Regras de alerta recomendadas para clusters Kubernetes
Os alertas no Azure Monitor identificam proativamente problemas relacionados à integridade e ao desempenho de seus recursos do Azure. Este artigo descreve como habilitar e editar um conjunto de regras de alerta de métricas recomendadas predefinidas para seus clusters Kubernetes.
Tipos de regras de alerta
Há dois tipos de regras de alerta métrico usadas com clusters do Kubernetes.
| Tipo de regra de alerta | Description |
|---|---|
| Regras de alerta métrico Prometheus (visualização) | Use dados de métrica coletados do cluster do Kubernetes em um serviço gerenciado do Azure Monitor para Prometheus. Essas regras exigem que o Prometheus esteja habilitado em seu cluster e sejam armazenadas em um grupo de regras do Prometheus. |
| Regras de alerta de métricas da plataforma | Use métricas que são coletadas automaticamente do seu cluster AKS e são armazenadas como regras de alerta do Azure Monitor. |
Ativar regras de alerta recomendadas
Use um dos seguintes métodos para habilitar as regras de alerta recomendadas para seu cluster. Você pode habilitar as regras de alerta de métricas do Prometheus e da plataforma para o mesmo cluster.
Usando o portal do Azure, o grupo de regras Prometheus será criado na mesma região do cluster.
No menu Alertas do cluster, selecione Configurar recomendações.
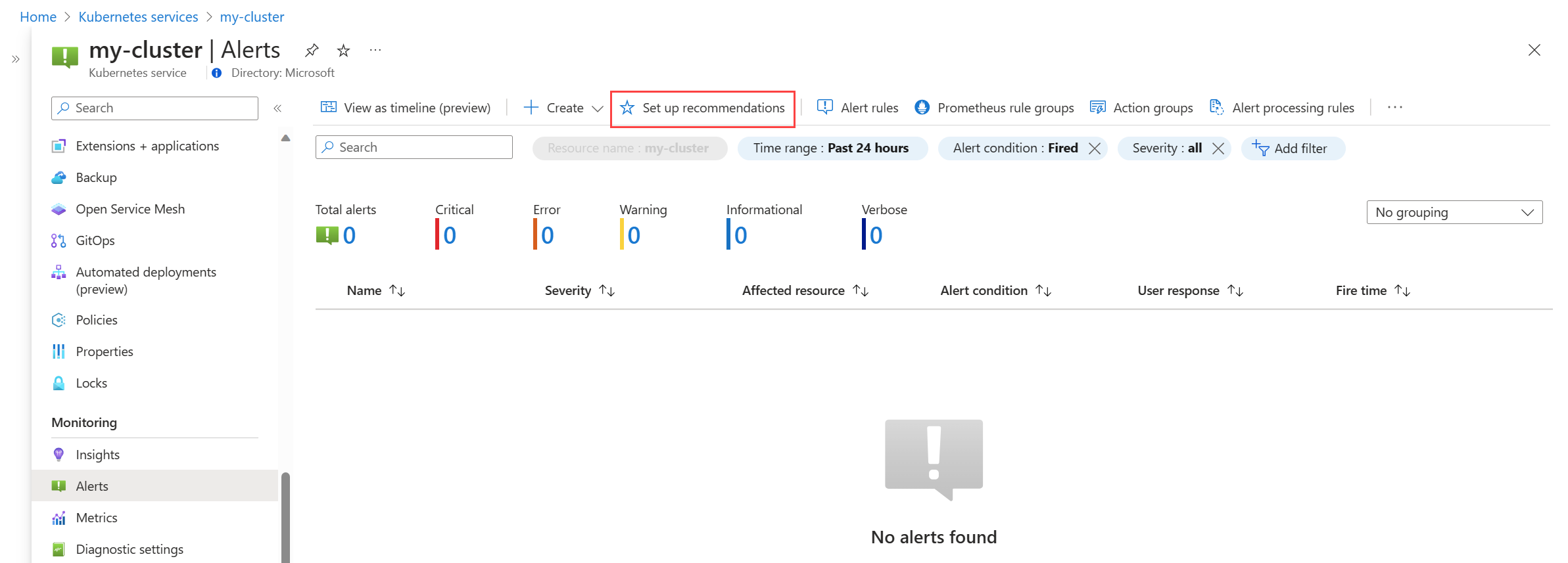
As regras de alerta disponíveis do Prometheus e da plataforma são exibidas com as regras do Prometheus organizadas por pod, cluster e nível de nó. Alterne um grupo de regras Prometheus para habilitar esse conjunto de regras. Expanda o grupo para ver as regras individuais. Você pode deixar os padrões ou desativar regras individuais e editar seu nome e gravidade.
