Tutorial: Configurar um lote de produtos de dados
Neste tutorial, saiba como configurar serviços de produtos de dados que já estão implantados. Use o Azure Data Factory para integrar e orquestrar seus dados e use o Microsoft Purview para descobrir, gerenciar e governar ativos de dados.
Aprenda a:
- Criar e implantar os recursos necessários
- Atribuir funções e permissões de acesso
- Conecte recursos para integração de dados
Este tutorial ajuda você a se familiarizar com os serviços implantados no grupo de recursos de produto de dados de <DMLZ-prefix>-dev-dp001 exemplo. Experimente como os serviços do Azure interagem entre si e quais medidas de segurança estão em vigor.
Ao implantar os novos componentes, você terá a chance de investigar como o Purview conecta a governança de serviços para criar um mapa holístico e atualizado do seu cenário de dados. O resultado é a descoberta automatizada de dados, a classificação de dados confidenciais e a linhagem de dados de ponta a ponta.
Pré-requisitos
Antes de começar a configurar o lote de produtos de dados, verifique se você atende a estes pré-requisitos:
Subscrição do Azure. Se você não tiver uma assinatura do Azure, crie sua conta gratuita do Azure hoje.
Permissões para a assinatura do Azure. Para configurar o Purview e o Azure Synapse Analytics para a implantação, você deve ter a função de Administrador de Acesso de Usuário ou a função de Proprietário na assinatura do Azure. Você definirá mais atribuições de função para serviços e entidades de serviço no tutorial.
Recursos implantados. Para concluir o tutorial, esses recursos já devem ser implantados em sua assinatura do Azure:
- Zona de aterragem de gestão de dados. Para obter mais informações, consulte o repositório GitHub da zona de aterrissagem de gerenciamento de dados.
- Zona de aterragem de dados. Para obter mais informações, consulte o repositório GitHub da zona de aterrissagem de dados.
- Lote de dados do produto. Para obter mais informações, consulte o repositório GitHub em lote de produtos de dados.
Conta Microsoft Purview. A conta é criada como parte da implantação da zona de aterrissagem do gerenciamento de dados.
Tempo de execução de integração auto-hospedado. O tempo de execução é criado como parte da implantação da zona de aterrissagem de dados.
Nota
Neste tutorial, os espaços reservados referem-se aos recursos de pré-requisito que você implanta antes de começar o tutorial:
<DMLZ-prefix>refere-se ao prefixo que você inseriu quando criou a implantação da zona de aterrissagem do gerenciamento de dados.<DLZ-prefix>refere-se ao prefixo que você inseriu quando criou sua implantação da zona de aterrissagem de dados.<DP-prefix>refere-se ao prefixo que você inseriu quando criou sua implantação em lote do produto de dados.
Criar instâncias do Banco de Dados SQL do Azure
Para começar este tutorial, crie duas instâncias de exemplo do Banco de dados SQL. Você usará os bancos de dados para simular fontes de dados de CRM e ERP em seções posteriores.
No portal do Azure, nos controles globais do portal, selecione o ícone do Cloud Shell para abrir um terminal do Azure Cloud Shell. Selecione Bash para o tipo de terminal.

No Cloud Shell, execute o seguinte script. O script localiza o grupo de recursos e o
<DLZ-prefix>-dev-dp001servidor SQL do<DP-prefix>-dev-sqlserver001Azure que está no grupo de recursos. Em seguida, o script cria as duas instâncias do<DP-prefix>-dev-sqlserver001Banco de dados SQL no servidor. Os bancos de dados são pré-preenchidos com dados de exemplo do AdventureWorks. Os dados incluem as tabelas que você usa neste tutorial.Certifique-se de substituir o valor do espaço reservado do parâmetro por sua própria ID de assinatura do
subscriptionAzure.# Azure SQL Database instances setup # Create the AdatumCRM and AdatumERP databases to simulate customer and sales data. # Use the ID for the Azure subscription you used to deployed the data product. az account set --subscription "<your-subscription-ID>" # Get the resource group for the data product. resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dp001')==\`true\`].name") # Get the existing Azure SQL Database server name. sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") # Create the first SQL Database instance, AdatumCRM, to create the customer's data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumCRM --service-objective Basic --sample-name AdventureWorksLT # Create the second SQL Database instance, AdatumERP, to create the sales data source. az sql db create --resource-group $resourceGroupName --server $sqlServerName --name AdatumERP --service-objective Basic --sample-name AdventureWorksLT
Quando o script terminar de ser executado, no servidor SQL do <DP-prefix>-dev-sqlserver001 Azure, você terá duas novas instâncias AdatumCRM do Banco de Dados SQL e AdatumERP. Ambos os bancos de dados estão na camada de computação Básica. Os bancos de dados estão localizados no mesmo <DLZ-prefix>-dev-dp001 grupo de recursos usado para implantar o lote de produtos de dados.
Configurar o Purview para catalogar o lote de produtos de dados
Em seguida, conclua as etapas para configurar o Purview para catalogar o lote de produtos de dados. Você começa criando uma entidade de serviço. Em seguida, você configura os recursos necessários e atribui funções e permissões de acesso.
Criar um principal de serviço
No portal do Azure, nos controles globais do portal, selecione o ícone do Cloud Shell para abrir um terminal do Azure Cloud Shell. Selecione Bash para o tipo de terminal.
Revise o seguinte script:
- Substitua o valor do espaço reservado do parâmetro por sua própria ID de assinatura do
subscriptionIdAzure. - Substitua o valor do espaço reservado do
spnameparâmetro pelo nome que você deseja usar para a entidade de serviço. O nome da entidade de serviço deve ser exclusivo na assinatura.
Depois de atualizar os valores dos parâmetros, execute o script no Cloud Shell.
# Replace the parameter values with the name you want to use for your service principal name and your Azure subscription ID. spname="<your-service-principal-name>" subscriptionId="<your-subscription-id>" # Set the scope to the subscription. scope="/subscriptions/$subscriptionId" # Create the service principal. az ad sp create-for-rbac \ --name $spname \ --role "Contributor" \ --scope $scope- Substitua o valor do espaço reservado do parâmetro por sua própria ID de assinatura do
Verifique a saída JSON para obter um resultado semelhante ao exemplo a seguir. Anote ou copie os valores na saída para usar em etapas posteriores.
{ "appId": "<your-app-id>", "displayName": "<service-principal-display-name>", "name": "<your-service-principal-name>", "password": "<your-service-principal-password>", "tenant": "<your-tenant>" }
Configurar o acesso e as permissões da entidade de serviço
A partir da saída JSON gerada na etapa anterior, obtenha os seguintes valores retornados:
- ID da entidade de serviço (
appId) - chave principal de serviço (
password)
A entidade de serviço deve ter as seguintes permissões:
- Função Leitor de Dados de Blob de Armazenamento nas contas de armazenamento.
- Permissões de leitor de dados nas instâncias do Banco de dados SQL.
Para configurar a entidade de serviço com a função e as permissões necessárias, conclua as etapas a seguir.
Permissões da conta de Armazenamento do Azure
No portal do Azure, vá para a conta de Armazenamento do
<DLZ-prefix>devrawAzure. No menu de recursos, selecione Controle de acesso (IAM).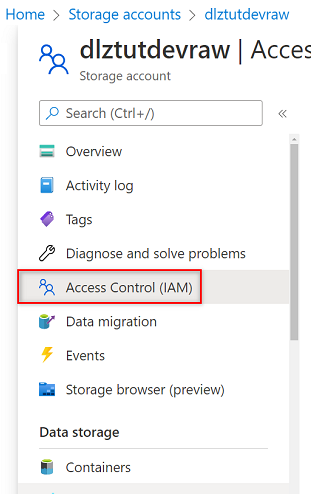
Selecione Adicionar>Adicionar atribuição de função.
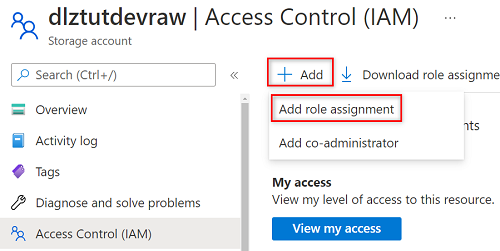
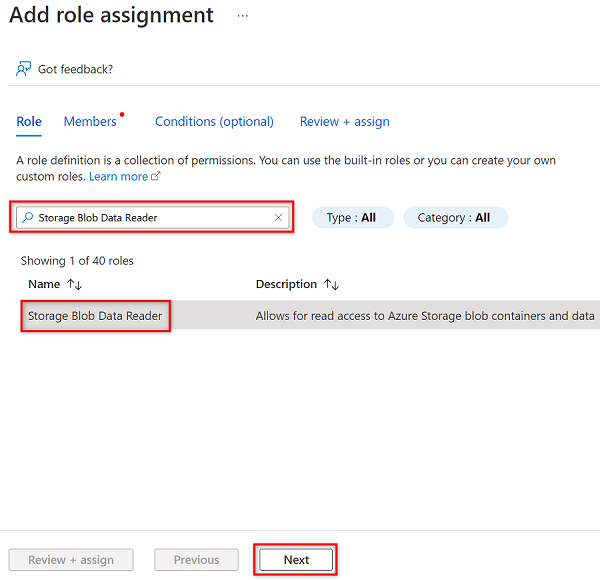
Em Adicionar atribuição de função, na guia Função, procure e selecione Leitor de Dados de Blob de Armazenamento. Em seguida, selecione Seguinte.
Em Membros, escolha Selecionar membros.
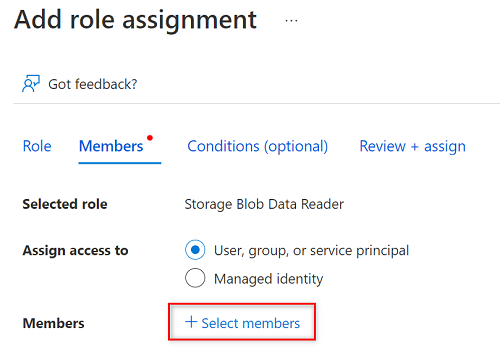
Em Selecionar membros, procure o nome da entidade de serviço que você criou.

Nos resultados da pesquisa, selecione a entidade de serviço e escolha Selecionar.
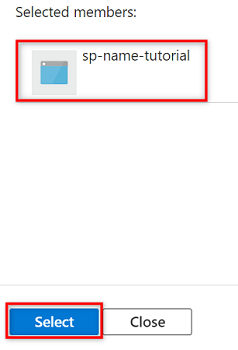
Para concluir a atribuição de função, selecione Rever + atribuir duas vezes.
Repita as etapas nesta seção para as contas de armazenamento restantes:
<DLZ-prefix>devencur<DLZ-prefix>devwork
Permissões do Banco de Dados SQL
Para definir permissões do Banco de Dados SQL, conecte-se à máquina virtual SQL do Azure usando o editor de consultas. Como todos os recursos estão por trás de um ponto de extremidade privado, você deve primeiro entrar no portal do Azure usando uma máquina virtual de host do Azure Bastion.
No portal do Azure, conecte-se à máquina virtual implantada <DMLZ-prefix>-dev-bastion no grupo de recursos. Se você não tiver certeza de como se conectar à máquina virtual usando o serviço de host Bastion, consulte Conectar-se a uma VM.
Para adicionar a entidade de serviço como um usuário no banco de dados, talvez seja necessário primeiro adicionar-se como administrador do Microsoft Entra. Nas etapas 1 e 2, você se adiciona como administrador do Microsoft Entra. Nas etapas 3 a 5, você concede permissões à entidade de serviço para um banco de dados. Quando tiver sessão iniciada no portal a partir da máquina virtual de anfitrião Bastion, procure máquinas virtuais SQL do Azure no portal do Azure.
Vá para a máquina virtual SQL do
<DP-prefix>-dev-sqlserver001Azure. No menu de recursos em Configurações, selecione Microsoft Entra ID.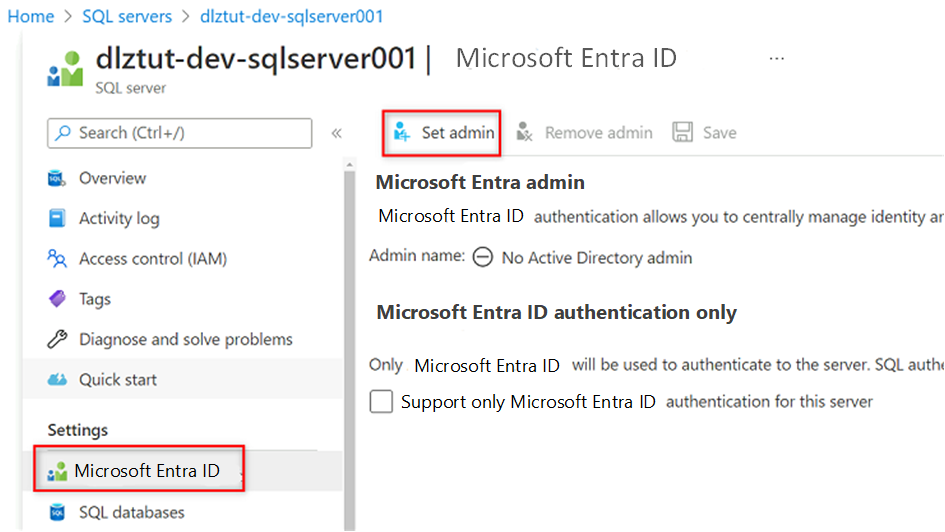
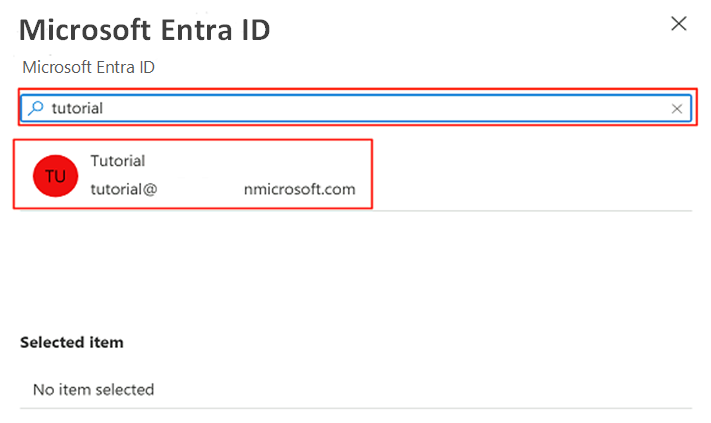
Na barra de comandos, selecione Definir administrador. Pesquise e selecione a sua própria conta. Escolha Selecionar.
No menu de recursos, selecione bancos de dados SQL e, em seguida, selecione o
AdatumCRMbanco de dados.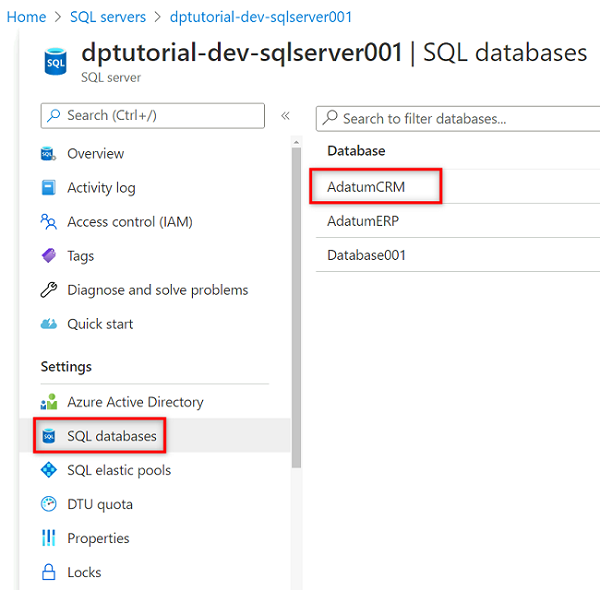
No menu de recursos do AdatumCRM, selecione Editor de consultas (visualização). Em Autenticação do Ative Directory, selecione o botão Continuar como para entrar.
