Copiar e transformar dados no Banco de Dados do Azure para MySQL usando o Azure Data Factory ou o Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Este artigo descreve como usar a Atividade de Cópia no Azure Data Factory ou nos pipelines do Synapse Analytics para copiar dados de e para o Banco de Dados do Azure para MySQL e usar o Fluxo de Dados para transformar dados no Banco de Dados do Azure para MySQL. Para saber mais, leia os artigos introdutórios do Azure Data Factory e do Synapse Analytics.
Este conector é especializado para
- Servidor Único da Base de Dados do Azure para MySQL
- Base de Dados do Azure para MySQL – Servidor Flexível
Para copiar dados do banco de dados MySQL genérico localizado no local ou na nuvem, use o conector MySQL.
Pré-requisitos
Este início rápido requer os seguintes recursos e configuração mencionados abaixo como ponto de partida:
- Um banco de dados existente do Azure para servidor MySQL Single ou MySQL Flexible Server com acesso público ou ponto de extremidade privado.
- Habilite Permitir acesso público de qualquer serviço do Azure no Azure para este servidor na página de rede do servidor MySQL. Isso permitirá que você use o estúdio Data Factory.
Capacidades suportadas
Este conector do Banco de Dados do Azure para MySQL tem suporte para os seguintes recursos:
| Capacidades suportadas | IR | Ponto final privado gerido |
|---|---|---|
| Atividade de cópia (origem/coletor) | ① ② | ✓ |
| Mapeando o fluxo de dados (origem/coletor) | ① | ✓ |
| Atividade de Pesquisa | ① ② | ✓ |
(1) Tempo de execução de integração do Azure (2) Tempo de execução de integração auto-hospedado
Introdução
Para executar a atividade Copiar com um pipeline, você pode usar uma das seguintes ferramentas ou SDKs:
- A ferramenta Copiar dados
- O portal do Azure
- O SDK do .NET
- O SDK do Python
- Azure PowerShell
- A API REST
- O modelo do Azure Resource Manager
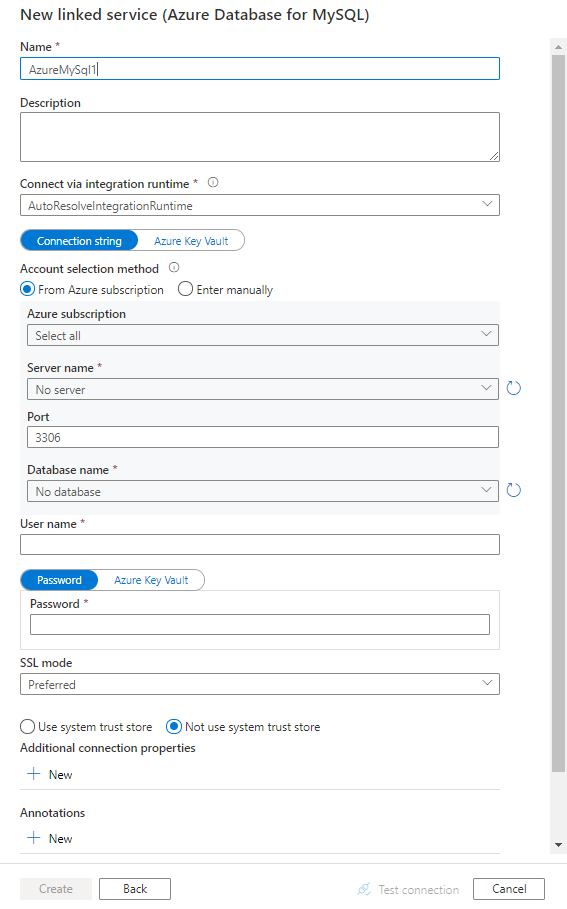
Criar um serviço vinculado ao Banco de Dados do Azure para MySQL usando a interface do usuário
Use as etapas a seguir para criar um serviço vinculado ao Banco de Dados do Azure para MySQL na interface do usuário do portal do Azure.