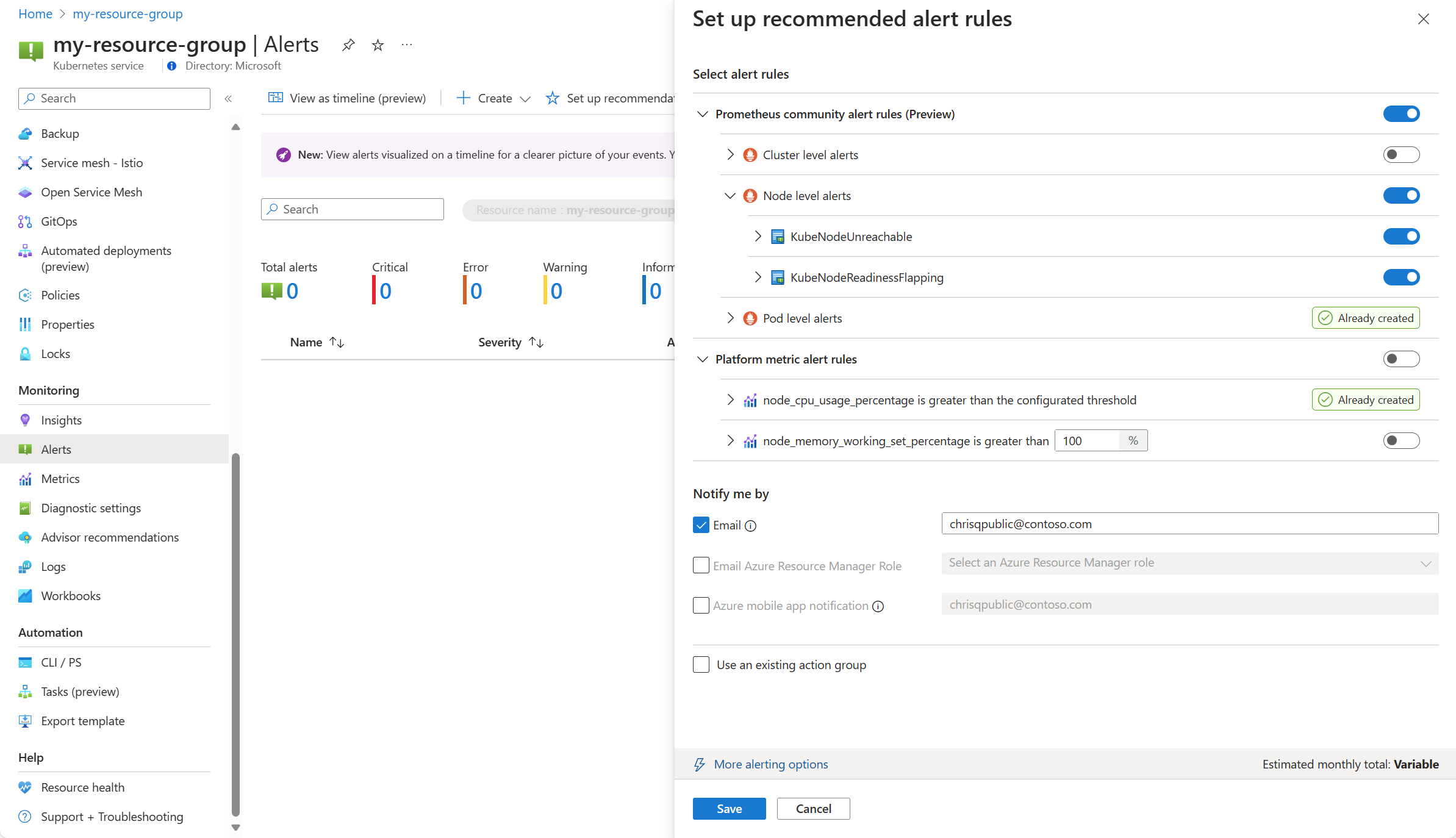
Alterne uma regra de métrica de plataforma para habilitar essa regra. Você pode expandir a regra para modificar seus detalhes, como nome, gravidade e limite.
