O que é o serviço de Voz?
O serviço de Fala fornece recursos de fala para texto e de texto para fala com um recurso de fala. Você pode transcrever fala para texto com alta precisão, produzir texto com som natural para vozes de fala, traduzir áudio falado e usar o reconhecimento de alto-falante durante conversas.

Crie vozes personalizadas, adicione palavras específicas ao vocabulário de base ou compile os seus próprios modelos. Execute a Voz em qualquer lugar, seja na cloud ou na periferia em contentores. É fácil habilitar seus aplicativos, ferramentas e dispositivos com as APIs Speech CLI, Speech SDK, Speech Studio ou REST.
A fala está disponível para muitos idiomas, regiões e preços.
Cenários de voz
Os cenários comuns para fala incluem:
- Legendas: saiba como sincronizar legendas com o áudio de entrada, aplicar filtros de palavrões, obter resultados parciais, aplicar personalizações e identificar idiomas falados para cenários multilíngues.
- Criação de conteúdo de áudio: Você pode usar vozes neurais para tornar as interações com chatbots e assistentes de voz mais naturais e envolventes, converter textos digitais, como e-books, em audiolivros e aprimorar os sistemas de navegação no carro.
- Call Center: transcreva chamadas em tempo real ou processe um lote de chamadas, retire informações de identificação pessoal e extraia informações como sentimento para ajudar com seu caso de uso de call center.
- Aprendizagem de línguas: Forneça feedback de avaliação de pronúncia aos alunos de línguas, apoie a transcrição em tempo real para conversas de aprendizagem remota e leia em voz alta materiais de ensino com vozes neurais.
- Assistentes de voz: Crie interfaces de conversação naturais e humanas para as suas aplicações e experiências. O recurso de assistente de voz fornece interação rápida e confiável entre um dispositivo e uma implementação de assistente.
A Microsoft usa o Speech para muitos cenários, como legendas no Teams, ditado no Office 365 e leitura em voz alta no navegador Microsoft Edge.
Capacidades de fala
Estas seções resumem os recursos de fala com links para obter mais informações.
Voz em texto
Use fala para texto para transcrever áudio em texto, em tempo real ou de forma assíncrona com transcrição em lote.
Gorjeta
Você pode tentar conversão de fala em texto em tempo real no Speech Studio sem se inscrever ou escrever qualquer código.
Converta áudio em texto a partir de várias fontes, entre as quais microfones, ficheiros de áudio e armazenamento de blob. Use a diarização do orador para determinar quem disse o quê e quando. Obtenha transcrições legíveis com a formatação e a pontuação automática.
O modelo base pode não ser suficiente se o áudio contiver ruído ambiente ou incluir vários jargões específicos da indústria e do domínio. Nesses casos, você pode criar e treinar modelos de fala personalizados com dados acústicos, de linguagem e de pronúncia. Os modelos de fala personalizados são privados e podem oferecer uma vantagem competitiva.
Conversão de voz em texto em tempo real
Com fala em texto em tempo real, o áudio é transcrito à medida que a fala é reconhecida a partir de um microfone ou arquivo. Use fala em tempo real para texto para aplicativos que precisam transcrever áudio em tempo real, como:
- Transcrições, legendas ou legendas para reuniões ao vivo
- Diarização
- Avaliação da pronúncia
- Agentes de contact center auxiliam
- Ditado
- Agentes de voz
Transcrição em lotes
A transcrição em lote é usada para transcrever uma grande quantidade de áudio no armazenamento. Pode apontar para ficheiros de áudio com um URI de assinatura de acesso partilhado (SAS) e receber os resultados de transcrição de forma assíncrona. Use a transcrição em lote para aplicativos que precisam transcrever áudio em massa, como:
- Transcrições, legendas ou legendas para áudio pré-gravado
- Análise pós-chamada do contact center
- Diarização
Conversão de texto em voz
Com texto em fala, você pode converter texto de entrada em fala sintetizada como humana. Use vozes neurais, que são humanas como vozes alimentadas por redes neurais profundas. Use a SSML (Speech Synthesis Markup Language) para ajustar o tom, a pronúncia, a taxa de fala, o volume e muito mais.