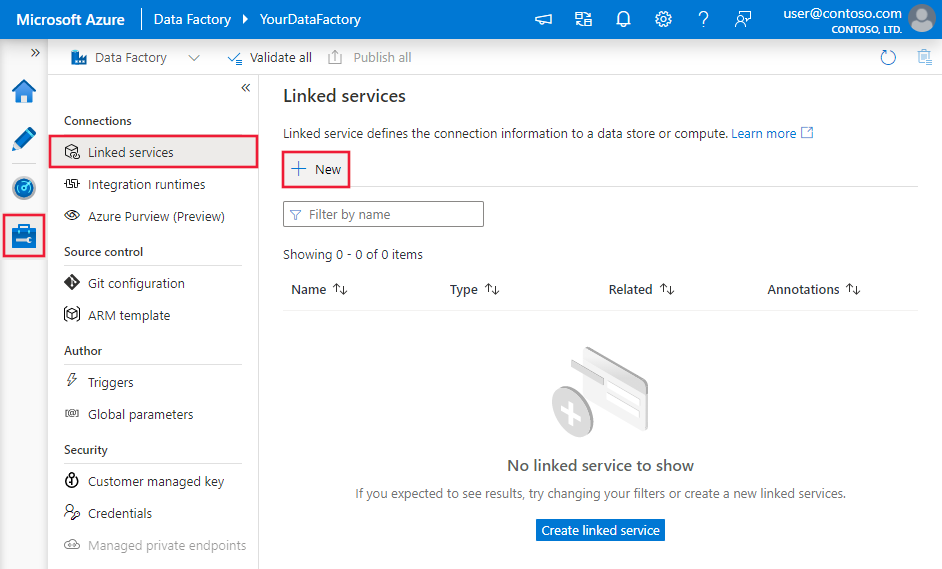
Navegue até a guia Gerenciar em seu espaço de trabalho do Azure Data Factory ou Synapse e selecione Serviços Vinculados e clique em Novo:
Procure o MySQL e selecione o conector do Banco de Dados do Azure para MySQL.

Configure os detalhes do serviço, teste a conexão e crie o novo serviço vinculado.
Detalhes de configuração do conector
As seções a seguir fornecem detalhes sobre as propriedades usadas para definir entidades do Data Factory específicas para o conector do Banco de Dados do Azure para MySQL.
Propriedades do serviço vinculado
As seguintes propriedades têm suporte para o serviço vinculado Banco de Dados do Azure para MySQL:
| Propriedade | Descrição | Necessário |
|---|---|---|
| tipo | A propriedade type deve ser definida como: AzureMySql | Sim |
| connectionString | Especifique as informações necessárias para se conectar ao Banco de Dados do Azure para a instância do MySQL. Você também pode colocar a senha no Cofre de Chaves do Azure e extrair a password configuração da cadeia de conexão. Consulte os seguintes exemplos e o artigo Armazenar credenciais no Cofre de Chaves do Azure com mais detalhes. |
Sim |
| ConecteVia | O tempo de execução de integração a ser usado para se conectar ao armazenamento de dados. Você pode usar o Azure Integration Runtime ou o Self-hosted Integration Runtime (se seu armazenamento de dados estiver localizado em rede privada). Se não for especificado, ele usará o Tempo de Execução de Integração do Azure padrão. | Não |
Uma cadeia de conexão típica é Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>. Mais propriedades que pode definir de acordo com o seu caso:
| Propriedade | Description | Opções | Necessário |
|---|---|---|---|
| SSLMode | Esta opção especifica se o driver usa criptografia e verificação TLS ao se conectar ao MySQL. Por exemplo: SSLMode=<0/1/2/3/4> |
DESATIVADO (0) / PREFERENCIAL (1) (Padrão) / OBRIGATÓRIO (2) / VERIFY_CA (3) / VERIFY_IDENTITY (4) | Não |
| UseSystemTrustStore | Esta opção especifica se um certificado de autoridade de certificação do armazenamento confiável do sistema deve ser usado ou de um arquivo PEM especificado. Por exemplo: UseSystemTrustStore=<0/1>; |
Ativado (1) / Desativado (0) (Padrão) | Não |
Exemplo:
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;PWD=<password>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Exemplo: armazenar senha no Cofre da Chave do Azure
{
"name": "AzureDatabaseForMySQLLinkedService",
"properties": {
"type": "AzureMySql",
"typeProperties": {
"connectionString": "Server=<server>.mysql.database.azure.com;Port=<port>;Database=<database>;UID=<username>;",
"password": {
"type": "AzureKeyVaultSecret",
"store": {
"referenceName": "<Azure Key Vault linked service name>",
"type": "LinkedServiceReference"
},
"secretName": "<secretName>"
}
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
Propriedades do conjunto de dados
Para obter uma lista completa de seções e propriedades disponíveis para definir conjuntos de dados, consulte o artigo sobre conjuntos de dados. Esta seção fornece uma lista de propriedades suportadas pelo conjunto de dados do Banco de Dados do Azure para MySQL.
