Utilizar Azure Data Lake Tools for Visual Studio Code
Importante
As novas contas do Azure Data Lake Analytics já não podem ser criadas, a menos que a sua subscrição tenha sido ativada. Se precisar que a sua subscrição esteja ativada , contacte o suporte e forneça o seu cenário empresarial.
Se já estiver a utilizar o Azure Data Lake Analytics, terá de criar um plano de migração para Azure Synapse Analytics para a sua organização até 29 de fevereiro de 2024.
Neste artigo, saiba como pode utilizar o Azure Data Lake Tools para Visual Studio Code (VS Code) para criar, testar e executar scripts U-SQL. As informações também são abordadas no seguinte vídeo:
Pré-requisitos
O Azure Data Lake Tools para VS Code suporta Windows, Linux e macOS. A execução local do U-SQL e a depuração local só funcionam no Windows.
Para macOS e Linux:
Instalar o Azure Data Lake Tools
Depois de instalar os pré-requisitos, pode instalar o Azure Data Lake Tools para VS Code.
Para instalar o Azure Data Lake Tools
Abra o Visual Studio Code.
Selecione Extensões no painel esquerdo. Introduza Azure Data Lake Tools na caixa de pesquisa.
Selecione Instalar junto ao Azure Data Lake Tools.
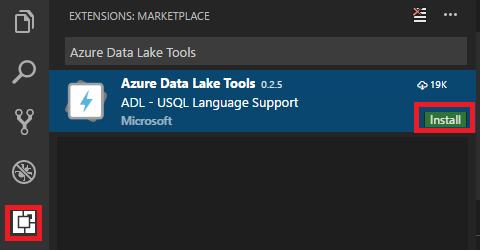
Após alguns segundos, o botão Instalar muda para Recarregar.
Selecione Recarregar para ativar a extensão do Azure Data Lake Tools .
Selecione Recarregar Janela para confirmar. Pode ver o Azure Data Lake Tools no painel Extensões .
Ativar o Azure Data Lake Tools
Crie um ficheiro .usql ou abra um ficheiro .usql existente para ativar a extensão.
Trabalhar com U-SQL
Para trabalhar com o U-SQL, precisa de abrir um ficheiro U-SQL ou uma pasta.
Para abrir o script de exemplo
Abra a paleta de comandos (Ctrl+Shift+P) e introduza ADL: Abrir Script de Exemplo. Abre outra instância deste exemplo. Também pode editar, configurar e submeter um script nesta instância.
Para abrir uma pasta para o projeto U-SQL
No Visual Studio Code, selecione o menu Ficheiro e, em seguida, selecione Abrir Pasta.
Especifique uma pasta e, em seguida, selecione Selecionar Pasta.
Selecione o menu Ficheiro e, em seguida, selecione Novo. É adicionado um ficheiro Sem Título 1 ao projeto.
Introduza o seguinte código no ficheiro Untitled-1:
@departments = SELECT * FROM (VALUES (31, "Sales"), (33, "Engineering"), (34, "Clerical"), (35, "Marketing") ) AS D( DepID, DepName );OUTPUT @departments TO "/Output/departments.csv" USING Outputters.Csv();
O script cria um ficheiro departments.csv com alguns dados incluídos na pasta /output.
Guarde o ficheiro como myUSQL.usql na pasta aberta.
Para compilar um script U-SQL
- Selecione Ctrl+Shift+P para abrir a paleta de comandos.
- Introduza ADL: Compilar Script. Os resultados da compilação são apresentados na janela Saída . Também pode clicar com o botão direito do rato num ficheiro de script e, em seguida, selecionar ADL: Compilar Script para compilar uma tarefa U-SQL. O resultado da compilação é apresentado no painel Saída .
Para submeter um script U-SQL
- Selecione Ctrl+Shift+P para abrir a paleta de comandos.
- Introduza ADL: Submeter tarefa. Também pode clicar com o botão direito do rato num ficheiro de script e, em seguida, selecionar ADL: Submeter Tarefa.
