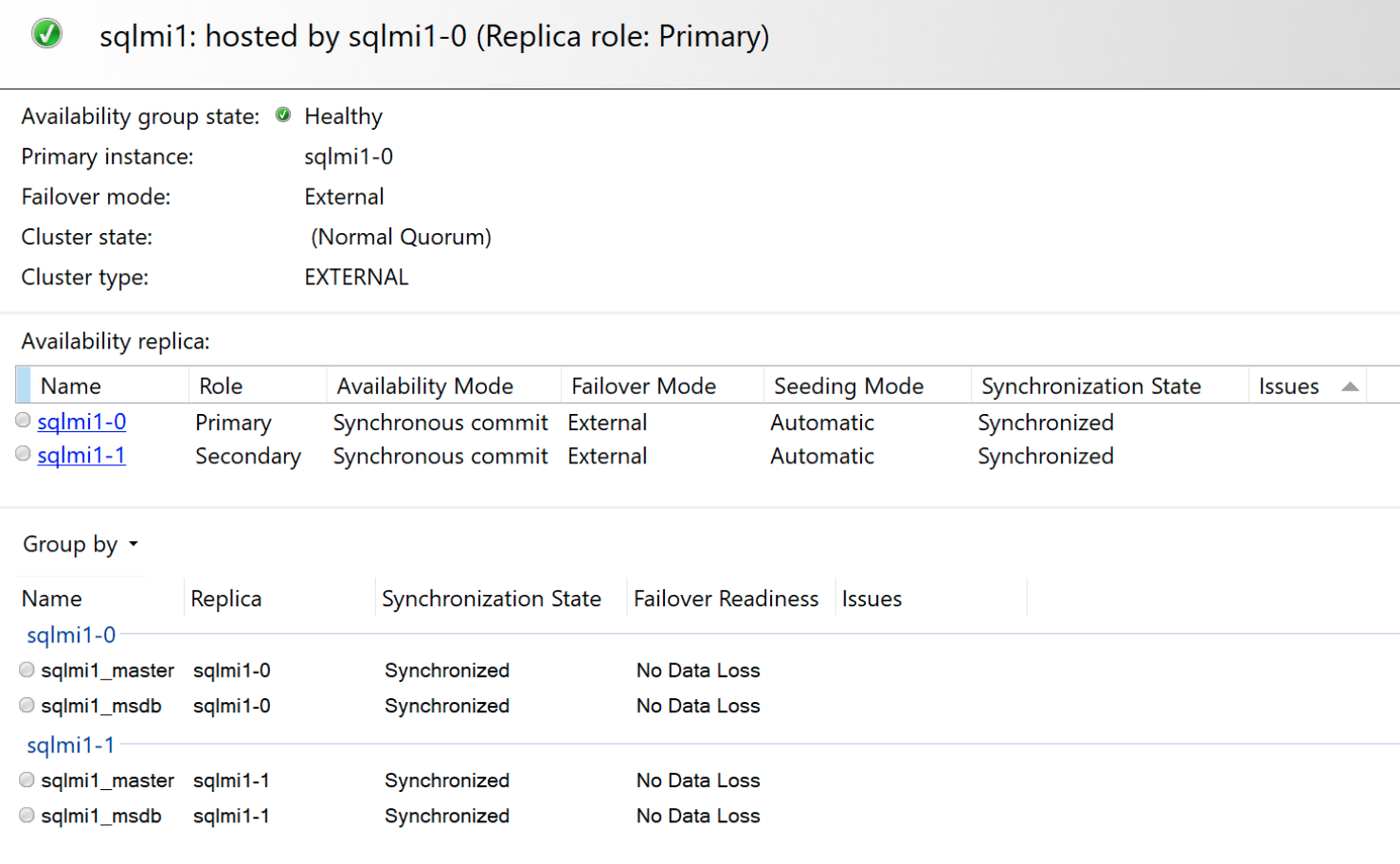
Cenários de failover
Ao contrário dos grupos de disponibilidade Always On do SQL Server, o grupo de disponibilidade contido é uma solução gerenciada de alta disponibilidade. Assim, os modos de failover são limitados em comparação com os modos típicos disponíveis com os grupos de disponibilidade Always On do SQL Server.
Implante instâncias gerenciadas SQL da camada de serviço Crítica de Negócios em configuração de duas ou três réplicas. Os efeitos das falhas e a subsequente capacidade de recuperação são diferentes com cada configuração. Uma instância de três réplicas fornece um nível mais alto de disponibilidade e recuperação do que uma instância de duas réplicas.
Em uma configuração de duas réplicas, quando ambos os estados do nó são SYNCHRONIZED, se a réplica primária ficar indisponível, a réplica secundária será automaticamente promovida para primária. Quando a réplica com falha fica disponível, ela é atualizada com todas as alterações pendentes. Se houver problemas de conectividade entre as réplicas, a réplica primária pode não confirmar nenhuma transação, pois cada transação precisa ser confirmada em ambas as réplicas antes que um êxito seja retornado na principal.
Em uma configuração de três réplicas, uma transação precisa ser confirmada em pelo menos 2 das 3 réplicas antes de retornar uma mensagem de êxito ao aplicativo. Em caso de falha, um dos secundários é automaticamente promovido a primário enquanto o Kubernetes tenta recuperar a réplica com falha. Quando a réplica fica disponível, ela é automaticamente unida novamente ao grupo de disponibilidade contido e as alterações pendentes são sincronizadas. Se houver problemas de conectividade entre as réplicas e mais de 2 réplicas estiverem fora de sincronia, a réplica principal não confirmará nenhuma transação.