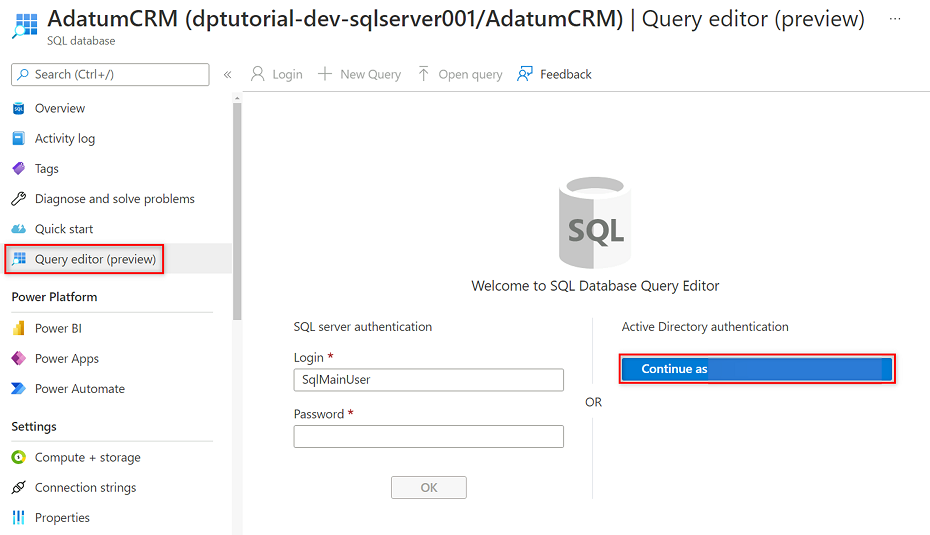
No editor de consultas, revise as instruções a seguir para substituir
<service principal name>pelo nome da entidade de serviço criada (por exemplo,purview-service-principal). Em seguida, execute as instruções.CREATE USER [<service principal name>] FROM EXTERNAL PROVIDER GO EXEC sp_addrolemember 'db_datareader', [<service principal name>] GO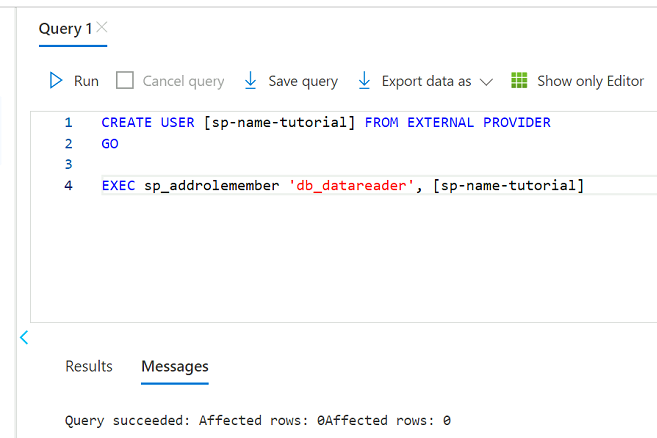
Repita as etapas 3 a 5 para o AdatumERP banco de dados.
Configurar o cofre de chaves
O Purview lê a chave da entidade de serviço de uma instância do Cofre de Chaves do Azure. O cofre de chaves é criado na implantação da zona de aterrissagem de gerenciamento de dados. As seguintes etapas são necessárias para configurar o cofre de chaves:
Adicione a chave da entidade de serviço ao cofre de chaves como um segredo.
Dê permissões ao Purview MSI Secrets Reader no cofre de chaves.
Adicione o cofre de chaves ao Purview como uma conexão de cofre de chaves.
Crie uma credencial no Purview que aponte para o segredo do cofre de chaves.
Adicionar permissões para adicionar segredo ao cofre de chaves
No portal do Azure, vá para o serviço Azure Key Vault. Procure o cofre da
<DMLZ-prefix>-dev-vault001chave.
No menu de recursos, selecione Controle de acesso (IAM). Na barra de comandos, selecione Adicionar e, em seguida, selecione Adicionar atribuição de função.
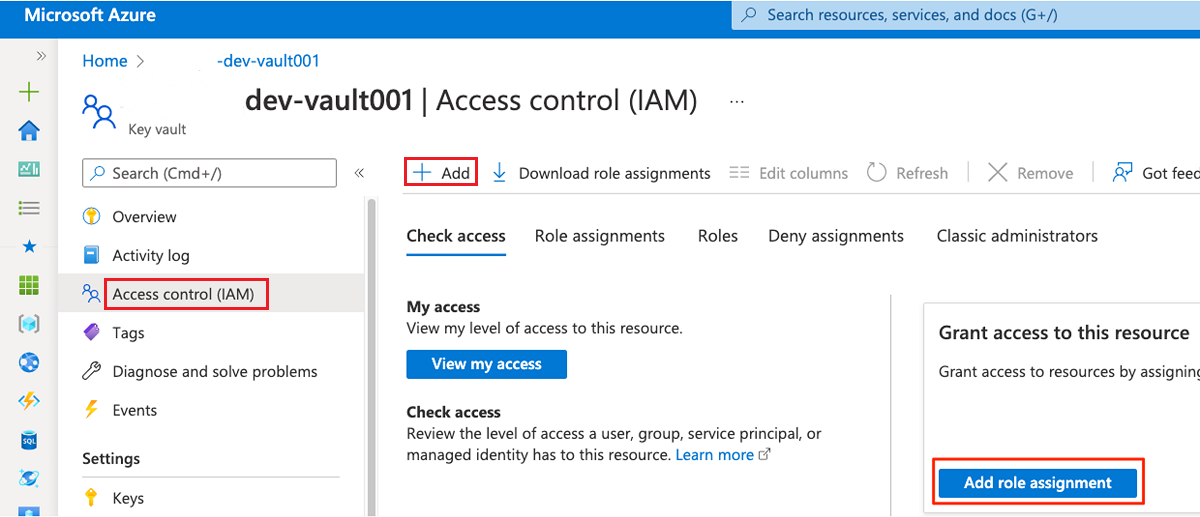
Na guia Função, procure e selecione Administrador do Cofre da Chave. Selecione Seguinte.
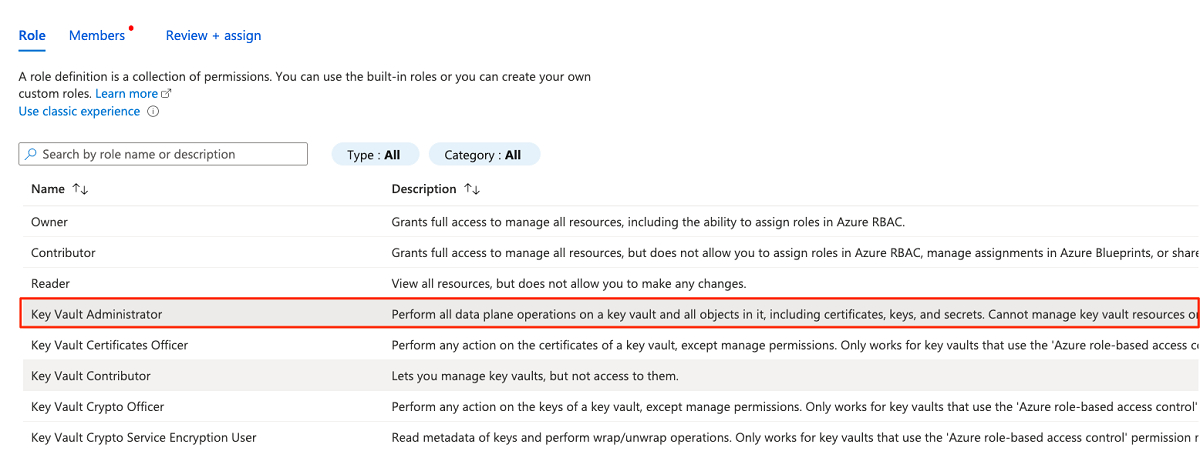
Em Membros, escolha Selecionar membros para adicionar a conta que está conectada no momento.
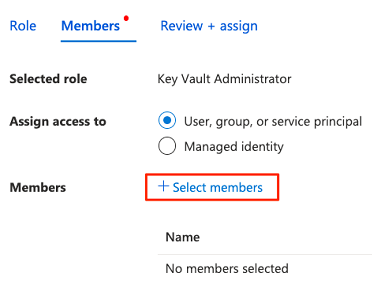
Em Selecionar membros, procure a conta que está atualmente conectada. Selecione a conta e, em seguida, escolha Selecionar.
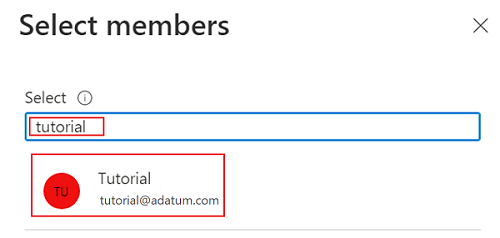
Para concluir o processo de atribuição de função, selecione Rever + atribuir duas vezes.
Adicionar um segredo ao cofre de chaves
Conclua as etapas a seguir para entrar no portal do Azure a partir da máquina virtual do host Bastion.
No menu de recursos do cofre de
<DMLZ-prefix>-dev-vault001chaves, selecione Segredos. Na barra de comandos, selecione Gerar/Importar para criar um novo segredo.
Em Criar um segredo, selecione ou insira os seguintes valores:
Definição Ação Opções de carregamento Selecione Manual. Name Insira service-principal-secret. valor Introduza a palavra-passe da entidade de serviço que criou anteriormente. 
Nota
Esta etapa cria um segredo nomeado
service-principal-secretno cofre de chaves usando a chave de senha da entidade de serviço. O Purview usa o segredo para se conectar e verificar as fontes de dados. Se introduzir uma palavra-passe incorreta, não poderá concluir as secções seguintes.Selecione Criar.
Configurar permissões do Purview no cofre de chaves
Para que a instância Purview leia os segredos armazenados no cofre de chaves, você deve atribuir a Purview as permissões relevantes no cofre de chaves. Para definir as permissões, adicione a Identidade Gerenciada Purview à função Leitor de Segredos do cofre de chaves.
No menu de recursos do cofre de chaves, selecione Controle de
<DMLZ-prefix>-dev-vault001acesso (IAM).Na barra de comandos, selecione Adicionar e, em seguida, selecione Adicionar atribuição de função.
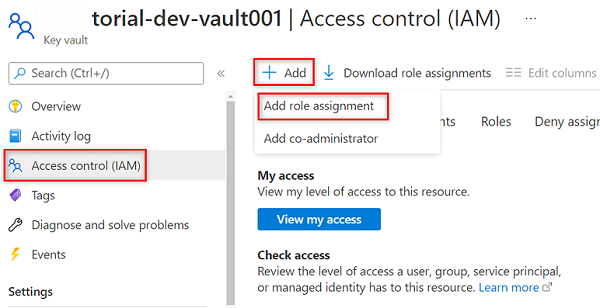
Em Função, procure e selecione Key Vault Secrets User. Selecione Seguinte.

Em Membros, escolha Selecionar membros.
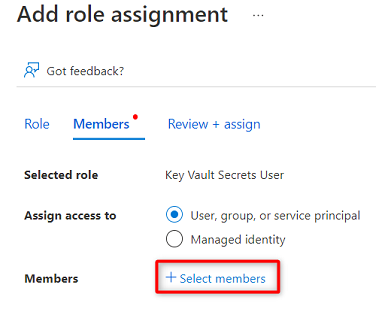
Procure a
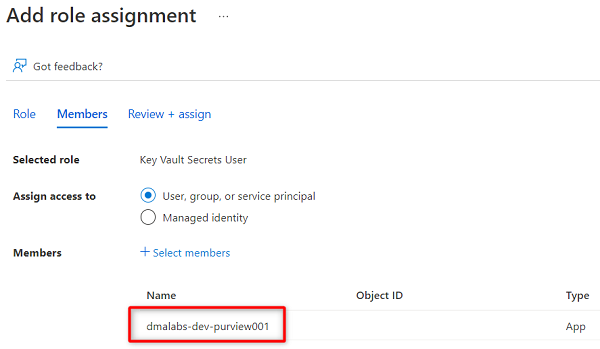
<DMLZ-prefix>-dev-purview001instância Purview. Selecione a instância para adicionar a conta relevante. Em seguida, escolha Selecionar.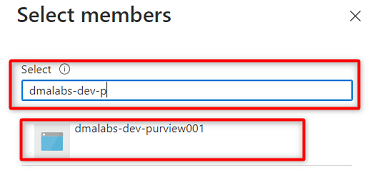
Para concluir o processo de atribuição de função, selecione Rever + atribuir duas vezes.
Configurar uma conexão de cofre de chaves no Purview
Para configurar uma conexão de cofre de chaves com o Purview, você deve entrar no portal do Azure usando uma máquina virtual de host do Azure Bastion.
No portal do Azure, vá para a
<DMLZ-prefix>-dev-purview001conta Purview. Em Introdução, em Abrir o Portal de Governança do Microsoft Purview, selecione Abrir.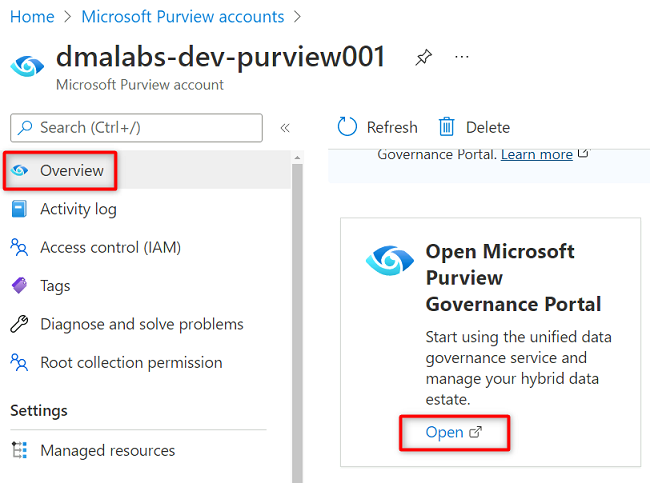
No Purview Studio, selecione Credenciais de gerenciamento>. Na barra de comandos Credenciais, selecione Gerir ligações do Cofre da Chave e, em seguida, selecione Novo.
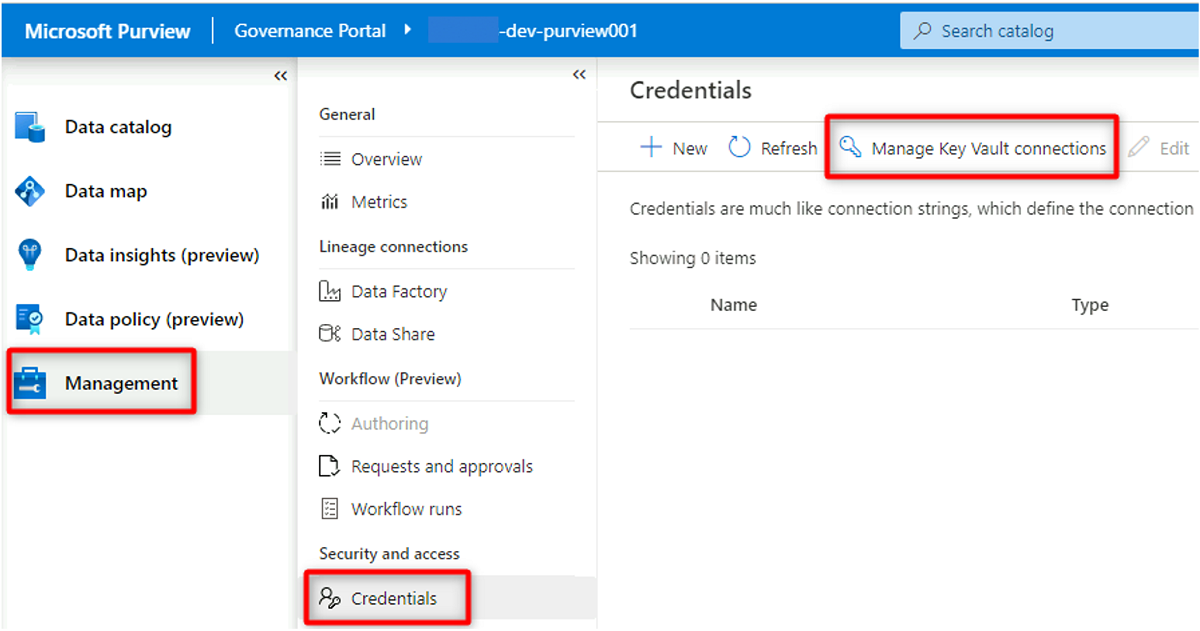
Em Nova conexão do cofre de chaves, selecione ou insira as seguintes informações:
Definição Ação Name Digite <DMLZ-prefix-dev-vault001>. Subscrição do Azure Selecione a assinatura que hospeda o cofre de chaves. Nome do Cofre da Chave Selecione o cofre de chaves DMLZ-prefix-dev-vault001><. 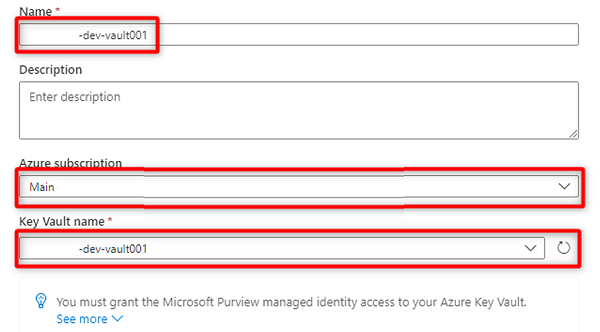
Selecione Criar.