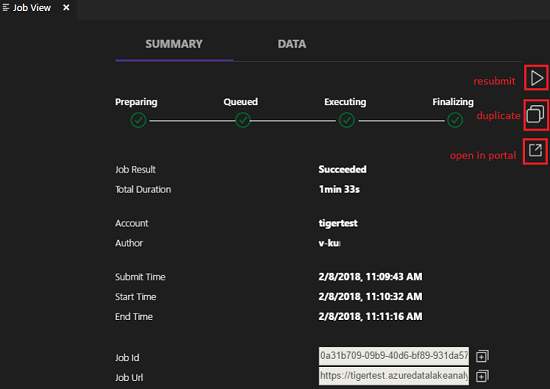
Depois de submeter uma tarefa U-SQL, os registos de submissão são apresentados na janela Saída no VS Code. A vista de trabalho é apresentada no painel direito. Se a submissão for bem-sucedida, o URL da tarefa também será apresentado. Pode abrir o URL da tarefa num browser para controlar o estado da tarefa em tempo real.
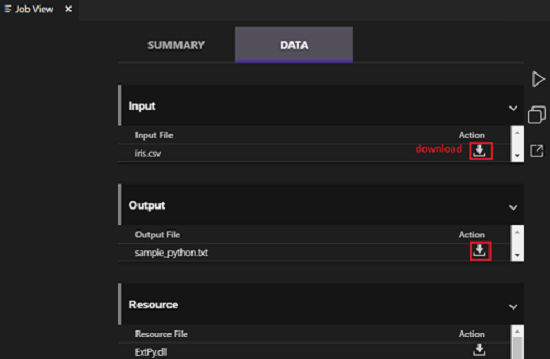
No separador RESUMO da vista de tarefas, pode ver os detalhes da tarefa. As funções principais incluem submeter novamente um script, duplicar um script e abrir no portal. No separador DADOS da vista de tarefas, pode consultar os ficheiros de entrada, os ficheiros de saída e os ficheiros de recursos. Os ficheiros podem ser transferidos para o computador local.
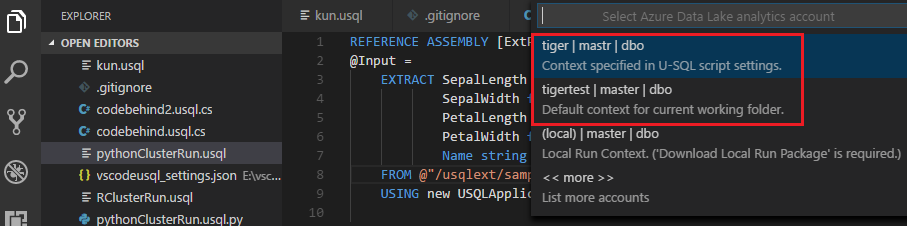
Para definir o contexto predefinido
Pode definir o contexto predefinido para aplicar esta definição a todos os ficheiros de script se não tiver definido parâmetros para ficheiros individualmente.
Selecione Ctrl+Shift+P para abrir a paleta de comandos.
Introduza ADL: defina o Contexto Predefinido. Em alternativa, clique com o botão direito do rato no editor de scripts e selecione ADL: Definir Contexto Predefinido.
Escolha a conta, a base de dados e o esquema que pretende. A definição é guardada no ficheiro de configuração xxx_settings.json.
Para definir parâmetros de script
Selecione Ctrl+Shift+P para abrir a paleta de comandos.
Introduza ADL: Definir Parâmetros de Script.
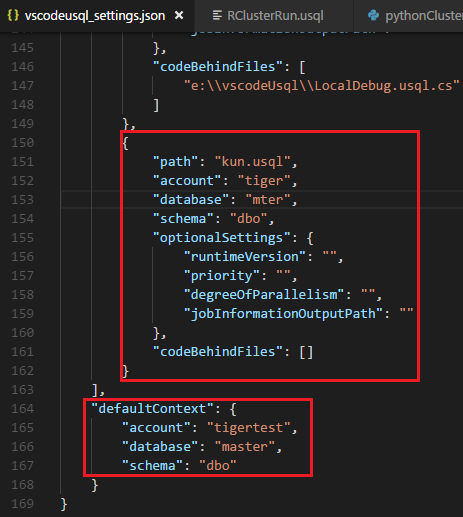
O ficheiro xxx_settings.json é aberto com as seguintes propriedades:
- conta: uma conta do Azure Data Lake Analytics na sua subscrição do Azure necessária para compilar e executar tarefas U-SQL. Tem de configurar a conta de computador antes de compilar e executar tarefas U-SQL.
