Tolerância a falhas da atividade de cópia nos pipelines do Azure Data Factory e do Synapse Analytics
APLICA-SE A: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
Gorjeta
Experimente o Data Factory no Microsoft Fabric, uma solução de análise tudo-em-um para empresas. O Microsoft Fabric abrange tudo, desde a movimentação de dados até ciência de dados, análises em tempo real, business intelligence e relatórios. Saiba como iniciar uma nova avaliação gratuitamente!
Quando você copia dados do armazenamento de origem para o de destino, a atividade de cópia fornece determinado nível de tolerância a falhas para evitar a interrupção de falhas no meio da movimentação de dados. Por exemplo, você está copiando milhões de linhas do armazenamento de origem para o de destino, onde uma chave primária foi criada no banco de dados de destino, mas o banco de dados de origem não tem nenhuma chave primária definida. Quando você copiar linhas duplicadas da origem para o destino, você atingirá a falha de violação de PK no banco de dados de destino. Neste momento, a atividade de cópia oferece duas maneiras de lidar com esses erros:
- Você pode cancelar a atividade de cópia assim que qualquer falha for encontrada.
- Você pode continuar a copiar o restante ativando a tolerância a falhas para ignorar os dados incompatíveis. Por exemplo, ignore a linha duplicada neste caso. Além disso, você pode registrar os dados ignorados habilitando o log de sessão na atividade de cópia. Você pode consultar a atividade de cópia de log de sessão para obter mais detalhes.
Copiando arquivos binários
O serviço suporta os seguintes cenários de tolerância a falhas ao copiar arquivos binários. Você pode optar por cancelar a atividade de cópia ou continuar a copiar o restante nos seguintes cenários:
- Os arquivos a serem copiados pelo serviço estão sendo excluídos por outros aplicativos ao mesmo tempo.
- Algumas pastas ou arquivos específicos não permitem o acesso ao serviço porque as ACLs desses arquivos ou pastas exigem um nível de permissão mais alto do que as informações de conexão configuradas.
- Um ou mais arquivos não são verificados para serem consistentes entre o armazenamento de origem e de destino se você habilitar a configuração de verificação de consistência de dados.
Habilite a tolerância a falhas com a interface do usuário
Para configurar a tolerância a falhas em uma atividade de cópia em um pipeline com interface do usuário, conclua as seguintes etapas:
Se você ainda não criou uma atividade Copiar para seu pipeline, procure Copiar no painel Atividades do pipeline e arraste uma atividade Copiar Dados para a tela do pipeline.
Selecione a nova atividade Copiar dados na tela, se ainda não estiver selecionada, e sua guia Configurações , para configurar a tolerância a falhas.
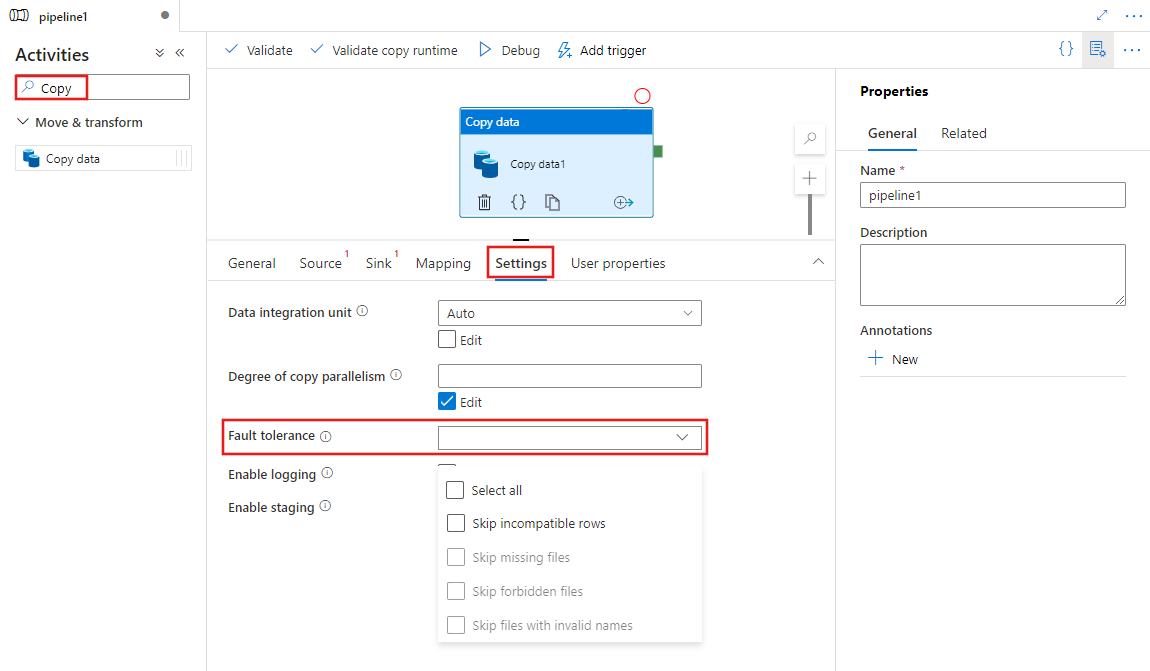
Configuração