Em Confirmar concessão de acesso, selecione Confirmar.
Criar uma credencial no Purview
A etapa final para configurar o cofre de chaves é criar uma credencial no Purview que aponte para o segredo que você criou no cofre de chaves para a entidade de serviço.
No Purview Studio, selecione Credenciais de gerenciamento>. Na barra de comandos Credenciais, selecione Novo.
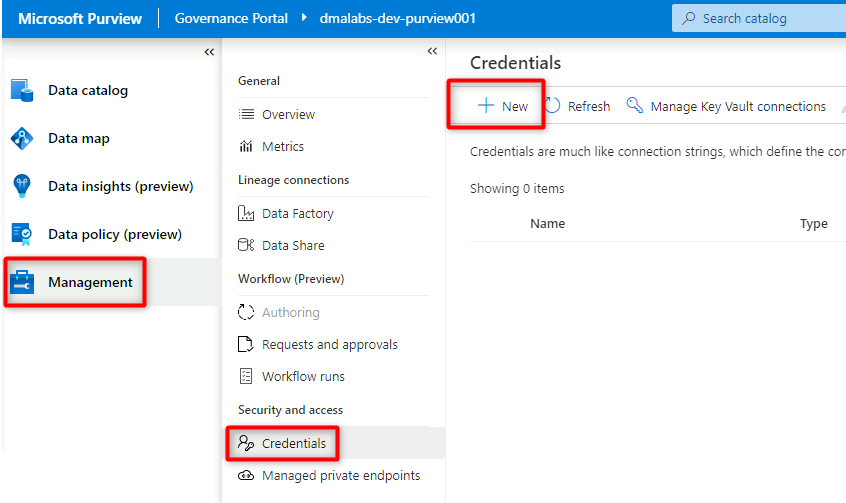
Em Nova credencial, selecione ou insira as seguintes informações:
Definição Ação Name Digite purviewServicePrincipal. Método de autenticação Selecione Entidade de serviço. ID do Inquilino O valor é preenchido automaticamente. ID da entidade de serviço Insira o ID do aplicativo ou o ID do cliente da entidade de serviço. Conexão do Cofre da Chave Selecione a conexão do cofre de chaves que você criou na seção anterior. Nome secreto Digite o nome do segredo no cofre de chaves (service-principal-secret). 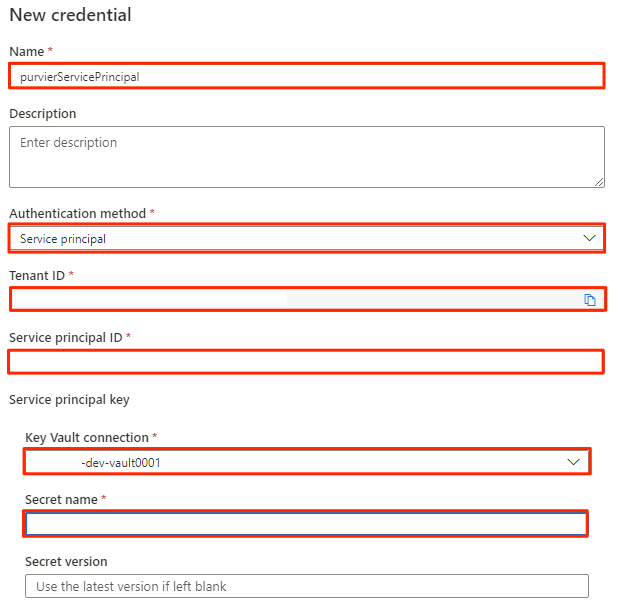
Selecione Criar.
Registar origens de dados
Neste ponto, o Purview pode se conectar à entidade de serviço. Agora você pode registrar e configurar as fontes de dados.
Registrar contas do Azure Data Lake Storage Gen2
As etapas a seguir descrevem o processo para registrar uma conta de armazenamento do Azure Data Lake Storage Gen2.
No Purview Studio, selecione o ícone do mapa de dados, selecione Fontes e, em seguida, selecione Registrar.

Em Registrar fontes, selecione Azure Data Lake Storage Gen2 e selecione Continuar.

Em Registrar fontes (Azure Data Lake Storage Gen2), selecione ou insira as seguintes informações:
Definição Ação Name Digite <DLZ-prefix>dldevraw. Subscrição do Azure Selecione a assinatura que hospeda a conta de armazenamento. Nome da conta de armazenamento Selecione a conta de armazenamento relevante. Ponto final O valor é preenchido automaticamente com base na conta de armazenamento selecionada. Selecione uma coleção Selecione a coleção raiz. 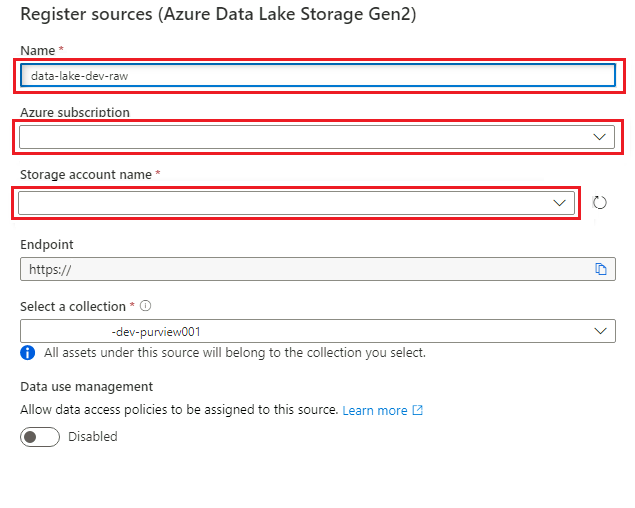
Selecione Registrar para criar a fonte de dados.
Repita estas etapas para as seguintes contas de armazenamento:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Registrar a instância do Banco de dados SQL como uma fonte de dados
No Purview Studio, selecione o ícone Mapa de dados, selecione Fontes e, em seguida, selecione Registrar.
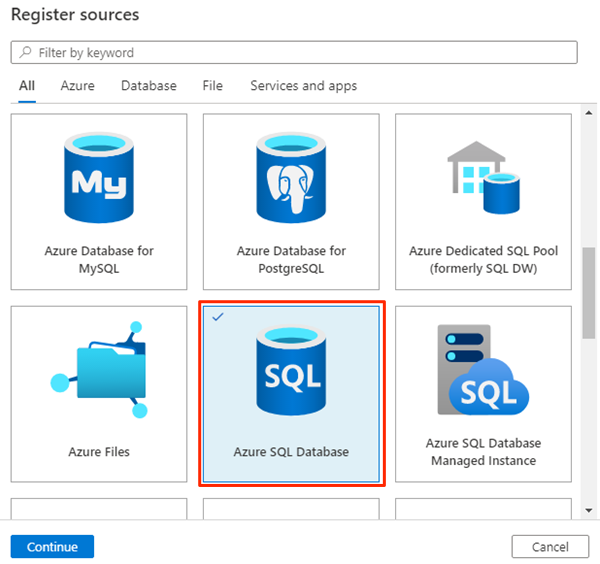
Em Registrar fontes, selecione Banco de Dados SQL do Azure e selecione Continuar.
Em Registrar fontes (Banco de Dados SQL do Azure), selecione ou insira as seguintes informações:
Definição Ação Name Insira SQLDatabase (o nome do banco de dados criado em Criar instâncias do Banco de Dados SQL do Azure). Subscrição Selecione a assinatura que hospeda o banco de dados. Nome do servidor Digite <DP-prefix-dev-sqlserver001>. 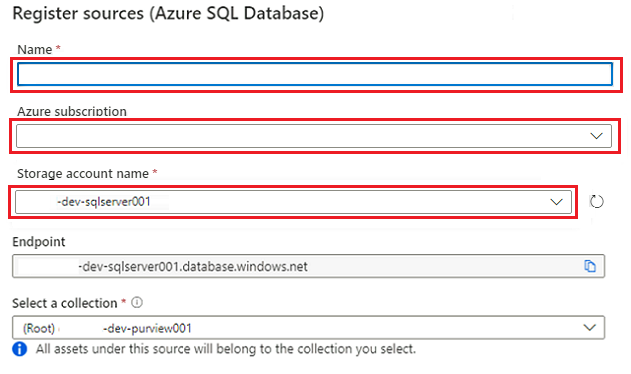
Selecione Registar.
Configurar verificações
Em seguida, configure verificações para as fontes de dados.
Verificar a fonte de dados do Data Lake Storage Gen2
No Purview Studio, vá para o mapa de dados. Na fonte de dados, selecione o ícone Nova verificação .
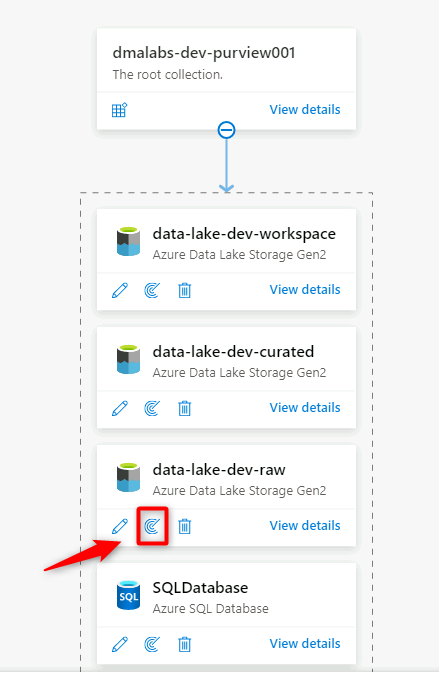
No novo painel de verificação, selecione ou insira as seguintes informações:
Definição Ação Name Digite Scan_<DLZ-prefix>devraw. Conecte-se via tempo de execução de integração Selecione o tempo de execução de integração auto-hospedado que foi implantado com a zona de aterrissagem de dados. Credencial Selecione a entidade de serviço que você configurou para o Purview. 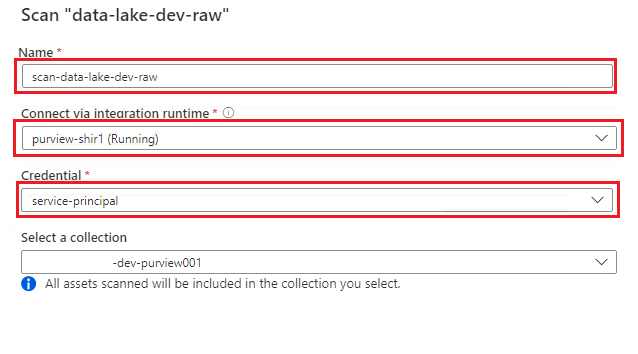
Selecione Testar conexão para verificar a conectividade e se as permissões estão em vigor. Selecione Continuar.
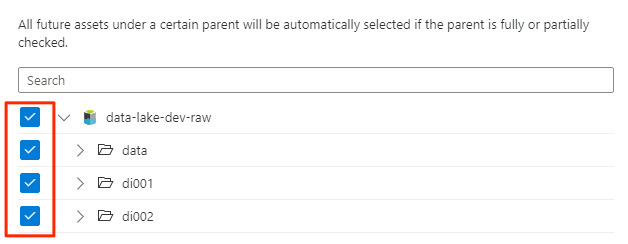
Em Escopo da verificação, selecione toda a conta de armazenamento como o escopo da verificação e, em seguida, selecione Continuar.
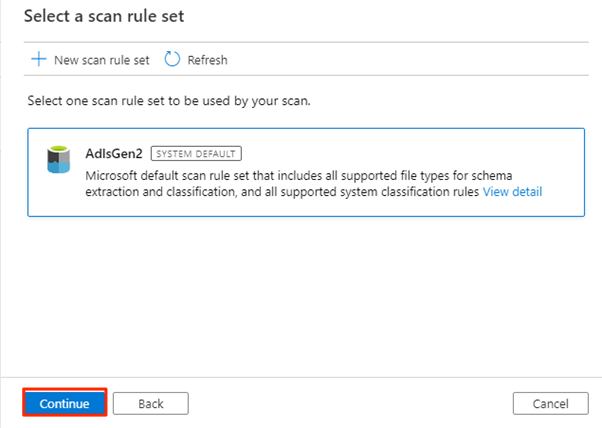
Em Selecione um conjunto de regras de verificação, selecione AdlsGen2 e, em seguida, selecione Continuar.
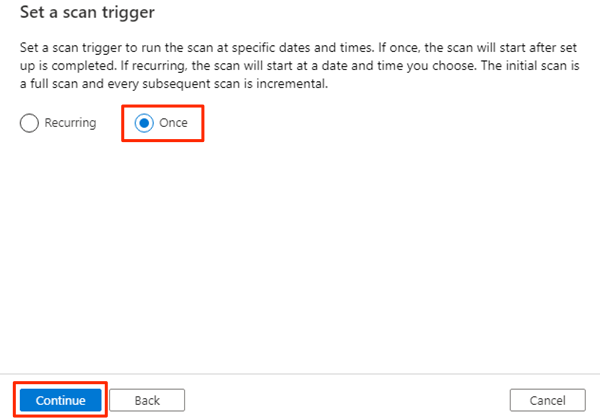
Em Definir um gatilho de verificação, selecione Uma vez e, em seguida, selecione Continuar.
Em Rever a análise, reveja as definições da análise. Selecione Salvar e Executar para iniciar a verificação.
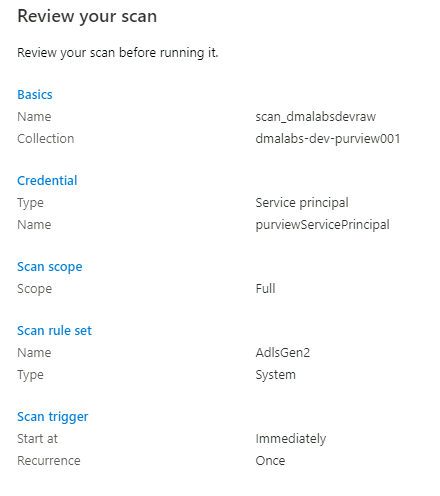
Repita estas etapas para as seguintes contas de armazenamento:
<DMLZ-prefix>devencur<DMLZ-prefix>devwork
Verificar a fonte de dados do Banco de dados SQL
Na fonte de dados do Banco de Dados SQL do Azure, selecione Nova verificação.
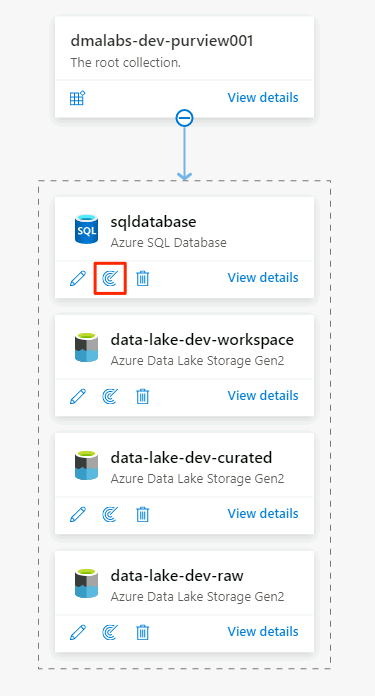
No novo painel de verificação, selecione ou insira as seguintes informações:
Definição Ação Name Digite Scan_Database001. Conecte-se via tempo de execução de integração Selecione Purview-SHIR. Nome da base de dados Selecione o nome do banco de dados. Credencial Selecione a credencial do cofre de chaves que você criou no Purview. Extração de linhagem (pré-visualização) Selecione Desativado. 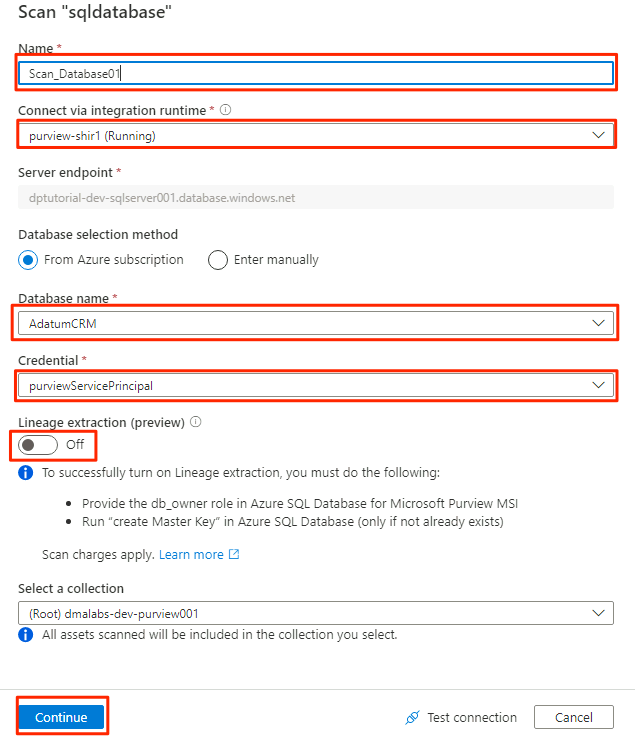
Selecione Testar conexão para verificar a conectividade e se as permissões estão em vigor. Selecione Continuar.
Selecione o escopo da verificação. Para verificar todo o banco de dados, use o valor padrão.
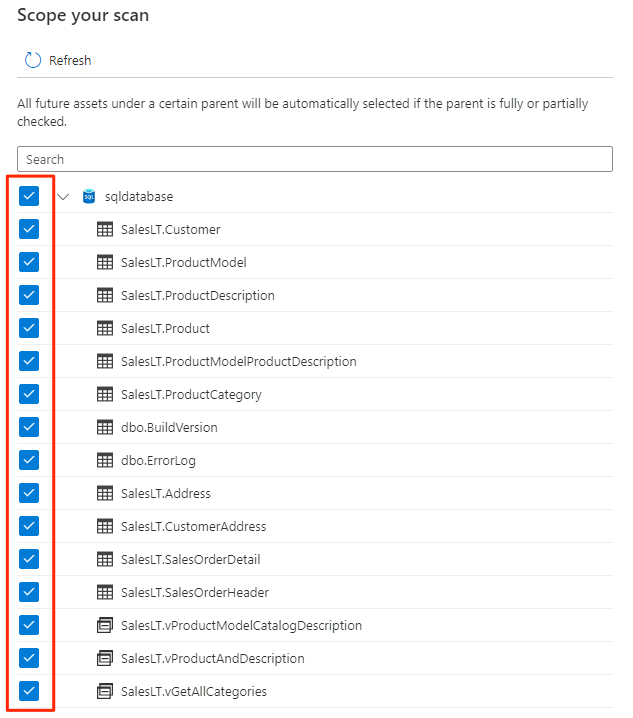
Em Selecione um conjunto de regras de verificação, selecione AzureSqlDatabase e, em seguida, selecione Continuar.

Em Definir um gatilho de verificação, selecione Uma vez e, em seguida, selecione Continuar.
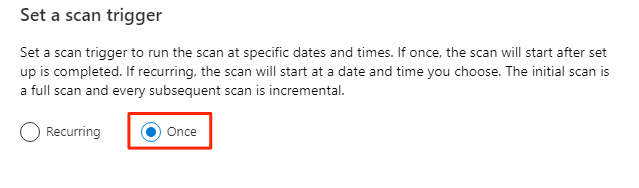
Em Rever a análise, reveja as definições da análise. Selecione Salvar e Executar para iniciar a verificação.
Repita estas etapas para o AdatumERP banco de dados.
A Purview agora está configurada para a governança de dados para as fontes de dados registradas.
Copiar dados do Banco de dados SQL para o Data Lake Storage Gen2
Nas etapas a seguir, use a ferramenta Copiar Dados no Data Factory para criar um pipeline para copiar as tabelas das instâncias AdatumCRM do Banco de dados SQL e AdatumERP para arquivos CSV na <DLZ-prefix>devraw conta do Data Lake Storage Gen2.
O ambiente está bloqueado para acesso público, portanto, primeiro, você precisa configurar pontos de extremidade privados. Para usar os pontos de extremidade privados, você entrará no portal do Azure em seu navegador local e se conectará à máquina virtual do host Bastion para acessar os serviços necessários do Azure.
Criar pontos finais privados
Para configurar pontos de extremidade privados para os recursos necessários:
No grupo de
<DMLZ-prefix>-dev-bastionrecursos, selecione<DMLZ-prefix>-dev-vm001.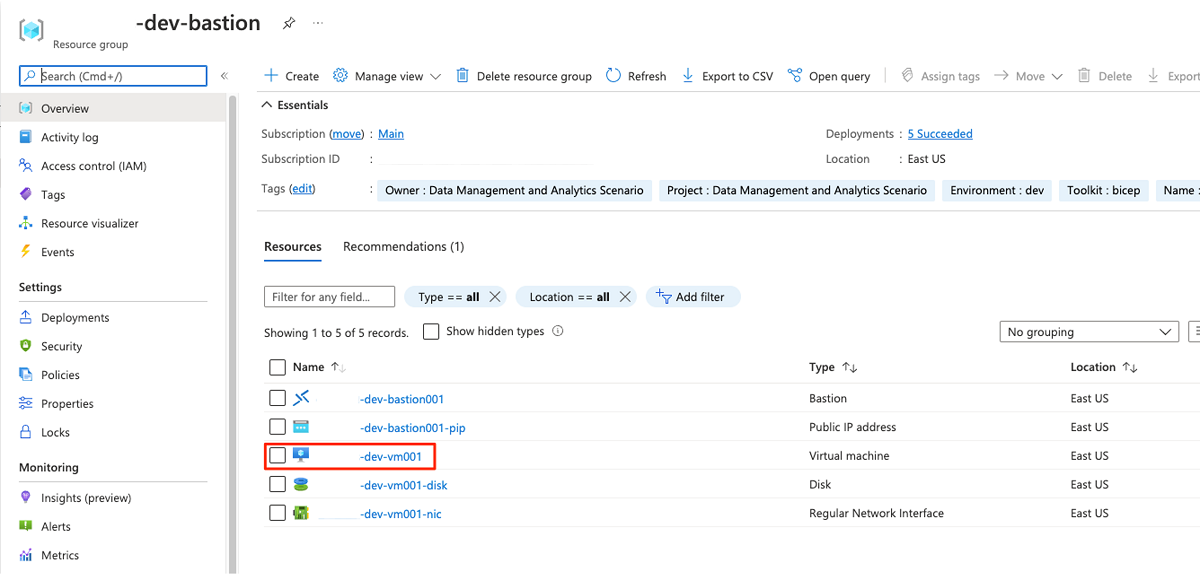
Na barra de comandos, selecione Conectar e selecione Bastion.
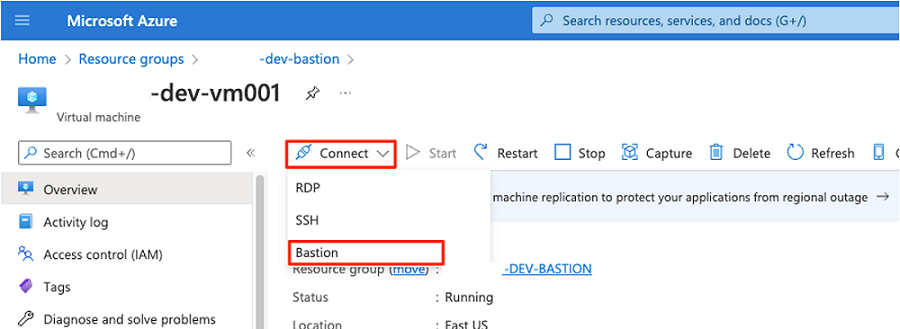
Introduza o nome de utilizador e a palavra-passe da máquina virtual e, em seguida, selecione Ligar.

No navegador da Web da máquina virtual, vá para o portal do Azure. Vá para o grupo de recursos e abra o
<DLZ-prefix>-dev-shared-integration<DLZ-prefix>-dev-integration-datafactory001data factory.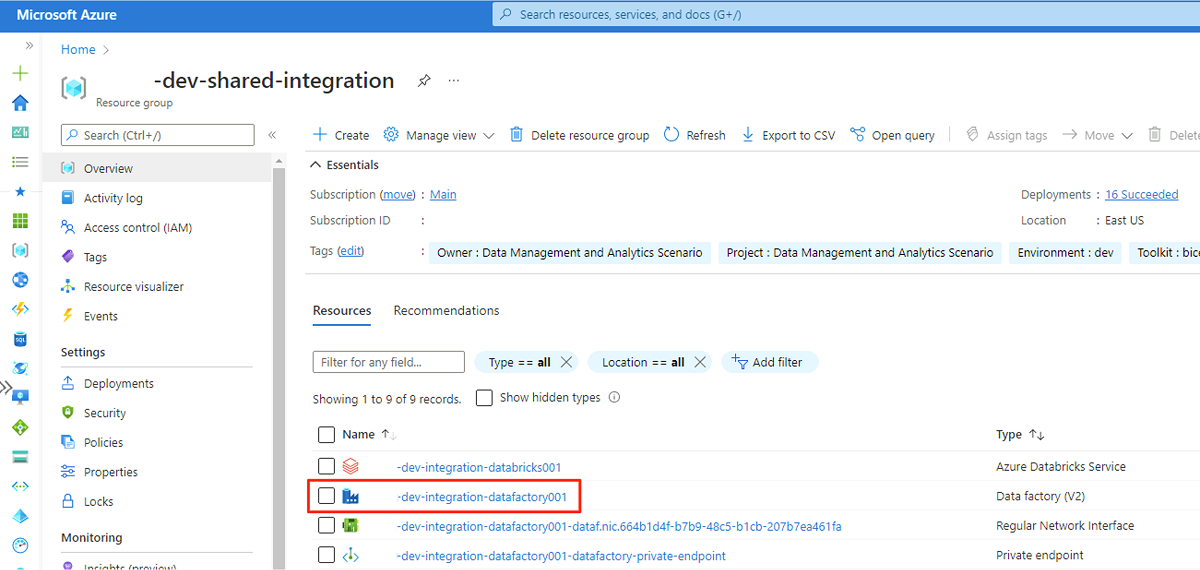
Em Introdução, no Open Azure Data Factory Studio, selecione Abrir.
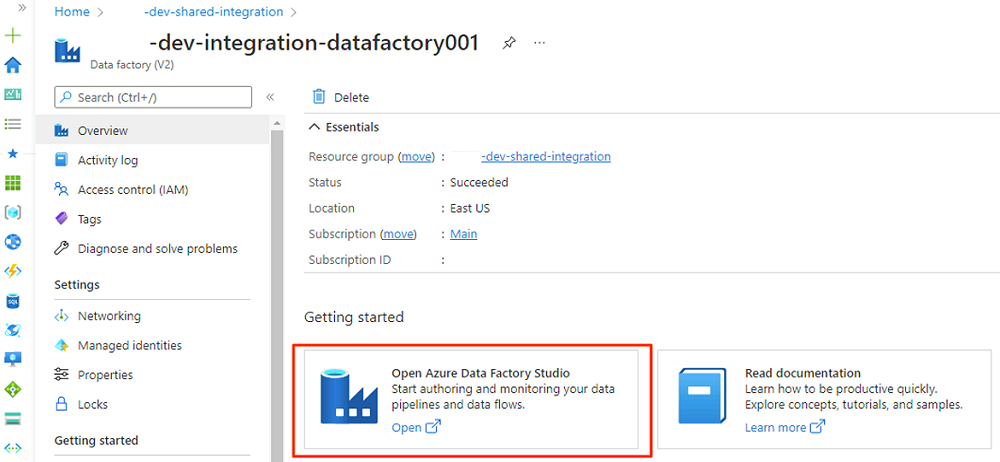
No menu Data Factory Studio, selecione o ícone Gerenciar (o ícone parece uma caixa de ferramentas quadrada com uma chave inglesa estampada nele). No menu de recursos, selecione Pontos de extremidade privados gerenciados para criar os pontos de extremidade privados necessários para conectar o Data Factory a outros serviços seguros do Azure.
A aprovação de solicitações de acesso para os pontos de extremidade privados é discutida em uma seção posterior. Depois de aprovar as solicitações de acesso ao ponto de extremidade privado, seu status de aprovação é Aprovado, como no exemplo a seguir da conta de
<DLZ-prefix>devencurarmazenamento.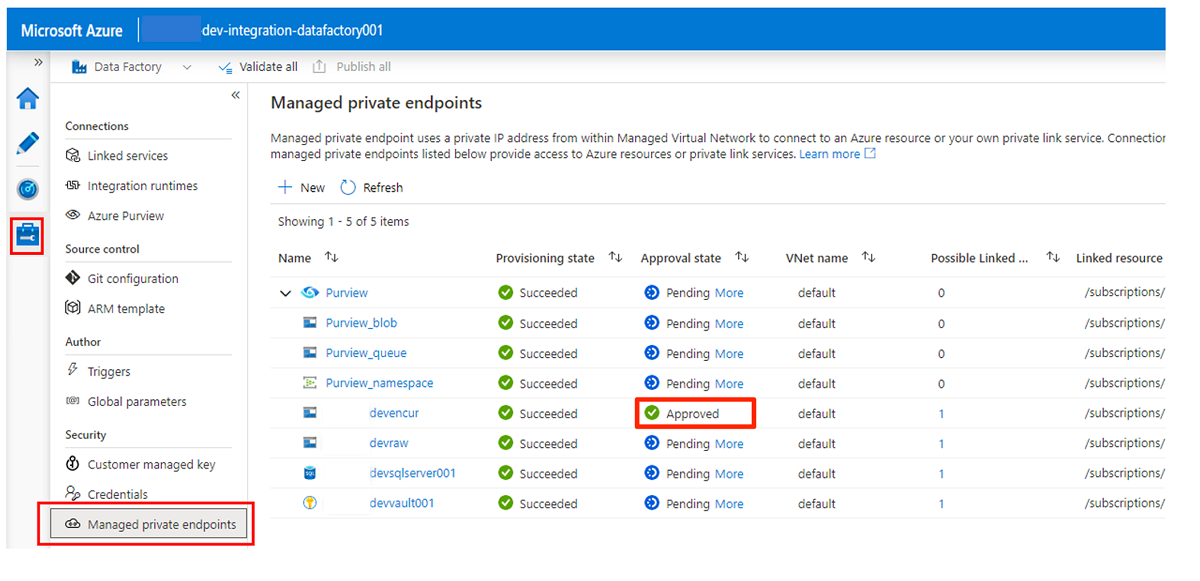
Antes de aprovar as conexões de ponto de extremidade privado, selecione Novo. Insira o SQL do Azure para localizar o conector do Banco de Dados SQL do Azure que você usa para criar um novo ponto de extremidade privado gerenciado para a máquina virtual SQL do
<DP-prefix>-dev-sqlserver001Azure. A máquina virtual contém os bancos de dados eAdatumERPcriadosAdatumCRManteriormente.Em Novo ponto de extremidade privado gerenciado (Banco de Dados SQL do Azure), para Nome, insira data-product-dev-sqlserver001. Insira a assinatura do Azure que você usou para criar os recursos. Em Nome do servidor, selecione
<DP-prefix>-dev-sqlserver001para que você possa se conectar a ele a partir desta fábrica de dados nas próximas seções.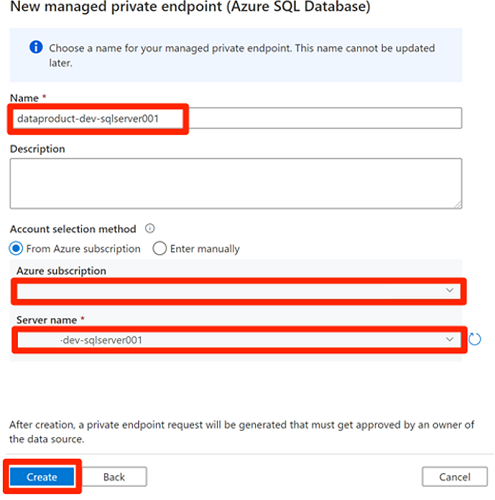



Aprovar solicitações de acesso a pontos finais privados
Para dar ao Data Factory acesso aos pontos de extremidade privados para os serviços necessários, você tem algumas opções:
Opção 1: Em cada serviço ao qual você solicita acesso, no portal do Azure, vá para a opção de conexões de ponto de extremidade privado ou de rede do serviço e aprove as solicitações de acesso ao ponto de extremidade privado.
