Migrar dados do Cassandra para uma conta do Azure Cosmos DB para Apache Cassandra com o Azure Databricks
APLICA-SE A:![]() Cassandra
Cassandra
A API para Cassandra no Azure Cosmos DB tornou-se uma ótima opção para cargas de trabalho empresariais em execução no Apache Cassandra por vários motivos:
Sem custos gerais de gestão e monitorização: Elimina a sobrecarga da gestão e monitorização das definições nos ficheiros do SO, JVM e YAML e respetivas interações.
Poupanças de custos significativas: Pode poupar custos com o Azure Cosmos DB, que inclui o custo das VMs, a largura de banda e quaisquer licenças aplicáveis. Não tem de gerir datacenters, servidores, armazenamento SSD, redes e custos de eletricidade.
Capacidade de utilizar código e ferramentas existentes: O Azure Cosmos DB fornece compatibilidade ao nível do protocolo de transmissão com os SDKs e ferramentas do Cassandra existentes. Esta compatibilidade garante que pode utilizar a base de código existente com o Azure Cosmos DB para Apache Cassandra com alterações triviais.
Existem várias formas de migrar cargas de trabalho de base de dados de uma plataforma para outra. O Azure Databricks é uma oferta de plataforma como serviço (PaaS) para o Apache Spark que oferece uma forma de realizar migrações offline em grande escala. Este artigo descreve os passos necessários para migrar dados de keyspaces e tabelas nativas do Apache Cassandra para o Azure Cosmos DB para Apache Cassandra com o Azure Databricks.
Pré-requisitos