Ao copiar arquivos binários entre armazenamentos de armazenamento, você pode habilitar a tolerância a falhas da seguinte maneira:
{
"name": "CopyActivityFaultTolerance",
"type": "Copy",
"typeProperties": {
"source": {
"type": "BinarySource",
"storeSettings": {
"type": "AzureDataLakeStoreReadSettings",
"recursive": true
}
},
"sink": {
"type": "BinarySink",
"storeSettings": {
"type": "AzureDataLakeStoreWriteSettings"
}
},
"skipErrorFile": {
"fileMissing": true,
"fileForbidden": true,
"dataInconsistency": true,
"invalidFileName": true
},
"validateDataConsistency": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
}
}
| Propriedade | Description | Valores permitidos | Necessário |
|---|---|---|---|
| skipErrorFile | Um grupo de propriedades para especificar os tipos de falhas que você deseja ignorar durante a movimentação de dados. | Não | |
| arquivoAusente | Um dos pares chave-valor dentro do conjunto de propriedades skipErrorFile para determinar se você deseja ignorar arquivos que estão sendo excluídos por outros aplicativos no momento em que o serviço está executando a operação de cópia. -True: você quer copiar o resto ignorando os arquivos que estão sendo excluídos por outros aplicativos. - Falso: você deseja abortar a atividade de cópia uma vez que todos os arquivos estão sendo excluídos do armazenamento de origem no meio da movimentação de dados. Lembre-se de que essa propriedade está definida como true como padrão. |
True(padrão) False |
Não |
| arquivoProibido | Um dos pares chave-valor dentro do pacote de propriedades skipErrorFile para determinar se você deseja ignorar os arquivos específicos, quando as ACLs desses arquivos ou pastas exigem um nível de permissão mais alto do que a conexão configurada. -True: você quer copiar o resto ignorando os arquivos. - Falso: você deseja abortar a atividade de cópia uma vez obtendo o problema de permissão em pastas ou arquivos. |
Verdadeiro False(padrão) |
Não |
| inconsistência de dados | Um dos pares chave-valor no saco de propriedades skipErrorFile para determinar se você deseja ignorar os dados inconsistentes entre o armazenamento de origem e de destino. -True: você deseja copiar o resto ignorando dados inconsistentes. - Falso: você deseja abortar a atividade de cópia uma vez que dados inconsistentes encontrados. Lembre-se de que essa propriedade só é válida quando você define validateDataConsistency como True. |
Verdadeiro False(padrão) |
Não |
| Nome do arquivo inválido | Um dos pares chave-valor dentro do saco de propriedades skipErrorFile para determinar se você deseja ignorar os arquivos específicos, quando os nomes de arquivo são inválidos para o armazenamento de destino. -True: você deseja copiar o resto ignorando os arquivos com nomes de arquivo inválidos. - False: você deseja abortar a atividade de cópia uma vez que todos os arquivos tenham nomes de arquivo inválidos. Lembre-se de que essa propriedade funciona ao copiar arquivos binários de qualquer armazenamento de armazenamento para o ADLS Gen2 ou ao copiar arquivos binários do AWS S3 apenas para qualquer armazenamento de armazenamento. |