Para copiar dados do Banco de Dados do Azure para MySQL, defina a propriedade type do conjunto de dados como AzureMySqlTable. As seguintes propriedades são suportadas:
| Propriedade | Descrição | Necessário |
|---|---|---|
| tipo | A propriedade type do conjunto de dados deve ser definida como: AzureMySqlTable | Sim |
| tableName | Nome da tabela no banco de dados MySQL. | Não (se "consulta" na fonte da atividade for especificado) |
Exemplo
{
"name": "AzureMySQLDataset",
"properties": {
"type": "AzureMySqlTable",
"linkedServiceName": {
"referenceName": "<Azure MySQL linked service name>",
"type": "LinkedServiceReference"
},
"typeProperties": {
"tableName": "<table name>"
}
}
}
Propriedades da atividade Copy
Para obter uma lista completa de seções e propriedades disponíveis para definir atividades, consulte o artigo Pipelines . Esta seção fornece uma lista de propriedades suportadas pelo Banco de Dados do Azure para origem e coletor do MySQL.
Banco de Dados do Azure para MySQL como origem
Para copiar dados do Banco de Dados do Azure para MySQL, as seguintes propriedades são suportadas na seção de fonte de atividade de cópia:
| Propriedade | Descrição | Necessário |
|---|---|---|
| tipo | A propriedade type da fonte de atividade de cópia deve ser definida como: AzureMySqlSource | Sim |
| query | Use a consulta SQL personalizada para ler dados. Por exemplo: "SELECT * FROM MyTable". |
Não (se "tableName" no conjunto de dados for especificado) |
| queryCommandTimeout | O tempo de espera antes que a solicitação de consulta atinja o tempo limite. O padrão é 120 minutos (02:00:00) | Não |
Exemplo:
"activities":[
{
"name": "CopyFromAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<Azure MySQL input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureMySqlSource",
"query": "<custom query e.g. SELECT * FROM MyTable>"
},
"sink": {
"type": "<sink type>"
}
}
}
]
Banco de Dados do Azure para MySQL como coletor
Para copiar dados para o Banco de Dados do Azure para MySQL, as seguintes propriedades são suportadas na seção do coletor de atividade de cópia:
| Propriedade | Descrição | Necessário |
|---|---|---|
| tipo | A propriedade type do coletor de atividade de cópia deve ser definida como: AzureMySqlSink | Sim |
| pré-CopyScript | Especifique uma consulta SQL para a atividade de cópia a ser executada antes de gravar dados no Banco de Dados do Azure para MySQL em cada execução. Você pode usar essa propriedade para limpar os dados pré-carregados. | Não |
| writeBatchSize | Insere dados na tabela do Banco de Dados do Azure para MySQL quando o tamanho do buffer atinge writeBatchSize. O valor permitido é inteiro que representa o número de linhas. |
Não (o padrão é 10.000) |
| writeBatchTimeout | Aguarde o tempo para que a operação de inserção em lote seja concluída antes que ela atinja o tempo limite. Os valores permitidos são Timepan. Um exemplo é 00:30:00 (30 minutos). |
Não (o padrão é 00:00:30) |
Exemplo:
"activities":[
{
"name": "CopyToAzureDatabaseForMySQL",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Azure MySQL output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureMySqlSink",
"preCopyScript": "<custom SQL script>",
"writeBatchSize": 100000
}
}
}
]
Mapeando propriedades de fluxo de dados
Ao transformar dados em fluxo de dados de mapeamento, você pode ler e gravar em tabelas do Banco de Dados do Azure para MySQL. Para obter mais informações, consulte a transformação de origem e a transformação de coletor no mapeamento de fluxos de dados. Você pode optar por usar um banco de dados do Azure para conjunto de dados MySQL ou um conjunto de dados embutido como tipo de fonte e coletor.