- Voz neural pré-construída: Vozes altamente naturais e prontas para uso. Verifique as amostras de voz neural pré-construídas na Galeria de Vozes e determine a voz certa para as necessidades da sua empresa.
- Voz neural personalizada: Além das vozes neurais pré-construídas que saem da caixa, você também pode criar uma voz neural personalizada que seja reconhecível e exclusiva para sua marca ou produto. As vozes neurais personalizadas são privadas e podem oferecer uma vantagem competitiva. Verifique as amostras de voz neural personalizadas aqui.
Tradução de voz
A tradução de voz permite a tradução multilingue em tempo real da fala para as suas aplicações, ferramentas e dispositivos. Use esse recurso para conversão de fala para fala e de fala para texto.
Identificação linguística
A identificação de idioma é usada para identificar idiomas falados em áudio quando comparados com uma lista de idiomas suportados. Use a identificação da linguagem por si só, com reconhecimento de fala para texto ou com tradução de fala.
Reconhecimento de oradores
O reconhecimento de alto-falantes fornece algoritmos que verificam e identificam os alto-falantes por suas características únicas de voz. O reconhecimento do orador é usado para responder à pergunta: "Quem está falando?".
Avaliação da pronúncia
A avaliação da pronúncia avalia a pronúncia da fala e dá feedback aos falantes sobre a precisão e fluência do áudio falado. Com a avaliação da pronúncia, os estudantes de línguas podem praticar, obter feedback instantâneo e melhorar a sua pronúncia para que possam falar e apresentar com confiança.
Reconhecimento de intenção
Reconhecimento de intenção: use fala para texto com compreensão de linguagem conversacional para derivar as intenções do usuário da fala transcrita e agir em comandos de voz.
Entrega e presença
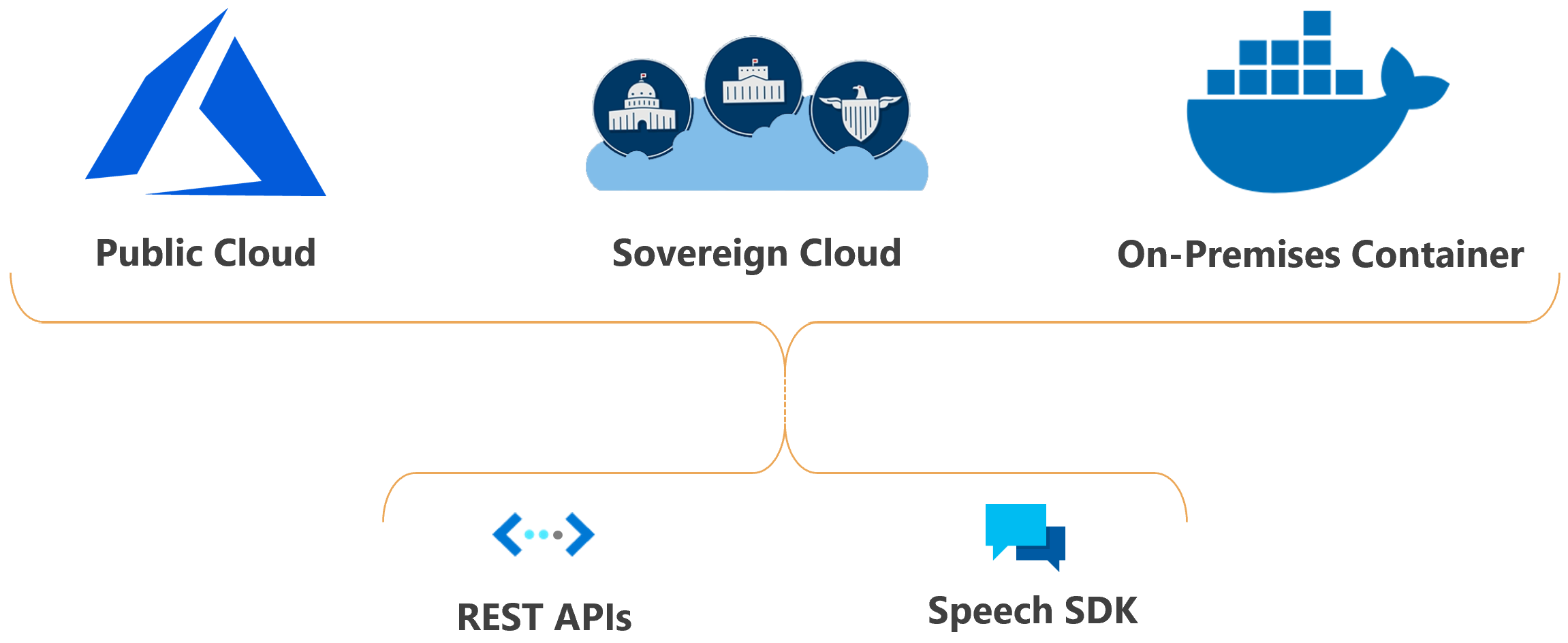
Você pode implantar os recursos do Azure AI Speech na nuvem ou no local.
