O processo de operações de machine learning
O processo de desenvolvimento de modelos
O processo de desenvolvimento deve produzir os seguintes resultados:
A preparação é automatizada e os modelos são validados, o que inclui a funcionalidade de teste e o desempenho (por exemplo, com métricas de precisão).
A implementação na infraestrutura utilizada para inferência (incluindo a monitorização) é automatizada.
Os mecanismos criam um registo de auditoria de dados ponto a ponto. A nova preparação automática de modelos ocorre quando os dados desfasam ao longo do tempo, o que é relevante para sistemas de aprendizagem automática em larga escala.
O diagrama seguinte ilustra o ciclo de vida de implementação de um sistema de machine learning:
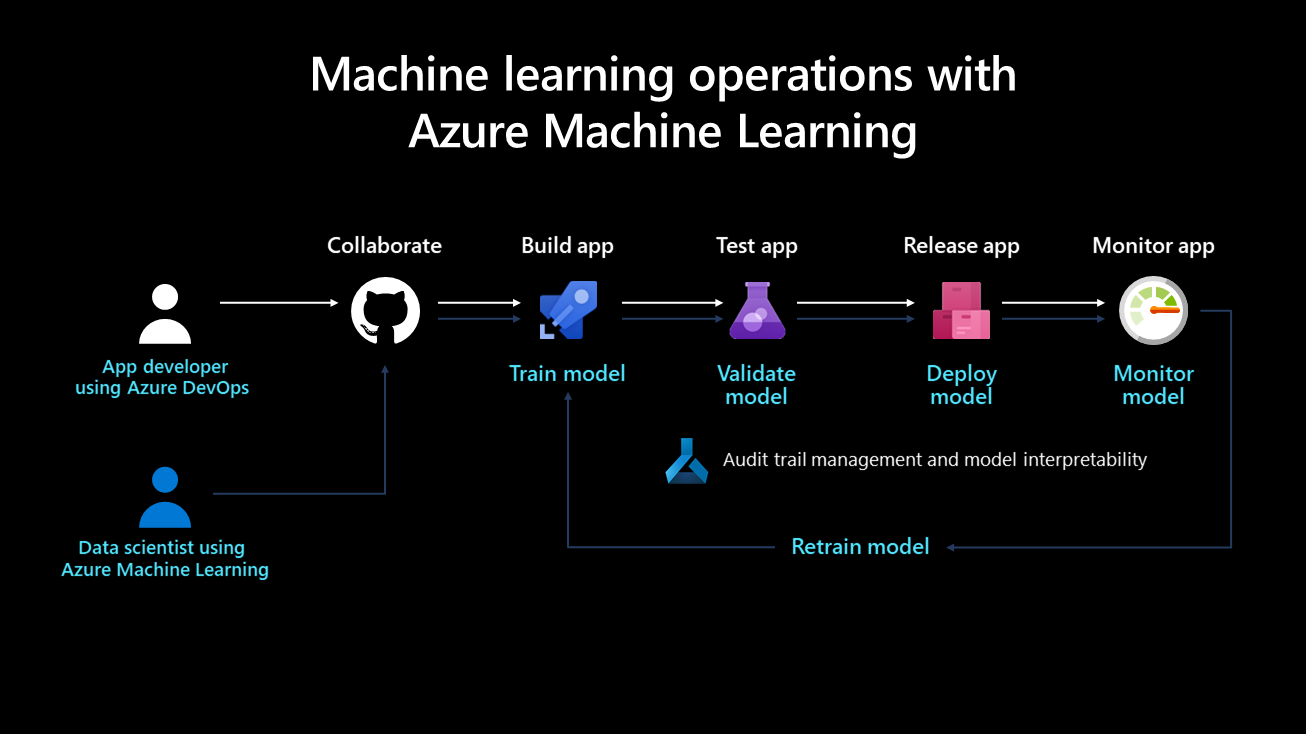
Depois de desenvolvido, um modelo de machine learning é preparado, validado, implementado e monitorizado. Do ponto de vista organizacional e a nível técnico e de gestão, é importante definir quem é o proprietário e implementa este processo. Em grandes empresas, um cientista de dados pode ser o proprietário dos passos de preparação e validação de modelos, e um engenheiro de machine learning pode ter tendência para os passos restantes. Em empresas mais pequenas, um cientista de dados pode possuir todos os passos.