Transformação da fonte
A tabela abaixo lista as propriedades suportadas pelo Banco de Dados do Azure para a fonte MySQL. Você pode editar essas propriedades na guia Opções de origem .
| Nome | Descrição | Necessário | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Tabela | Se você selecionar Tabela como entrada, o fluxo de dados buscará todos os dados da tabela especificada no conjunto de dados. | Não | - | (apenas para conjunto de dados embutido) tableName |
| Consulta | Se você selecionar Consulta como entrada, especifique uma consulta SQL para buscar dados da origem, que substituirá qualquer tabela especificada no conjunto de dados. Usar consultas é uma ótima maneira de reduzir linhas para testes ou pesquisas. A cláusula Order By não é suportada, mas você pode definir uma instrução SELECT FROM completa. Você também pode usar funções de tabela definidas pelo usuário. select * from udfGetData() é um UDF em SQL que retorna uma tabela que você pode usar no fluxo de dados. Exemplo de consulta: select * from mytable where customerId > 1000 and customerId < 2000 ou select * from "MyTable". |
Não | String | query |
| Procedimento armazenado | Se você selecionar Procedimento armazenado como entrada, especifique um nome do procedimento armazenado para ler dados da tabela de origem ou selecione Atualizar para solicitar que o serviço descubra os nomes dos procedimentos. | Sim (se você selecionar Procedimento armazenado como entrada) | String | nome_procedimento |
| Parâmetros do procedimento | Se você selecionar Procedimento armazenado como entrada, especifique quaisquer parâmetros de entrada para o procedimento armazenado na ordem definida no procedimento ou selecione Importar para importar todos os parâmetros do procedimento usando o formulário @paraName. |
Não | Matriz | Insumos |
| Tamanho do lote | Especifique um tamanho de lote para fragmentar dados grandes em lotes. | Não | Integer | batchSize |
| Nível de isolamento | Escolha um dos seguintes níveis de isolamento: - Ler Comprometido - Ler Não confirmado (padrão) - Leitura repetível - Serializável - Nenhum (ignorar o nível de isolamento) |
Não | READ_COMMITTED READ_UNCOMMITTED REPEATABLE_READ SERIALIZÁVEL NENHUM |
Nível de isolamento |
Exemplo de script de origem do Banco de Dados do Azure para MySQL
Quando você usa o Banco de Dados do Azure para MySQL como tipo de origem, o script de fluxo de dados associado é:
source(allowSchemaDrift: true,
validateSchema: false,
isolationLevel: 'READ_UNCOMMITTED',
query: 'select * from mytable',
format: 'query') ~> AzureMySQLSource
Transformação do lavatório
A tabela abaixo lista as propriedades suportadas pelo coletor do Banco de Dados do Azure para MySQL. Você pode editar essas propriedades na guia Opções do coletor .