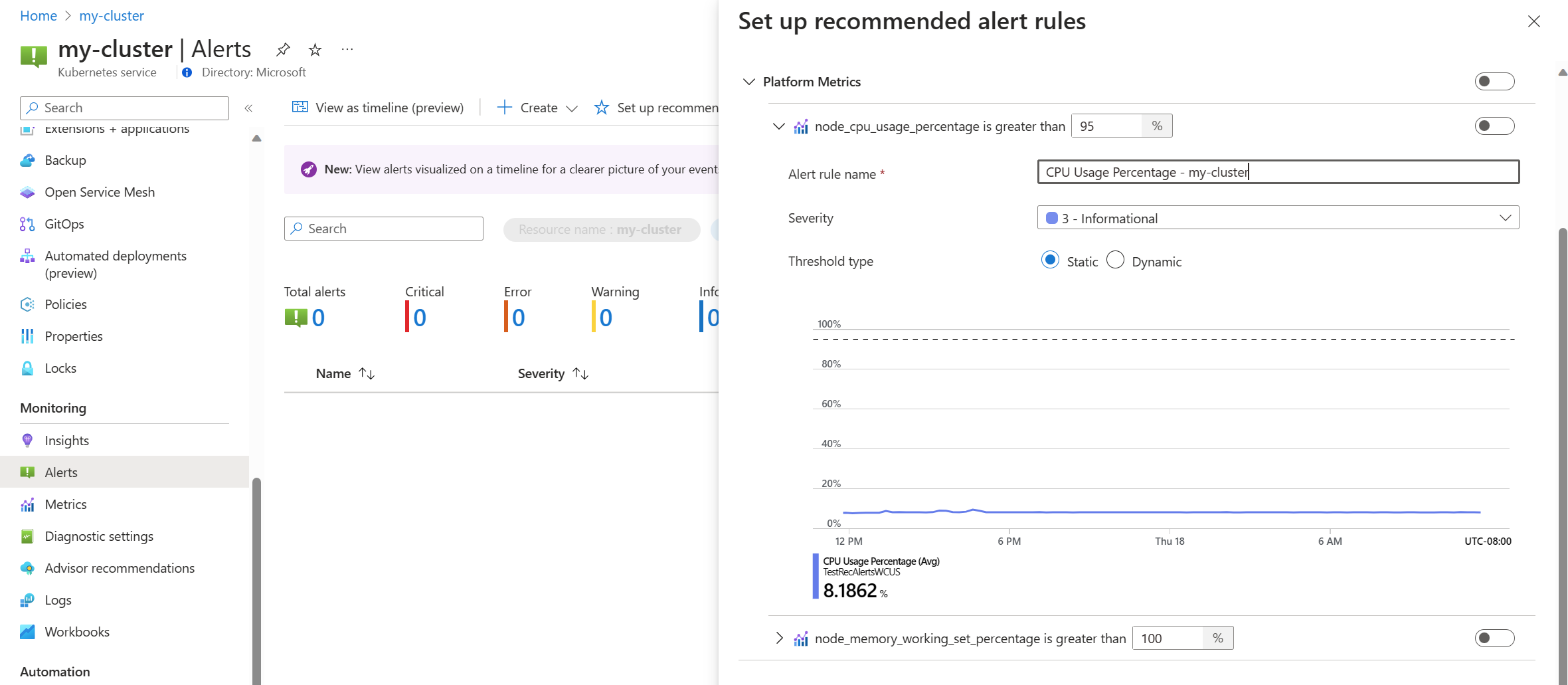
Selecione um ou mais métodos de notificação para criar um novo grupo de ações ou selecione um grupo de ações existente com os detalhes de notificação para esse conjunto de regras de alerta.