Opção 2: Execute os seguintes scripts no Azure Cloud Shell no modo Bash para aprovar todas as solicitações de acesso aos pontos de extremidade privados necessários de uma só vez.
# Storage managed private endpoint approval # devencur resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devencur')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # devraw resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-storage')==\`true\`].name") storageAcctName=$(az storage account list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'devraw')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $storageAcctName --type Microsoft.Storage/storageAccounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $storageAcctName --type Microsoft.Storage/storageAccounts --description "Approved" # SQL Database managed private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-dp001')==\`true\`].name") sqlServerName=$(az sql server list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'sqlserver001')==\`true\`].name") endPointConnectionName=$(az network private-endpoint-connection list -g $resourceGroupName -n $sqlServerName --type Microsoft.Sql/servers -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") az network private-endpoint-connection approve -g $resourceGroupName -n $endPointConnectionName --resource-name $sqlServerName --type Microsoft.Sql/servers --description "Approved" # Key Vault private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, '-dev-metadata')==\`true\`].name") keyVaultName=$(az keyvault list -g $resourceGroupName -o tsv --query "[?contains(@.name, 'dev-vault001')==\`true\`].name") endPointConnectionID=$(az network private-endpoint-connection list -g $resourceGroupName -n $keyVaultName --type Microsoft.Keyvault/vaults -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].id") az network private-endpoint-connection approve -g $resourceGroupName --id $endPointConnectionID --resource-name $keyVaultName --type Microsoft.Keyvault/vaults --description "Approved" # Purview private endpoint approval resourceGroupName=$(az group list -o tsv --query "[?contains(@.name, 'dev-governance')==\`true\`].name") purviewAcctName=$(az purview account list -g $resourceGroupName -o tsv --query "[?contains(@.name, '-dev-purview001')==\`true\`].name") for epn in $(az network private-endpoint-connection list -g $resourceGroupName -n $purviewAcctName --type Microsoft.Purview/accounts -o tsv --query "[?contains(@.properties.privateLinkServiceConnectionState.status, 'Pending')==\`true\`].name") do az network private-endpoint-connection approve -g $resourceGroupName -n $epn --resource-name $purviewAcctName --type Microsoft.Purview/accounts --description "Approved" done
O exemplo a seguir mostra como a <DLZ-prefix>devraw conta de armazenamento gerencia solicitações privadas de acesso ao ponto final. No menu de recursos da conta de armazenamento, selecione Rede. Na barra de comandos, selecione Conexões de ponto de extremidade privadas.

Para alguns recursos do Azure, selecione Conexões de ponto de extremidade privadas no menu de recursos. Um exemplo para o servidor SQL do Azure é mostrado na captura de tela a seguir.
Para aprovar uma solicitação de acesso de ponto de extremidade privado, em Conexões de ponto de extremidade privado, selecione a solicitação de acesso pendente e, em seguida, selecione Aprovar:

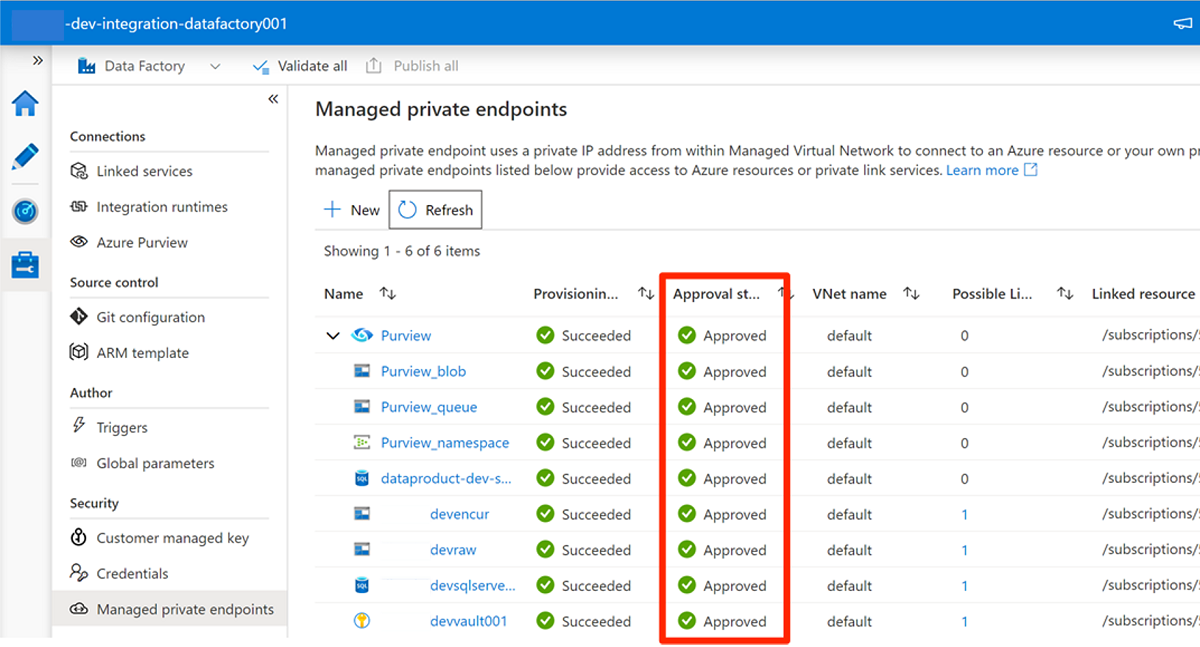
Depois de aprovar a solicitação de acesso em cada serviço necessário, pode levar alguns minutos para que a solicitação seja exibida como Aprovado em Pontos de extremidade privados gerenciados no Data Factory Studio. Mesmo se você selecionar Atualizar na barra de comandos, o estado de aprovação pode ficar obsoleto por alguns minutos.
Quando terminar de aprovar todas as solicitações de acesso para os serviços necessários, em Pontos de extremidade privados gerenciados, o valor do estado de Aprovação para todos os serviços será Aprovado:
Atribuições de funções
Quando terminar de aprovar as solicitações de acesso ao ponto de extremidade privado, adicione as permissões de função apropriadas para o Data Factory acessar estes recursos:
- Instâncias
AdatumCRMdo Banco de Dados SQL eAdatumERPno servidor SQL do<DP-prefix>-dev-sqlserver001Azure - Contas
<DLZ-prefix>devrawde armazenamento ,<DLZ-prefix>devencure<DLZ-prefix>devwork - Conta Purview
<DMLZ-prefix>-dev-purview001
Máquina virtual SQL do Azure
Para adicionar atribuições de função, comece com a máquina virtual SQL do Azure. No grupo de
<DMLZ-prefix>-dev-dp001recursos, vá para<DP-prefix>-dev-sqlserver001.No menu de recursos, selecione Controle de acesso (IAM). Na barra de comandos, selecione Adicionar>atribuição de função.
No separador Função, selecione Colaborador e, em seguida, selecione Seguinte.
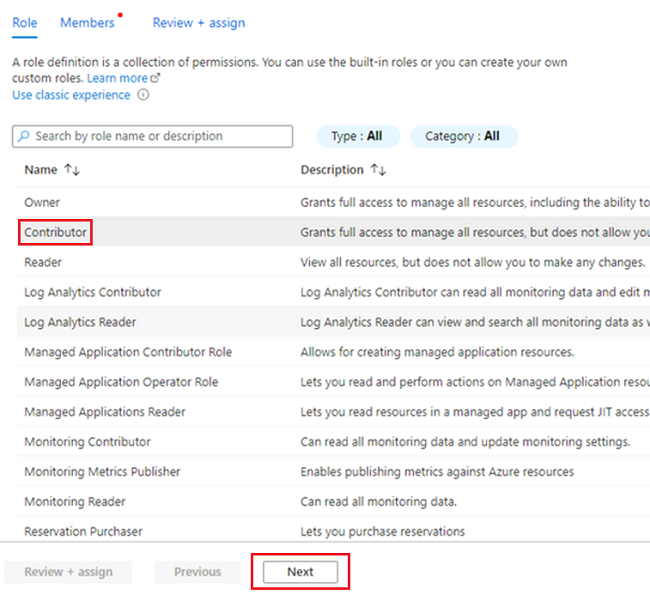
Em Membros, para Atribuir acesso a, selecione Identidade gerenciada. Para Membros, escolha Selecionar Membros.
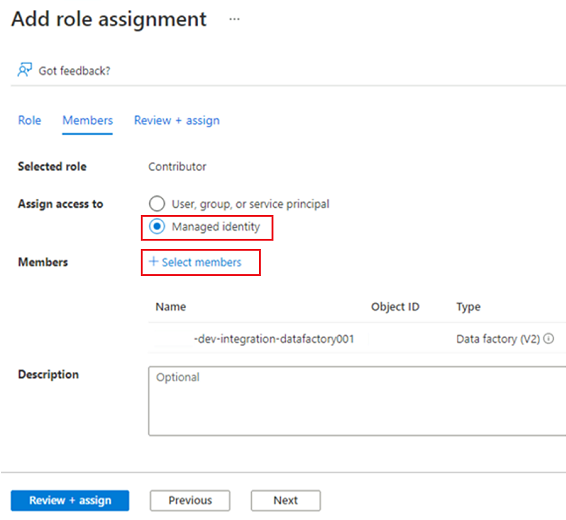
Em Selecionar identidades gerenciadas, selecione sua assinatura do Azure. Em Identidade gerenciada, selecione Data Factory (V2) para ver as fábricas de dados disponíveis. Na lista de fábricas de dados, selecione Azure Data Factory <DLZ-prefix-dev-integration-datafactory001>. Escolha Selecionar.
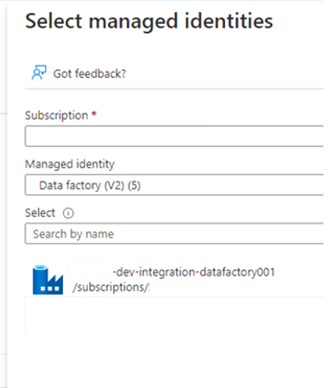
Selecione Rever + Atribuir duas vezes para concluir o processo.
Contas de armazenamento
Em seguida, atribua as funções necessárias às <DLZ-prefix>devrawcontas , <DLZ-prefix>devencure <DLZ-prefix>devwork de armazenamento.
Para atribuir as funções, conclua as mesmas etapas que você usou para criar a atribuição de função de servidor SQL do Azure. Mas, para a função, selecione Colaborador de Dados de Blob de Armazenamento em vez de Colaborador.
Depois de atribuir funções para as três contas de armazenamento, o Data Factory pode se conectar e acessar as contas de armazenamento.
Microsoft Purview
A etapa final para adicionar atribuições de função é adicionar a função Purview Data Curator no Microsoft Purview à conta de identidade gerenciada do <DLZ-prefix>-dev-integration-datafactory001 data factory. Conclua as etapas a seguir para que o Data Factory possa enviar informações de ativos do catálogo de dados de várias fontes de dados para a conta Purview.
No grupo
<DMLZ-prefix>-dev-governancede recursos , vá para a<DMLZ-prefix>-dev-purview001conta Purview.No Purview Studio, selecione o ícone Mapa de dados e, em seguida, selecione Coleções.
Selecione a guia Atribuições de função para a coleção. Em Curadores de dados, adicione a identidade gerenciada para
<DLZ-prefix>-dev-integration-datafactory001:
Conecte o Data Factory ao Purview
As permissões estão definidas, e o Purview agora pode ver o data factory. O próximo passo é ter <DMLZ-prefix>-dev-purview001 conexão com o <DLZ-prefix>-dev-integration-datafactory001.
No Purview Studio, selecione o ícone Gerenciamento e, em seguida, selecione Data Factory. Selecione Novo para criar uma conexão do Data Factory.
No painel Novas conexões do Data Factory, insira sua assinatura do Azure e selecione o
<DLZ-prefix>-dev-integration-datafactory001data factory. Selecione OK.
Na instância do Data Factory Studio, em Manage>Azure Purview, atualize a conta do
<DLZ-prefix>-dev-integration-datafactory001Azure Purview.A
Data Lineage - Pipelineintegração agora mostra o ícone verde Conectado .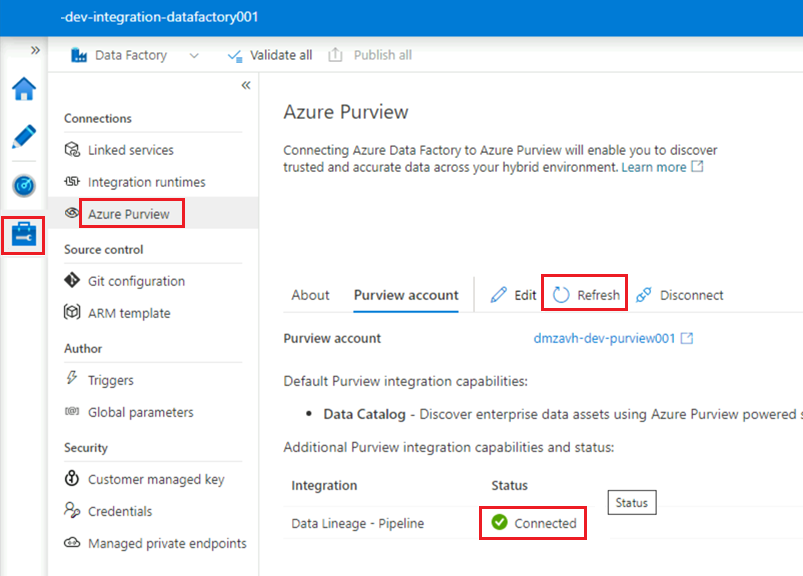

Criar um pipeline ETL
Agora que o <DLZ-prefix>-dev-integration-datafactory001 tem as permissões de acesso necessárias, crie uma atividade de cópia no Data Factory para mover dados de instâncias do Banco de dados SQL para a <DLZ-prefix>devraw conta de armazenamento bruto.
Use a ferramenta Copiar dados com o AdatumCRM
Esse processo extrai dados do cliente da instância do Banco de dados SQL e os copia para o AdatumCRM armazenamento do Data Lake Storage Gen2.
No Data Factory Studio, selecione o ícone Autor e, em seguida, selecione Recursos de Fábrica. Selecione o sinal de adição (+) e selecione a ferramenta Copiar dados.