- base de dados: uma base de dados na sua conta. A predefinição é mestre.
- schema: um esquema na base de dados. A predefinição é dbo.
- optionalSettings:
- prioridade: o intervalo de prioridades é de 1 a 1000, com 1 como a prioridade mais alta. O valor predefinido é 1000.
- degreeOfParallelismo: o intervalo de paralelismo é de 1 a 150. O valor predefinido é o paralelismo máximo permitido na sua conta do Azure Data Lake Analytics.
Nota
Depois de guardar a configuração, as informações de conta, base de dados e esquema aparecem na barra de estado no canto inferior esquerdo do ficheiro .usql correspondente se não tiver um contexto predefinido configurado.
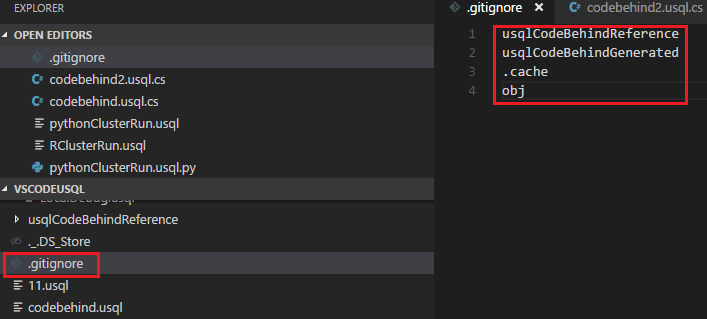
Para definir a ignorar o Git
Selecione Ctrl+Shift+P para abrir a paleta de comandos.
Introduza ADL: defina Git Ignore.
- Se não tiver um ficheiro .gitIgnore na pasta de trabalho do VS Code, é criado um ficheiro com o nome .gitIgnore na sua pasta. Quatro itens (usqlCodeBehindReference, usqlCodeBehindGenerated, .cache, obj) são adicionados ao ficheiro por predefinição. Se necessário, pode fazer mais atualizações.
- Se já tiver um ficheiro .gitIgnore na pasta de trabalho do VS Code, a ferramenta adiciona quatro itens (usqlCodeBehindReference, usqlCodeBehindGenerated, .cache, obj) no ficheiro .gitIgnore se os quatro itens não tiverem sido incluídos no ficheiro.
Trabalhar com ficheiros protegidos por código: C Sharp, Python e R
O Azure Data Lake Tools suporta vários códigos personalizados. Para obter instruções, veja Desenvolver U-SQL com Python, R e C Sharp para Data Lake Analytics do Azure no VS Code.
Trabalhar com assemblagens
Para obter informações sobre o desenvolvimento de assemblagens, veja Desenvolver assemblagens U-SQL para tarefas de Data Lake Analytics do Azure.
Pode utilizar o Data Lake Tools para registar assemblagens de código personalizadas no catálogo de Data Lake Analytics.
Para registar uma assemblagem
Pode registar a assemblagem através do comando ADL: Registar Assemblagem ou ADL: Registar Assemblagem (Avançadas ).
Para se registar através do comando ADL: Registar Assemblagem
- Selecione Ctrl+Shift+P para abrir a paleta de comandos.
- Introduza ADL: Registar Assemblagem.
- Especifique o caminho de assemblagem local.
- Selecione uma conta Data Lake Analytics.
- Selecione uma base de dados.
O portal é aberto num browser e apresenta o processo de registo de assemblagem.