Verdadeiro False(padrão) |
Não |
| logSettings | Um grupo de propriedades que podem ser especificadas quando você deseja registrar os nomes de objeto ignorados. | Não | |
| linkedServiceName | O serviço vinculado do Armazenamento de Blobs do Azure ou do Azure Data Lake Storage Gen2 para armazenar os arquivos de log de sessão. | Os nomes de um AzureBlobStorage ou AzureBlobFS tipo de serviço vinculado, que se refere à instância que você usa para armazenar o arquivo de log. |
Não |
| path | O caminho dos arquivos de log. | Especifique o caminho que você usa para armazenar os arquivos de log. Se você não fornecer um caminho, o serviço criará um contêiner para você. | Não |
Nota
A seguir estão os pré-requisitos para habilitar a tolerância a falhas na atividade de cópia ao copiar arquivos binários. Para ignorar arquivos específicos quando eles estão sendo excluídos do armazenamento de origem:
- O conjunto de dados de origem e o conjunto de dados do coletor devem ser de formato binário e o tipo de compactação não pode ser especificado.
- Os tipos de armazenamento de dados suportados são armazenamento de Blob do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, File System, FTP, SFTP, Amazon S3, Google Cloud Storage e HDFS.
- Somente se quando você especificar vários arquivos no conjunto de dados de origem, que pode ser uma pasta, curinga ou uma lista de arquivos, a atividade de cópia poderá ignorar os arquivos de erro específicos. Se um único arquivo for especificado no conjunto de dados de origem a ser copiado para o destino, a atividade de cópia falhará se ocorrer algum erro.
Para ignorar arquivos específicos quando seu acesso é proibido do armazenamento de origem:
- O conjunto de dados de origem e o conjunto de dados do coletor devem ser de formato binário e o tipo de compactação não pode ser especificado.
- Os tipos de armazenamento de dados suportados são armazenamento de Blob do Azure, Azure Data Lake Storage Gen1, Azure Data Lake Storage Gen2, Azure Files, SFTP, Amazon S3 e HDFS.
- Somente se quando você especificar vários arquivos no conjunto de dados de origem, que pode ser uma pasta, curinga ou uma lista de arquivos, a atividade de cópia poderá ignorar os arquivos de erro específicos. Se um único arquivo for especificado no conjunto de dados de origem a ser copiado para o destino, a atividade de cópia falhará se ocorrer algum erro.
Para ignorar arquivos específicos quando se verifica que eles são inconsistentes entre o armazenamento de origem e de destino:
- Você pode obter mais detalhes do documento de consistência de dados aqui.
Monitorização
Saída da atividade de cópia
Você pode obter o número de arquivos que estão sendo lidos, gravados e ignorados através da saída de cada atividade de cópia executada.