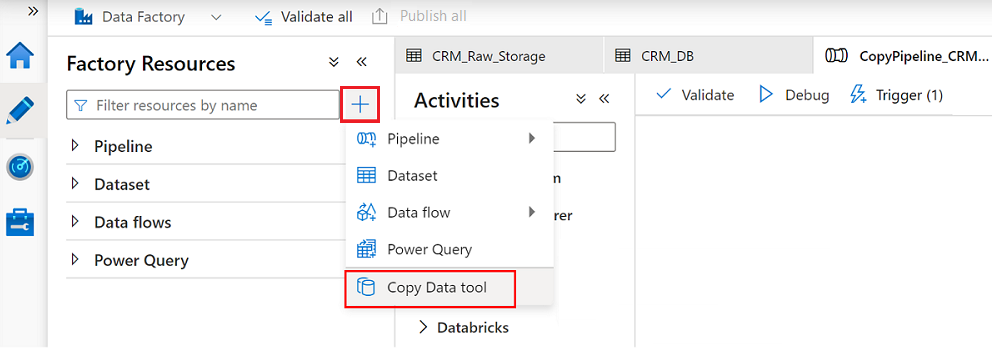
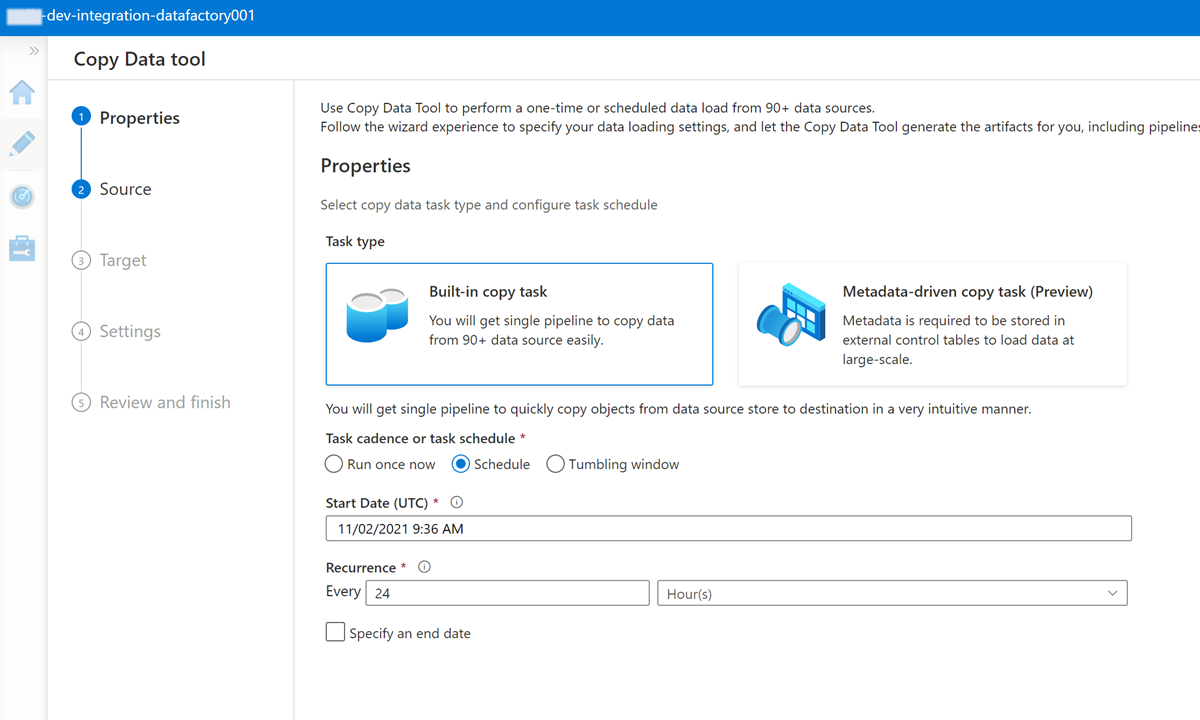
Conclua cada etapa no assistente da ferramenta Copiar dados:
Para criar um gatilho para executar o pipeline a cada 24 horas, selecione Agendar.
Para criar um serviço vinculado para conectar essa fábrica de dados à instância do
AdatumCRMBanco de dados SQL no<DP-prefix>-dev-sqlserver001servidor (origem), selecione Nova Conexão.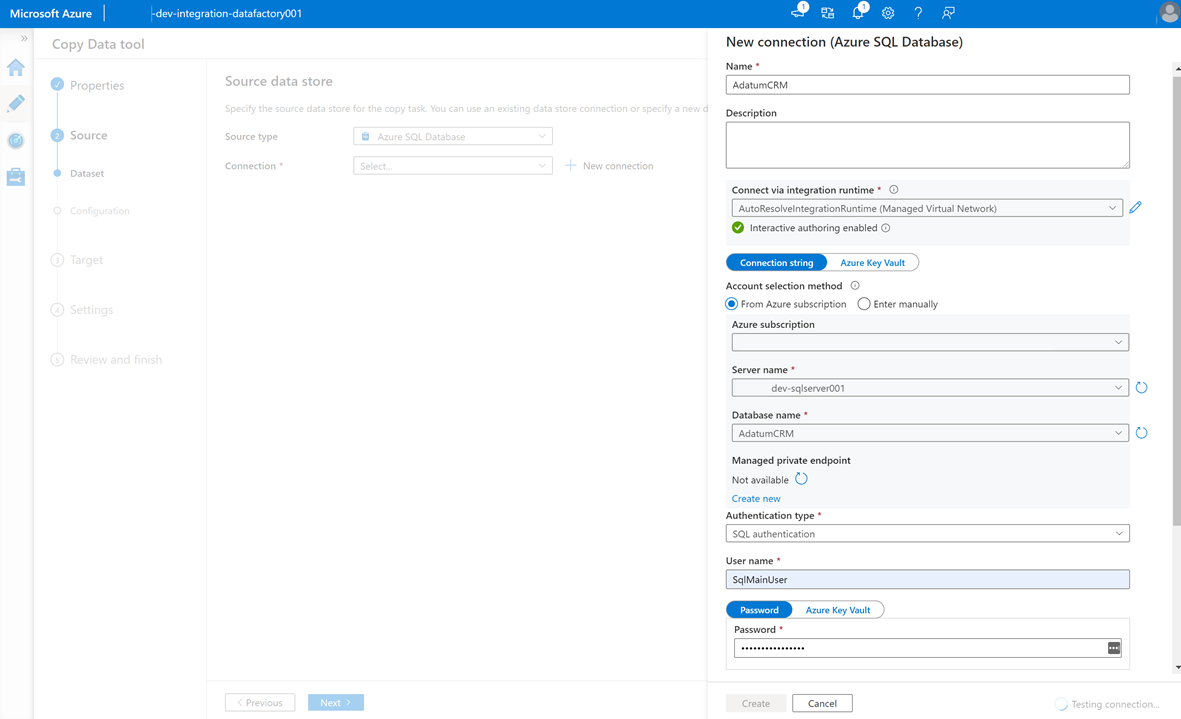
Nota
Se você tiver erros ao se conectar ou acessar os dados nas instâncias do Banco de Dados SQL ou nas contas de armazenamento, revise suas permissões na assinatura do Azure. Certifique-se de que a fábrica de dados tem as credenciais necessárias e permissões de acesso a qualquer recurso problemático.
Selecione estas três tabelas:
SalesLT.AddressSalesLT.CustomerSalesLT.CustomerAddress
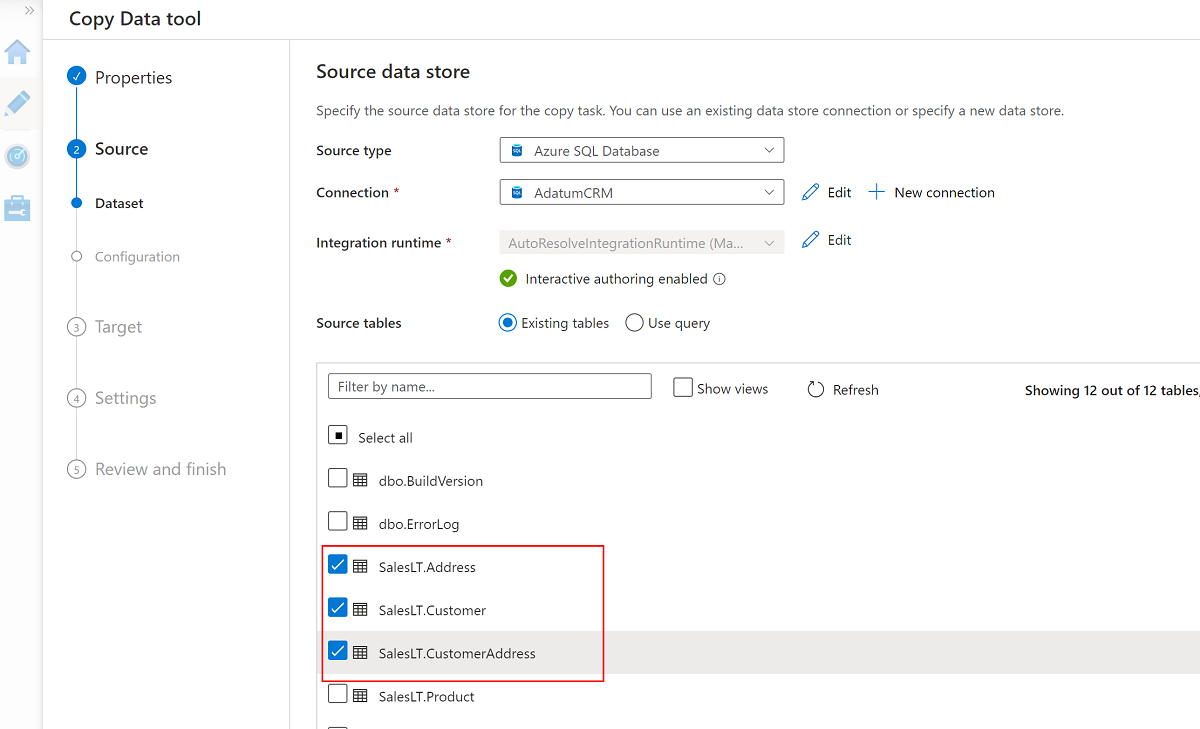
Crie um novo serviço vinculado para acessar o
<DLZ-prefix>devrawarmazenamento do Azure Data Lake Storage Gen2 (destino).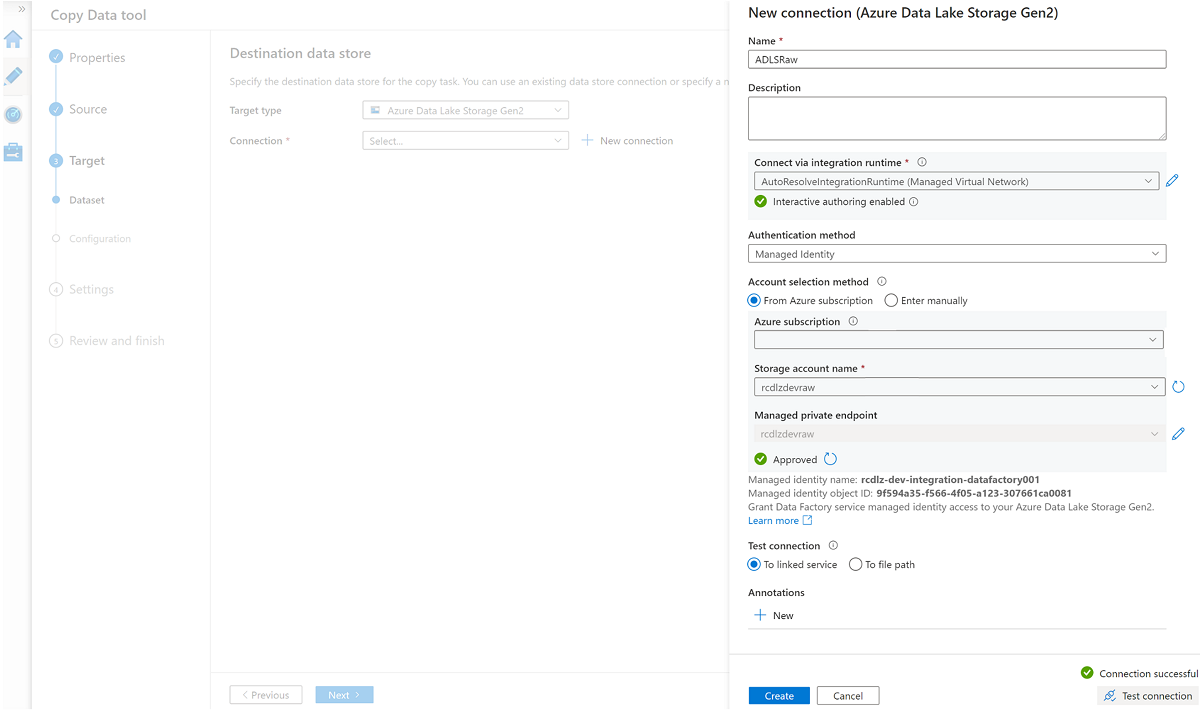
Navegue pelas pastas no
<DLZ-prefix>devrawarmazenamento e selecione Dados como destino.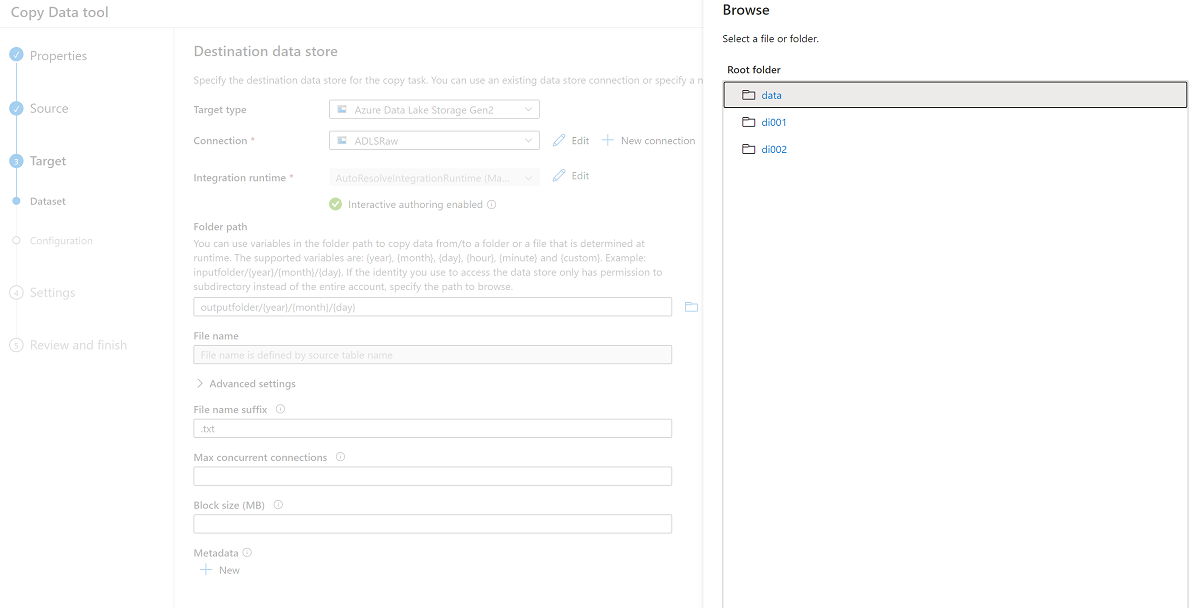
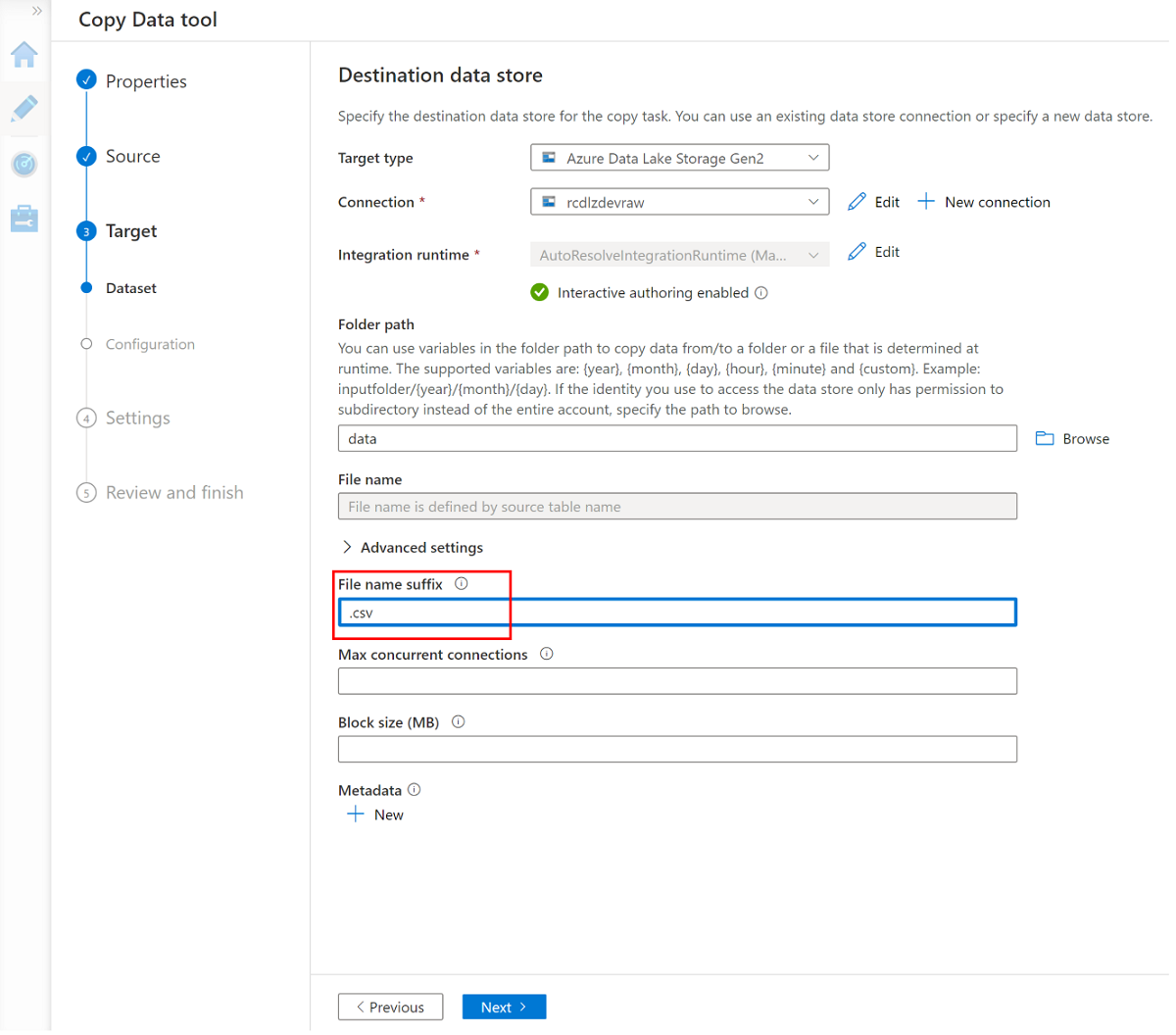
Altere o sufixo de nome de arquivo para .csv e use as outras opções padrão.