Uma forma mais conveniente de acionar o comando ADL: Registar Assemblagem é clicar com o botão direito do rato no ficheiro .dll no Explorador de Ficheiros.
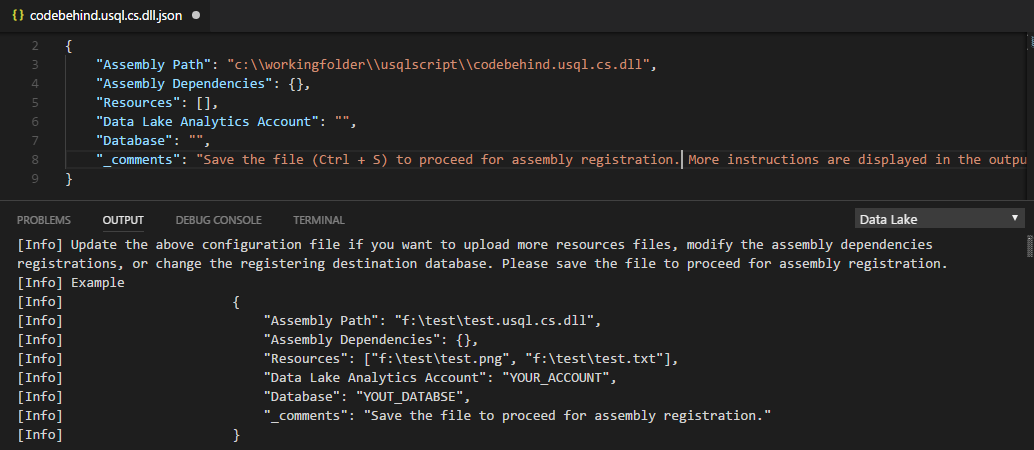
Para se registar através do comando ADL: Registar Assemblagem (Avançadas)
Selecione Ctrl+Shift+P para abrir a paleta de comandos.
Introduza ADL: Registar Assemblagem (Avançada).
Especifique o caminho de assemblagem local.
O ficheiro JSON é apresentado. Reveja e edite as dependências de assemblagem e os parâmetros de recursos, se necessário. As instruções são apresentadas na janela Saída . Para avançar para o registo de assemblagem, guarde (Ctrl+S) o ficheiro JSON.
Nota
- O Azure Data Lake Tools detetará automaticamente se a DLL tem dependências de assemblagem. As dependências são apresentadas no ficheiro JSON depois de serem detetadas.
- Pode carregar os seus recursos DLL (por exemplo, .txt, .png e .csv) como parte do registo de assemblagem.
Outra forma de acionar o comando ADL: Register Assembly (Advanced) é clicar com o botão direito do rato no ficheiro .dll no Explorador de Ficheiros.
O seguinte código U-SQL demonstra como chamar uma assemblagem. No exemplo, o nome da assemblagem é teste.
REFERENCE ASSEMBLY [test];
@a =
EXTRACT
Iid int,
Starts DateTime,
Region string,
Query string,
DwellTime int,
Results string,
ClickedUrls string
FROM @"Sample/SearchLog.txt"
USING Extractors.Tsv();
@d =
SELECT DISTINCT Region
FROM @a;
@d1 =
PROCESS @d
PRODUCE
Region string,
Mkt string
USING new USQLApplication_codebehind.MyProcessor();
OUTPUT @d1
TO @"Sample/SearchLogtest.txt"
USING Outputters.Tsv();
Utilizar a execução local do U-SQL e a depuração local para utilizadores do Windows
A execução local do U-SQL testa os seus dados locais e valida o script localmente antes de o código ser publicado no Data Lake Analytics. Pode utilizar a funcionalidade de depuração local para concluir as seguintes tarefas antes de o código ser submetido para Data Lake Analytics:
- Depure o código C# atrás.
- Percorrer o código.
- Valide o script localmente.
A funcionalidade de execução local e depuração local só funciona em ambientes Windows e não é suportada em sistemas operativos baseados em macOS e Linux.
Para obter instruções sobre a execução local e a depuração local, veja U-SQL local run and local debug with Visual Studio Code (Execução local do U-SQL e depuração local com o Visual Studio Code).