Preparar o modelo
Neste passo, um conjunto de dados de preparação prepara o modelo de machine learning. O código de preparação é controlado por versões e reutilizável e esta funcionalidade otimiza os cliques e os acionadores de eventos (como uma nova versão dos dados que estão a ficar disponíveis) para automatizar a forma como o modelo é preparado.
Validar o modelo
Este passo utiliza métricas estabelecidas, como uma métrica de precisão, para validar automaticamente o modelo preparado recentemente e compará-lo com as mais antigas. A sua precisão aumentou? Se sim, este modelo poderá estar registado no registo de modelos para garantir que os próximos passos podem consumi-lo. Se o novo modelo tiver um desempenho pior, um cientista de dados pode ser alertado para investigar o motivo ou eliminar o modelo recém-preparado.
Implementar o modelo
Implemente o modelo como um serviço de API para aplicações Web no passo de implementação. Esta abordagem permite que o modelo seja dimensionado e atualizado independentemente das aplicações. Em alternativa, o modelo pode ser utilizado para efetuar a classificação de lotes em que é utilizado uma vez ou periodicamente para calcular predições em novos pontos de dados. Isto é útil quando grandes quantidades de dados têm de ser processadas de forma assíncrona. Pode encontrar mais detalhes sobre os modelos de implementação na inferência de machine learning durante a página de implementação .
Monitorizar o modelo
É necessário monitorizar o modelo por dois motivos fundamentais. Em primeiro lugar, a monitorização do modelo ajuda a garantir que está tecnicamente funcional; por exemplo, capaz de gerar predições. Isto é importante se as aplicações de uma organização dependerem do modelo e o utilizarem em tempo real. A monitorização do modelo também ajuda as organizações a avaliar se gera continuamente predições úteis. Isto pode não ser útil quando ocorre um desvio de dados, como quando os dados utilizados para preparar o modelo diferem significativamente dos dados enviados para o modelo durante a fase de predição. Por exemplo, um modelo preparado para recomendar produtos a jovens pode produzir resultados indesejáveis ao recomendar produtos a pessoas de uma faixa etária diferente. A monitorização de modelos com desfasamento de dados pode detetar este tipo de incompatibilidade, alertar os engenheiros de machine learning e preparar automaticamente o modelo com dados mais relevantes ou mais recentes.
Como monitorizar modelos
Uma vez que a desfasamento de dados, a sazonalidade ou a arquitetura mais recente otimizada para um melhor desempenho podem fazer com que o desempenho do modelo diminua ao longo do tempo, é importante estabelecer um processo para implementar continuamente modelos. Algumas práticas recomendadas incluem:
Propriedade: Um proprietário deve ser atribuído ao processo de monitorização do desempenho do modelo para gerir ativamente o seu desempenho.
Pipelines de versão: Configure primeiro um pipeline de versão no Azure DevOps e defina o acionador para o registo de modelos. Quando um novo modelo é registado no registo, o pipeline de versão aciona e termina um processo de implementação.
Pré-requisitos para a preparação de modelos
Recolher dados de modelos em produção é um pré-requisito para preparar modelos numa arquitetura de integração contínua/desenvolvimento contínuo e este processo utiliza dados de entrada de pedidos de classificação. Esta capacidade está atualmente limitada a dados tabulares que podem ser analisados como JSON com formatação e manipulação mínimas; vídeo, áudio e imagens são excluídos. Esta capacidade está disponível para modelos no Azure Kubernetes Service (AKS). Os dados recolhidos são armazenados num blob do Azure.
Para preparar novamente um modelo:
Monitorizar o desvio de dados dos dados de entrada recolhidos. A configuração de um processo de monitorização requer a extração do carimbo de data/hora dos dados de produção. Isto é necessário para comparar os dados de produção e os dados de linha de base (os dados de preparação utilizados para criar o modelo). A forma preferencial de monitorizar o desfasamento de dados é através do Azure Monitor Application Insights. Esta funcionalidade fornece um alerta que pode acionar ações como e-mail, sms, push ou Funções do Azure. Tem de ativar o Application Insights para registar dados.
Analise os dados recolhidos. Certifique-se de que recolhe dados de modelos em produção e inclui os resultados no script de classificação do modelo. Recolha todas as funcionalidades utilizadas para a classificação de modelos, uma vez que garante que todas as funcionalidades necessárias estão presentes e podem ser utilizadas como dados de preparação.