Clique em Salvar para salvar o grupo de regras.



Editar regras de alerta recomendadas
Depois que o grupo de regras for criado, você não poderá usar a mesma página no portal para editar as regras. Para métricas Prometheus, você deve editar o grupo de regras para modificar quaisquer regras nele, incluindo a habilitação de quaisquer regras que ainda não estavam habilitadas. Para métricas de plataforma, você pode editar cada regra de alerta.
No menu Alertas do cluster, selecione Configurar recomendações. Todas as regras ou grupos de regras que já foram criados serão rotulados como Já criados.
Expanda a regra ou o grupo de regras. Clique em Ver grupo de regras para Prometheus e Ver regra de alerta para métricas da plataforma.
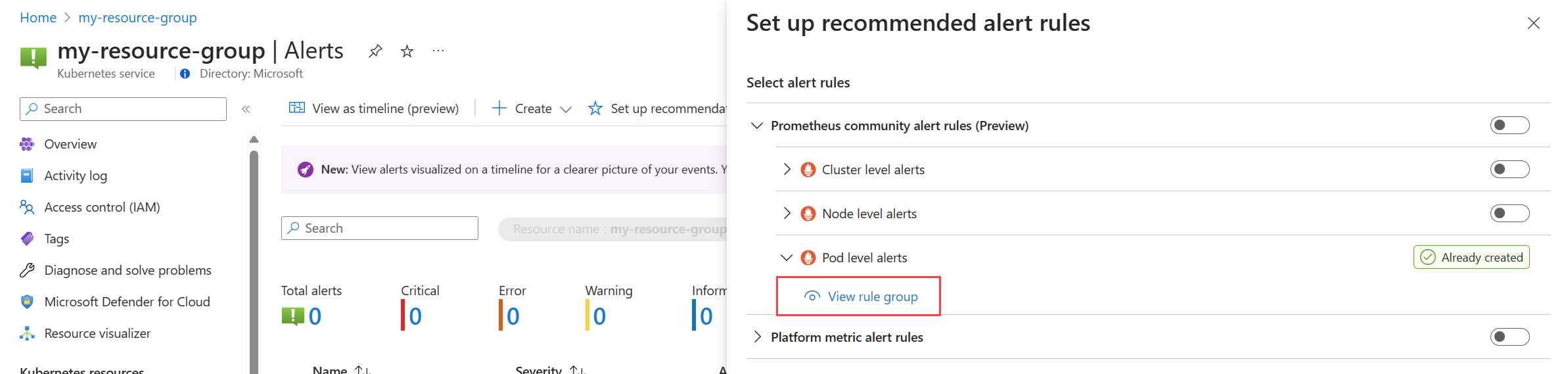
Para os grupos de regras de Prometeu:
selecione Regras para exibir as regras de alerta no grupo.
Clique no ícone Editar ao lado de uma regra que você deseja modificar. Use as orientações em Criar uma regra de alerta para modificar a regra.

Quando terminar de editar as regras no grupo, clique em Salvar para salvar o grupo de regras.
Para métricas de plataforma:
clique em Editar para abrir os detalhes da regra de alerta. Use as orientações em Criar uma regra de alerta para modificar a regra.



Desativar grupo de regras de alerta
Desative o grupo de regras para parar de receber alertas das regras nele contidas.