Aprovisionar uma conta do Azure Cosmos DB para Apache Cassandra.
Reveja as noções básicas da ligação a um Azure Cosmos DB para Apache Cassandra.
Reveja as funcionalidades suportadas no Azure Cosmos DB para Apache Cassandra para garantir a compatibilidade.
Certifique-se de que já criou áreas de chaves e tabelas vazias na sua conta do Azure Cosmos DB de destino para o Apache Cassandra.
Aprovisionar um cluster do Azure Databricks
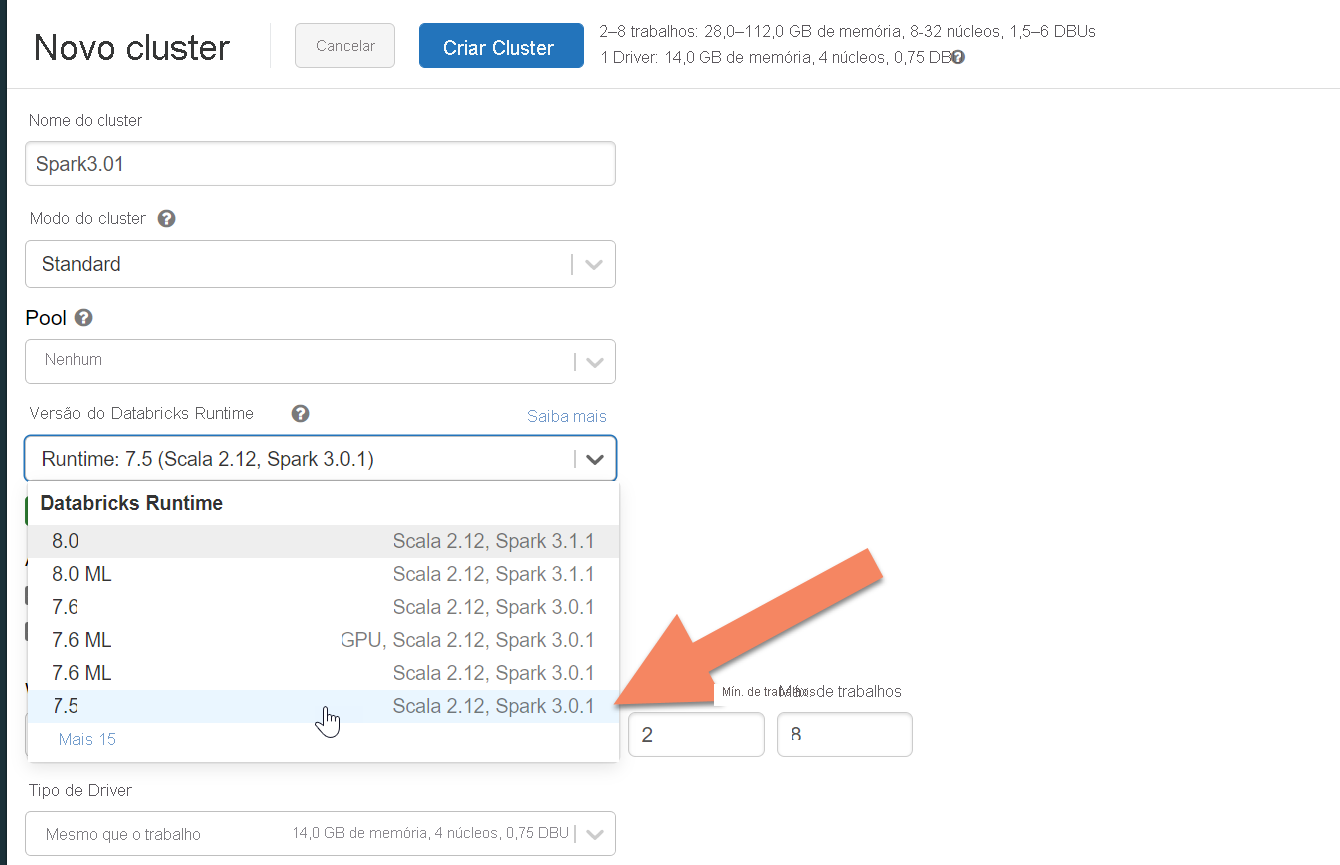
Pode seguir as instruções para aprovisionar um cluster do Azure Databricks. Recomendamos que selecione Databricks runtime versão 7.5, que suporta o Spark 3.0.
Adicionar dependências
Tem de adicionar a biblioteca do Conector para Cassandra do Apache Spark ao cluster para ligar aos pontos finais nativos e do Cassandra do Azure Cosmos DB. No seu cluster, selecione Bibliotecas>Instalar Novo>Maven e, em seguida, adicione com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0 as coordenadas do Maven.
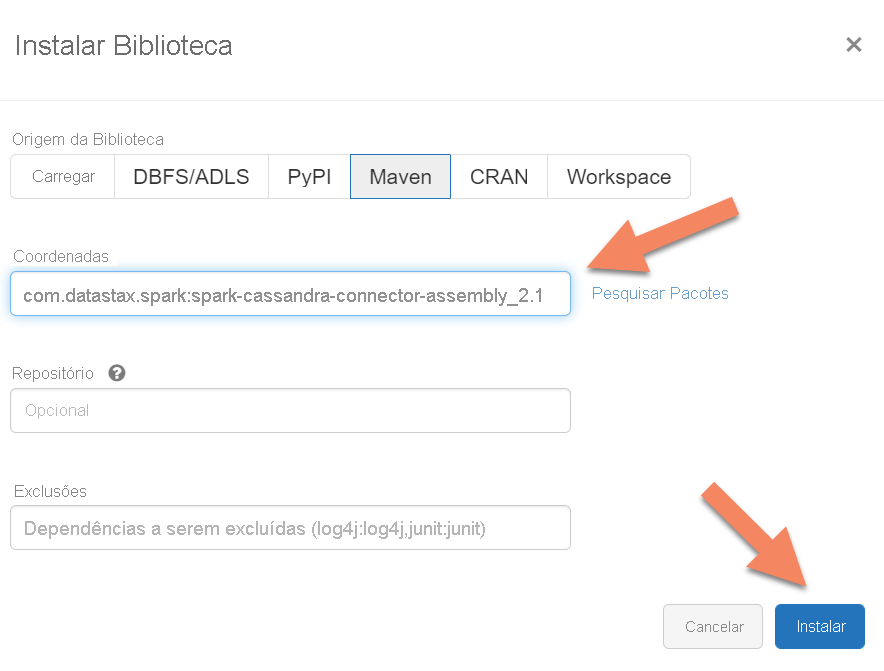
Selecione Instalar e, em seguida, reinicie o cluster quando a instalação estiver concluída.
Nota
Certifique-se de que reinicia o cluster do Databricks após a instalação da biblioteca do Cassandra Connector.
Aviso
Os exemplos apresentados neste artigo foram testados com a versão 3.0.1 do Spark e o Conector do Apache Spark para Cassandra correspondente com.datastax.spark:spark-cassandra-connector-assembly_2.12:3.0.0. As versões posteriores do Spark e/ou do conector do Cassandra podem não funcionar conforme esperado.