Nota
Recomenda-se implantar uma Instância Gerenciada SQL Crítica de Negócios em uma configuração de três réplicas em vez de uma configuração de duas réplicas para obter perda de dados quase nula.
Para fazer failover da réplica primária para um dos secundários, para um evento planejado, execute o seguinte comando:
Se você se conectar ao primário, poderá usar o seguinte T-SQL para fazer failover da instância SQL para um dos secundários:
ALTER AVAILABILITY GROUP current SET (ROLE = SECONDARY);
Se você se conectar ao secundário, poderá usar o seguinte T-SQL para promover o secundário desejado para a réplica primária.
ALTER AVAILABILITY GROUP current SET (ROLE = PRIMARY);
Réplica primária preferida
Você também pode definir uma réplica específica para ser a réplica primária usando a AZ CLI da seguinte maneira:
az sql mi-arc update --name <sqlinstance name> --k8s-namespace <namespace> --use-k8s --preferred-primary-replica <replica>
Exemplo:
az sql mi-arc update --name sqldemo --k8s-namespace my-namespace --use-k8s --preferred-primary-replica sqldemo-3
Nota
O Kubernetes tentará definir a réplica preferida, no entanto, isso não é garantido.
Restaurando um banco de dados em uma instância de várias réplicas
São necessárias etapas adicionais para restaurar um banco de dados em um grupo de disponibilidade. As etapas a seguir demonstram como restaurar um banco de dados em uma instância gerenciada e adicioná-lo a um grupo de disponibilidade.
Exponha o ponto de extremidade externo da instância primária criando um novo serviço Kubernetes.
Determine o pod que hospeda a réplica primária. Conecte-se à instância gerenciada e execute:
SELECT @@SERVERNAMEA consulta retorna o pod que hospeda a réplica primária.
Crie o serviço Kubernetes para a instância primária executando o seguinte comando se o cluster do Kubernetes usar
NodePortserviços. Substitua<podName>pelo nome do servidor retornado na etapa anterior,<serviceName>pelo nome preferencial para o serviço Kubernetes criado.kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=NodePortPara um serviço LoadBalancer, execute o mesmo comando, exceto que o tipo do serviço criado é
LoadBalancer. Por exemplo:kubectl -n <namespaceName> expose pod <podName> --port=1533 --name=<serviceName> --type=LoadBalancerAqui está um exemplo desse comando executado no Serviço Kubernetes do Azure, onde o pod que hospeda o primário é
sql2-0:kubectl -n arc-cluster expose pod sql2-0 --port=1533 --name=sql2-0-p --type=LoadBalancerObtenha o IP do serviço Kubernetes criado:
kubectl get services -n <namespaceName>Restaure o banco de dados para o ponto de extremidade da instância primária.
Adicione o arquivo de backup do banco de dados ao contêiner da instância primária.
kubectl cp <source file location> <pod name>:var/opt/mssql/data/<file name> -c <serviceName> -n <namespaceName>Exemplo
kubectl cp /home/WideWorldImporters-Full.bak sql2-1:var/opt/mssql/data/WideWorldImporters-Full.bak -c arc-sqlmi -n arcRestaure o arquivo de backup do banco de dados executando o comando abaixo.
RESTORE DATABASE test FROM DISK = '/var/opt/mssql/data/<file name>.bak' WITH MOVE '<database name>' to '/var/opt/mssql/data/<file name>.mdf' ,MOVE '<database name>' to '/var/opt/mssql/data/<file name>_log.ldf' ,RECOVERY, REPLACE, STATS = 5; GOExemplo
RESTORE Database WideWorldImporters FROM DISK = '/var/opt/mssql/data/WideWorldImporters-Full.BAK' WITH MOVE 'WWI_Primary' TO '/var/opt/mssql/data/WideWorldImporters.mdf', MOVE 'WWI_UserData' TO '/var/opt/mssql/data/WideWorldImporters_UserData.ndf', MOVE 'WWI_Log' TO '/var/opt/mssql/data/WideWorldImporters.ldf', MOVE 'WWI_InMemory_Data_1' TO '/var/opt/mssql/data/WideWorldImporters_InMemory_Data_1', RECOVERY, REPLACE, STATS = 5; GOAdicione o banco de dados ao grupo de disponibilidade.
Para que o banco de dados seja adicionado ao AG, ele deve ser executado no modo de recuperação total e um backup de log deve ser feito. Execute as instruções TSQL abaixo para adicionar o banco de dados restaurado ao grupo de disponibilidade.
ALTER DATABASE <databaseName> SET RECOVERY FULL; BACKUP DATABASE <databaseName> TO DISK='<filePath>' ALTER AVAILABILITY GROUP containedag ADD DATABASE <databaseName>O exemplo a seguir adiciona um banco de dados chamado
WideWorldImportersque foi restaurado na instância:ALTER DATABASE WideWorldImporters SET RECOVERY FULL; BACKUP DATABASE WideWorldImporters TO DISK='/var/opt/mssql/data/WideWorldImporters.bak' ALTER AVAILABILITY GROUP containedag ADD DATABASE WideWorldImporters
Importante
Como prática recomendada, você deve excluir o serviço Kubernetes criado acima executando este comando:
kubectl delete svc sql2-0-p -n arc
Limitações
A Instância Gerenciada SQL habilitada pelos grupos de disponibilidade do Azure Arc tem as mesmas limitações que os grupos de disponibilidade do Cluster de Big Data. Para obter mais informações, consulte Implantar o cluster de Big Data do SQL Server com alta disponibilidade.
Conteúdos relacionados
Saiba mais sobre Recursos e Capacidades da Instância Gerenciada SQL habilitada pelo Azure Arc