Exiba o grupo de regras de alerta Prometheus ou a regra de alerta métrica da plataforma conforme descrito em Editar regras de alerta recomendadas.
No menu Visão geral, selecione Desativar.

Detalhes recomendados da regra de alerta
As tabelas a seguir listam os detalhes de cada regra de alerta recomendada. O código-fonte de cada um está disponível no GitHub , juntamente com guias de solução de problemas da comunidade Prometheus.
Regras de alerta da comunidade Prometheus
Alertas ao nível do cluster
| Nome do alerta | Description | Limiar por defeito | Prazo (minutos) |
|---|---|---|---|
| KubeCPUQuotaOvercommit | A cota de recursos da CPU alocada para namespaces excede os recursos de CPU disponíveis nos nós do cluster em mais de 50% nos últimos 5 minutos. | >1.5 | 5 |
| KubeMemoryQuotaOvercommit | A cota de recursos de memória alocada para namespaces excede os recursos de memória disponíveis nos nós do cluster em mais de 50% nos últimos 5 minutos. | >1.5 | 5 |
| O número de contentores mortos OOM é superior a 0 | Um ou mais recipientes dentro de pods foram mortos devido a eventos de falta de memória (OOM) nos últimos 5 minutos. | >0 | 5 |
| KubeClientErrors | A taxa de erros do cliente (códigos de status HTTP começando com 5xx) em solicitações de API do Kubernetes excede 1% da taxa total de solicitações de API nos últimos 15 minutos. | >0.01 | 15 |
| KubePersistentVolumeFillingUp | O volume persistente está a encher e espera-se que fique sem espaço disponível avaliado na relação de espaço disponível, espaço utilizado e tendência linear prevista de espaço disponível nas últimas 6 horas. Estas condições são avaliadas ao longo dos últimos 60 minutos. | N/A | 60 |
| KubePersistentVolumeInodesFillingUp | Menos de 3% dos inodos dentro de um volume persistente estão disponíveis nos últimos 15 minutos. | <0.03 | 15 |
| KubePersistentVolumeErrors | Um ou mais volumes persistentes estão em uma fase com falha ou pendente nos últimos 5 minutos. | >0 | 5 |
| KubeContainerWaiting | Um ou mais contêineres dentro dos pods do Kubernetes estão em um estado de espera nos últimos 60 minutos. | >0 | 60 |
| KubeDaemonSetNotScheduled | Um ou mais pods não estão programados em nenhum nó nos últimos 15 minutos. | >0 | 15 |
| KubeDaemonSetMisScheduled | Um ou mais pods são programados incorretamente dentro do cluster para os últimos 15 minutos. | >0 | 15 |
| KubeQuotaQuaseCheio | A utilização de cotas de recursos do Kubernetes está entre 90% e 100% dos limites rígidos dos últimos 15 minutos. | >0,9 <1 | 15 |
Alertas ao nível do nó
| Nome do alerta | Description | Limiar por defeito | Prazo (minutos) |
|---|---|---|---|
| KubeNodeInacessível | Um nó esteve inacessível nos últimos 15 minutos. | 1 | 15 |
| KubeNodeReadinessFlapping | O status de prontidão de um nó foi alterado mais de 2 vezes nos últimos 15 minutos. | 2 | 15 |
Alertas de nível de pod
| Nome do alerta | Description | Limiar por defeito | Prazo (minutos) |
|---|---|---|---|
| O uso médio de energia fotovoltaica é superior a 80% | O uso médio de Volumes Persistentes (PVs) no pod excede 80% nos últimos 15 minutos. | >0.8 | 15 |
| KubeDeploymentReplicasMismatch | Há uma incompatibilidade entre o número desejado de réplicas e o número de réplicas disponíveis nos últimos 10 minutos. | N/A | 10 |
| KubeStatefulSetReplicasIncompatibilidade | O número de réplicas prontas no StatefulSet não corresponde ao número total de réplicas no StatefulSet nos últimos 15 minutos. | N/A | 15 |