"output": {
"dataRead": 695,
"dataWritten": 186,
"filesRead": 3,
"filesWritten": 1,
"filesSkipped": 2,
"throughput": 297,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"dataConsistencyVerification":
{
"VerificationResult": "Verified",
"InconsistentData": "Skipped"
}
}
Log de sessão da atividade de cópia
Se você configurar para registrar os nomes de arquivo ignorados, poderá encontrar o arquivo de log neste caminho: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Os arquivos de log devem ser os arquivos csv. O esquema do arquivo de log é o seguinte:
| Coluna | Description |
|---|---|
| Carimbo de Data/Hora | O carimbo de data/hora quando o arquivo foi ignorado. |
| Nível | O nível de log deste item. Ele estará no nível 'Aviso' para o item que mostra o arquivo pulando. |
| OperationName | Copie o comportamento operacional da atividade em cada arquivo. Será 'FileSkip' para especificar o arquivo a ser ignorado. |
| OperationItem | Os nomes de arquivo a serem ignorados. |
| Mensagem | Mais informações para ilustrar por que o arquivo está sendo ignorado. |
O exemplo de um arquivo de log é o seguinte:
Timestamp,Level,OperationName,OperationItem,Message
2020-03-24 05:35:41.0209942,Warning,FileSkip,"bigfile.csv","File is skipped after read 322961408 bytes: ErrorCode=UserErrorSourceBlobNotExist,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=The required Blob is missing. ContainerName: https://transferserviceonebox.blob.core.windows.net/skipfaultyfile, path: bigfile.csv.,Source=Microsoft.DataTransfer.ClientLibrary,'."
2020-03-24 05:38:41.2595989,Warning,FileSkip,"3_nopermission.txt","File is skipped after read 0 bytes: ErrorCode=AdlsGen2OperationFailed,'Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=ADLS Gen2 operation failed for: Operation returned an invalid status code 'Forbidden'. Account: 'adlsgen2perfsource'. FileSystem: 'skipfaultyfilesforbidden'. Path: '3_nopermission.txt'. ErrorCode: 'AuthorizationPermissionMismatch'. Message: 'This request is not authorized to perform this operation using this permission.'. RequestId: '35089f5d-101f-008c-489e-01cce4000000'..,Source=Microsoft.DataTransfer.ClientLibrary,''Type=Microsoft.DataTransfer.Common.Shared.HybridDeliveryException,Message=Operation returned an invalid status code 'Forbidden',Source=,''Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message='Type=Microsoft.Azure.Storage.Data.Models.ErrorSchemaException,Message=Operation returned an invalid status code 'Forbidden',Source=Microsoft.DataTransfer.ClientLibrary,',Source=Microsoft.DataTransfer.ClientLibrary,'."
A partir do log acima, você pode ver bigfile.csv foi ignorado devido a outro aplicativo excluído este arquivo quando o serviço estava copiando-o. E 3_nopermission.txt foi ignorado porque o serviço não tem permissão para acessá-lo devido a um problema de permissão.
Copiar dados tabulares
Cenários suportados
A atividade de cópia suporta três cenários para detetar, ignorar e registrar dados tabulares incompatíveis:
Incompatibilidade entre o tipo de dados de origem e o tipo nativo do coletor.
Por exemplo: copie dados de um arquivo CSV no armazenamento de Blob para um banco de dados SQL com uma definição de esquema que contenha três colunas do tipo INT. As linhas do arquivo CSV que contêm dados numéricos, como 123.456.789, são copiadas com êxito para o repositório de coletores. No entanto, as linhas que contêm valores não numéricos, como 123.456, abc são detetadas como incompatíveis e são ignoradas.
Incompatibilidade no número de colunas entre a origem e o coletor.
Por exemplo: copie dados de um arquivo CSV no armazenamento de Blob para um banco de dados SQL com uma definição de esquema que contém seis colunas. As linhas do arquivo CSV que contêm seis colunas são copiadas com êxito para o repositório de coletores. As linhas do arquivo CSV que contêm mais de seis colunas são detetadas como incompatíveis e ignoradas.
Violação de chave primária ao gravar no SQL Server/Banco de Dados SQL do Azure/Azure Cosmos DB.