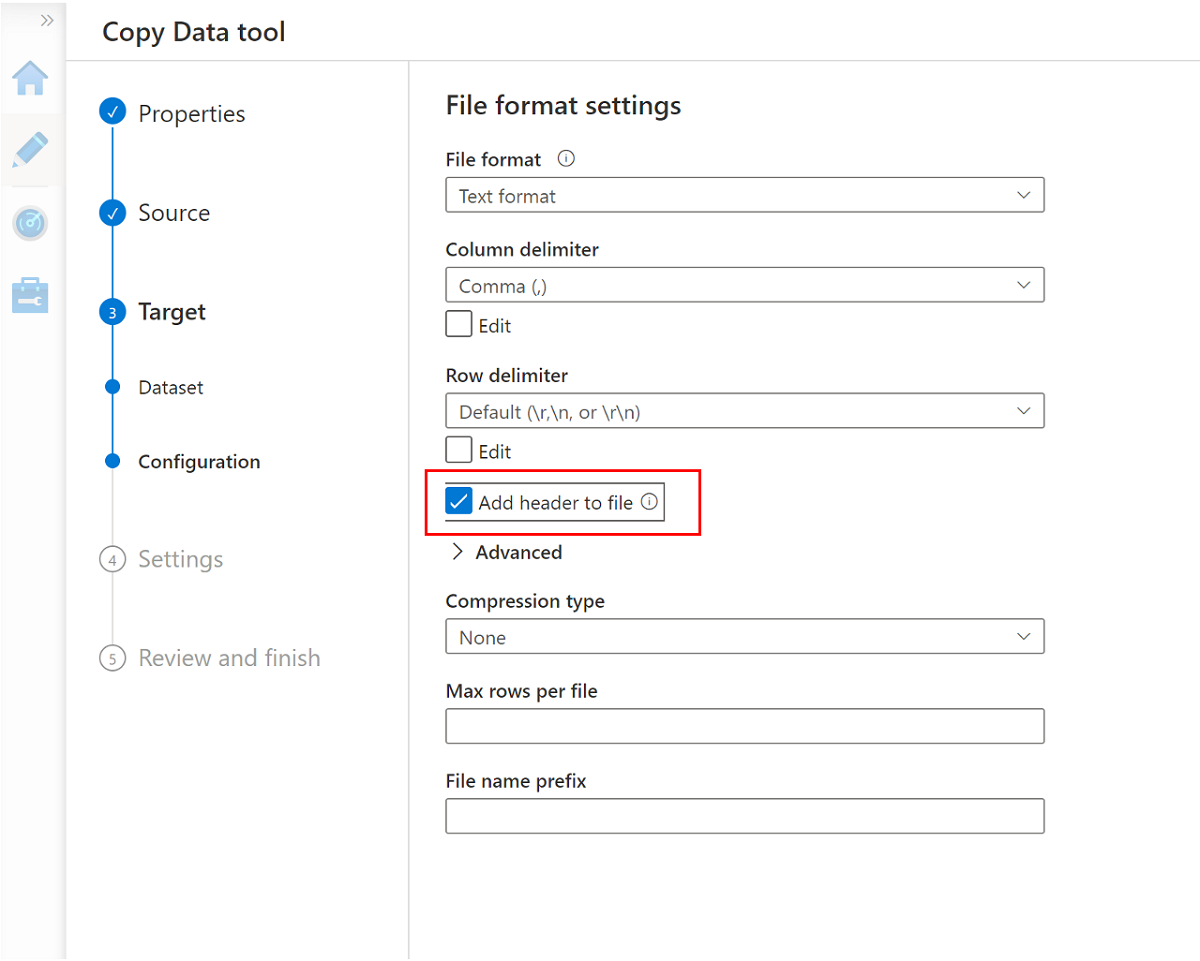
Vá para o próximo painel e selecione Adicionar cabeçalho ao arquivo.
Quando você concluir o assistente, o painel Implantação concluída será semelhante a este exemplo:
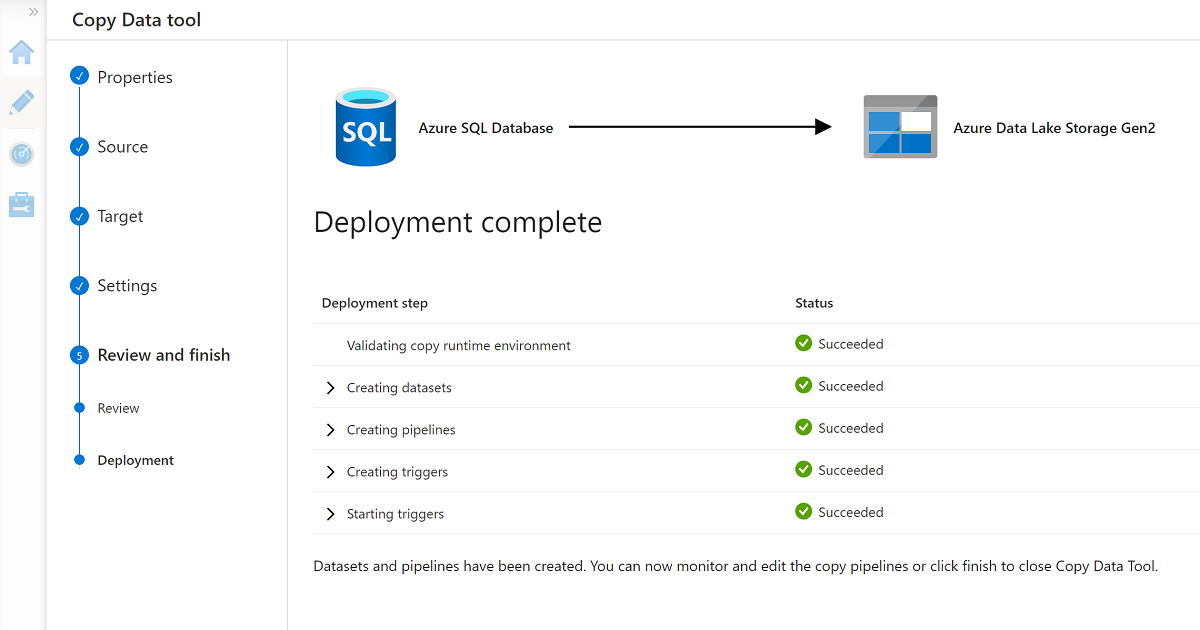




O novo pipeline está listado em Pipelines.
Executar o pipeline
Esse processo cria três arquivos .csv na pasta Data\CRM , um para cada uma das tabelas selecionadas no AdatumCRM banco de dados.
Renomeie o pipeline
CopyPipeline_CRM_to_Raw.Renomeie os conjuntos de
CRM_Raw_Storagedados eCRM_DB.Na barra de comandos Recursos de fábrica, selecione Publicar tudo.
Selecione o
CopyPipeline_CRM_to_Rawpipeline e, na barra de comandos do pipeline, selecione Trigger para copiar as três tabelas do Banco de dados SQL para o Data Lake Storage Gen2.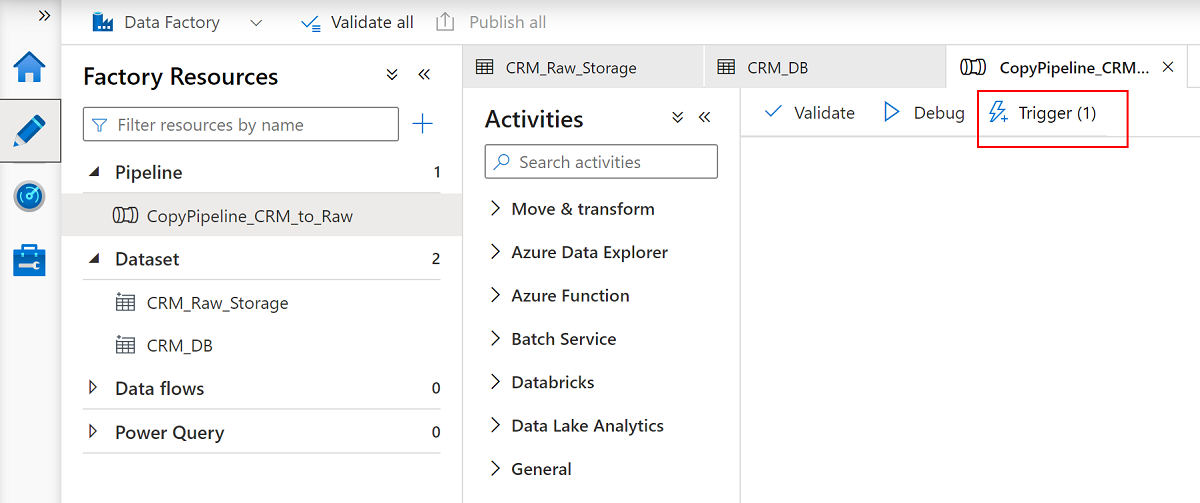
Use a ferramenta Copiar dados com o AdatumERP
Em seguida, extraia os dados do AdatumERP banco de dados. Os dados representam os dados de vendas provenientes do sistema ERP.
Ainda no Data Factory Studio, crie um novo pipeline usando a ferramenta Copiar dados. Desta vez, você está enviando os dados de vendas para a
<DLZ-prefix>devrawpasta de dados da conta de armazenamento, da mesma forma que fez com os dados doAdatumERPCRM. Conclua as mesmas etapas, mas use oAdatumERPbanco de dados como fonte.Crie a programação para acionar a cada hora.
Crie um serviço vinculado à instância do
AdatumERPBanco de dados SQL.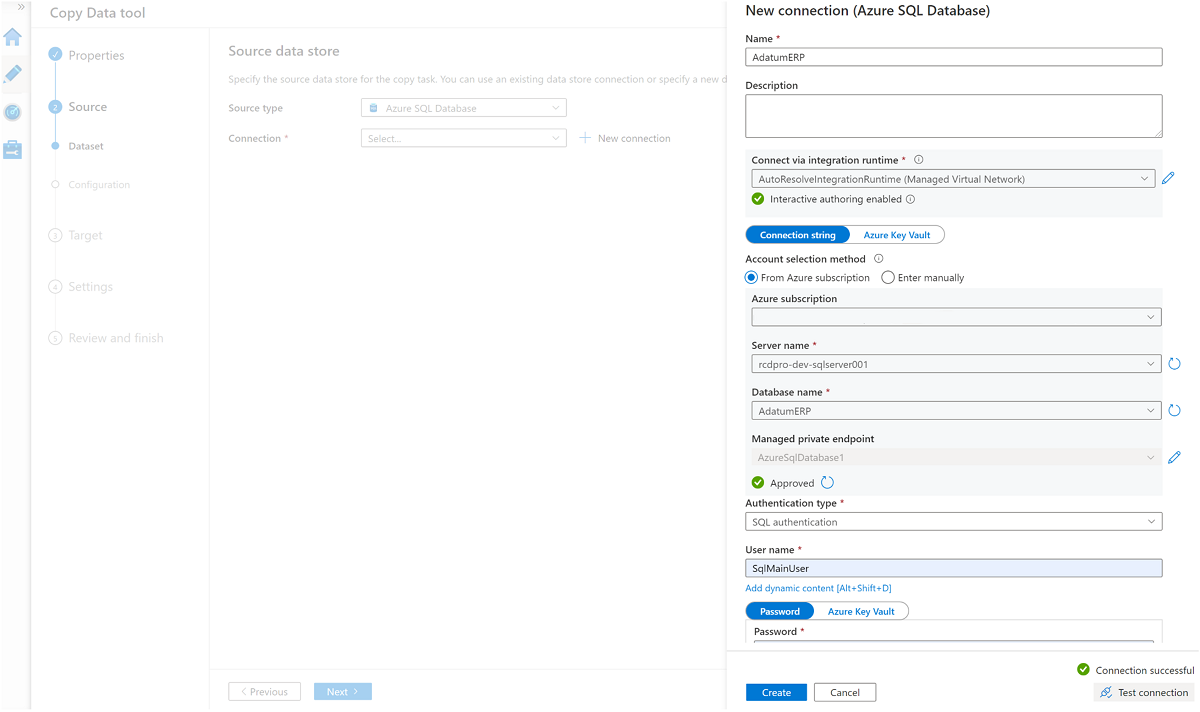
Selecione estas sete tabelas:
SalesLT.ProductSalesLT.ProductCategorySalesLT.ProductDescriptionSalesLT.ProductModelSalesLT.ProductModelProductDescriptionSalesLT.SalesOrderDetailSalesLT.SalesOrderHeader
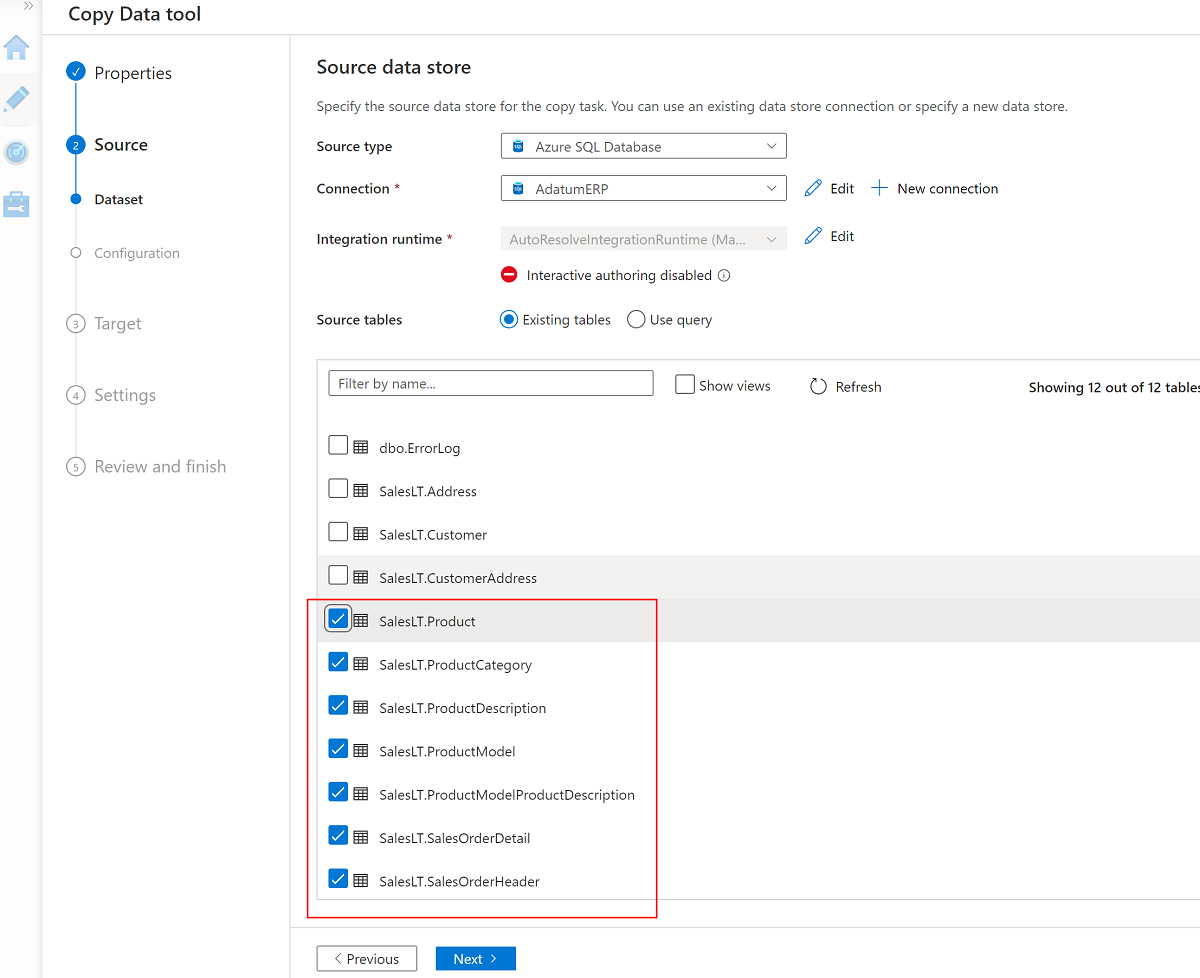
Use o serviço vinculado existente à
<DLZ-prefix>devrawconta de armazenamento e defina a extensão de arquivo como .csv.