| KubeHpaReplicasIncompatibilidade | O Horizontal Pod Autoscaler no cluster não correspondeu ao número desejado de réplicas nos últimos 15 minutos. | N/A | 15 |
| KubeHpaMaxedOut | O Horizontal Pod Autoscaler (HPA) no cluster tem sido executado no máximo de réplicas nos últimos 15 minutos. | N/A | 15 |
| KubePodCrashLooping | Um ou mais pods estão em uma condição CrashLoopBackOff, onde o pod falha continuamente após a inicialização e não consegue se recuperar com sucesso nos últimos 15 minutos. | >=1 | 15 |
| KubeJobStale | Pelo menos uma instância de trabalho não foi concluída com êxito nas últimas 6 horas. | >0 | 360 |
| Recipiente de pod reiniciado na última 1 hora | Um ou mais contêineres dentro de pods no cluster Kubernetes foram reiniciados pelo menos uma vez na última hora. | >0 | 15 |
| O estado de prontidão das cápsulas é inferior a 80% | A porcentagem de pods em um estado pronto cai abaixo de 80% para qualquer implantação ou daemonset no cluster Kubernetes nos últimos 5 minutos. | <0.8 | 5 |
| Número de pods em estado de falha é maior que 0. | Um ou mais pods estão em um estado de falha nos últimos 5 minutos. | >0 | 5 |
| KubePodNotReadyByController | Um ou mais pods não estão em um estado pronto (ou seja, na fase "Pendente" ou "Desconhecido") nos últimos 15 minutos. | >0 | 15 |
| KubeStatefulSetGenerationMismatch | A geração observada de um Kubernetes StatefulSet não corresponde à sua geração de metadados nos últimos 15 minutos. | N/A | 15 |
| KubeJobFailed | Um ou mais trabalhos do Kubernetes falharam nos últimos 15 minutos. | >0 | 15 |
| O uso médio da CPU por contêiner é maior que 95% | O uso médio da CPU por contêiner excede 95% nos últimos 5 minutos. | >0.95 | 5 |
| O uso médio de memória por contêiner é maior que 95% | O uso médio de memória por contêiner excede 95% nos últimos 5 minutos. | >0.95 | 10 |
| KubeletPodStartUpLatencyHigh | O percentil 99 da latência de inicialização do pod excede 60 segundos nos últimos 10 minutos. | >60 | 10 |
Regras de alerta de métricas de plataforma
| Nome do alerta | Description | Limiar por defeito | Prazo (minutos) |
|---|---|---|---|
| A porcentagem de CPU do nó é maior que 95% | A porcentagem de CPU do nó é maior que 95% nos últimos 5 minutos. | 95 | 5 |
| A porcentagem do conjunto de trabalho da memória do nó é maior que 100% | A porcentagem do conjunto de trabalho da memória do nó é maior que 95% nos últimos 5 minutos. | 100 | 5 |
Alertas de métricas de insights de contêiner herdado (visualização)
As regras métricas no Container insights serão desativadas em 31 de maio de 2024 (isso foi anunciado anteriormente como 14 de março de 2026). Essas regras não estão disponíveis para criação usando o portal desde 15 de agosto de 2023. Essas regras estavam em visualização pública, mas serão desativadas sem atingir a disponibilidade geral, uma vez que os novos alertas de métricas recomendadas descritos neste artigo já estão disponíveis.
Se você já habilitou essas regras de alerta herdadas, deve desativá-las e habilitar a nova experiência.
Desativar regras de alerta de métricas
- No menu Informações do cluster, selecione Alertas recomendados (visualização).
- Altere o status de cada regra de alerta para Desativado.
Próximos passos
- Leia sobre os diferentes tipos de regra de alerta no Azure Monitor.
- Leia sobre como alertar grupos de regras no serviço gerenciado do Azure Monitor para Prometheus.