Por exemplo: copie dados de um servidor SQL para um banco de dados SQL. Uma chave primária é definida no banco de dados SQL do coletor, mas nenhuma chave primária é definida no servidor SQL de origem. As linhas duplicadas que existem na origem não podem ser copiadas para o coletor. A atividade de cópia copia apenas a primeira linha dos dados de origem para o coletor. As linhas de origem subsequentes que contêm o valor de chave primária duplicado são detetadas como incompatíveis e ignoradas.
Nota
- Para carregar dados no Azure Synapse Analytics usando o PolyBase, configure as configurações nativas de tolerância a falhas do PolyBase especificando políticas de rejeição por meio de "polyBaseSettings" na atividade de cópia. Você ainda pode habilitar o redirecionamento de linhas incompatíveis com o PolyBase para Blob ou ADLS normalmente, conforme mostrado abaixo.
- Esse recurso não se aplica quando a atividade de cópia é configurada para invocar o Amazon Redshift Unload.
- Esse recurso não se aplica quando a atividade de cópia é configurada para invocar um procedimento armazenado de um coletor SQL ou usar o Upsert para gravar dados em um coletor SQL.
Configuração
O exemplo a seguir fornece uma definição JSON para configurar ignorar as linhas incompatíveis na atividade de cópia:
"typeProperties": {
"source": {
"type": "AzureSqlSource"
},
"sink": {
"type": "AzureSqlSink"
},
"enableSkipIncompatibleRow": true,
"logSettings": {
"enableCopyActivityLog": true,
"copyActivityLogSettings": {
"logLevel": "Warning",
"enableReliableLogging": false
},
"logLocationSettings": {
"linkedServiceName": {
"referenceName": "ADLSGen2",
"type": "LinkedServiceReference"
},
"path": "sessionlog/"
}
}
},
| Propriedade | Description | Valores permitidos | Necessário |
|---|---|---|---|
| enableSkipIncompatibleRow | Especifica se as linhas incompatíveis devem ser ignoradas durante a cópia ou não. | True Falso (predefinição) |
Não |
| logSettings | Um grupo de propriedades que podem ser especificadas quando você deseja registrar as linhas incompatíveis. | Não | |
| linkedServiceName | O serviço vinculado do Armazenamento de Blobs do Azure ou do Azure Data Lake Storage Gen2 para armazenar o log que contém as linhas ignoradas. | Os nomes de um AzureBlobStorage ou AzureBlobFS tipo de serviço vinculado, que se refere à instância que você usa para armazenar o arquivo de log. |
Não |
| path | O caminho dos arquivos de log que contém as linhas ignoradas. | Especifique o caminho que você deseja usar para registrar os dados incompatíveis. Se você não fornecer um caminho, o serviço criará um contêiner para você. | Não |
Monitorar linhas ignoradas
Após a conclusão da execução da atividade de cópia, você poderá ver o número de linhas ignoradas na saída da atividade de cópia:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"logFilePath": "myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Se você configurar para registrar as linhas incompatíveis, poderá encontrar o arquivo de log neste caminho: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/copyactivity-logs/[copy-activity-name]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Os arquivos de log serão os arquivos csv. O esquema do arquivo de log é o seguinte:
| Coluna | Description |
|---|---|
| Carimbo de Data/Hora | O carimbo de data/hora quando as linhas incompatíveis foram ignoradas |
| Nível | O nível de log deste item. Estará no nível 'Aviso' se este item mostrar as linhas ignoradas |
| OperationName | Copie o comportamento operacional da atividade em cada linha. Será 'TabularRowSkip' para especificar que a linha incompatível específica foi ignorada |
| OperationItem | As linhas ignoradas do armazenamento de dados de origem. |
| Mensagem | Mais informações para ilustrar o porquê da incompatibilidade desta linha em particular. |
Um exemplo do conteúdo do arquivo de log é o seguinte:
Timestamp, Level, OperationName, OperationItem, Message
2020-02-26 06:22:32.2586581, Warning, TabularRowSkip, """data1"", ""data2"", ""data3""," "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
2020-02-26 06:22:33.2586351, Warning, TabularRowSkip, """data4"", ""data5"", ""data6"",", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
No arquivo de log de exemplo acima, você pode ver uma linha "data1, data2, data3" foi ignorada devido a um problema de conversão de tipo do armazenamento de origem para o destino. Outra linha "data4, data5, data6" foi ignorada devido ao problema de violação de PK do armazenamento de origem para o destino.