Criar Bloco de Notas scala para migração
Crie um Bloco de Notas Scala no Databricks. Substitua as configurações do Cassandra de origem e de destino pelas credenciais correspondentes e os espaços de chaves e tabelas de origem e de destino. Em seguida, execute o seguinte código:
import com.datastax.spark.connector._
import com.datastax.spark.connector.cql._
import org.apache.spark.SparkContext
// source cassandra configs
val nativeCassandra = Map(
"spark.cassandra.connection.host" -> "<Source Cassandra Host>",
"spark.cassandra.connection.port" -> "9042",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "false",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>"
)
//target cassandra configs
val cosmosCassandra = Map(
"spark.cassandra.connection.host" -> "<USERNAME>.cassandra.cosmos.azure.com",
"spark.cassandra.connection.port" -> "10350",
"spark.cassandra.auth.username" -> "<USERNAME>",
"spark.cassandra.auth.password" -> "<PASSWORD>",
"spark.cassandra.connection.ssl.enabled" -> "true",
"keyspace" -> "<KEYSPACE>",
"table" -> "<TABLE>",
//throughput related settings below - tweak these depending on data volumes.
"spark.cassandra.output.batch.size.rows"-> "1",
"spark.cassandra.output.concurrent.writes" -> "1000",
//"spark.cassandra.connection.remoteConnectionsPerExecutor" -> "1", // Spark 3.x
"spark.cassandra.connection.connections_per_executor_max"-> "1", // Spark 2.x
"spark.cassandra.concurrent.reads" -> "512",
"spark.cassandra.output.batch.grouping.buffer.size" -> "1000",
"spark.cassandra.connection.keep_alive_ms" -> "600000000"
)
//Read from native Cassandra
val DFfromNativeCassandra = sqlContext
.read
.format("org.apache.spark.sql.cassandra")
.options(nativeCassandra)
.load
//Write to CosmosCassandra
DFfromNativeCassandra
.write
.format("org.apache.spark.sql.cassandra")
.options(cosmosCassandra)
.mode(SaveMode.Append) // only required for Spark 3.x
.save
Nota
Os spark.cassandra.output.batch.size.rows valores e spark.cassandra.output.concurrent.writes e o número de trabalhos no cluster do Spark são configurações importantes a ajustar para evitar a limitação da taxa. A limitação da taxa ocorre quando os pedidos para o Azure Cosmos DB excedem o débito aprovisionado ou as unidades de pedido (RUs). Poderá ter de ajustar estas definições, consoante o número de executores no cluster do Spark e, potencialmente, o tamanho (e, portanto, o custo de RU) de cada registo a ser escrito nas tabelas de destino.
Resolução de problemas
Limitação da taxa (erro 429)
Poderá ver um código de erro 429 ou um texto de erro "a taxa de pedidos é grande", mesmo que tenha reduzido as definições para os valores mínimos. Os seguintes cenários podem causar a limitação da taxa:
O débito alocado à tabela é inferior a 6000 unidades de pedido. Mesmo com as definições mínimas, o Spark pode escrever a uma taxa de cerca de 6000 unidades de pedido ou mais. Se tiver aprovisionado uma tabela num espaço de chaves com débito partilhado, é possível que esta tabela tenha menos de 6000 RUs disponíveis no runtime.
Certifique-se de que a tabela para a qual está a migrar tem, pelo menos, 6000 RUs disponíveis quando executar a migração. Se necessário, aloque unidades de pedido dedicadas a essa tabela.
Distorção excessiva de dados com grandes volumes de dados. Se tiver uma grande quantidade de dados para migrar para uma determinada tabela, mas tiver uma distorção significativa nos dados (ou seja, um grande número de registos escritos para o mesmo valor de chave de partição), poderá continuar a ter uma limitação de taxa mesmo que tenha várias unidades de pedido aprovisionadas na tabela. As unidades de pedido são divididas de forma igual entre partições físicas e a distorção de dados pesada pode causar um estrangulamento de pedidos para uma única partição.
Neste cenário, reduza para definições de débito mínimas no Spark e force a migração a ser executada lentamente. Este cenário pode ser mais comum ao migrar tabelas de referência ou de controlo, em que o acesso é menos frequente e a distorção pode ser elevada. No entanto, se existir uma distorção significativa em qualquer outro tipo de tabela, poderá querer rever o modelo de dados para evitar problemas de partição frequente da carga de trabalho durante as operações de estado estável.