| Nome | Descrição | Necessário | Valores permitidos | Propriedade do script de fluxo de dados |
|---|---|---|---|---|
| Método de atualização | Especifique quais operações são permitidas no destino do banco de dados. O padrão é permitir apenas inserções. Para atualizar, atualizar ou excluir linhas, uma transformação de linha Alter é necessária para marcar linhas para essas ações. |
Sim | true ou false |
suprimido inserível atualizável Atualizável |
| Colunas-chave | Para atualizações, atualizações e exclusões, a(s) coluna(s) de chave devem ser definidas para determinar qual linha alterar. O nome da coluna que você escolher como a chave será usado como parte da atualização subsequente, upsert, excluir. Portanto, você deve escolher uma coluna que existe no mapeamento de coletor. |
Não | Matriz | chaves |
| Ignorar colunas de teclas de escrita | Se desejar não escrever o valor na coluna de chave, selecione "Ignorar colunas de chave de escrita". | Não | true ou false |
skipKeyWrites |
| Ação da tabela | Determina se todas as linhas da tabela de destino devem ser recriadas ou removidas antes da gravação. - Nenhuma: Nenhuma ação será feita para a mesa. - Recriar: A tabela será descartada e recriada. Necessário se criar uma nova tabela dinamicamente. - Truncate: Todas as linhas da tabela de destino serão removidas. |
Não | true ou false |
recriar truncate |
| Tamanho do lote | Especifique quantas linhas estão sendo escritas em cada lote. Lotes maiores melhoram a compactação e a otimização da memória, mas correm o risco de exceções de falta de memória ao armazenar dados em cache. | Não | Integer | batchSize |
| Scripts pré e pós SQL | Especifique scripts SQL de várias linhas que serão executados antes (pré-processamento) e depois que os dados (pós-processamento) forem gravados no banco de dados do coletor. | Não | String | pré-SQLs postSQLs |
Gorjeta
- Recomenda-se quebrar scripts de lote único com vários comandos em vários lotes.
- Somente instruções DDL (Data Definition Language) e DML (Data Manipulation Language) que retornam uma contagem de atualização simples podem ser executadas como parte de um lote. Saiba mais em Executando operações em lote
Habilitar extração incremental: use esta opção para informar ao ADF para processar apenas linhas que foram alteradas desde a última vez que o pipeline foi executado.
Coluna incremental: Ao usar o recurso de extração incremental, você deve escolher a data/hora ou a coluna numérica que deseja usar como marca d'água na tabela de origem.
Comece a ler desde o início: definir essa opção com extração incremental instruirá o ADF a ler todas as linhas na primeira execução de um pipeline com a extração incremental ativada.
Exemplo de script de coletor do Banco de Dados do Azure para MySQL
Quando você usa o Banco de Dados do Azure para MySQL como tipo de coletor, o script de fluxo de dados associado é:
IncomingStream sink(allowSchemaDrift: true,
validateSchema: false,
deletable:false,
insertable:true,
updateable:true,
upsertable:true,
keys:['keyColumn'],
format: 'table',
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> AzureMySQLSink
Propriedades da atividade de pesquisa
Para saber detalhes sobre as propriedades, verifique Atividade de pesquisa.
Mapeamento de tipo de dados para o Banco de Dados do Azure para MySQL
Ao copiar dados do Banco de Dados do Azure para MySQL, os mapeamentos a seguir são usados de tipos de dados MySQL para tipos de dados provisórios usados internamente no serviço. Consulte Mapeamentos de esquema e tipo de dados para saber como a atividade de cópia mapeia o esquema de origem e o tipo de dados para o coletor.
| Tipo de dados do Banco de Dados do Azure para MySQL | Tipo de dados de serviço provisório |
|---|---|
bigint |
Int64 |
bigint unsigned |
Decimal |
bit |
Boolean |
bit(M), M>1 |
Byte[] |
blob |
Byte[] |
bool |
Int16 |
char |
String |
date |
Datetime |
datetime |
Datetime |
decimal |
Decimal, String |
double |
Double |
double precision |
Double |
enum |
String |
float |
Single |
int |
Int32 |
int unsigned |
Int64 |
integer |
Int32 |
integer unsigned |
Int64 |
long varbinary |
Byte[] |
long varchar |
String |
longblob |
Byte[] |
longtext |
String |
mediumblob |
Byte[] |
mediumint |
Int32 |
mediumint unsigned |
Int64 |
mediumtext |
String |
numeric |
Decimal |
real |
Double |
set |
String |
smallint |
Int16 |
smallint unsigned |
Int32 |
text |
String |
time |
TimeSpan |
timestamp |
Datetime |
tinyblob |
Byte[] |
tinyint |
Int16 |
tinyint unsigned |
Int16 |
tinytext |
String |
varchar |
String |
year |
Int32 |
Conteúdos relacionados
Para obter uma lista de armazenamentos de dados suportados como fontes e coletores pela atividade de cópia, consulte Armazenamentos de dados suportados.