Ligar ao Azure
Antes de poder compilar e executar scripts U-SQL no Data Lake Analytics, tem de se ligar à sua conta do Azure.
Para ligar ao Azure com um comando
Selecione Ctrl+Shift+P para abrir a paleta de comandos.
Introduza ADL: Iniciar sessão. As informações de início de sessão são apresentadas no canto inferior direito.
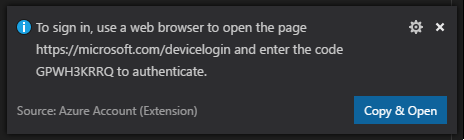
Selecione Copiar & Abrir para abrir a página Web de início de sessão. Cole o código na caixa e, em seguida, selecione Continuar.
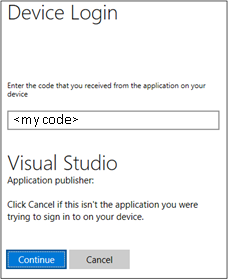
Siga as instruções para iniciar sessão a partir da página Web. Quando estiver ligado, o nome da conta do Azure aparece na barra de estado no canto inferior esquerdo da janela do VS Code.
Nota
- O Data Lake Tools inicia sessão automaticamente na próxima vez se não terminar sessão.
- Se a sua conta tiver dois fatores ativados, recomendamos que utilize a autenticação por telefone em vez de utilizar um PIN.
Para terminar sessão, introduza o comando ADL: Terminar sessão.
Para ligar ao Azure a partir do explorador
Expanda AZURE DATALAKE, selecione Iniciar sessão no Azure e, em seguida, siga o passo 3 e o passo 4 de Para ligar ao Azure com um comando.
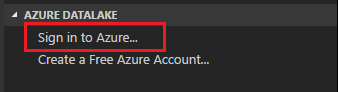
Não pode terminar sessão no explorador. Para terminar sessão, veja Para ligar ao Azure com um comando.
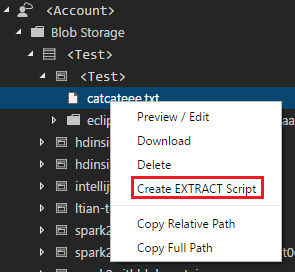
Criar um script de extração
Pode criar um script de extração para .csv, .tsv e .txt ficheiros com o comando ADL: Criar Script EXTRACT ou a partir do explorador do Azure Data Lake.
Para criar um script de extração com um comando
- Selecione Ctrl+Shift+P para abrir a paleta de comandos e introduza ADL: Criar Script EXTRACT.
- Especifique o caminho completo para um ficheiro de Armazenamento do Azure e selecione a tecla Enter.
- Selecione uma conta.
- Para um ficheiro .txt, selecione um delimitador para extrair o ficheiro.
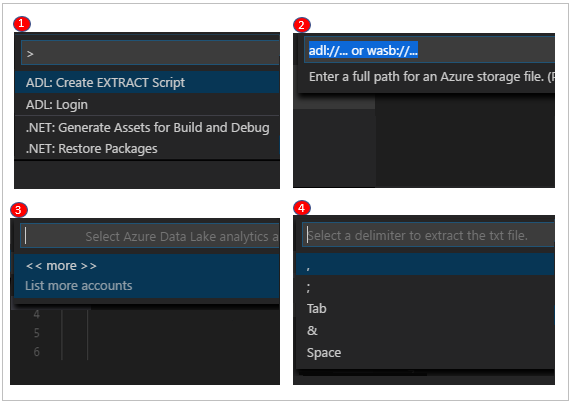
O script de extração é gerado com base nas entradas. Para um script que não consegue detetar as colunas, selecione uma das duas opções. Caso contrário, apenas será gerado um script.

Para criar um script de extração a partir do explorador
Outra forma de criar o script de extração é através do menu de clique com o botão direito do rato (atalho) no ficheiro .csv, .tsv ou .txt no Azure Data Lake Store ou no armazenamento de Blobs do Azure.