Com contêineres, você pode aproximar o serviço de seus dados por motivos de conformidade, segurança ou outros motivos operacionais.
A implantação do serviço de fala em nuvens soberanas está disponível para algumas entidades governamentais e seus parceiros. Por exemplo, a nuvem do Azure Government está disponível para entidades governamentais dos EUA e seus parceiros. O Microsoft Azure operado pela nuvem 21Vianet está disponível para organizações com presença comercial na China. Para obter mais informações, consulte Nuvens soberanas.
Utilizar a Voz na sua aplicação
O Speech Studio é um conjunto de ferramentas baseadas na interface do usuário para criar e integrar recursos do serviço Azure AI Speech em seus aplicativos. Você cria projetos no Speech Studio usando uma abordagem sem código e, em seguida, faz referência a esses ativos em seus aplicativos usando o SDK de fala, a CLI de fala ou as APIs REST.
A CLI de Fala é uma ferramenta de linha de comando para usar o serviço de Fala sem precisar escrever nenhum código. A maioria das funcionalidades do SDK de Voz estão disponíveis na CLI de Voz e algumas funcionalidades e personalizações avançadas são simplificadas na CLI de Voz.
O SDK de Fala expõe muitos dos recursos do serviço de Fala que você pode usar para desenvolver aplicativos habilitados para fala. O Speech SDK está disponível em muitas linguagens de programação e em todas as plataformas.
Em alguns casos, você não pode ou não deve usar o SDK de fala. Nesses casos, você pode usar APIs REST para acessar o serviço de fala. Por exemplo, use APIs REST para transcrição em lote e APIs REST de reconhecimento de alto-falante.
Começar
Oferecemos inícios rápidos em muitas linguagens de programação populares. Cada início rápido é projetado para ensinar padrões básicos de design e fazer com que você execute o código em menos de 10 minutos. Consulte a lista a seguir para obter o início rápido de cada recurso:
- Guia de início rápido de fala para texto
- Guia de início rápido de texto para fala
- Guia de início rápido de tradução de fala
Amostras de código
O código de exemplo para o serviço de Fala está disponível no GitHub. Esses exemplos abrangem cenários comuns, como a leitura de áudio de um arquivo ou fluxo, o reconhecimento contínuo e de captura única e o trabalho com modelos personalizados. Use estes links para exibir exemplos de SDK e REST:
- Exemplos de conversão de fala em texto, de texto em fala e de tradução de fala (SDK)
- Amostras de transcrição em lote (REST)
- Exemplos de conversão de texto em fala (REST)
- Exemplos de assistente de voz (SDK)
IA responsável
Um sistema de IA inclui não apenas a tecnologia, mas também as pessoas que a usam, as pessoas que são afetadas por ela e o ambiente em que é implantado. Leia as notas de transparência para saber mais sobre o uso e a implantação responsáveis da IA em seus sistemas.
Voz em texto
- Nota de transparência e casos de uso
- Características e limitações
- Integração e utilização responsável
- Dados, privacidade e segurança
Avaliação de Pronúncia
Voz neural personalizada
- Nota de transparência e casos de uso
- Características e limitações
- Acesso limitado
- Implantação responsável de fala sintética
- Divulgação de talentos de voz
- Divulgação das orientações relativas ao desenho ou modelo
- Divulgação de padrões de design
- Código de conduta
- Dados, privacidade e segurança
Reconhecimento de Orador
- Nota de transparência e casos de uso
- Características e limitações
- Acesso limitado
- Orientações gerais
- Dados, privacidade e segurança