Selecione Adicionar cabeçalho ao arquivo.
Conclua o assistente novamente e renomeie o pipeline
CopyPipeline_ERP_to_DevRaw. Em seguida, na barra de comandos, selecione Publicar tudo. Por fim, execute o gatilho nesse pipeline recém-criado para copiar as sete tabelas selecionadas do Banco de dados SQL para o Data Lake Storage Gen2.

Quando você concluir essas etapas, 10 arquivos CSV estarão no <DLZ-prefix>devraw armazenamento Data Lake Storage Gen2. Na próxima seção, você seleciona os arquivos no <DLZ-prefix>devencur armazenamento Data Lake Storage Gen2.
Segmentar dados no Data Lake Storage Gen2
Quando terminar de criar os 10 arquivos CSV no armazenamento bruto <DLZ-prefix>devraw do Data Lake Storage Gen2, transforme esses arquivos conforme necessário ao copiá-los para o armazenamento Data Lake Storage Gen2 com curadoria <DLZ-prefix>devencur .
Continue usando o Azure Data Factory para criar esses novos pipelines para orquestrar a movimentação de dados.
Segmentar o CRM para os dados do cliente
Crie um fluxo de dados que obtenha os arquivos CSV na pasta Data\CRM em <DLZ-prefix>devraw. Transforme os arquivos e copie os arquivos transformados no formato de arquivo .parquet para a pasta Data\Customer em <DLZ-prefix>devencur.
No Azure Data Factory, vá para o data factory e selecione Orquestrar.
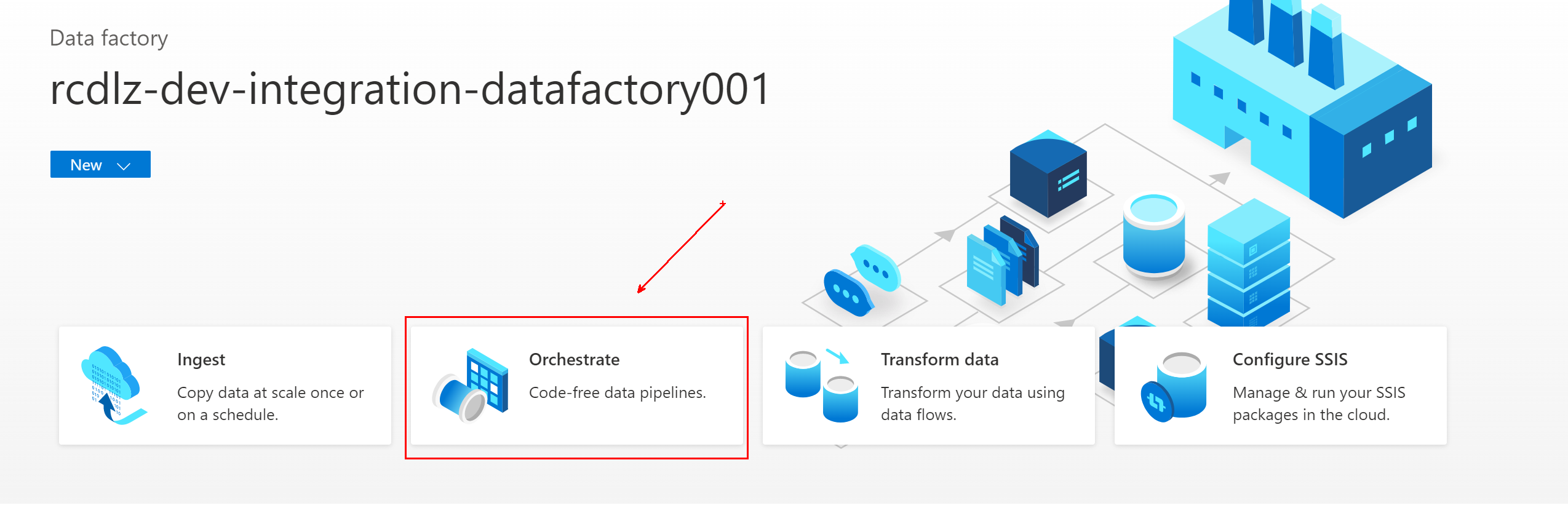
Em Geral, nomeie o pipeline
Pipeline_transform_CRM.No painel Atividades, expanda Mover e Transformar. Arraste a atividade de fluxo de dados e solte-a na tela do pipeline.
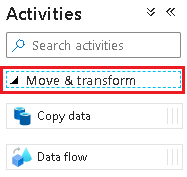
Em Adicionando fluxo de dados, selecione Criar novo fluxo de dados e nomeie o fluxo de
CRM_to_Customerdados . Selecione Concluir.Nota
Na barra de comandos da tela do pipeline, ative a depuração do fluxo de dados. No modo de depuração, você pode testar interativamente a lógica de transformação em relação a um cluster Apache Spark ao vivo. Os clusters de fluxo de dados levam de 5 a 7 minutos para aquecer. Recomendamos que você ative a depuração antes de iniciar o desenvolvimento do fluxo de dados.

Quando terminar de selecionar as opções no
CRM_to_Customerfluxo de dados, oPipeline_transform_CRMpipeline será semelhante a este exemplo: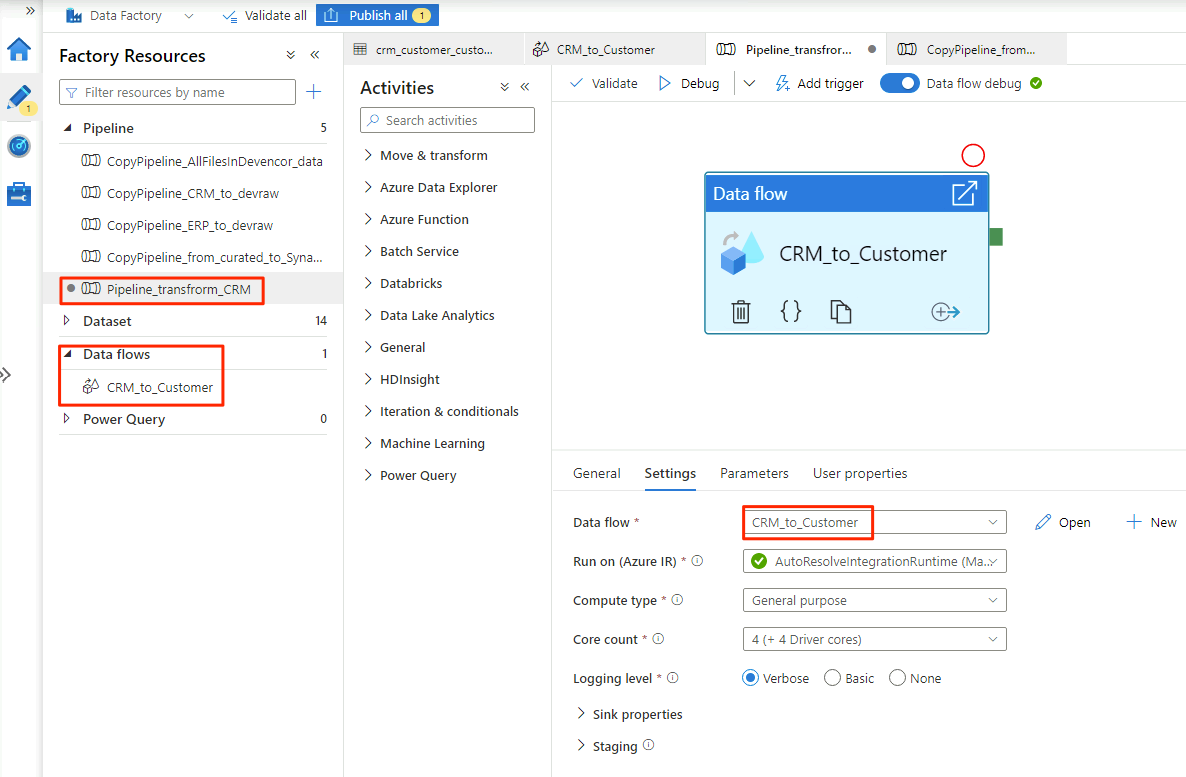
O fluxo de dados se parece com este exemplo:
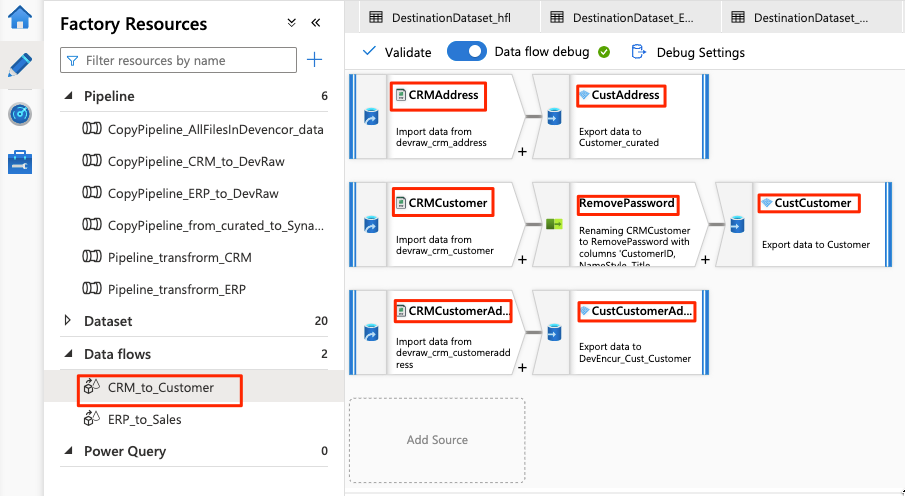
Em seguida, modifique estas configurações no fluxo de dados para a
CRMAddressfonte:Crie um novo conjunto de dados a partir do Data Lake Storage Gen2. Use o formato DelimitedText . Nomeie o conjunto de
DevRaw_CRM_Addressdados .Conecte o serviço vinculado ao
<DLZ-prefix>devraw.Selecione o
Data\CRM\SalesLTAddress.csvarquivo como a fonte.
Modifique estas configurações no fluxo de dados para o coletor emparelhado
CustAddress:Crie um novo conjunto de dados chamado
DevEncur_Cust_Address.Selecione a pasta Data\Customer como
<DLZ-prefix>devencuro coletor.Em Configurações\Saída em arquivo único, converta o arquivo em Address.parquet.
Para o restante da configuração de fluxo de dados, use as informações nas tabelas a seguir para cada componente. Note que CRMAddress e CustAddress são as duas primeiras linhas. Use-os como exemplos para os outros objetos.
Um item que não está em nenhuma das tabelas a seguir é o RemovePasswords modificador de esquema. A captura de tela anterior mostra que esse item vai entre CRMCustomer e CustCustomer. Para adicionar esse modificador de esquema, vá para Selecionar configurações e remova PasswordHash e PasswordSalt.
CRMCustomer Retorna um esquema de 15 colunas do arquivo .crv. CustCustomer Grava apenas 13 colunas depois que o modificador de esquema remove as duas colunas de senha.
A tabela completa
| Nome | Object type | Nome do conjunto de dados | Arquivo de dados | Tipo de formato | Serviço ligado | Ficheiro ou pasta |
|---|---|---|---|---|---|---|
CRMAddress |
origem | DevRaw_CRM_Address |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\CRM\SalesLTAddress.csv |
CustAddress |
lavatório | DevEncur_Cust_Address |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Cliente\Endereço.parquet |
CRMCustomer |
origem | DevRaw_CRM_Customer |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\CRM\SalesLTCustomer.csv |
CustCustomer |
lavatório | DevEncur_Cust_Customer |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Cliente\Customer.parquet |
CRMCustomerAddress |
origem | DevRaw_CRM_CustomerAddress |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\CRM\SalesLTCustomerAddress.csv |
CustCustomerAddress |
lavatório | DevEncur_Cust_CustomerAddress |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Customer\CustomerAddress.parquet |
A tabela ERP para Vendas
Agora, repita etapas semelhantes para criar um pipeline, crie um fluxo de ERP_to_Sales dados para transformar os arquivos .csv na pasta Data\ERP em e copie os arquivos transformados para a pasta Data\Sales em <DLZ-prefix>devencur<DLZ-prefix>devraw.Pipeline_transform_ERP
Na tabela a seguir, você encontrará os objetos a serem criados no ERP_to_Sales fluxo de dados e as configurações que precisa modificar para cada objeto. Cada arquivo .csv é mapeado para um coletor .parquet .
| Nome | Object type | Nome do conjunto de dados | Arquivo de dados | Tipo de formato | Serviço ligado | Ficheiro ou pasta |
|---|---|---|---|---|---|---|
ERPProduct |
origem | DevRaw_ERP_Product |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProduct.csv |
SalesProduct |
lavatório | DevEncur_Sales_Product |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\Produto.parquet |
ERPProductCategory |
origem | DevRaw_ERP_ProductCategory |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProductCategory.csv |
SalesProductCategory |
lavatório | DevEncur_Sales_ProductCategory |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\ProductCategory.parquet |
ERPProductDescription |
origem | DevRaw_ERP_ProductDescription |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProductDescription.csv |
SalesProductDescription |
lavatório | DevEncur_Sales_ProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\ProductDescription.parquet |
ERPProductModel |
origem | DevRaw_ERP_ProductModel |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProductModel.csv |
SalesProductModel |
lavatório | DevEncur_Sales_ProductModel |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\ProductModel.parquet |
ERPProductModelProductDescription |
origem | DevRaw_ERP_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProductModelProductDescription.csv |
SalesProductModelProductDescription |
lavatório | DevEncur_Sales_ProductModelProductDescription |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\ProductModelProductDescription.parquet |
ERPProductSalesOrderDetail |
origem | DevRaw_ERP_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProductSalesOrderDetail.csv |
SalesProductSalesOrderDetail |
lavatório | DevEncur_Sales_ProductSalesOrderDetail |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\ProductSalesOrderDetail.parquet |
ERPProductSalesOrderHeader |
origem | DevRaw_ERP_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | DelimitadoTexto | devraw |
Data\ERP\SalesLTProductSalesOrderHeader.csv |
SalesProductSalesOrderHeader |
lavatório | DevEncur_Sales_ProductSalesOrderHeader |
Azure Data Lake Storage Gen2 | Parquet | devencur |
Dados\Vendas\ProductSalesOrderHeader.parquet |
Próximos passos
Clean up resources (Limpar recursos)