Decida se a nova preparação com os dados recolhidos é necessária. Muitas coisas causam desfasamento de dados, incluindo problemas de sensor para a sazonalidade, alterações no comportamento do utilizador e problemas de qualidade de dados relacionados com a origem de dados. A nova preparação de modelos não é necessária em todos os casos, pelo que é recomendado investigar e compreender a causa do desfasamento de dados antes de prosseguir com isto.
Volte a preparar o modelo. A preparação de modelos já deve ser automatizada e este passo envolve acionar o passo de preparação atual. Isto pode dever-se ao momento em que foi detetado um desvio de dados (e não está relacionado com um problema de dados) ou quando um engenheiro de dados publicou uma nova versão de um conjunto de dados. Dependendo do caso de utilização, estes passos podem ser totalmente automatizados ou supervisionados por um humano. Por exemplo, embora alguns casos de utilização, como recomendações de produtos, possam ser executados de forma autónoma no futuro, outros em finanças teriam padrões como a equidade e a transparência dos modelos e exigiriam que um humano aprovasse modelos recém-preparados.
No início, é comum uma organização automatizar apenas a preparação e implementação de um modelo, mas não os passos de validação, monitorização e preparação, que são executados manualmente. Eventualmente, os passos de automatização para estas tarefas podem progredir até que o estado pretendido seja alcançado. O DevOps e as operações de machine learning são conceitos que se desenvolvem ao longo do tempo e as organizações devem estar cientes da evolução.
Ciclo de vida do Processo Ciência de Dados Equipa
O Team Ciência de Dados Process (TDSP) fornece um ciclo de vida para estruturar o desenvolvimento dos seus projetos de ciência de dados. O ciclo de vida descreve as principais fases que os projetos normalmente executam, muitas vezes iterativamente:
- Noções sobre empresas
- Aquisição e compreensão de dados
- Modelação
- Implementação
Os objetivos, tarefas e artefactos de documentação para cada fase do ciclo de vida do TDSP são descritos no ciclo de vida do Processo de Ciência de Dados equipa.
As funções e atividades nas operações de machine learning
De acordo com o ciclo de vida do TDSP, as principais funções no projeto de IA são engenheiro de dados, cientista de dados e engenheiro de operações de machine learning. Estas funções são fundamentais para o sucesso do projeto e têm de trabalhar em conjunto para soluções precisas, repetíveis, dimensionáveis e prontas para produção.

Engenheiro de dados: Esta função ingere, valida e limpa os dados. Assim que os dados são refinados, são catalogados e disponibilizados para os cientistas de dados utilizarem. Nesta fase, é importante explorar e analisar dados duplicados, remover valores atípicos e identificar dados em falta. Estas atividades devem ser definidas nos passos do pipeline e executadas à medida que o pipeline do comboio é pré-processado. Os nomes exclusivos e específicos devem ser atribuídos às funcionalidades principais e geradas.
Cientista de dados (ou engenheiro de IA): Esta função navega no processo de pipeline de preparação e avalia modelos. Um cientista de dados recebe dados do engenheiro de dados e identifica padrões e relações no mesmo, possivelmente selecionando ou gerando funcionalidades para a experimentação. Uma vez que a engenharia de funcionalidades desempenha um papel importante na criação de um modelo generalizado de som, é fundamental que esta fase seja concluída o mais detalhadamente possível. Podem ser realizadas várias experimentações com diferentes algoritmos e hiperparâmetros. As ferramentas do Azure, como o machine learning automatizado, podem automatizar esta tarefa, o que também pode ajudar no subajuste ou no sobreajuste de um modelo. Um modelo preparado com êxito é, em seguida, registado no registo de modelos. O modelo deve ter um nome exclusivo e específico e um histórico de versões deve ser mantido para rastreabilidade.
Engenheiro de operações de machine learning: Esta função cria pipelines ponto a ponto para integração e entrega contínuas. Isto inclui empacotar o modelo numa imagem do Docker, validar e criar perfis do modelo, aguardar aprovação de um interveniente e implementar o modelo num serviço de orquestração de contentores, como o AKS. Vários acionadores podem ser definidos durante a integração contínua e o código do modelo pode acionar o pipeline de preparação e o pipeline de versão posteriormente.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários