Model Serving legado do MLflow no Azure Databricks
Importante
Esta funcionalidade está em Pré-visualização Pública.
Importante
- Esta documentação foi desativada e pode não ser atualizada. Os produtos, serviços ou tecnologias mencionados neste conteúdo não são mais suportados.
- A orientação neste artigo é para o Legacy MLflow Model Serving. A Databricks recomenda que você migre seus fluxos de trabalho de serviço de modelo para o Model Serving para a implantação e escalabilidade aprimoradas do ponto de extremidade do modelo. Para obter mais informações, consulte Modelo de serviço com o Azure Databricks.
O Legacy MLflow Model Serving permite hospedar modelos de aprendizado de máquina do Model Registry como pontos de extremidade REST que são atualizados automaticamente com base na disponibilidade de versões de modelo e seus estágios. Ele usa um cluster de nó único que é executado sob sua própria conta dentro do que agora é chamado de plano de computação clássico. Esse plano de computação inclui a rede virtual e seus recursos de computação associados, como clusters para notebooks e trabalhos, armazéns SQL profissionais e clássicos e pontos de extremidade de serviço de modelo legado.
Quando você habilita o serviço de modelo para um determinado modelo registrado, o Azure Databricks cria automaticamente um cluster exclusivo para o modelo e implanta todas as versões não arquivadas do modelo nesse cluster. O Azure Databricks reinicia o cluster se ocorrer um erro e encerra o cluster quando você desabilita o serviço de modelo para o modelo. O serviço de modelo sincroniza automaticamente com o Registro de modelo e implanta todas as novas versões de modelo registrado. As versões de modelo implantadas podem ser consultadas com uma solicitação de API REST padrão. O Azure Databricks autentica solicitações para o modelo usando sua autenticação padrão.
Enquanto esse serviço está em visualização, o Databricks recomenda seu uso para aplicativos de baixa taxa de transferência e não críticos. A taxa de transferência alvo é de 200 qps e a disponibilidade alvo é de 99,5%, embora nenhuma garantia seja feita quanto a isso. Além disso, há um limite de tamanho de carga útil de 16 MB por solicitação.
Cada versão do modelo é implantada usando a implantação do modelo MLflow e é executada em um ambiente Conda especificado por suas dependências.
Nota
- O cluster é mantido enquanto o serviço estiver habilitado, mesmo que não exista uma versão ativa do modelo. Para encerrar o cluster de serviço, desative o modelo de serviço para o modelo registrado.
- O cluster é considerado um cluster multiuso, sujeito a preços de carga de trabalho para todos os fins.
- Os scripts de inicialização global não são executados em clusters de serviço de modelo.
Importante
atualizou seus termos de serviço para anaconda.org canais. Com base nos novos termos de serviço, você pode precisar de uma licença comercial se depender da embalagem e distribuição da Anaconda. Consulte Anaconda Commercial Edition FAQ para obter mais informações. Seu uso de qualquer canal Anaconda é regido por seus termos de serviço.
Os modelos MLflow registrados antes da v1.18 (Databricks Runtime 8.3 ML ou anterior) eram, por padrão, registrados com o canal conda defaults (https://repo.anaconda.com/pkgs/) como dependência. Devido a essa alteração de licença, o Databricks interrompeu o defaults uso do canal para modelos registrados usando MLflow v1.18 e superior. O canal padrão registrado agora conda-forgeé , o que aponta para a comunidade gerenciada https://conda-forge.org/.
Se você registrou um modelo antes do MLflow v1.18 sem excluir o defaults canal do ambiente conda para o modelo, esse modelo pode ter uma dependência do defaults canal que você pode não ter pretendido.
Para confirmar manualmente se um modelo tem essa dependência, você pode examinar channel o valor no arquivo que é empacotado conda.yaml com o modelo registrado. Por exemplo, um modelo com uma dependência de conda.yaml canal pode ter esta defaults aparência:
channels:
- defaults
dependencies:
- python=3.8.8
- pip
- pip:
- mlflow
- scikit-learn==0.23.2
- cloudpickle==1.6.0
name: mlflow-env
Como a Databricks não pode determinar se seu uso do repositório Anaconda para interagir com seus modelos é permitido sob seu relacionamento com a Anaconda, a Databricks não está forçando seus clientes a fazer alterações. Se o seu uso do repositório de Anaconda.com através do uso do Databricks for permitido sob os termos da Anaconda, você não precisará tomar nenhuma ação.
Se desejar alterar o canal usado no ambiente de um modelo, você pode registrar novamente o modelo no registro do modelo com um novo conda.yamlarquivo . Você pode fazer isso especificando o conda_env canal no parâmetro de log_model().
Para obter mais informações sobre a log_model() API, consulte a documentação do MLflow para o modelo com o qual você está trabalhando, por exemplo, log_model para scikit-learn.
Para obter mais informações sobre conda.yaml arquivos, consulte a documentação do MLflow.
Requisitos
- O Legacy MLflow Model Serving está disponível para modelos Python MLflow. Você deve declarar todas as dependências do modelo no ambiente conda. Consulte Dependências do modelo de log.
- Para habilitar o Serviço de Modelo, você deve ter permissão de criação de cluster.
Modelo a servir a partir do Registo de Modelo
O serviço de modelo está disponível no Azure Databricks a partir do Registo de Modelo.
Ativar e desativar o serviço de modelo
Você habilita um modelo para veiculação a partir de sua página de modelo registrado.
Clique na guia Servir . Se o modelo ainda não estiver habilitado para servir, o botão Ativar serviço será exibido.
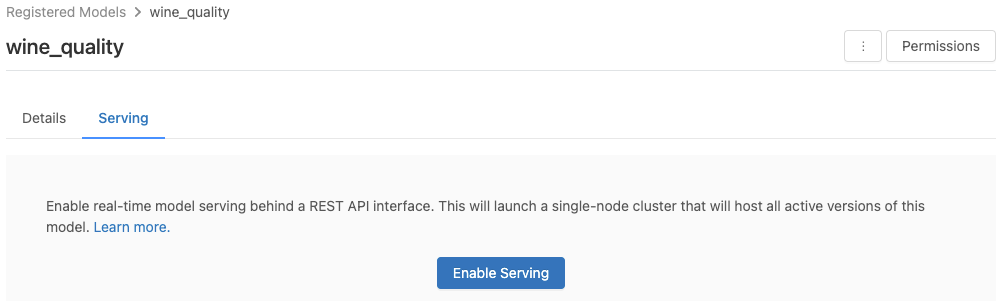
Clique em Ativar Serviço. A guia Servindo aparece com Status mostrado como Pendente . Após alguns minutos, o Status muda para Pronto.
Para desativar um modelo de serviço, clique em Parar.
Validar modelo de serviço
Na guia Servir, você pode enviar uma solicitação para o modelo atendido e visualizar a resposta.

URIs da versão do modelo
A cada versão do modelo implantado é atribuído um ou vários URIs exclusivos. No mínimo, a cada versão do modelo é atribuído um URI construído da seguinte forma:
<databricks-instance>/model/<registered-model-name>/<model-version>/invocations
Por exemplo, para chamar a versão 1 de um modelo registrado como iris-classifier, use este URI:
https://<databricks-instance>/model/iris-classifier/1/invocations
Você também pode chamar uma versão do modelo por seu estágio. Por exemplo, se a versão 1 estiver no estágio Produção, ela também poderá ser pontuada usando este URI:
https://<databricks-instance>/model/iris-classifier/Production/invocations
A lista de URIs de modelo disponíveis aparece na parte superior da guia Versões do modelo na página de serviço.
Gerenciar versões servidas
Todas as versões de modelo ativas (não arquivadas) são implantadas e você pode consultá-las usando os URIs. O Azure Databricks implanta automaticamente novas versões de modelo quando elas são registradas e remove automaticamente as versões antigas quando elas são arquivadas.
Nota
Todas as versões implantadas de um modelo registrado compartilham o mesmo cluster.
Gerenciar direitos de acesso ao modelo
Os direitos de acesso ao modelo são herdados do Registro do modelo. Ativar ou desativar o recurso de veiculação requer a permissão 'gerenciar' no modelo registrado. Qualquer pessoa com direitos de leitura pode pontuar qualquer uma das versões implantadas.
Pontuar versões de modelos implantados
Para pontuar um modelo implantado, você pode usar a interface do usuário ou enviar uma solicitação de API REST para o URI do modelo.
Pontuação via UI
Esta é a maneira mais fácil e rápida de testar o modelo. Você pode inserir os dados de entrada do modelo no formato JSON e clicar em Enviar solicitação. Se o modelo tiver sido registrado com um exemplo de entrada (como mostrado no gráfico acima), clique em Carregar exemplo para carregar o exemplo de entrada.
Pontuação via solicitação de API REST
Você pode enviar uma solicitação de pontuação por meio da API REST usando a autenticação padrão do Databricks. Os exemplos abaixo demonstram a autenticação usando um token de acesso pessoal com MLflow 1.x.
Nota
Como prática recomendada de segurança, quando você se autentica com ferramentas, sistemas, scripts e aplicativos automatizados, o Databricks recomenda que você use tokens de acesso pessoal pertencentes a entidades de serviço em vez de usuários do espaço de trabalho. Para criar tokens para entidades de serviço, consulte Gerenciar tokens para uma entidade de serviço.
Dado um MODEL_VERSION_URI like https://<databricks-instance>/model/iris-classifier/Production/invocations (onde <databricks-instance> é o nome da sua instância do Databricks) e um token da API REST do Databricks chamado DATABRICKS_API_TOKEN, os exemplos a seguir mostram como consultar um modelo servido:
Os exemplos a seguir refletem o formato de pontuação para modelos criados com MLflow 1.x. Se preferir usar o MLflow 2.0, será necessário atualizar o formato de carga útil da solicitação.
Bash
Trecho para consultar um modelo que aceita entradas de dataframe.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '[
{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}
]'
Trecho para consultar um modelo que aceita entradas tensoras. As entradas do tensor devem ser formatadas conforme descrito nos documentos da API do TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \
-H 'Content-Type: application/json' \
-d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'
Python
import numpy as np
import pandas as pd
import requests
def create_tf_serving_json(data):
return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()}
def score_model(model_uri, databricks_token, data):
headers = {
"Authorization": f"Bearer {databricks_token}",
"Content-Type": "application/json",
}
data_json = data.to_dict(orient='records') if isinstance(data, pd.DataFrame) else create_tf_serving_json(data)
response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json)
if response.status_code != 200:
raise Exception(f"Request failed with status {response.status_code}, {response.text}")
return response.json()
# Scoring a model that accepts pandas DataFrames
data = pd.DataFrame([{
"sepal_length": 5.1,
"sepal_width": 3.5,
"petal_length": 1.4,
"petal_width": 0.2
}])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
# Scoring a model that accepts tensors
data = np.asarray([[5.1, 3.5, 1.4, 0.2]])
score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)
Powerbi
Você pode pontuar um conjunto de dados no Power BI Desktop usando as seguintes etapas:
Abra o conjunto de dados que você deseja pontuar.
Vá para Transformar dados.
Clique com o botão direito do mouse no painel esquerdo e selecione Criar nova consulta.
Vá para Ver > Editor Avançado.
Substitua o corpo da consulta pelo trecho de código abaixo, depois de preencher um arquivo apropriado
DATABRICKS_API_TOKENeMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNomeie a consulta com o nome do modelo desejado.
Abra o editor de consultas avançado para seu conjunto de dados e aplique a função de modelo.
Monitore modelos servidos
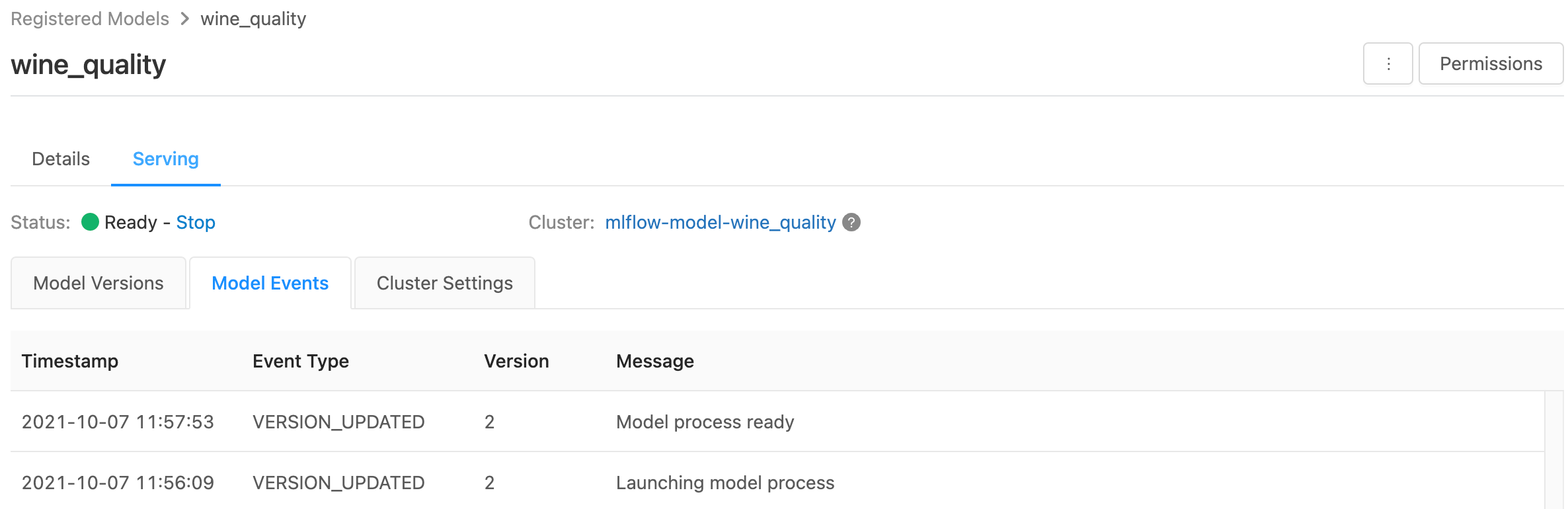
A página de serviço exibe indicadores de status para o cluster de serviço, bem como versões de modelo individuais.
- Para inspecionar o estado do cluster de serviço, use a guia Eventos do modelo, que exibe uma lista de todos os eventos de serviço para esse modelo.
- Para inspecionar o estado de uma única versão do modelo, clique na guia Versões do Modelo e role para exibir as guias Logs ou Eventos de Versão.
Personalizar o cluster de serviço
Para personalizar o cluster de serviço, use a guia Configurações do Cluster na guia Servindo .
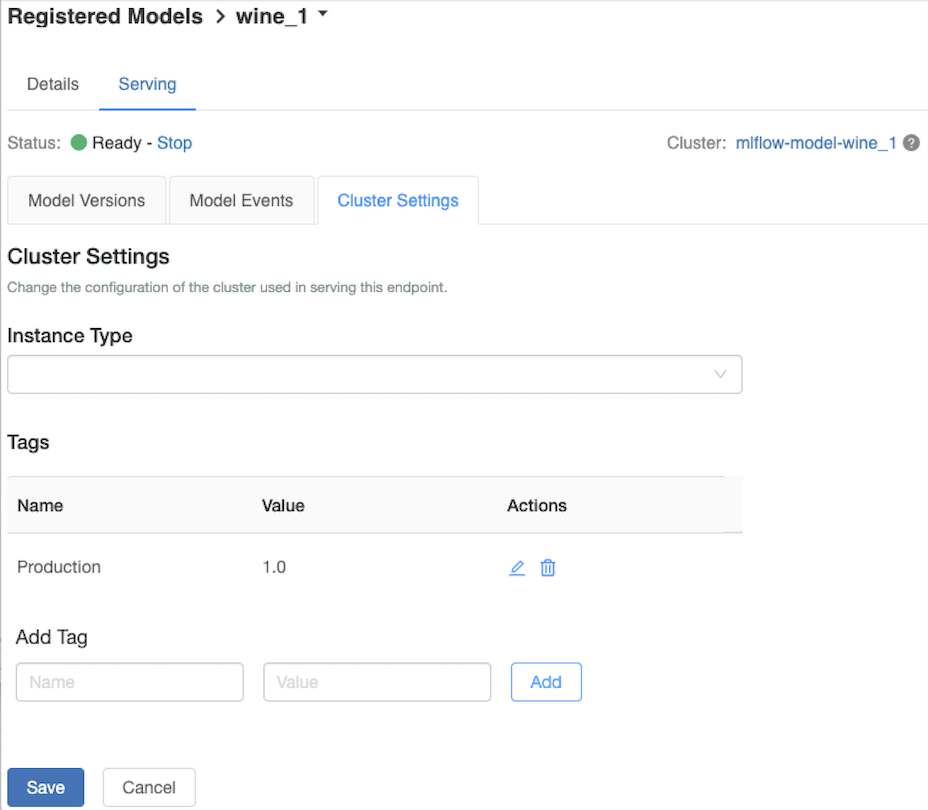
- Para modificar o tamanho da memória e o número de núcleos de um cluster de serviço, use o menu suspenso Tipo de instância para selecionar a configuração de cluster desejada. Quando você clica em Salvar, o cluster existente é encerrado e um novo cluster é criado com as configurações especificadas.
- Para adicionar uma etiqueta, escreva o nome e o valor nos campos Adicionar Etiqueta e clique em Adicionar.
- Para editar ou eliminar uma etiqueta existente, clique num dos ícones na coluna Ações da tabela Etiquetas .
Integração com a loja de recursos
O serviço de modelo herdado pode procurar automaticamente valores de recursos de lojas online publicadas.
.. AWS:
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Amazon DynamoDB (v0.3.8 and above)
- Amazon Aurora (MySQL-compatible)
- Amazon RDS MySQL
.. azure::
Databricks Legacy MLflow Model Serving supports automatic feature lookup from these online stores:
- Azure Cosmos DB (v0.5.0 and above)
- Azure Database for MySQL
Erros conhecidos
ResolvePackageNotFound: pyspark=3.1.0
Este erro pode ocorrer se um modelo depende pyspark e é registrado usando o Databricks Runtime 8.x.
Se você vir esse erro, especifique a pyspark versão explicitamente ao registrar o modelo, usando o conda_env parâmetro.
Unrecognized content type parameters: format
Este erro pode ocorrer como resultado do novo formato de protocolo de pontuação MLflow 2.0. Se você estiver vendo esse erro, provavelmente está usando um formato de solicitação de pontuação desatualizado. Para resolver o erro, você pode:
Atualize o formato do seu pedido de pontuação para o protocolo mais recente.
Nota
Os exemplos a seguir refletem o formato de pontuação introduzido no MLflow 2.0. Se preferir usar o MLflow 1.x, você pode modificar suas
log_model()chamadas de API para incluir a dependência de versão do MLflow desejada noextra_pip_requirementsparâmetro. Isso garante que o formato de pontuação apropriado seja usado.mlflow.<flavor>.log_model(..., extra_pip_requirements=["mlflow==1.*"])Bash
Consulte um modelo aceitando entradas de dataframe pandas.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{ "dataframe_records": [{"sepal_length (cm)": 5.1, "sepal_width (cm)": 3.5, "petal_length (cm)": 1.4, "petal_width": 0.2}, {"sepal_length (cm)": 4.2, "sepal_width (cm)": 5.0, "petal_length (cm)": 0.8, "petal_width": 0.5}] }'Consultar um modelo aceitando entradas tensoras. As entradas do tensor devem ser formatadas conforme descrito nos documentos da API do TensorFlow Serving.
curl -X POST -u token:$DATABRICKS_API_TOKEN $MODEL_VERSION_URI \ -H 'Content-Type: application/json' \ -d '{"inputs": [[5.1, 3.5, 1.4, 0.2]]}'Python
import numpy as np import pandas as pd import requests def create_tf_serving_json(data): return {'inputs': {name: data[name].tolist() for name in data.keys()} if isinstance(data, dict) else data.tolist()} def score_model(model_uri, databricks_token, data): headers = { "Authorization": f"Bearer {databricks_token}", "Content-Type": "application/json", } data_dict = {'dataframe_split': data.to_dict(orient='split')} if isinstance(data, pd.DataFrame) else create_tf_serving_json(data) data_json = json.dumps(data_dict) response = requests.request(method='POST', headers=headers, url=model_uri, json=data_json) if response.status_code != 200: raise Exception(f"Request failed with status {response.status_code}, {response.text}") return response.json() # Scoring a model that accepts pandas DataFrames data = pd.DataFrame([{ "sepal_length": 5.1, "sepal_width": 3.5, "petal_length": 1.4, "petal_width": 0.2 }]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data) # Scoring a model that accepts tensors data = np.asarray([[5.1, 3.5, 1.4, 0.2]]) score_model(MODEL_VERSION_URI, DATABRICKS_API_TOKEN, data)Powerbi
Você pode pontuar um conjunto de dados no Power BI Desktop usando as seguintes etapas:
Abra o conjunto de dados que você deseja pontuar.
Vá para Transformar dados.
Clique com o botão direito do mouse no painel esquerdo e selecione Criar nova consulta.
Vá para Ver > Editor Avançado.
Substitua o corpo da consulta pelo trecho de código abaixo, depois de preencher um arquivo apropriado
DATABRICKS_API_TOKENeMODEL_VERSION_URI.(dataset as table ) as table => let call_predict = (dataset as table ) as list => let apiToken = DATABRICKS_API_TOKEN, modelUri = MODEL_VERSION_URI, responseList = Json.Document(Web.Contents(modelUri, [ Headers = [ #"Content-Type" = "application/json", #"Authorization" = Text.Format("Bearer #{0}", {apiToken}) ], Content = Json.FromValue(dataset) ] )) in responseList, predictionList = List.Combine(List.Transform(Table.Split(dataset, 256), (x) => call_predict(x))), predictionsTable = Table.FromList(predictionList, (x) => {x}, {"Prediction"}), datasetWithPrediction = Table.Join( Table.AddIndexColumn(predictionsTable, "index"), "index", Table.AddIndexColumn(dataset, "index"), "index") in datasetWithPredictionNomeie a consulta com o nome do modelo desejado.
Abra o editor de consultas avançado para seu conjunto de dados e aplique a função de modelo.
Se sua solicitação de pontuação usa o cliente MLflow, como
mlflow.pyfunc.spark_udf(), atualize seu cliente MLflow para a versão 2.0 ou superior para usar o formato mais recente. Saiba mais sobre o protocolo de pontuação do Modelo MLflow atualizado no MLflow 2.0.
Para obter mais informações sobre formatos de dados de entrada aceitos pelo servidor (por exemplo, formato pandas split-oriented ), consulte a documentação MLflow.
Comentários
Brevemente: Ao longo de 2024, vamos descontinuar progressivamente o GitHub Issues como mecanismo de feedback para conteúdos e substituí-lo por um novo sistema de feedback. Para obter mais informações, veja: https://aka.ms/ContentUserFeedback.
Submeter e ver comentários