Cópia de dados tabulares (legado):
A abordagem a seguir é a maneira herdada de habilitar a tolerância a falhas apenas para copiar dados tabulares. Se você estiver criando um novo pipeline ou atividade, você é encorajado a começar a partir daqui.
Configuração
O exemplo a seguir fornece uma definição JSON para configurar ignorar as linhas incompatíveis na atividade de cópia:
"typeProperties": {
"source": {
"type": "BlobSource"
},
"sink": {
"type": "SqlSink",
},
"enableSkipIncompatibleRow": true,
"redirectIncompatibleRowSettings": {
"linkedServiceName": {
"referenceName": "<Azure Storage or Data Lake Store linked service>",
"type": "LinkedServiceReference"
},
"path": "redirectcontainer/erroroutput"
}
}
| Propriedade | Description | Valores permitidos | Necessário |
|---|---|---|---|
| enableSkipIncompatibleRow | Especifica se as linhas incompatíveis devem ser ignoradas durante a cópia ou não. | True Falso (predefinição) |
Não |
| redirectIncompatibleRowSettings | Um grupo de propriedades que podem ser especificadas quando você deseja registrar as linhas incompatíveis. | Não | |
| linkedServiceName | O serviço vinculado do Armazenamento do Azure ou do Repositório Azure Data Lake para armazenar o log que contém as linhas ignoradas. | Os nomes de um AzureStorage ou AzureDataLakeStore tipo de serviço vinculado, que se refere à instância que você deseja usar para armazenar o arquivo de log. |
Não |
| path | O caminho do arquivo de log que contém as linhas ignoradas. | Especifique o caminho que você deseja usar para registrar os dados incompatíveis. Se você não fornecer um caminho, o serviço criará um contêiner para você. | Não |
Monitorar linhas ignoradas
Após a conclusão da execução da atividade de cópia, você poderá ver o número de linhas ignoradas na saída da atividade de cópia:
"output": {
"dataRead": 95,
"dataWritten": 186,
"rowsCopied": 9,
"rowsSkipped": 2,
"copyDuration": 16,
"throughput": 0.01,
"redirectRowPath": "https://myblobstorage.blob.core.windows.net//myfolder/a84bf8d4-233f-4216-8cb5-45962831cd1b/",
"errors": []
},
Se você configurar para registrar as linhas incompatíveis, poderá encontrar o arquivo de log neste caminho: https://[your-blob-account].blob.core.windows.net/[path-if-configured]/[copy-activity-run-id]/[auto-generated-GUID].csv.
Os arquivos de log só podem ser os arquivos csv. Os dados originais que estão sendo ignorados serão registrados com vírgula como delimitador de coluna, se necessário. Adicionamos mais duas colunas "ErrorCode" e "ErrorMessage" além dos dados de origem originais no arquivo de log, onde você pode ver a causa raiz da incompatibilidade. O ErrorCode e o ErrorMessage serão citados entre aspas duplas.
Um exemplo do conteúdo do arquivo de log é o seguinte:
data1, data2, data3, "UserErrorInvalidDataValue", "Column 'Prop_2' contains an invalid value 'data3'. Cannot convert 'data3' to type 'DateTime'."
data4, data5, data6, "2627", "Violation of PRIMARY KEY constraint 'PK_tblintstrdatetimewithpk'. Cannot insert duplicate key in object 'dbo.tblintstrdatetimewithpk'. The duplicate key value is (data4)."
Conteúdos relacionados
Veja os outros artigos da atividade de cópia: